LocalNav: Distilling Frontier VLMs and Embodied RL for On-Device Object Goal Navigation
Pith reviewed 2026-06-29 04:43 UTC · model grok-4.3
The pith
Fine-tuning Qwen3.5-4B on 500 frontier reasoning traces yields 34.5 percent success in object goal navigation, closing most of the gap to a 39.7 percent cloud pipeline while cutting edge latency by 82.8 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Distilling 500 reasoning traces from a frontier VLM into Qwen3.5-4B enables 34.5 percent success rate on HM3D OVON, narrowing the gap to the 39.7 percent achieved by the full Claude Sonnet 4.6 scene-graph pipeline, while E-RLVR with token-generation regularization plus quantization reduces overall inference latency by 82.8 percent for edge execution.
What carries the argument
Distillation of frontier VLM reasoning traces into a 4B local model combined with E-RLVR token-generation regularization for sequence compression.
If this is right
- A 4B VLM can perform object goal navigation at success rates within 5 percentage points of a much larger cloud model.
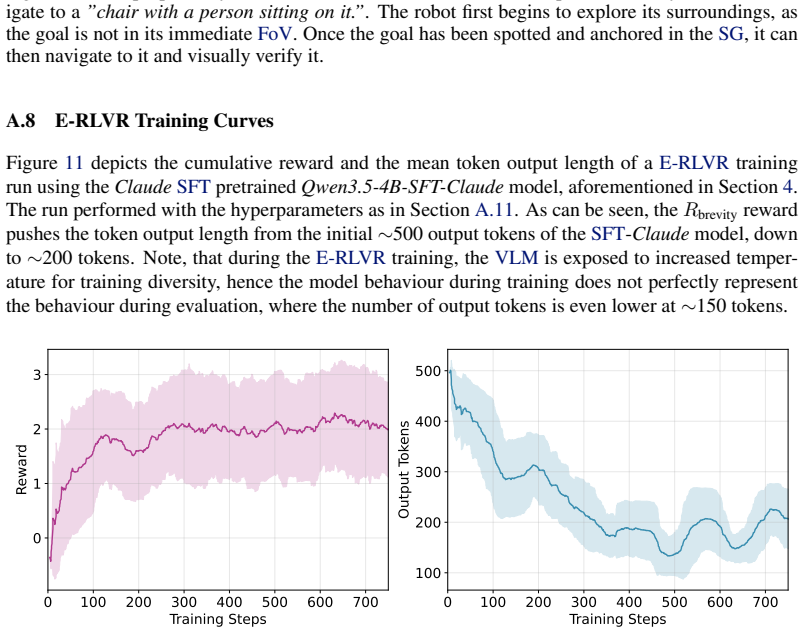
- Output sequence lengths drop by 72.1 percent and per-step latency by 71.8 percent after E-RLVR regularization.
- Quantization combined with the regularization produces an 82.8 percent cumulative latency reduction suitable for embedded GPUs.
- The distilled model supports low-latency local execution on mobile robots without cloud round-trips.
- The same distillation pattern can be applied to other open-vocabulary embodied tasks that rely on spatial-semantic reasoning.
Where Pith is reading between the lines
- If the 500-trace set proves sufficient across benchmarks, the cost of creating local navigation agents drops dramatically because frontier model calls are needed only once.
- The method implies that embodied RL can serve as a post-distillation compressor rather than a full training regime when high-quality traces already exist.
- Real-robot deployment would test whether the simulated 34.5 percent success transfers when perception noise and actuation delays appear.
Load-bearing premise
The 500 reasoning traces generated by Claude Sonnet 4.6 contain sufficient transferable spatial-semantic knowledge that fine-tuning alone can close most of the performance gap to the full frontier pipeline.
What would settle it
Evaluating the base Qwen3.5-4B model without the 500-trace fine-tuning on the same HM3D OVON benchmark and finding its success rate remains below 15 percent would show the traces are necessary for the reported performance.
