IMCBench: A benchmark for multimodal LLMs in Image-grounded Medical Conversations
Pith reviewed 2026-06-30 00:44 UTC · model grok-4.3
The pith
Accurate clinical descriptions from multimodal medical AIs do not ensure safe patient guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
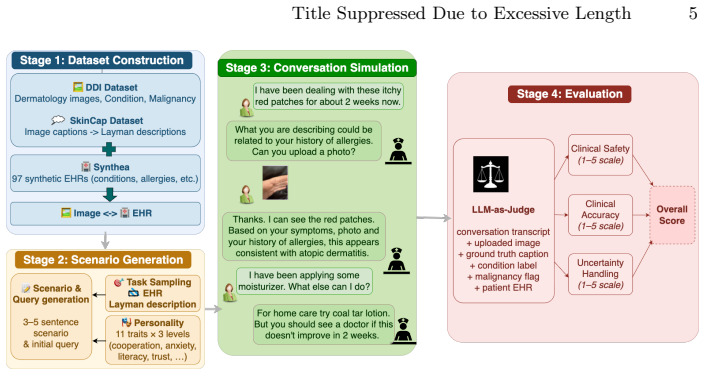
IMCBench pairs real clinical images with synthetic patient profiles to create multi-turn conversations that test multimodal models on safety, accuracy, and uncertainty; benchmark results show no model dominates all dimensions, safety drops for malignant and rare cases, and both visual input and EHR context improve safe guidance, establishing that accurate clinical description does not guarantee safe patient guidance.
What carries the argument
IMCBench benchmark, which generates multi-turn image-grounded medical conversations scored on safety, accuracy, and uncertainty using LLM-as-Jury calibrated to clinician annotations.
If this is right
- Multi-dimensional evaluation is required because single metrics like accuracy miss safety shortfalls.
- Safety performance varies by case type, with consistent drops for malignant and rare conditions.
- Visual input and EHR context each contribute measurably to safer model guidance.
- Stronger models extract more value from visual features than weaker ones do.
Where Pith is reading between the lines
- The benchmark could be used to track progress as models improve their handling of uncertainty in ambiguous cases.
- Deployment of these models in real settings would likely require additional guardrails or human oversight for high-risk conditions.
- Extending the test set to include more diverse patient demographics might expose further safety variations.
Load-bearing premise
The synthetic patient profiles paired with real clinical images simulate realistic patient-clinician interactions sufficiently for reliable evaluation of safety, accuracy, and uncertainty.
What would settle it
Direct comparison of model outputs on the benchmark cases against real clinician responses to the same image-profile pairs would show whether safety and accuracy scores match observed clinical practice.
Figures
read the original abstract
Recent advances in large language models and vision-language models have enabled reasoning over multimodal data, offering opportunities for clinical applications such as decision support and triaging. However, existing medical AI benchmarks are fragmented: some support multi-turn dialogues but lack images, while others provide multimodal inputs but focus on single-turn QA tasks. To address this gap, we introduce IMCBench, an image-grounded, multi-turn medical conversation benchmark that pairs real, publicly available clinical images with synthetic patient profiles to simulate realistic patient-clinician interactions. Each conversation is evaluated across three clinical dimensions: safety, accuracy, and appropriate use of uncertainty in diagnosis. We benchmark eight multimodal frontier models across four model families (Claude, GPT, Nova, and Llama), scoring each on a 1-5 scale using LLM-as-Jury scoring calibrated against expert clinician annotations. Our results show that Claude Opus 4.6 achieves the highest overall score (3.61), followed by Claude Sonnet 4.6 (3.30) and GPT-5.2 (3.29), though no model dominates all dimensions and safety degrades for both malignant and rare conditions ($\Delta$ = -0.27 each). Ablation studies further reveal that both visual input and EHR context contribute to safe guidance (safety drops of 0.18 and 0.23 on average when each is removed), with stronger models leveraging visual features more effectively. Together, these findings demonstrate that accurate clinical description does not guarantee safe patient guidance, motivating the need for multi-dimensional evaluation frameworks in medical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IMCBench, a benchmark pairing real publicly available clinical images with synthetic patient profiles to create multi-turn image-grounded medical conversations. It evaluates eight multimodal LLMs across four families (Claude, GPT, Nova, Llama) on three dimensions—safety, accuracy, and appropriate uncertainty use—via LLM-as-Jury scoring calibrated against expert clinician annotations. Results indicate Claude Opus 4.6 leads with an overall score of 3.61, followed by Claude Sonnet 4.6 (3.30) and GPT-5.2 (3.29); safety degrades by Δ = -0.27 on malignant and rare conditions; ablations show average safety drops of 0.18 and 0.23 when visual input or EHR context is removed. The central claim is that accurate clinical description does not guarantee safe patient guidance, motivating multi-dimensional evaluation frameworks.
