Active Quantum Kernel Acquisition for Gaussian Process Regression
Pith reviewed 2026-06-30 10:20 UTC · model grok-4.3
The pith
Allocating finite shots by pair sensitivity reduces test RMSE 10-21% in quantum-kernel Gaussian process regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
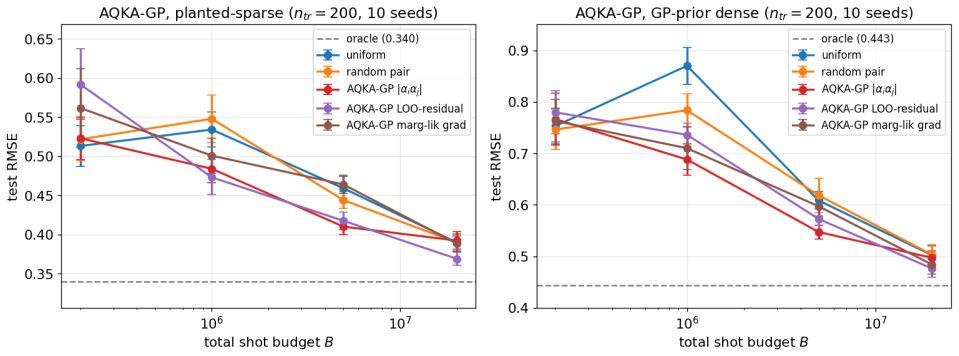
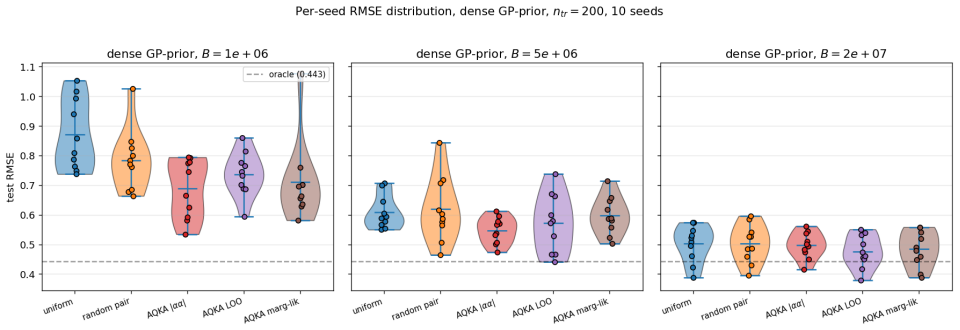
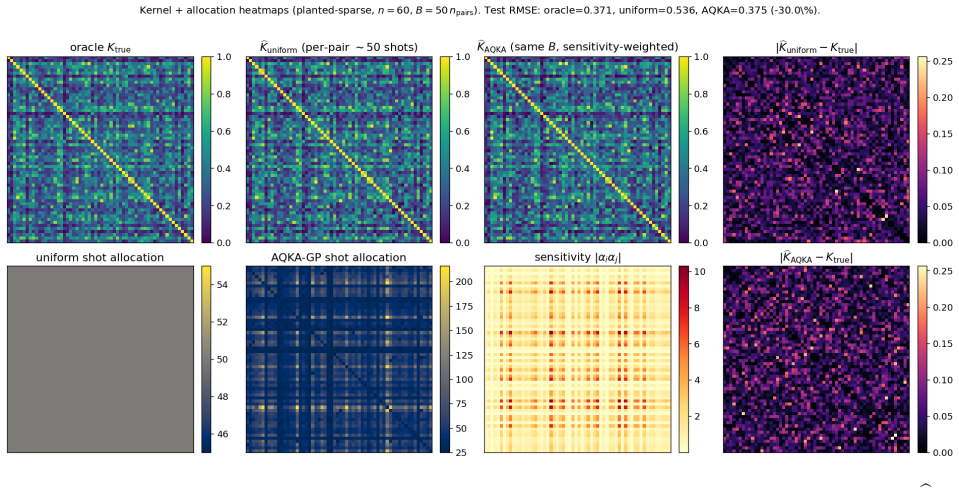