Figures





read the original abstract
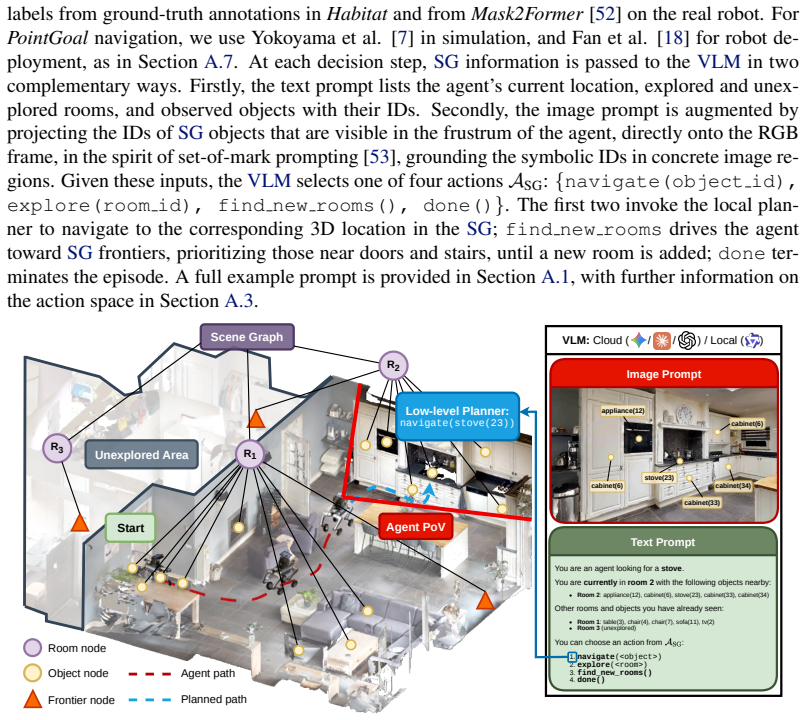
Vision Language Models (VLMs) have emerged in the robotic domain as a powerful tool that enables environmental perception with language context, serving as a catalyst for open-vocabulary tasks like ObjectNav. Yet, their computational footprint typically confines them to cloud execution, hindering low-latency inference with local deployment on resource-constrained robots. To address this challenge, we present a distillation strategy that transfers complex spatial-semantic reasoning from large frontier models into a lightweight, 4B-parameter local VLM for edge execution on embedded GPU devices (e.g., Jetson Orin). We first establish a State of the Art (SotA), Scene Graph (SG)-based pipeline using Claude Sonnet 4.6, achieving a 39.7% Success Rate (SR) on the HM3D OVON benchmark. We then demonstrate that fine-tuning Qwen3.5-4B on just 500 frontier reasoning traces effectively enables navigation capabilities, yielding a SR of 34.5%, narrowing the gap to the performance of large cloud models. Finally, we introduce E-RLVR with Token Generation (TG) regularization to compress output sequence lengths for physical deployment while grounding the agent in its task. This downstream optimization reduces TG overhead by 72.1% and latency by 71.8%. Combined with quantization, this joint strategy yields a cumulative 82.8% reduction in overall inference latency without significantly sacrificing performance, presenting a viable paradigm for local, low-latency VLM execution on mobile robots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LocalNav, a distillation approach that transfers spatial-semantic reasoning from a frontier VLM (Claude Sonnet 4.6) via a scene-graph pipeline to a lightweight 4B VLM (Qwen3.5-4B) by fine-tuning on 500 reasoning traces. This achieves a 34.5% success rate on the HM3D OVON benchmark, close to the 39.7% of the frontier model. It further proposes E-RLVR with Token Generation regularization to reduce output lengths and latency for on-device deployment on embedded GPUs, reporting an 82.8% cumulative latency reduction.
Significance. If the results hold, the work would be significant as it shows that effective distillation of complex navigation reasoning can be achieved with a very small number of traces from a frontier model, enabling practical on-device VLM-based ObjectNav on resource-constrained robots without relying on cloud inference. The latency optimizations further support real-world deployment.
major comments (3)
- [Abstract] Abstract: The success rates of 34.5% and 39.7% are presented as single-point values without error bars, confidence intervals, or details on the evaluation protocol (e.g., number of episodes, variance across runs), which is load-bearing for claims of narrowing the performance gap.
- [Abstract / distillation experiments] Abstract / distillation experiments: No details are provided on the collection, sampling strategy, diversity (e.g., object categories, scene layouts on HM3D), quality filtering, or coverage metrics of the 500 frontier reasoning traces. This is central to the claim that fine-tuning on these traces transfers sufficient spatial-semantic knowledge, as the transferability assumption lacks supporting ablations or analysis.