Significance. If the dissociation between accuracy and safety holds under realistic conditions, the work is significant for medical AI evaluation by providing concrete evidence that single-dimension metrics are insufficient, especially for high-risk malignant/rare cases. The use of real images, expert-calibrated LLM jury, and quantified ablation deltas (0.18, 0.23, 0.27) are strengths that support falsifiable claims about context contributions. This could inform safer model development and benchmark design, though dependent on the fidelity of the synthetic profiles.
major comments (2)
- [Abstract and benchmark construction section] Abstract and benchmark construction section: The claim that synthetic patient profiles 'simulate realistic patient-clinician interactions' is load-bearing for the central dissociation between accuracy and safety, yet the manuscript provides no quantitative validation (e.g., comparison of turn length, cooperation level, or medical literacy against real dialogues) or error analysis of profile generation; without this, the reported safety degradation (Δ = -0.27) on malignant/rare conditions cannot be confidently attributed to model behavior rather than profile artifacts.
- [Ablation studies] Ablation studies: The reported safety drops (0.18 for visual removal, 0.23 for EHR removal) are interpreted as evidence that both inputs contribute to safe guidance, but the paper does not confirm that patient-side dialogue turns remain fixed and identically realistic across ablated conditions; any change in patient behavior would confound the separability of the three evaluation dimensions and weaken the multi-dimensional framework claim.
minor comments (2)
- The exact prompts and few-shot examples used for the LLM-as-Jury scorer should be included in an appendix to support reproducibility of the calibrated 1-5 scores.
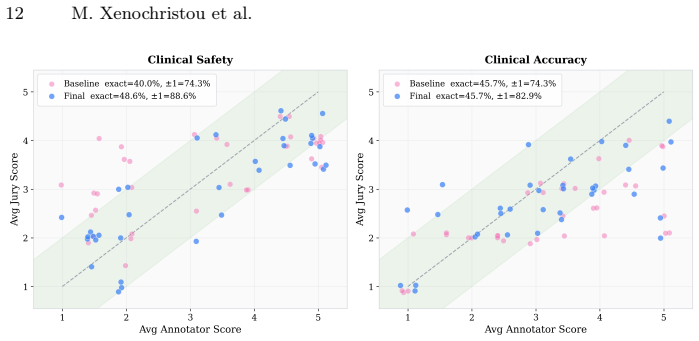
- Table or figure reporting per-dimension scores for all eight models would clarify the statement that 'no model dominates all dimensions.'
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. These points help clarify the evidentiary basis for our claims about synthetic profiles and ablation design. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and benchmark construction section] Abstract and benchmark construction section: The claim that synthetic patient profiles 'simulate realistic patient-clinician interactions' is load-bearing for the central dissociation between accuracy and safety, yet the manuscript provides no quantitative validation (e.g., comparison of turn length, cooperation level, or medical literacy against real dialogues) or error analysis of profile generation; without this, the reported safety degradation (Δ = -0.27) on malignant/rare conditions cannot be confidently attributed to model behavior rather than profile artifacts.
Authors: We agree that the absence of quantitative validation for the synthetic profiles is a limitation that weakens attribution of the safety degradation. The profiles were derived from real clinical image metadata and standard medical dialogue templates, but the manuscript does not include direct statistical comparisons or error analysis. In revision we will add (i) an error analysis of profile generation and (ii) quantitative comparisons of turn length, lexical diversity, and cooperation indicators against publicly available real medical dialogue corpora. These additions will be placed in the benchmark construction section and will allow readers to assess whether profile artifacts could explain the Δ = -0.27 safety drop. revision: yes
-
Referee: [Ablation studies] Ablation studies: The reported safety drops (0.18 for visual removal, 0.23 for EHR removal) are interpreted as evidence that both inputs contribute to safe guidance, but the paper does not confirm that patient-side dialogue turns remain fixed and identically realistic across ablated conditions; any change in patient behavior would confound the separability of the three evaluation dimensions and weaken the multi-dimensional framework claim.
