Multimodal and Multiscale Spatial-Temporal Semantic Search and Recommendation with AI Foundation Models
Pith reviewed 2026-06-30 11:25 UTC · model grok-4.3
The pith
A framework using vision-language models and adaptive spatiotemporal re-ranking improves similarity search for environmental event reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
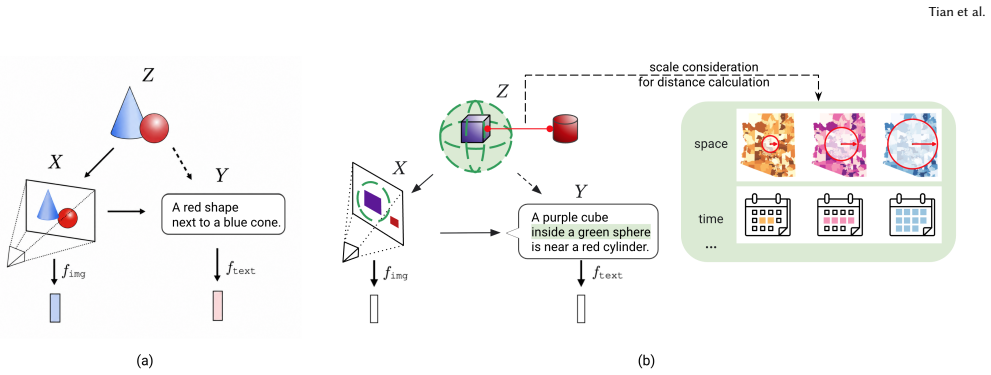
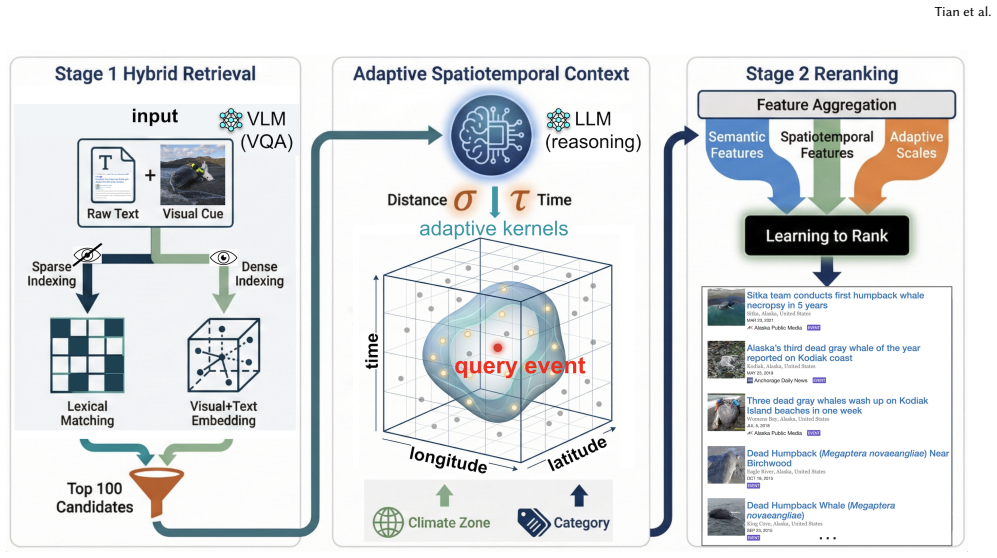
The authors claim that their VLM-enhanced methods, which use CAMERA to fuse textual and visual information for richer embeddings and ASTRA to incorporate scale-dependent spatiotemporal relevance into similarity ranking, outperform unimodal, LLM-based approaches in similarity ranking effectiveness on the Local Environmental Observer Network dataset.