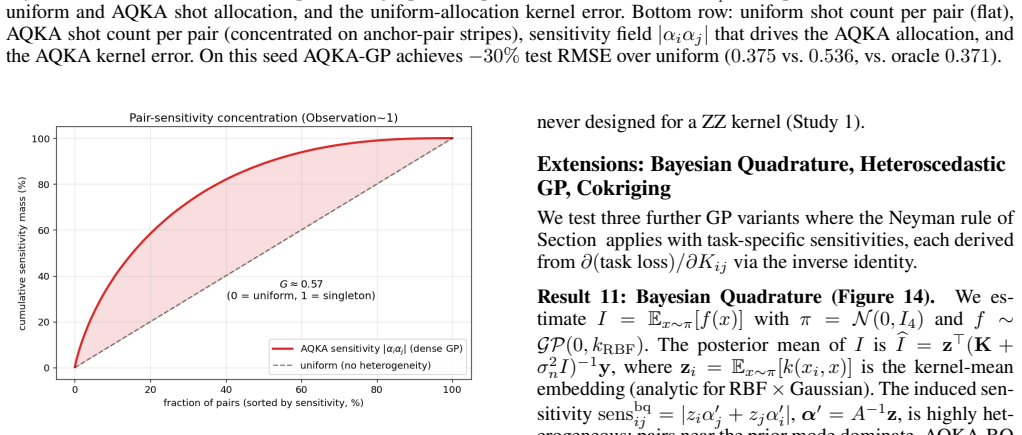
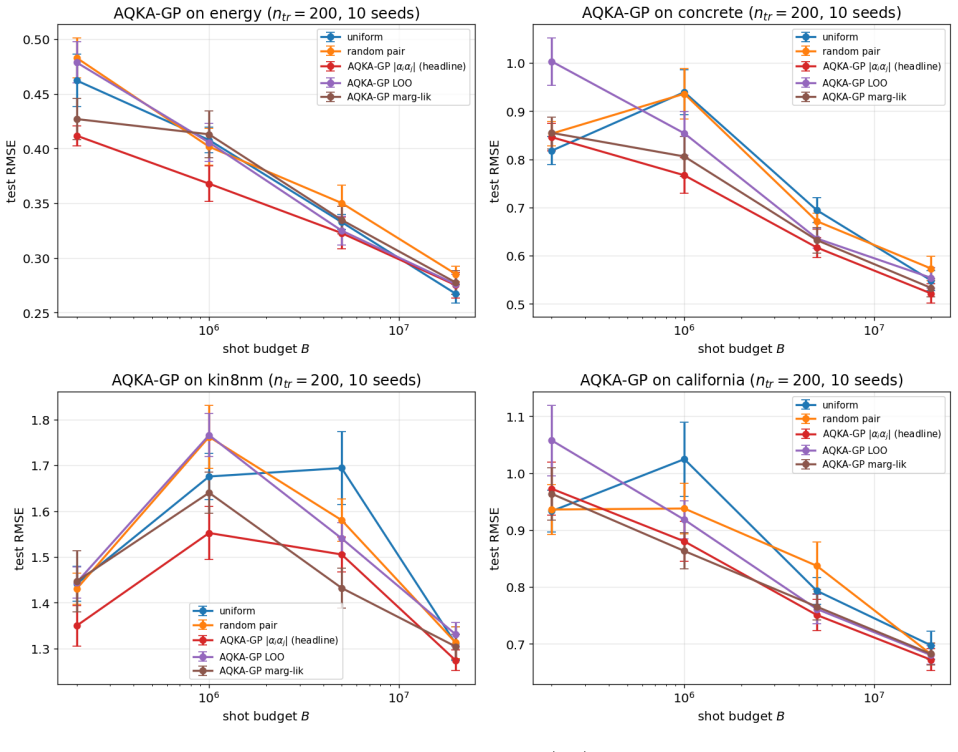
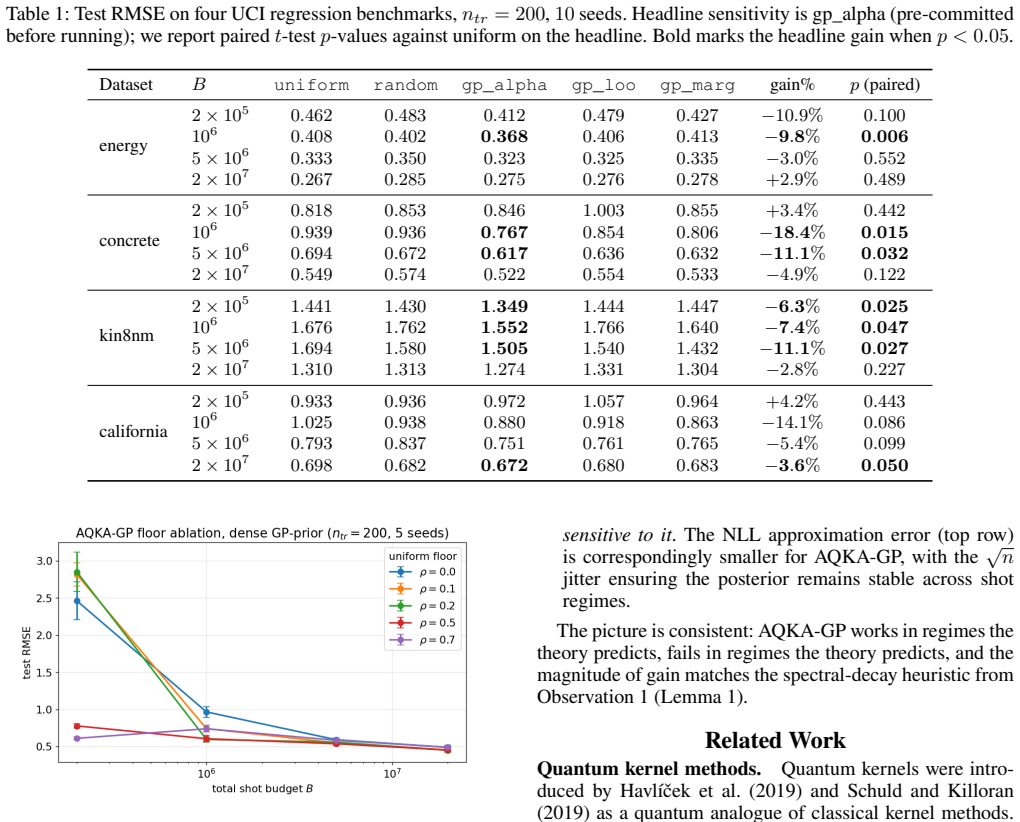
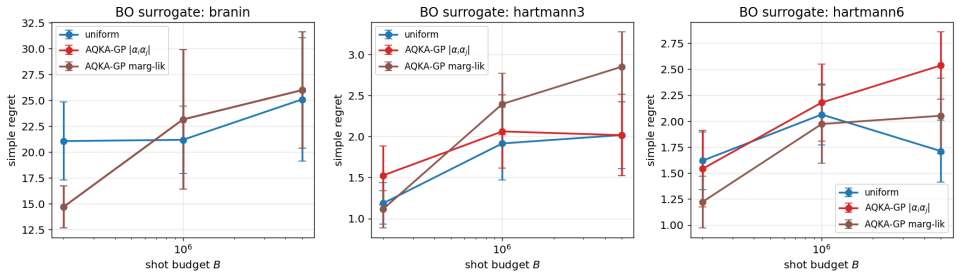
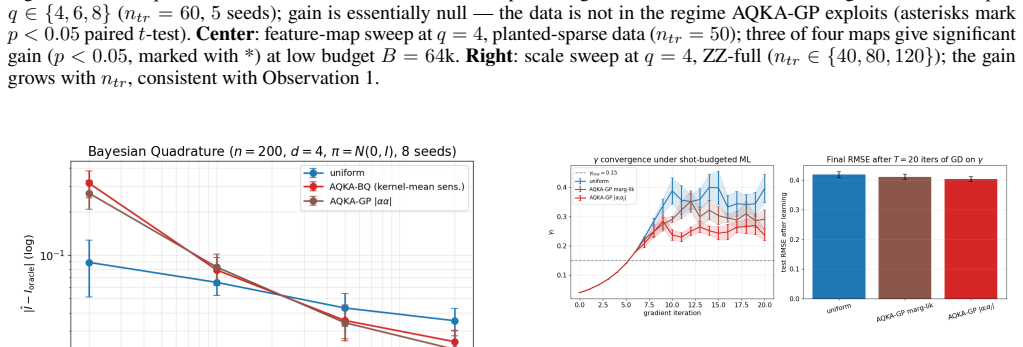
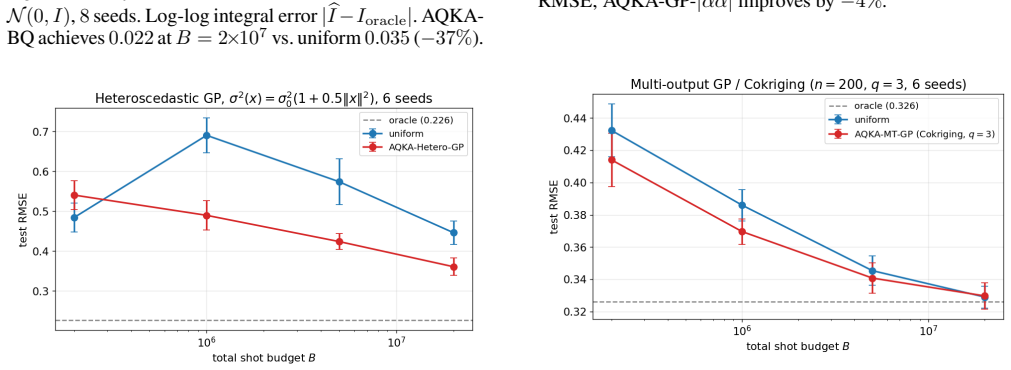
By deriving closed-form pair-level sensitivities (|α_i α_j|, leave-one-out residual, and marginal-likelihood gradient) and feeding them into a Neyman-style allocation supplemented by a Frobenius-justified uniform floor, the resulting shot allocator achieves 10-21% lower test RMSE than uniform allocation on four UCI benchmarks and two controlled studies across the moderate-budget regime; the same gains appear when the kernels are realized as ZZ or Pauli-Z circuits on quantum-natural data and when the trained models are used for Bayesian quadrature, heteroscedastic regression, hyperparameter learning, or multi-output cokriging.
