AdvancedShelLM: A Stateful Multi-Agent LLM Honeypot for SSH Deception
Pith reviewed 2026-06-29 03:50 UTC · model grok-4.3
The pith
AdvancedShelLM uses a Manager-Worker LLM pair and permanent filesystem to influence real attacker behavior on SSH honeypots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
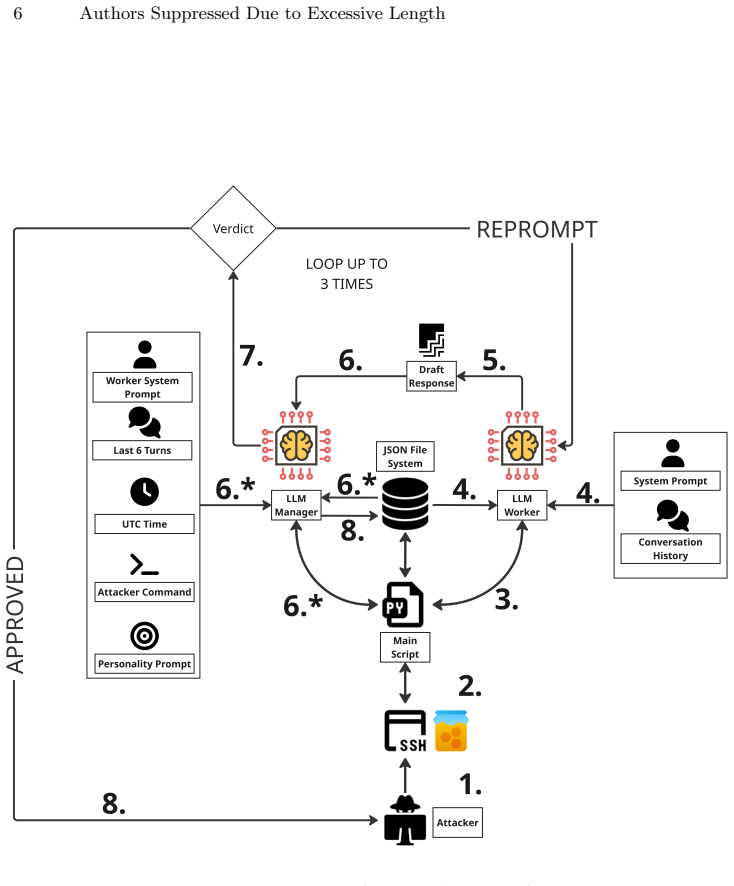
AdvancedShelLM is a multi-agent, multi-LLM architecture for SSH honeypots consisting of a Manager and Worker agent that together understand commands while reducing incorrect responses and increasing deception. It implements an advanced permanent filesystem allowing many simultaneous attackers to see the same changing files. Evaluations show up to 99.02% pass rate in unit tests, issues for an AI attacker in deciding if it is a honeypot, deception of more humans than Cowrie, and concrete evidence from internet deployment that its output influences real-life attackers' behaviour.
What carries the argument
Manager-Worker multi-agent LLM split combined with a permanent filesystem for consistent state across simultaneous attackers
If this is right
- Unit tests confirm generative capabilities with pass rates up to 99.02%.
- An AI attacker system shows difficulty distinguishing the honeypot from real systems.
- Human attackers are deceived more effectively than by the Cowrie honeypot.
- Internet deployment demonstrates that the system's outputs influence real attacker behaviour.
Where Pith is reading between the lines
- The permanent filesystem design could extend to other protocols to maintain consistent state for multi-attacker studies.
- If outputs can steer attacker actions, the approach might support active defenses that redirect adversaries toward decoy resources.
- Scaling the Manager-Worker split may reduce manual tuning needed for long-running deception systems.
Load-bearing premise
The multi-agent Manager-Worker split plus permanent filesystem will produce fewer incorrect responses and higher deception than the prior single-LLM shelLM design when facing determined attackers.
What would settle it
A side-by-side internet deployment of AdvancedShelLM and a non-LLM honeypot where attacker identification rates and behavioral patterns show no difference would falsify the influence and improvement claims.
Figures
read the original abstract
LLM-based SSH honeypots can generate believable interactions, but evaluations indicate they remain somewhat identifiable to determined attackers, indicating the need for a better scaffolding. We present a new LLM-based honeypot design that uses a multi-agent, multi-LLM architecture to address the limitations of the previous shelLM LLM honeypot. Our honeypot, called AdvancedShelLM, uses two LLM agents, a Manager and a Worker, that better understand the commands while reducing incorrect responses and increasing deception. It implements an advanced permanent filesystem, allowing many simultaneous attackers to see the same changing files for the first time. It was evaluated with: (i) unit tests for generative capabilities, (ii) an AI attacker (ARACNE) to assess realism and deception, (iii) human attackers to assess its deceptive capability, and (iv) an Internet deployment to evaluate deception in real-world attacks. In unit test results, AdvancedShelLM achieved a pass rate of up to 99.02%. The AI attacker ARACNE had issues making a decision if the system is honeypot or not, but showed slight bias towards saying honeypot, even for a real Ubuntu shell. With human attackers, AdvancedShelLM deceived more humans than Cowrie, but had similar results as shelLM. The Internet deployment showed concrete evidence that the output of AdvancedShelLM can influence the behaviour of real-life attackers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AdvancedShelLM, a multi-agent LLM-based SSH honeypot using a Manager-Worker architecture and permanent filesystem to improve on prior single-LLM designs like shelLM. It reports unit-test pass rates up to 99.02%, ARACNE AI-attacker results with honeypot bias, human-attacker deception superior to Cowrie but similar to shelLM, and internet-deployment observations that AdvancedShelLM outputs can influence real attackers.