What carries the argument
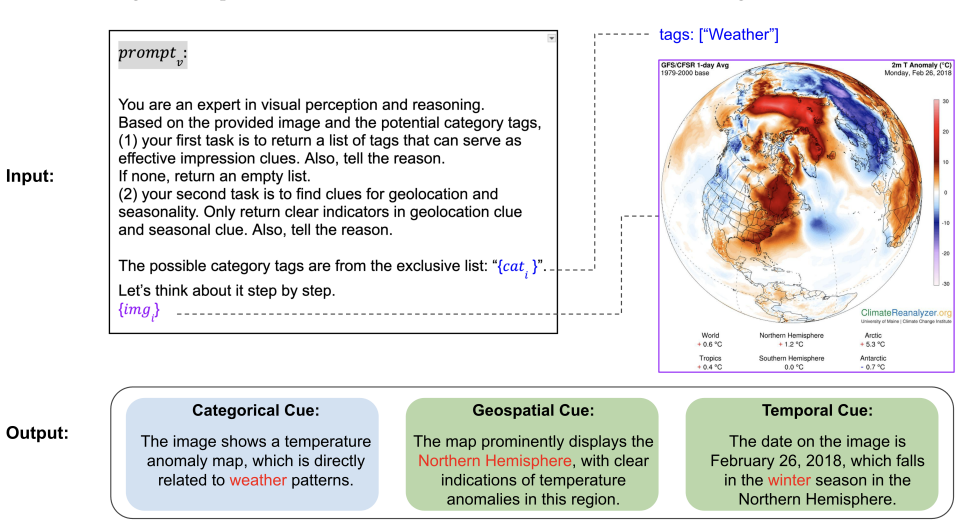
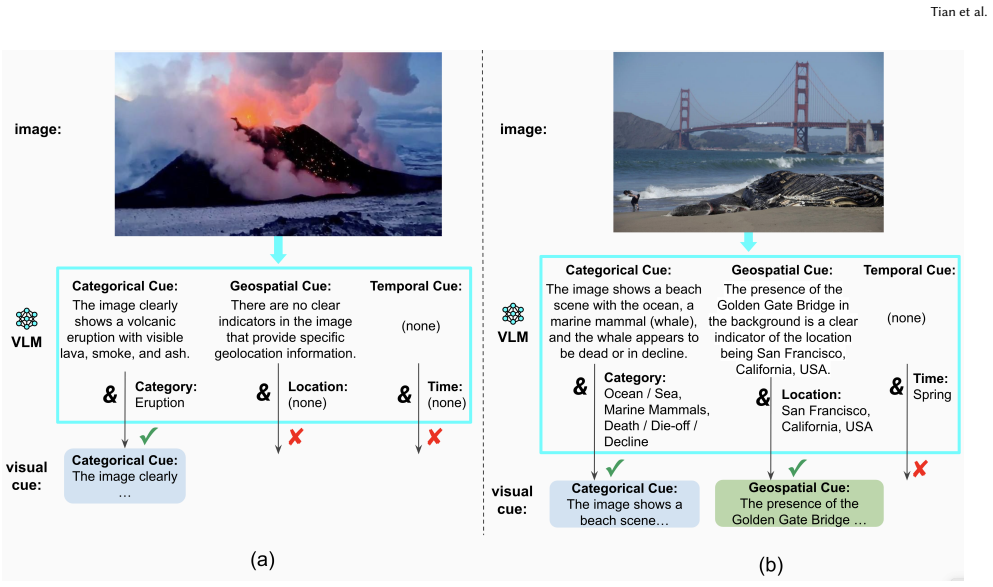
CAMERA, which fuses textual and visual information to generate richer embeddings, and ASTRA, which improves similarity ranking by adding scale-dependent spatiotemporal relevance to semantic similarity.
If this is right
- Automatically linking relevant event reports helps data curators and the public gain deeper insights into environmental change and its localized impacts.
- The framework advances geographic information retrieval by integrating space, time, scale, and semantics using AI foundation models.
- VLM-enhanced methods provide better performance than text-only LLM approaches for this type of semantic search.
- Multifaceted analysis that combines multiple geographic concepts becomes feasible with foundation models.
Where Pith is reading between the lines
- This method could extend to searching other types of spatiotemporal documents, such as news or scientific papers, beyond environmental events.
- Incorporating visual data may help when textual descriptions are vague or incomplete about the event's appearance.
- The scale-dependent aspect of ASTRA might be particularly useful for distinguishing local from regional or global events.
- Testing the framework on datasets from other geographic domains would reveal how general the improvements are.
Load-bearing premise
That combining text and images through CAMERA creates better embeddings for search and that adding scale-dependent spatiotemporal factors in ASTRA improves rankings more than semantic similarity alone.