- [Experiments section] Experiments section: The manuscript does not include ablations on the number of traces, comparison to other distillation methods, or verification that the 500-trace set was not post-hoc selected, making it hard to assess if the performance is due to genuine distillation or dataset-specific effects.
minor comments (1)
- [Abstract] Abstract: The term 'E-RLVR with Token Generation (TG) regularization' is introduced without prior definition or reference to its components.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas for improving the clarity and rigor of our results and experimental details. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The success rates of 34.5% and 39.7% are presented as single-point values without error bars, confidence intervals, or details on the evaluation protocol (e.g., number of episodes, variance across runs), which is load-bearing for claims of narrowing the performance gap.
Authors: We agree that providing evaluation protocol details and statistical measures would strengthen the claims. In the revised manuscript, we will update the abstract and relevant sections to specify the number of episodes evaluated on the HM3D OVON benchmark and include any available variance or confidence interval information from the runs performed. revision: yes
-
Referee: [Abstract / distillation experiments] Abstract / distillation experiments: No details are provided on the collection, sampling strategy, diversity (e.g., object categories, scene layouts on HM3D), quality filtering, or coverage metrics of the 500 frontier reasoning traces. This is central to the claim that fine-tuning on these traces transfers sufficient spatial-semantic knowledge, as the transferability assumption lacks supporting ablations or analysis.
Authors: We will expand the methods and distillation experiments sections to include full details on the collection process for the 500 reasoning traces. This will cover the sampling strategy from the scene-graph pipeline, diversity across object categories and HM3D scene layouts, quality filtering steps applied, and any coverage metrics used. revision: yes
-
Referee: [Experiments section] Experiments section: The manuscript does not include ablations on the number of traces, comparison to other distillation methods, or verification that the 500-trace set was not post-hoc selected, making it hard to assess if the performance is due to genuine distillation or dataset-specific effects.
Authors: We will revise the experiments section to explicitly describe the trace generation and selection pipeline, confirming it followed a systematic process rather than post-hoc selection. While we did not conduct full ablations on varying numbers of traces or head-to-head comparisons against other distillation baselines (due to computational constraints), we will add discussion of related distillation literature and the rationale for selecting 500 traces based on our preliminary scaling observations. revision: partial
Circularity Check
No circularity: empirical distillation evaluated on external benchmark
full rationale
The paper describes an empirical pipeline that generates 500 reasoning traces from Claude Sonnet 4.6, fine-tunes Qwen3.5-4B on them, and reports success rate (34.5%) and latency reductions on the external HM3D OVON benchmark. No equations, fitted parameters, or self-referential definitions appear in the provided text that would reduce the reported metrics to quantities defined by the method itself. The central claims rest on measured outcomes after explicit training rather than any of the enumerated circular patterns (self-definitional, fitted-input-called-prediction, or load-bearing self-citation).
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of frontier reasoning traces =
500
axioms (1)
- domain assumption Reasoning traces produced by Claude Sonnet 4.6 contain the spatial-semantic knowledge required for ObjectNav.
invented entities (1)
-
E-RLVR with Token Generation (TG) regularization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. GPT-4o System Card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[3]
G. C. et. al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/ 2507.06261
Pith/arXiv arXiv 2025
-
[4]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[5]
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.013
-
[6]
Z. Zhu, X. Wang, Y . Li, Z. Zhang, X. Ma, Y . Chen, B. Jia, W. Liang, Q. Yu, Z. Deng, S. Huang, and Q. Li. Move to understand a 3d scene: Bridging visual grounding and exploration for effi- cient and versatile embodied navigation.2025 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 8120–8132, 2025. URLhttps://api.semanticscholar. org/...
2025
-
[7]
Yokoyama, S
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. InInternational Conference on Robotics and Automation (ICRA), 2024
2024
-
[8]
E. Padilla, B. Sun, M. Pollefeys, and H. Blum. Openfrontier: General navigation with visual- language grounded frontiers, 2026. URLhttps://arxiv.org/abs/2603.05377
Pith/arXiv arXiv 2026
-
[9]
Yokoyama, R
N. Yokoyama, R. Ramrakhya, A. Das, D. Batra, and S. Ha. Hm3d-ovon: A dataset and bench- mark for open-vocabulary object goal navigation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5543–5550. IEEE, 2024
2024
-
[10]
Khanna*, R
M. Khanna*, R. Ramrakhya*, G. Chhablani, S. Yenamandra, T. Gervet, M. Chang, Z. Kira, D. S. Chaplot, D. Batra, and R. Mottaghi. Goat-bench: A benchmark for multi-modal lifelong navigation. InCVPR, 2024. 9
2024
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An Open-Source Vision-Language-Action Model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Lea...
