Virtual Ring Try-On
Pith reviewed 2026-06-30 09:35 UTC · model grok-4.3
The pith
A mobile app uses hand landmark detection and ring object detection to overlay a correctly rotated and resized virtual ring on a user's hand photo.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
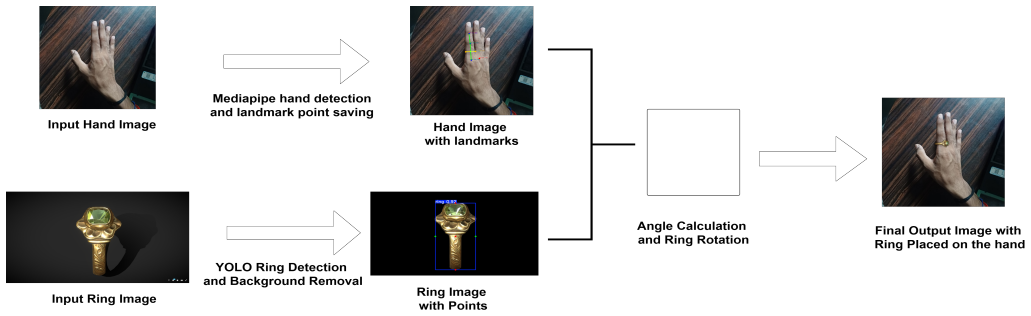
The central claim is that MediaPipe hand point detection combined with YOLO-V8 ring detection, followed by vector algebra to compute angular discrepancy between finger axis and ring axis and rescaling according to finger thickness while preserving aspect ratio, produces an output image with the ring placed on the user's hand.
What carries the argument
The pipeline of MediaPipe hand point detection to generate a region of interest, YOLO-V8 to extract the ring without background, vector algebra for angular alignment, and thickness-based rescaling for realistic placement.
If this is right
- The ring is rotated to align its principal axis with the finger's reference axis.
- The ring is rescaled to the measured finger thickness while keeping its original aspect ratio.
- The ring's background is removed so only the jewel appears on the hand image.
- The final composite is displayed directly in the mobile app interface.
Where Pith is reading between the lines
- The same detection-plus-vector steps could be reused for other narrow accessories such as bracelets if the region-of-interest logic is adjusted.
- Static single-image input leaves open the question of how the method would behave under continuous camera motion or changing hand poses.
- Because no error metrics are supplied, the approach's sensitivity to lighting, skin tone, or ring shape remains untested.
Load-bearing premise
The detections from MediaPipe and YOLO-V8 are accurate enough that the subsequent vector rotation and thickness scaling produce a perceptually realistic ring placement.
What would settle it
Take a photo of a real ring worn on a finger, run the app on the same bare-hand photo with the same ring image, and check whether the overlaid ring matches the real ring's position, angle, and size.
Figures

read the original abstract
This paper presents an innovative approach that enables the users to capture their hand and try the jewel ring on their hand. The user captures the image of the hand using the React Native base GUI of the mobile application and selects the ring that the user wants to try, and the output image will have the user's hand with the ring image. This approach is implemented using a combination of MediaPipe hand point detection and YOLO-V8 custom object detection. The hand image uploaded by the user first undergoes mediapipe hand point detection. It will give the hand points and a Region of Interest mask where the ring is going to be placed. Then the ring is passed through YOLO object detection, in which ring points are detected, and background is removed. After that, using vector algebra, the angular discrepancy between the finger's reference axis and the ring's principal axis is computed. Also, ring size is rescaled according to finger thickness, preserving the aspect ratio to maintain perceptual realism. Then the ring is placed on the hand image and the output image is generated and shown on the user screen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a mobile application pipeline for virtual ring try-on: a user captures a hand image via a React Native GUI, MediaPipe detects hand landmarks and generates a ROI mask, YOLOv8 detects and segments the selected ring, vector algebra computes the angular discrepancy between the finger reference axis and ring principal axis, the ring is rescaled according to finger thickness while preserving aspect ratio, and the transformed ring is overlaid on the hand image.