What would settle it
Running the same experiments on the Local Environmental Observer Network dataset and finding that the VLM-enhanced methods with CAMERA and ASTRA do not outperform the unimodal LLM-based approaches in similarity ranking metrics.
Figures
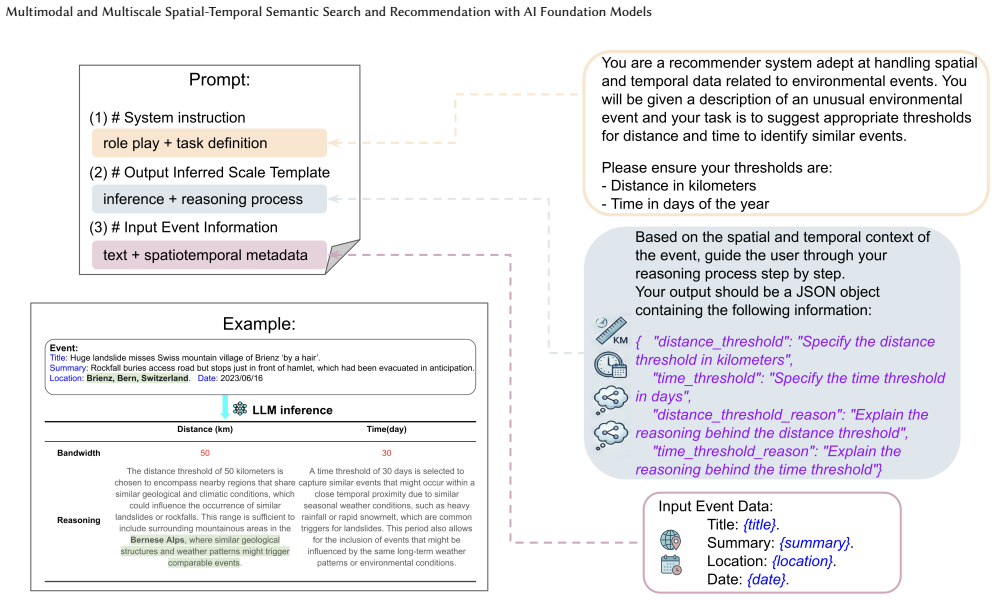
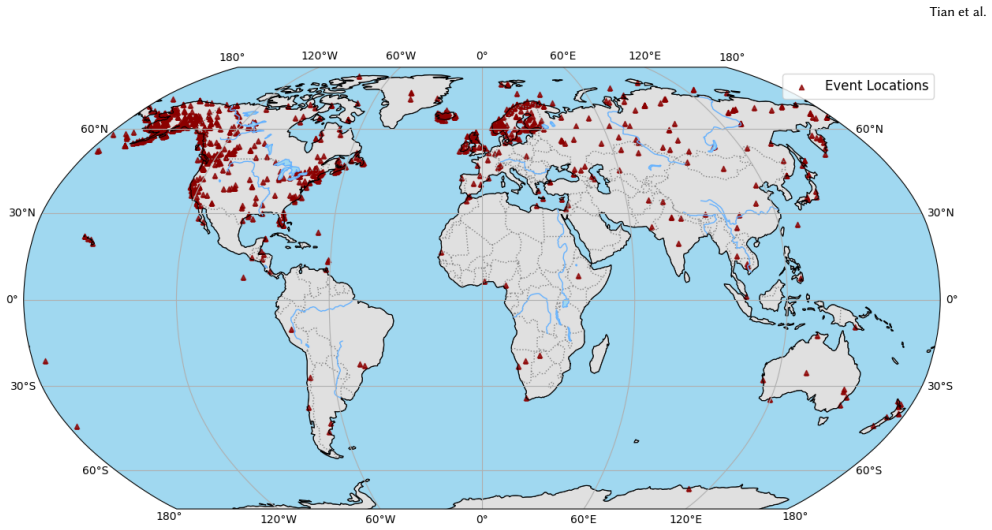
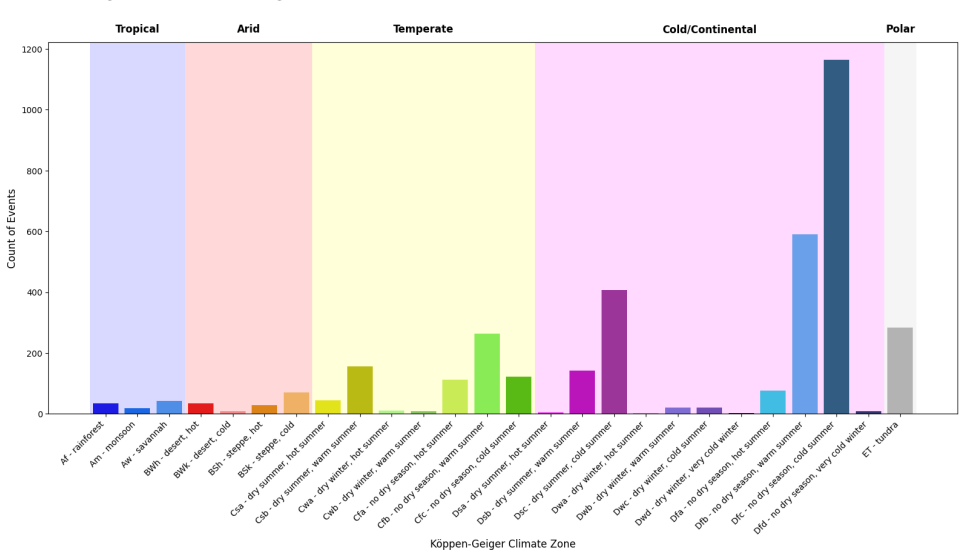
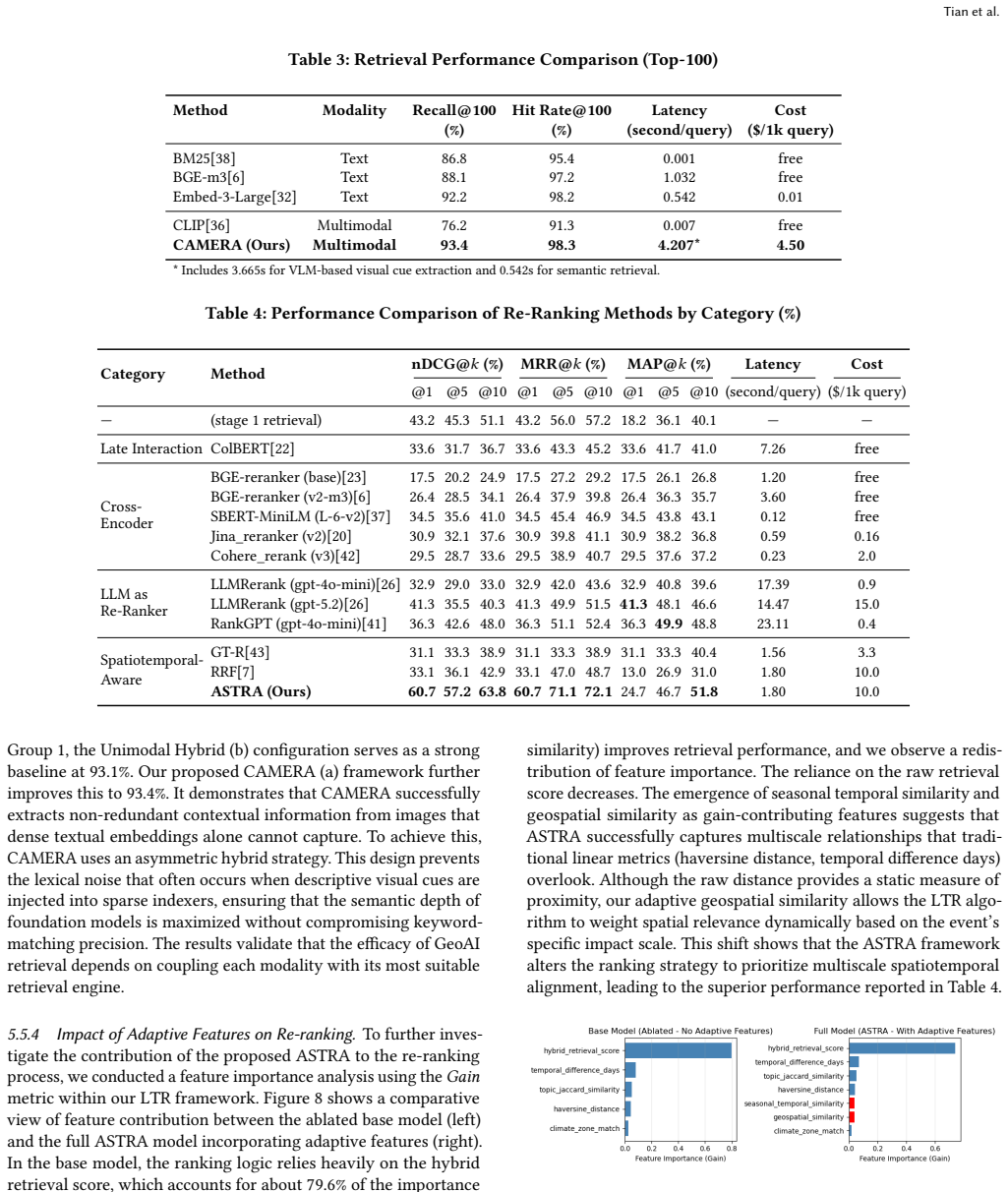
read the original abstract
Semantic search and recommendation of similar documents, such as news and reports about unusual environmental events (e.g., a dead whale washed ashore in Alaska) that contain spatial and temporal information, is a critical task in Geographic Information Retrieval (GIR). This work presents a novel framework that leverages AI foundation models, including Large Language Models (LLMs) and Vision-Language Models (VLMs), to enable effective similarity search and ranking for such event documents. To support this goal, we introduce two new strategies: (1) CAMERA (Context-Aware Multimodal Event Retrieval Algorithm), which fuses textual and visual information to generate richer embeddings than those derived from text alone; and (2) ASTRA (Adaptive Spatial and Temporal Re-ranking Algorithm), which improves similarity ranking by incorporating scale-dependent spatiotemporal relevance alongside semantic similarity. Experimental results, using a dataset from the Local Environmental Observer Network, demonstrate that our VLM-enhanced methods