2025
-
[12]
URL https://www.roboticsproceedings.org/ rss21/p010.html
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilin- sky. $\pi {0}$: A Vision-Language-Action Flow Model for General Robot Control. In ...
-
[13]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[14]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics, 2025.URL https://arxiv. org/abs/2506.01844, 2, 1844
Pith/arXiv arXiv 2025
-
[15]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space, 2025.URL https://arxiv. org/abs/2508.07917, 2025
Pith/arXiv arXiv 2025
-
[16]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[17]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[18]
F. Yang, P. Frivik, D. Hoeller, C. Wang, C. Cadena, and M. Hutter. Spatially-enhanced recur- rent memory for long-range mapless navigation via end-to-end reinforcement learning.The International Journal of Robotics Research, page 02783649251401926, 2025
2025
-
[19]
K. Zhou, Q. Chen, D. Peng, Z. Li, X. Li, and J. Gu. Characterizing vision-language-action models across xpus: Constraints and acceleration for on-robot deployment, 2026. URL https://arxiv.org/abs/2604.24447
Pith/arXiv arXiv 2026
-
[20]
Honerkamp, M
D. Honerkamp, M. B ¨uchner, F. Despinoy, T. Welschehold, and A. Valada. Language-grounded dynamic scene graphs for interactive object search with mobile manipulation.IEEE Robotics and Automation Letters, 2024. 10
2024
-
[21]
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu. Sg-nav: online 3d scene graph prompting for llm-based zero-shot object navigation. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
2024
-
[22]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as I Can, Not as I Say: Grounding Language in Robotic Affordances.arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[23]
W. Yu, N. Gileadi, C. Fu, S. Kirmani, K.-H. Lee, M. G. Arenas, H.-T. L. Chiang, T. Erez, L. Hasenclever, J. Humplik, et al. Language to Rewards for Robotic Skill Synthesis.arXiv preprint arXiv:2306.08647, 2023
arXiv 2023
-
[24]
N. Baumann, C. Hu, P. Sivasothilingam, H. Qin, L. Xie, M. Magno, and L. Benini. Enhancing Autonomous Driving Systems With on-Board Deployed Large Language Models, 2025. URL https://arxiv.org/abs/2504.11514
arXiv 2025
-
[25]
Wijmans, A
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra. DD- PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[26]
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames.arXiv preprint arXiv:1911.00357, 2019
arXiv 1911
- [27]
-
[28]
J. Ye, D. Batra, A. Das, and E. Wijmans. Auxiliary Tasks and Exploration Enable Ob- jectGoal Navigation . In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 16097–16106, Los Alamitos, CA, USA, Oct. 2021. IEEE Computer Society. doi:10.1109/ICCV48922.2021.01581. URLhttps://doi.ieeecomputersociety. org/10.1109/ICCV48922.2021.01581
-
[29]
K. Fang, A. Toshev, L. Fei-Fei, and S. Savarese. Scene memory transformer for embodied agents in long-horizon tasks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 538–547, 2019. doi:10.1109/CVPR.2019.00063
-
[30]
D. S. Chaplot, D. Gandhi, A. Gupta, and R. Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. InIn Neural Information Processing Systems (NeurIPS), 2020
2020
-
[31]
W. Xie, H. Jiang, Y . Zhu, J. Qian, and J. Xie. Naviformer: a spatio-temporal context-aware transformer for object navigation. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artifi- cial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intel...