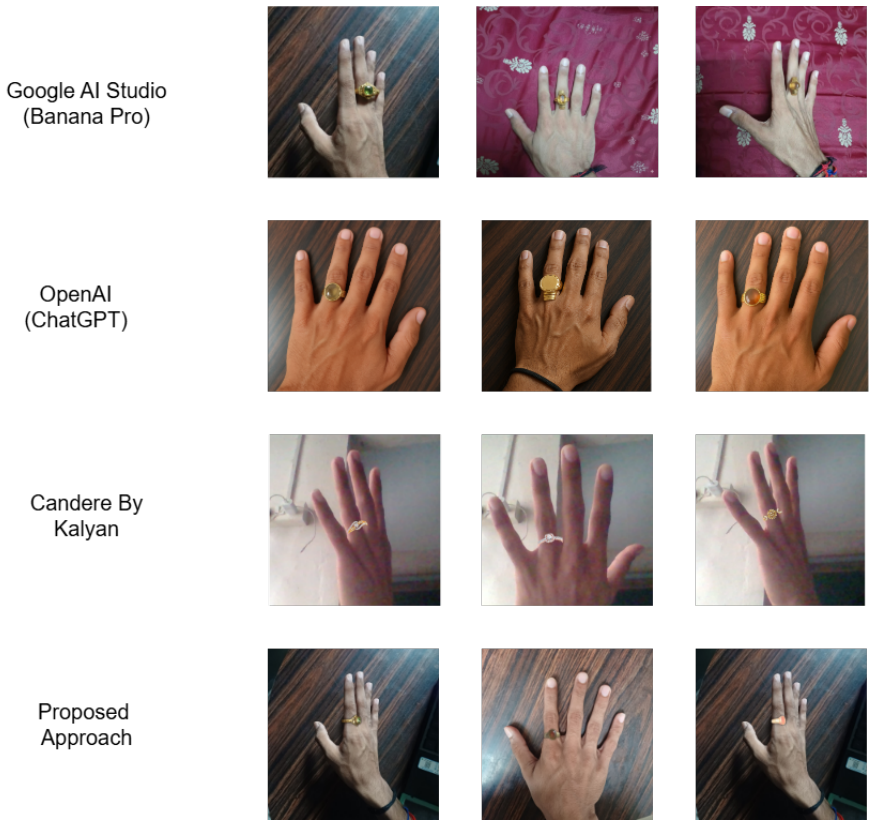
Significance. A validated implementation of this pipeline could provide a practical, lightweight on-device solution for virtual jewelry try-on in mobile e-commerce. However, the complete absence of any quantitative or qualitative evaluation means the work does not yet demonstrate a measurable advance over existing AR try-on techniques.
major comments (2)
- [Abstract] Abstract: the claim that the described transformations 'preserve perceptual realism' is load-bearing for the paper's contribution, yet the manuscript supplies no quantitative metrics on landmark detection accuracy, angular alignment error, scaling fidelity, or final overlay quality (e.g., IoU, perceptual similarity scores).
- [Method description] Method description (pipeline steps): the assumption that MediaPipe hand points and YOLOv8 ring detections are sufficiently accurate for the subsequent vector-algebra rotation and thickness-based rescaling is untested; no error analysis, failure cases, or comparison to alternative alignment methods is reported.
minor comments (2)
- The abstract contains minor grammatical issues ('enables the users to capture' should read 'enables users to capture'; 'jewel ring' is ambiguous).
- The manuscript would benefit from explicit pseudocode or a diagram of the full pipeline, including how the ROI mask is used for final compositing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the manuscript lacks quantitative or qualitative evaluation to support its claims, which limits its ability to demonstrate an advance. We will revise the manuscript to address the unsubstantiated claims and assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the described transformations 'preserve perceptual realism' is load-bearing for the paper's contribution, yet the manuscript supplies no quantitative metrics on landmark detection accuracy, angular alignment error, scaling fidelity, or final overlay quality (e.g., IoU, perceptual similarity scores).