outperform unimodal, LLM-based approaches in similarity ranking effectiveness. By automatically linking relevant event reports, the proposed framework helps both data curators and the general public gain deeper insights into environmental change and its localized impacts. These findings highlight the potential of AI foundation models to advance GIR through multifaceted, intelligent analysis that integrates key geographic concepts: space, time, scale, and semantics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for semantic search and recommendation of environmental event documents in Geographic Information Retrieval (GIR). It introduces CAMERA, a Context-Aware Multimodal Event Retrieval Algorithm that fuses textual and visual information via VLMs to produce richer embeddings than text-only methods, and ASTRA, an Adaptive Spatial and Temporal Re-ranking Algorithm that augments semantic similarity with scale-dependent spatiotemporal relevance. The central claim is that these VLM-enhanced methods outperform unimodal LLM baselines in similarity ranking effectiveness, as demonstrated on a dataset from the Local Environmental Observer Network.
Significance. If the performance claims are substantiated with rigorous evaluation, the work would offer a concrete advance in GIR by showing how foundation models can integrate space, time, scale, and semantics for linking event reports. This could aid data curation and public understanding of localized environmental impacts. The approach is timely given the rise of multimodal models, but its significance hinges on whether the fusion and re-ranking steps deliver measurable gains beyond existing semantic methods.
major comments (3)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the claim that VLM-enhanced methods 'outperform unimodal, LLM-based approaches in similarity ranking effectiveness' is asserted without any reported metrics (e.g., NDCG, MAP, precision@K), baselines, statistical significance tests, dataset statistics, or evaluation protocol. This leaves the central empirical claim without visible support.
- [§3] §3 (CAMERA description): the assertion that fusing textual and visual information 'produces richer embeddings' is presented as self-evident; no ablation isolating the contribution of the visual modality, no comparison of embedding spaces (e.g., cosine similarity distributions), and no analysis of failure cases where visual fusion harms performance.
- [§4] §4 (ASTRA description): the claim that scale-dependent spatiotemporal relevance 'meaningfully improves ranking over semantic similarity alone' lacks a concrete formulation of the re-ranking function, the definition of 'scale-dependent' relevance, or quantitative results showing the incremental gain attributable to ASTRA versus a pure semantic baseline.
minor comments (2)
- [§4] Notation for spatiotemporal relevance in ASTRA is introduced without a formal equation or pseudocode, making it difficult to assess reproducibility.