Authors: The patient simulator is implemented as a fixed, independent module whose responses are generated once from the patient profile and then reused verbatim across all ablation conditions. Only the clinician model's input context (visual features or EHR) is altered; the patient turns therefore remain identical. We will add an explicit statement, together with a short pseudocode description of the ablation pipeline, in the ablation studies section to document this fixed-patient design and thereby confirm that the reported safety deltas isolate the contribution of each input modality. revision: yes
Circularity Check
No circularity: empirical benchmark with external calibration
full rationale
The paper constructs IMCBench by pairing real images with synthetic profiles and evaluates eight models on safety/accuracy/uncertainty using LLM-as-Jury scores calibrated directly against expert clinician annotations. Reported results consist of concrete empirical deltas (e.g., safety drops of 0.18/0.23 on ablations, -0.27 on malignant/rare cases) rather than any fitted parameter renamed as prediction, self-definitional equation, or load-bearing self-citation. The claim that accurate description does not guarantee safe guidance follows from the observed separation of dimension scores on externally annotated data, with no reduction of outputs to the benchmark's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic patient profiles paired with real clinical images can simulate realistic patient-clinician interactions for safety, accuracy, and uncertainty evaluation.
Reference graph
Works this paper leans on
-
[1]
Arora,R.K.,Wei,J.,Hicks,R.S.,Bowman,P.,Quiñonero-Candela,J.,Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., Heidecke, J., Singhal, K.: Healthbench: Evaluating large language models towards improved human health (2025),https://arxiv.org/abs/2505.08775
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Science Advances8(32), eabq6147 (2022).https://doi.org/10
Daneshjou, R., Vodrahalli, K., Novoa, R.A., Jenkins, M., Liang, W., Rotemberg, V., Ko, J., Swetter, S.M., Bailey, E.E., Gevaert, O., Mukherjee, P., Phung, M., Yekrang,K.,Fong,B.,Sahasrabudhe,R.,Allerup,J.A.C.,Okata-Karigane,U.,Zou, J., Chiou, A.S.: Disparities in dermatology AI performance on a diverse, curated clinical image set. Science Advances8(32), e...
2022
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Groh, M., Harris, C., Soenksen, L., Lau, F., Han, R., Kim, A., Koochek, A., Badri, O.: Evaluating deep neural networks trained on clinical images in dermatology with the Fitzpatrick 17k dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 1820–1828 (2021)
2021
-
[4]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hu, Y., Li, T., Lu, Q., Shao, W., He, J., Qiao, Y., Luo, P.: OmniMedVQA: A new large-scale comprehensive evaluation benchmark for medical LVLM. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22170–22183 (2024)
2024
-
[5]
Li, Z., Zou, C., Ma, S., Yang, Z., Du, C., Tang, Y., Cao, Z., Zhang, N., Lai, J.H., Lin, R.S., Ni, Y., Sun, X., Xiao, J., Hou, J., Zhang, K., Han, M.: ZALM3: Zero-shot enhancement of vision-language alignment via in-context information in multi-turn multimodal medical dialogue (2024),https://arxiv.org/abs/2409.17610
-
[6]
In: Proceedings of the 31st International Con- ference on Computational Linguistics
Liu, R., Xue, K., Zhang, X., Zhang, S.: Interactive evaluation for medical LLMs via task-oriented dialogue system. In: Proceedings of the 31st International Con- ference on Computational Linguistics. pp. 4871–4896. Association for Computa- tional Linguistics, Abu Dhabi, UAE (Jan 2025),https://aclanthology.org/2025. coling-main.325/
2025
-
[7]
Matos, J., Chen, S., Placino, S., Li, Y., Climent Pardo, J.C., Idan, D., Tohyama, T., Restrepo, D., Nakayama, L.F., Pascual-Leone, J.M.M., Savova, G., Aerts, H., Celi, L.A., Wong, A.I., Bitterman, D.S., Gallifant, J.: WorldMedQA-V: a multi- lingual, multimodal medical examination dataset for multimodal language models evaluation. In: Findings of the Assoc...