Authors: We agree that the claim is unsupported. We will revise the abstract to remove the phrase 'preserve perceptual realism' and instead describe the method as rescaling while preserving aspect ratio and using vector algebra for alignment. We will also add a limitations section noting the absence of quantitative validation. revision: yes
-
Referee: [Method description] Method description (pipeline steps): the assumption that MediaPipe hand points and YOLOv8 ring detections are sufficiently accurate for the subsequent vector-algebra rotation and thickness-based rescaling is untested; no error analysis, failure cases, or comparison to alternative alignment methods is reported.
Authors: We acknowledge that the pipeline steps assume sufficient accuracy of the detection models without supporting analysis. We will revise the method section to explicitly discuss this assumption, include example failure cases (e.g., under varying lighting), and note that a full error analysis or comparison to alternatives is outside the current scope of the implementation paper. revision: partial
- Quantitative metrics (e.g., landmark accuracy, angular error, IoU, perceptual scores) or a full experimental evaluation, as none were conducted or reported in the original manuscript.
Circularity Check
No circularity: procedural pipeline with external libraries
full rationale
The manuscript describes an engineering pipeline (MediaPipe hand landmarks + YOLOv8 ring detection + vector-algebra rotation + thickness-based rescaling) without any derivation chain, fitted parameters presented as predictions, or load-bearing self-citations. All steps invoke external, independently developed components; the central claim reduces to an implementation description rather than a mathematical reduction to its own inputs. No equations or self-referential predictions exist.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2811-2815, December 2024
Dipali Ghatge, Sharvari Deshmukh, Ankita Gaikwad, Kaustubh Iparkar, and Anuj Mane, ”Virtual Jewellery Try-On: Enhancing Consumer Engagement and Personalization,” IRJAEH, pp. 2811-2815, December 2024
2024
-
[2]
Jai Prajapat, Manish Sathe, Simran Shah, and Chinmay Raut, ”Jewellery Tryon using AR,” IJCERT, pp 66-72, April 2022
2022
-
[3]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun- Yan Zhu, and Stefano Ermon, ”SDEDIT: Guided Image Synthesis and Editing with Stochastic Differential Equations,” January 2022
2022
-
[4]
22428-22437, 2023
Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang, ”SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model,” pp. 22428-22437, 2023
2023
-
[5]
Fan Zhang, Valentin Bazarevsky, Andrey Vakunov, Andrei Tkachenka, George Sung, Chuo-Ling Chang, and Matthias Grundmann, ”MediaPipe
-
[6]
Hands: On-device Real-time Hand Tracking,” Google research, June 2020
2020
-
[7]
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, ”You Only Look Once: Unified, Real-Time Object Detection,” May 2016
2016
-
[8]
Richard Szeliski, ”Image Alignment and Stitching: A Tutorial,” Mi- crosoft Research, USA, 2006
2006
-
[9]
Yang Zhang, Teoh Tze Tzun, Lim Wei Hern, and Kenji Kawaguchi, ”Enhancing Semantic Fidelity in Text-to-Image Synthesis: Attention Regulation in Diffusion Models,” July 2024
2024
-
[10]
Chengbin Du, Yanxi Li, Zhongwei Qiu, and Chang Xu, ”Stable Diffu- sion is Unstable,” School of Computer Science, Faculty of Engineering University of Sydney, Australia, June 2023
2023
-
[11]
Mingzhen Huang, Shan Jia, Zhou Zhou, Yan Ju, Jialing Cai, and Siwei Lyu, ”Exposing Text-Image Inconsistency Using Diffusion Models,” University at Buffalo, State University of New York, April 2024
2024
-
[12]
Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga, ”ObjectStitch: Object Com- positing with Diffusion Model,” Purdue University, 2023
2023
-
[13]
Patel, and Peyman Milanfar, ”ObjectStitch: Object Composit- ing with Diffusion Model,” Purdue University, 2023
Kangfu Mei, Mauricio Delbracio, Hossein Talebi, Zhengzhong Tu, Vishal M. Patel, and Peyman Milanfar, ”ObjectStitch: Object Composit- ing with Diffusion Model,” Purdue University, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.