- [Experimental Results] The LEO Network dataset is referenced but no description of its size, document characteristics, or ground-truth construction for similarity ranking is provided.
Simulated Author's Rebuttal
We thank the referee for the careful reading and specific suggestions. We agree that the current manuscript does not provide the quantitative details needed to support the central claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the claim that VLM-enhanced methods 'outperform unimodal, LLM-based approaches in similarity ranking effectiveness' is asserted without any reported metrics (e.g., NDCG, MAP, precision@K), baselines, statistical significance tests, dataset statistics, or evaluation protocol. This leaves the central empirical claim without visible support.
Authors: We acknowledge the omission. The manuscript currently states the performance claim without accompanying metrics, protocol, or statistical tests. In revision we will add a dedicated experimental section containing dataset statistics, the full evaluation protocol, baselines, NDCG/MAP/precision@K results, and significance tests. revision: yes
-
Referee: [§3] §3 (CAMERA description): the assertion that fusing textual and visual information 'produces richer embeddings' is presented as self-evident; no ablation isolating the contribution of the visual modality, no comparison of embedding spaces (e.g., cosine similarity distributions), and no analysis of failure cases where visual fusion harms performance.
Authors: We agree that the contribution of the visual modality is not isolated. We will insert ablation experiments, cosine-similarity distribution comparisons between text-only and multimodal embeddings, and a short analysis of cases in which visual fusion does not improve or degrades ranking quality. revision: yes
-
Referee: [§4] §4 (ASTRA description): the claim that scale-dependent spatiotemporal relevance 'meaningfully improves ranking over semantic similarity alone' lacks a concrete formulation of the re-ranking function, the definition of 'scale-dependent' relevance, or quantitative results showing the incremental gain attributable to ASTRA versus a pure semantic baseline.
Authors: We will expand §4 with the explicit mathematical form of the re-ranking function, a precise definition of scale-dependent relevance, and a quantitative comparison (including incremental gains) of ASTRA against a pure semantic baseline. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external dataset evaluation
full rationale
The paper introduces CAMERA (multimodal fusion) and ASTRA (spatiotemporal re-ranking) as new strategies, then reports experimental outperformance on the LEO Network dataset against LLM baselines. No equations, derivations, or self-citations are presented that reduce a claimed result to a fitted input or prior self-work by construction. The central claims are statistical comparisons on held-out data, which are falsifiable and independent of the method definitions themselves. This matches the default expectation of a non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models (LLMs and VLMs) can produce useful embeddings for documents containing spatial-temporal information
Reference graph
Works this paper leans on
-
[1]
Elise Acheson and Ross S Purves. 2021. Extracting and modeling geographic information from scientific articles.PloS one16, 1 (2021), e0244918
2021
-
[2]
Juan Carlos Augusto. 2022. Contexts and context-awareness revisited from an intelligent environments perspective.Applied Artificial Intelligence36, 1 (2022), 2008644
2022
-
[3]
Ingrid Baker, Ann Peterson, Greg Brown, and Clive McAlpine. 2012. Local government response to the impacts of climate change: An evaluation of local climate adaptation plans.Landscape and urban planning107, 2 (2012), 127–136
2012
-
[4]
Michael Brubaker, James Berner, and Moses Tcheripanoff. 2013. LEO, the Local Environmental Observer Network: a community-based system for surveillance of climate, environment, and health events.Circumpolar Health Supplements72 (2013), 513
2013
-
[5]
Christopher JC Burges. 2010. From ranknet to lambdarank to lambdamart: An overview.Learning11, 23-581 (2010), 81