-
[32]
H. Wang, B. Sun, J. Xing, F. Yang, M. Hutter, D. Shah, D. Scaramuzza, and M. Pollefeys. What matters in rl-based methods for object-goal navigation? an empirical study and a unified framework, 2025. URLhttps://arxiv.org/abs/2510.01830
arXiv 2025
-
[33]
X. Yu, S. Zhang, X. Song, X. Qin, and S. Jiang. Trajectory diffusion for objectgoal naviga- tion. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385. 11
2024
-
[34]
S. K. Ramakrishnan, D. S. Chaplot, Z. Al-Halah, J. Malik, and K. Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning. InComputer Vision and Pattern Recognition (CVPR), 2022 IEEE Conference on. IEEE, 2022
2022
-
[35]
Zhang, X
S. Zhang, X. Song, Y . Bai, W. Li, Y . Chu, and S. Jiang. Hierarchical object-to-zone graph for object navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15130–15140, October 2021
2021
-
[36]
W. Yang, X. Wang, A. Farhadi, A. Gupta, and R. Mottaghi. Visual semantic navigation using scene priors. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019
2019
-
[37]
Zhang, K
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.Robotics: Science and Systems, 2024
2024
-
[38]
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Biyik, H. Yin, S. Liu, and X. Wang. NaVILA: Legged Robot Vision-Language-Action Model for Navigation. In Proceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.018
-
[39]
C. Gao, L. Jin, X. Peng, J. Zhang, Y . Deng, A. Li, H. Wang, and S. Liu. Octonav: Towards generalist embodied navigation, 2025. URLhttps://arxiv.org/abs/2506.09839
arXiv 2025
-
[40]
Zhang, A
J. Zhang, A. Li, Y . Qi, M. Li, J. Liu, S. Wang, H. Liu, G. Zhou, Y . Wu, X. LI, Y . Fan, W. Li, Z. Chen, F. Gao, Q. Wu, Z. Zhang, and H. Wang. Embodied navigation foundation model. In The Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=kkBOIsrCXh
2026
-
[41]
Zawalski, W
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=S70MgnIA0v
2024
-
[42]
Firoozi, J
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y . Zhu, S. Song, A. Kapoor, K. Hausman, et al. Foundation models in robotics: Applications, challenges, and the future. The International Journal of Robotics Research, 44(5):701–739, 2025
2025
-
[43]
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment. In8th Annual Conference on Robot Learn- ing, 2024. URLhttps://openreview.net/forum?id=fCDOfpTCzZ
2024
- [44]
-
[45]
Y . Cao, J. Zhang, Z. Yu, S. Liu, Z. Qin, Q. Zou, B. Du, and K. Xu. Cognav: Cognitive process modeling for object goal navigation with llms.arXiv preprint arXiv:2412.10439, 2024
arXiv 2024
-
[46]