Significance. If the multi-agent scaffolding and permanent filesystem demonstrably reduce incorrect responses and increase deception relative to baselines, the work would advance LLM honeypot design by enabling consistent state across simultaneous attackers and providing deployment evidence of behavioral influence.
major comments (3)
- [Abstract] Abstract: the human-attacker results are reported as similar to the prior shelLM design rather than showing improvement; this undercuts the central claim that the Manager-Worker split plus permanent filesystem produces fewer incorrect responses and higher deception, so the internet-deployment influence cannot be attributed to the new architecture.
- [Abstract] Abstract / evaluation sections: the deception claims (human attackers, ARACNE, deployment) supply no quantitative metrics, error bars, statistical tests, or exclusion criteria, rendering it impossible to assess whether the data support the conclusions about realism or influence on attackers.
- [Abstract] Abstract: ARACNE exhibits bias toward labeling even a real Ubuntu shell as a honeypot; this weakens the validity of the AI-attacker evaluation as a measure of the design's superiority in realistic conditions.
minor comments (1)
- [Abstract] The abstract and evaluation descriptions could more explicitly separate the contributions of the multi-agent split from those of the permanent filesystem.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments. We provide point-by-point responses to the major comments and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the human-attacker results are reported as similar to the prior shelLM design rather than showing improvement; this undercuts the central claim that the Manager-Worker split plus permanent filesystem produces fewer incorrect responses and higher deception, so the internet-deployment influence cannot be attributed to the new architecture.
Authors: The unit test results demonstrate a high pass rate of 99.02%, indicating fewer incorrect responses compared to prior designs. The permanent filesystem is a novel contribution enabling consistent state for multiple simultaneous attackers, which was not possible before. While human-attacker deception rates are similar to shelLM, the deployment provides evidence that the outputs can influence real attacker behavior. We will revise the abstract to more precisely state the contributions without overstating the human evaluation results. revision: yes
-
Referee: [Abstract] Abstract / evaluation sections: the deception claims (human attackers, ARACNE, deployment) supply no quantitative metrics, error bars, statistical tests, or exclusion criteria, rendering it impossible to assess whether the data support the conclusions about realism or influence on attackers.
Authors: We agree that the current presentation lacks sufficient quantitative details for the deception evaluations. In the revised manuscript, we will include the number of human attackers, specific deception rates, and any available statistical information. For the deployment, we will provide more detailed observations and metrics from the collected data. This addresses the need for better assessment of the conclusions. revision: yes
-
Referee: [Abstract] Abstract: ARACNE exhibits bias toward labeling even a real Ubuntu shell as a honeypot; this weakens the validity of the AI-attacker evaluation as a measure of the design's superiority in realistic conditions.
Authors: The manuscript already reports the bias in ARACNE's labeling, including for real Ubuntu shells. This is presented as a limitation of the AI-attacker approach. We will add further discussion in the evaluation section on the implications of this bias and how it affects the interpretation of the results, to clarify the validity of this evaluation method. revision: yes
Circularity Check
No circularity; purely empirical system description and evaluation
full rationale
The paper presents an engineering design for a multi-agent LLM honeypot and reports results from unit tests, an AI attacker, human attackers, and an internet deployment. No mathematical derivations, fitted parameters, or predictive claims that reduce to inputs by construction appear in the provided text. The central claim rests on observed outcomes from external evaluations rather than any self-referential loop or renamed ansatz. Self-citations to prior shelLM work, if present, are not load-bearing for any derivation since the work is descriptive and benchmarked against independent systems like Cowrie.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Splitting command understanding across two LLM agents will reduce incorrect responses relative to a single LLM
- domain assumption A permanent shared filesystem will allow consistent views for simultaneous attackers without breaking deception
Reference graph
Works this paper leans on
-
[1]
cowrie/cowrie (Jun 2026), https://github.com/cowrie/cowrie, original-date: 2015- 05-12T14:58:09Z
2026
-
[2]
Digital Ocean (Jun 2026), https://www.digitalocean.com
2026
-
[3]
Adebimpe, A., Neukirchen, H., Welsh, T.: SBASH: A framework for designing and evaluating RAG vs. prompt-tuned LLM honeypots. In: 2025 3rd Interna- tional Conference on Foundation and Large Language Models (FLLM) (2025). https://doi.org/10.1109/FLLM67465.2025.11391242
-
[4]
SoK: Honeypots & LLMs, More Than the Sum of Their Parts?