2010
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. 758–759
2009
-
[8]
Seth L Danielson, Jacqueline M Grebmeier, Katrin Iken, Catherine Berchok, Lyle Britt, Kenneth H Dunton, Lisa Eisner, Edward V Farley, Amane Fujiwara, Donna DW Hauser, et al. 2022. Monitoring Alaskan Arctic Shelf ecosystems through collaborative observation networks.Oceanography35, 3/4 (2022), 198– 209
2022
-
[9]
Maarten De Rijke, Bart Van Den Hurk, Flora Salim, Alaa Al Khourdajie, Nan Bai, Renato Calzone, Declan Curran, Getnet Demil, Lesley Frew, Noah Gießing, et al
-
[10]
InACM SIGIR Forum, Vol
Report on the 1st Workshop on Information Retrieval for Climate Impact (MANILA24) at SIGIR 2024. InACM SIGIR Forum, Vol. 59. ACM New York, NY, USA, 1–23
2024
-
[11]
Jonathan Ensor and Blane Harvey. 2015. Social learning and climate change adap- tation: evidence for international development practice.Wiley Interdisciplinary Reviews: Climate Change6, 5 (2015), 509–522
2015
-
[12]
A Stewart Fotheringham, Chris Brunsdon, and Martin Charlton. 2009. Geo- graphically weighted regression.The Sage handbook of spatial analysis1 (2009), 243–254
2009
-
[13]
Auroop R Ganguly and Karsten Steinhaeuser. 2008. Data mining for climate change and impacts. In2008 IEEE international conference on data mining work- shops. IEEE, 385–394
2008
-
[14]
David L Griffith, Lilian Alessa, and Andrew Kliskey. 2018. Community-based observing for social–ecological science: lessons from the Arctic.Frontiers in Ecology and the Environment16, S1 (2018), S44–S51
2018
-
[15]
Yingjie Hu, Krzysztof Janowicz, Sathya Prasad, and Song Gao. 2015. Metadata topic harmonization and semantic search for linked-data-driven geoportals: A case study using ArcGIS Online.Transactions in GIS19, 3 (2015), 398–416
2015
-
[16]
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. 2024. Position: The platonic representation hypothesis. InForty-first International Conference on Machine Learning
2024
-
[17]
Krzysztof Janowicz, Song Gao, Grant McKenzie, Yingjie Hu, and Budhendra Bhaduri. 2020. GeoAI: spatially explicit artificial intelligence techniques for geographic knowledge discovery and beyond. 625–636 pages
2020
-
[18]
Krzysztof Janowicz, Pascal Hitzler, Wenwen Li, Dean Rehberger, Mark Schild- hauer, Rui Zhu, Cogan Shimizu, Colby Fisher, Ling Cai, Gengchen Mai, et al
-
[19]
Know, Know Where, KnowWhereGraph: A densely connected, cross- domain knowledge graph and geo-enrichment service stack for applications in environmental intelligence.AI Magazine43, 1 (2022), 30–39
2022
-
[20]
Krzysztof Janowicz, Martin Raubal, and Werner Kuhn. 2011. The semantics of similarity in geographic information retrieval.Journal of Spatial Information Science2 (2011), 29–57
2011
-
[21]
Yuhan Ji, Song Gao, Ying Nie, Ivan Majić, and Krzysztof Janowicz. 2025. Founda- tion models for geospatial reasoning: assessing the capabilities of large language models in understanding geometries and topological spatial relations.Interna- tional Journal of Geographical Information Science38, 1 (2025)
2025
-
[22]
Jina.ai. 2026. jina-reranker-v2-base-multilingual. https://huggingface.co/jinaai/ jina-reranker-v2-base-multilingual
2026
-
[23]
Likith Anoop Kadiyala, Omer Mermer, Dinesh Jackson Samuel, Yusuf Sermet, and Ibrahim Demir. 2024. The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT.Hydrology11, 9 (2024), 148
2024
-
[24]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
- [25]
-
[26]
Wenwen Li. 2020. GeoAI: Where machine learning and big data converge in GIScience.Journal of Spatial Information Science20 (2020), 71–77
2020
-
[27]
Wenwen Li, Samantha Arundel, Song Gao, Michael Goodchild, Yingjie Hu, Shaowen Wang, and Alexander Zipf. 2024. GeoAI for Science and the Science of GeoAI.Journal of Spatial Information Science29 (2024)
2024
-
[28]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al
-
[29]
Holistic evaluation of language models.arXiv preprint arXiv:2211.09110 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. 2024. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions.Comput. Surveys56, 10 (2024), 1–42
2024
- [31]
-
[32]