2025
-
[8]
doi:10.1038/s41586-023-05881-4 (2023)
Moor, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Leskovec, J., Topol, E.J., Rajpurkar, P.: Foundation models for generalist medical artificial intelligence. Na- ture616(7956), 259–265 (2023).https://doi.org/10.1038/s41586-023-05881-4
-
[9]
IEEE Access (2025)
Öğdü, Ç.U., Arslanoğlu, K., Karaköse, M.: An adaptive multi-agent llm-based clinical decision support system integrating biomedical rag and web intelligence. IEEE Access (2025)
2025
-
[10]
OpenAI: Introducing ChatGPT health.https://openai.com/index/ introducing-chatgpt-health/(Jan 2026), openAI blog post
2026
- [11]
-
[12]
Rao, V.M., Hla, M., Moor, M., Adithan, S., Kwak, S., Topol, E.J., Rajpurkar, P.: Multimodal generative AI for medical image interpretation. Nature639(8056), 18 M. Xenochristou et al. 888–896 (2025).https://doi.org/10.1038/s41586-025-08675-y,https://www. nature.com/articles/s41586-025-08675-y
-
[13]
Shi, X., Liu, Z., Wang, C., Leng, H., Xue, K., Zhang, X., Zhang, S.: MidMed: Towards mixed-type dialogues for medical consultation. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8145–8157. Association for Computational Linguistics, Toronto, Canada (Jul 2023).https://doi.org/10.1865...
-
[14]
Nature620(7972), 172–180 (2023).https://doi.org/10.1038/ s41586-023-06291-2
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., et al.: Large language models encode clin- ical knowledge. Nature620(7972), 172–180 (2023).https://doi.org/10.1038/ s41586-023-06291-2
2023
- [15]
-
[16]
In: Proceed- ings of the 2025 Conference on Empirical Methods in Natural Language Process- ing
Sviridov, I., Miftakhova, A., Tereshchenko, A., Zubkova, G., Blinov, P., Savchenko, A.: 3MDBench: Medical multimodal multi-agent dialogue benchmark. In: Proceed- ings of the 2025 Conference on Empirical Methods in Natural Language Process- ing. pp. 26614–26654. Association for Computational Linguistics, Suzhou, China (Nov 2025).https://doi.org/10.18653/v1...
-
[17]
Tschandl, P., Rosendahl, C., Kittler, H.: The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific Data5, 180161 (2018).https://doi.org/10.1038/sdata.2018.161
-
[18]
Nature642, 442–450 (2025).https: //doi.org/10.1038/s41586-025-08866-7
Tu, T., Palepu, A., Schaekermann, M., Saab, K., Freyberg, J., Tanno, R., Wang, A., Li, B., Amin, M., Tomasev, N., Azizi, S., Singhal, K., Cheng, Y., Hou, L., Webson, A., Kulkarni, K., Mahdavi, S.S., Semturs, C., Gottweis, J., Barral, J., Chou,K.,Corrado,G.S.,Matias,Y.,Karthikesalingam,A.,Natarajan,V.:Towards conversational diagnostic artificial intelligen...
-
[19]
Walonoski, J., Kramer, M., Nichols, J., Quina, A., Moesel, C., Hall, D., Duffett, C., Dube, K., Gallagher, T., McLachlan, S.: Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. Journal of the American Medical Informatics Association25(3), 230–238 (2018).https://doi.org/10...
-
[20]
Xu, R., Huang, Z., Wei, Y., Zhou, X., Xu, Z., Liu, T., Jiang, Z., Zhou, S.K.: Medatlas: Evaluating llms for multi-round, multi-task medical reasoning across diverse imaging modalities and clinical text (2025),https://arxiv.org/abs/2508. 10947
2025
-
[21]
In: Proceedings of the 6th Clinical Natural Language Pro- cessing Workshop
Yim, W.w., Ben Abacha, A., Fu, Y., Sun, Z., Xia, F., Yetisgen, M., Krallinger, M.: Overview of the MEDIQA-M3G 2024 shared task on multilingual multimodal med- ical answer generation. In: Proceedings of the 6th Clinical Natural Language Pro- cessing Workshop. pp. 581–589. Association for Computational Linguistics, Mexico City, Mexico (Jun 2024).https://doi...
-
[22]
Zhou, J., Sun, L., Xu, Y., Liu, W., Afvari, S., Han, Z., Song, J., Ji, Y., He, X., Gao, X.: SkinCAP: A multi-modal dermatology dataset annotated with rich medical captions (2024).https://doi.org/10.48550/arXiv.2405.18004 Title Suppressed Due to Excessive Length 19 Supplementary Material 5.2 Conversation Generation We construct an evaluation dataset of 1,2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.