Bridges, R.A., Mitchell, T.R., Muñoz, M., Henriksson, T.: SoK: Hon- eypots & LLMs, More Than the Sum of Their Parts? (Apr 2026). https://doi.org/10.48550/arXiv.2510.25939, arXiv:2510.25939 [cs.CR]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.25939 2026
-
[5]
(eds.) Information and Communications Security
Fan, W., Yang, Z., Liu, Y., Qin, L., Liu, J.: HoneyLLM: A Large Language Model- PoweredMedium-InteractionHoneypot.In:Katsikas,S.,Xenakis,C.,Kalloniatis,C., Lambrinoudakis, C. (eds.) Information and Communications Security. pp. 253–272. Springer Nature, Singapore (2025). https://doi.org/10.1007/978-981-97-8801-9_13
-
[6]
In: 2024 IEEE International Conference on Cyber Security and Resilience (CSR)
Johnson, S., Hassing, R., Pijpker, J., Loves, R.: A modular generative honeypot shell. In: 2024 IEEE International Conference on Cyber Security and Resilience (CSR). pp. 430–435 (2024). https://doi.org/10.1109/CSR61664.2024.10679411
-
[7]
Malhotra, P.: LLMHoney: A Real-Time SSH Honeypot with Large Language Model-Driven Dynamic Response Generation (Sep 2025). https://doi.org/10.48550/arXiv.2509.01463, arXiv:2509.01463 [cs.CR] version: 1
-
[8]
McKee, F., Noever, D.: Chatbots in a honeypot world (Jan 2023), https://arxiv.org/abs/2301.03771
arXiv 2023
-
[9]
Nieponice, T., Valeros, V., Garcia, S.: ARACNE: An LLM-Based Autonomous Shell Pentesting Agent (Feb 2025), https://arxiv.org/abs/2502.18528v1
arXiv 2025
-
[10]
Otal, H.T., Canbaz, M.A.: LLM Honeypot: Leveraging Large Language Models as Advanced Interactive Honeypot Systems. In: 2024 IEEE Confer- ence on Communications and Network Security (CNS). pp. 1–6 (Sep 2024). https://doi.org/10.1109/CNS62487.2024.10735607, iSSN: 2994-5895
-
[11]
IEEE Access11, 117528– 117545 (2023)
Ragsdale, J., Boppana, R.V.: On Designing Low-Risk Honeypots Using Generative Pre-Trained Transformer Models With Curated Inputs. IEEE Access11, 117528– 117545 (2023). https://doi.org/10.1109/ACCESS.2023.3326104
-
[12]
Reworr, Volkov, D.: LLM Agent Honeypot: Monitoring AI Hacking Agents in the Wild (Feb 2025). https://doi.org/10.48550/arXiv.2410.13919, arXiv:2410.13919 [cs.CR] 18 Authors Suppressed Due to Excessive Length
-
[13]
Safargalieva, A., Rüffer, A., Vasilomanolakis, E.: OHRA: Dynamic multi-protocol LLM-based cyber deception. In: Secure IT Systems. Springer Nature (2026). https://doi.org/10.1007/978-3-032-14782-0_7
-
[14]
Strong supermartingales and limits of nonnegative martingales
Sladić, M., Valeros, V., Catania, C., Garcia, S.: LLM in the Shell: Generative Honeypots. In: 2024 IEEE European Symposium on Se- curity and Privacy Workshops (EuroS&PW). pp. 430–435 (Jul 2024). https://doi.org/10.1109/EuroSPW61312.2024.00054, iSSN: 2768-0657
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/eurospw61312.2024.00054 2024
-
[15]
Vellmes: A high- interaction ai-based deception framework
Sladić, M., Valeros, V., Catania, C., Garcia, S.: VelLMes: A High-Interaction AI-Based Deception Framework. In: 2025 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW). pp. 671–679 (Jun 2025). https://doi.org/10.1109/EuroSPW67616.2025.00082, iSSN: 2768-0657
-
[16]
Data in Brief40, 107795 (2022)
Valeros, V., Garcia, S.: Hornet 40: Network dataset of geographically placed honey- pots. Data in Brief40, 107795 (2022). https://doi.org/10.1016/j.dib.2022.107795
-
[17]
Data in Brief58, 111261 (2025)
Valeros, V., Garcia, S.: CTU Hornet 65 Niner: A network dataset of geograph- ically distributed low-interaction honeypots. Data in Brief58, 111261 (2025). https://doi.org/10.1016/j.dib.2024.111261
-
[18]
Computer Networks 282, 112223 (Jun 2026)
Wang, Z., You, J., Wang, H., Yuan, T., Lv, S., Wang, Y., Sun, L.: HoneyGPT: Break- ing the trilemma in honeypots with large language models. Computer Networks 282, 112223 (Jun 2026). https://doi.org/10.1016/j.comnet.2026.112223
-
[19]
IEEE Access12, 144579–144587 (2024)
Weber, S.B., Feger, M., Pilgermann, M.: Don’t Stop Believin’: A Unified Eval- uation Approach for LLM Honeypots. IEEE Access12, 144579–144587 (2024). https://doi.org/10.1109/ACCESS.2024.3472460
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.