Bruno Martins and Pável Calado. 2010. Learning to rank for geographic infor- mation retrieval. Inproceedings of the 6th workshop on geographic information retrieval. 1–8
2010
-
[33]
Stuart E Middleton, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and Yian- nis Kompatsiaris. 2018. Location extraction from social media: Geoparsing, location disambiguation, and geotagging.ACM Transactions on Information Systems (TOIS)36, 4 (2018), 1–27
2018
-
[34]
Emily Mosites, Erica Lujan, Michael Brook, Michael Brubaker, Desirae Roehl, Moses Tcheripanoff, and Thomas Hennessy. 2018. Environmental observation, social media, and One Health action: A description of the Local Environmental Observer (LEO) Network.One Health6 (2018), 29–33
2018
-
[35]
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al
-
[36]
Text and code embeddings by contrastive pre-training.arXiv preprint arXiv:2201.10005(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Taylor M Oshan, Levi J Wolf, Mehak Sachdeva, Sarah Bardin, and A Stewart Fotheringham. 2022. A scoping review on the multiplicity of scale in spatial analysis.Journal of Geographical Systems24, 3 (2022), 293–324. Multimodal and Multiscale Spatial-Temporal Semantic Search and Recommendation with AI Foundation Models
2022
-
[38]
Ross Purves and Christopher Jones. 2011. Geographic information retrieval. SIGSPATIAL Special3, 2 (2011), 2–4
2011
-
[39]
Ross S Purves, Paul Clough, Christopher B Jones, Mark H Hall, Vanessa Murdock, et al. 2018. Geographic information retrieval: Progress and challenges in spatial search of text.Foundations and Trends®in Information Retrieval12, 2-3 (2018), 164–318
2018
-
[40]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[41]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[42]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval 3, 4 (2009), 333–389
2009
-
[44]
Sonia I Seneviratne, Xuebin Zhang, Muhammad Adnan, Wafae Badi, Claudine Dereczynski, A Di Luca, Subimal Ghosh, Iskhaq Iskandar, James Kossin, Sophie Lewis, et al. 2021. Weather and climate extreme events in a changing climate. (2021)
2021
-
[45]
Hu Shao, Yi Zhang, and Wenwen Li. 2017. Extraction and analysis of city’s tourism districts based on social media data.Computers, Environment and Urban Systems65 (2017), 66–78
2017
- [46]
-
[47]
Sylvie Shi, Nils Reimers. 2024. Rerank 3: Efficient Enterprise Search & Retrieval. https://cohere.com/blog/rerank-3
2024
-
[48]
Yuanyuan Tian, Wenwen Li, Lei Hu, Xiao Chen, Michael Brook, Michael Brubaker, Fan Zhang, and Anna K Liljedahl. 2025. Advancing Large Language Models for Spatiotemporal and Semantic Association Mining of Similar Environmental Events.Transactions in GIS29, 1 (2025), e13282
2025
-
[49]
Siqin Wang, Tao Hu, Huang Xiao, Yun Li, Ce Zhang, Huan Ning, Rui Zhu, Zhenlong Li, and Xinyue Ye. 2024. GPT, large language models (LLMs) and generative artificial intelligence (GAI) models in geospatial science: a systematic review.International Journal of Digital Earth17, 1 (2024), 2353122
2024
-
[50]
Kohei Watanabe. 2018. Newsmap: A semi-supervised approach to geographical news classification.Digital Journalism6, 3 (2018), 294–309
2018
-
[51]
Chuhan Wu, Fangzhao Wu, Tao Qi, Chao Zhang, Yongfeng Huang, and Tong Xu
-
[52]
InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval
Mm-rec: Visiolinguistic model empowered multimodal news recommenda- tion. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 2560–2564
-
[53]
Meiliu Wu, Qunying Huang, and Song Gao. 2025. Advancing vision-language models with spatial-context prompt tuning: a case study in GeoAI-empowered image geo-localization.Journal of Location Based Services(2025), 1–21
2025
-
[54]
Gengyuan Zhang, Yurui Zhang, Kerui Zhang, and Volker Tresp. 2024. Can vision-language models be a good guesser? exploring vlms for times and location reasoning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 636–645
2024
-
[55]
Wayne Xin Zhao, Jing Liu, Ruiyang Ren, and Ji-Rong Wen. 2024. Dense text retrieval based on pretrained language models: A survey.ACM Transactions on Information Systems42, 4 (2024), 1–60
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.