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
2023
-
[47]
G. Team. Gemma 3 technical report, 2025. URLhttps://arxiv.org/abs/2503. 19786
2025
-
[48]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
-
[49]
Deepmind
G. Deepmind. Gemini 3 pro - model card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf, 2025. [Ac- cessed 28-05-2026]
2025
-
[50]
Gpt-5.4 thinking system card.https://deploymentsafety.openai.com/ gpt-5-4-thinking/gpt-5-4-thinking.pdf, 2026
OpenAI. Gpt-5.4 thinking system card.https://deploymentsafety.openai.com/ gpt-5-4-thinking/gpt-5-4-thinking.pdf, 2026. [Accessed 28-05-2026]
2026
-
[51]
Claude sonnet 4.6 system card.https://www-cdn.anthropic.com/ 78073f739564e986ff3e28522761a7a0b4484f84.pdf, 2026
Anthropic. Claude sonnet 4.6 system card.https://www-cdn.anthropic.com/ 78073f739564e986ff3e28522761a7a0b4484f84.pdf, 2026. [Accessed 28-05- 2026]
2026
-
[52]
Cheng, A
B. Cheng, A. Schwing, and A. Kirillov. Per-pixel classification is not all you need for semantic segmentation.Advances in neural information processing systems, 34:17864–17875, 2021
2021
-
[53]
J. Yang, H. Zhang, F. Li, X. Zou, C. Li, and J. Gao. Set-of-mark prompting unleashes extraor- dinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
Pith/arXiv arXiv 2023
-
[54]
J. Brussee. Caveman: A Claude Code skill that cuts output tokens by talking like a caveman. https://github.com/JuliusBrussee/caveman, 2026. Accessed: June 29, 2026
2026
- [55]
-
[56]
Y . Hu, A. Xi, Q. Xiao, S. Isaacson, H. X. Liu, R. Vasudevan, and M. Ghaffari. Longnav- r1: Horizon-adaptive multi-turn rl for long-horizon vla navigation, 2026. URLhttps:// arxiv.org/abs/2602.12351
arXiv 2026
-
[57]
Gerganov and O.-S
G. Gerganov and O.-S. Contributors. Llama.cpp.https://github.com/ggerganov/ llama.cpp, 2023. Accessed: April 2025
2023
-
[58]
Ziliotto, T
F. Ziliotto, T. Campari, L. Serafini, and L. Ballan. Tango: training-free embodied ai agents for open-world tasks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24603–24613, 2025
2025
- [59]
-
[60]
Find a chair with a person sitting on it
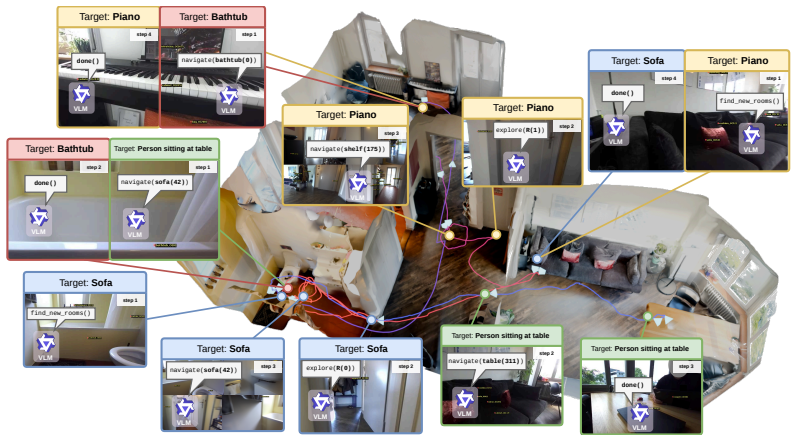
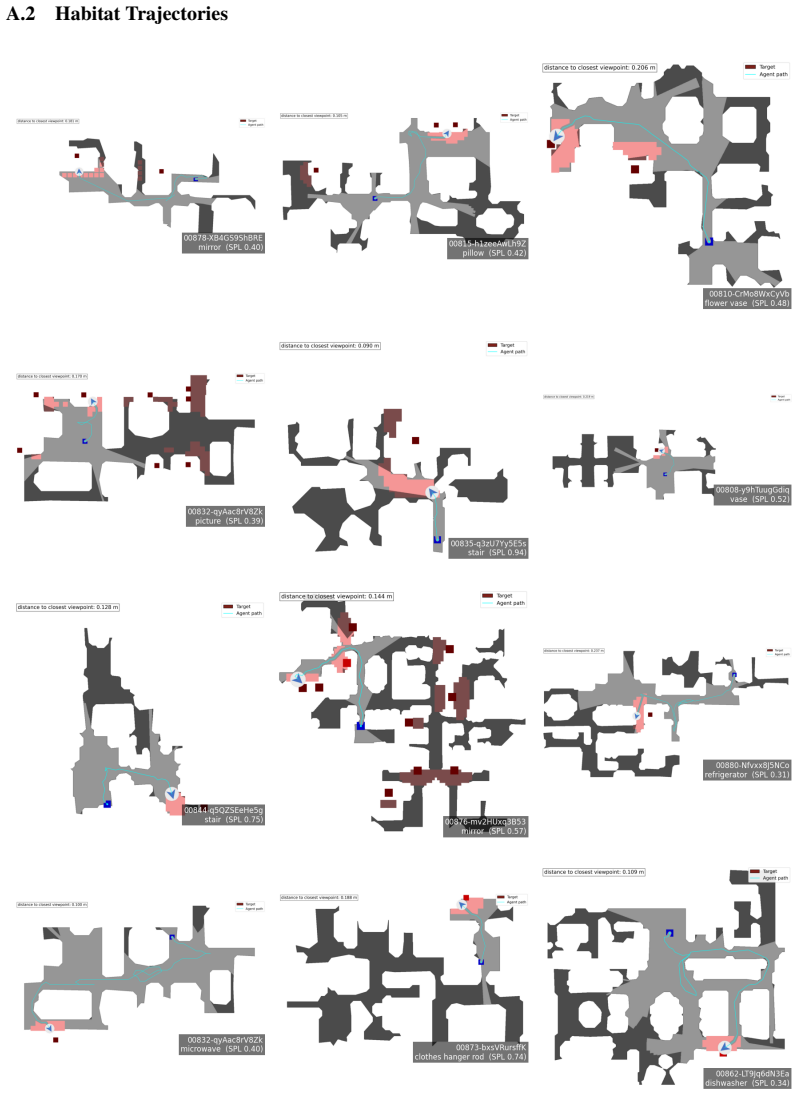
Q. Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026. A Appendix A.1 Model Input and Output Example This section aims to give an example of the VLM prompt in Figure 6, an exampleHabitatinput image in Figure 5, and the diversity of model responses in Table 4. Furthermore, this prompt-image pair and VLM response is an example from t...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.