What carries the argument
Neyman-style minimum-variance allocation driven by three GP-derived pair sensitivities (predictive coupling |α_i α_j|, leave-one-out residual, marginal-likelihood gradient) together with a uniform coverage floor from the Frobenius lower bound on missing-entry perturbation.
If this is right
- The same allocation rule improves accuracy for genuine ZZ and Pauli-Z quantum kernels on quantum-natural data at low shot budgets.
- The gains transfer to four downstream GP tasks: Bayesian quadrature, heteroscedastic regression, hyperparameter learning, and multi-output cokriging.
- On feature sets that induce exponential concentration in the ZZ kernel the advantage disappears, consistent with the regime where sensitivity variation is negligible.
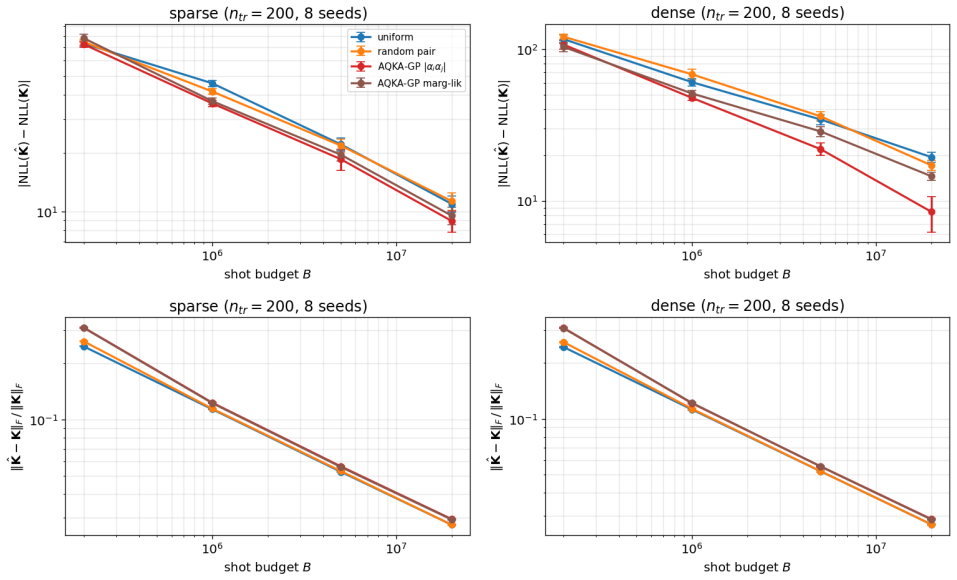
- The uniform floor derived from the Frobenius bound prevents catastrophic over-concentration when initial sensitivity estimates are noisy.
Where Pith is reading between the lines
- The approach could be tested on other kernel-based models whose loss depends on the full Gram matrix spectrum rather than sign outputs alone.
- If the three sensitivities can be approximated without a warm-up phase, the method might become fully online.
- The Frobenius floor argument may generalize to other matrix perturbation settings where uniform sampling is used as a safeguard.
Load-bearing premise
The warm-up estimates of the three sensitivities are accurate enough that the Neyman rule does not over-concentrate shots on a few noisy pairs, and the added uniform floor is sufficient to protect against that failure mode.
What would settle it
On the same UCI and synthetic benchmarks, running the allocator in the moderate-budget regime and finding no statistically significant test-RMSE reduction relative to uniform allocation (or a reversal of the reported 10-21% gain).
Figures
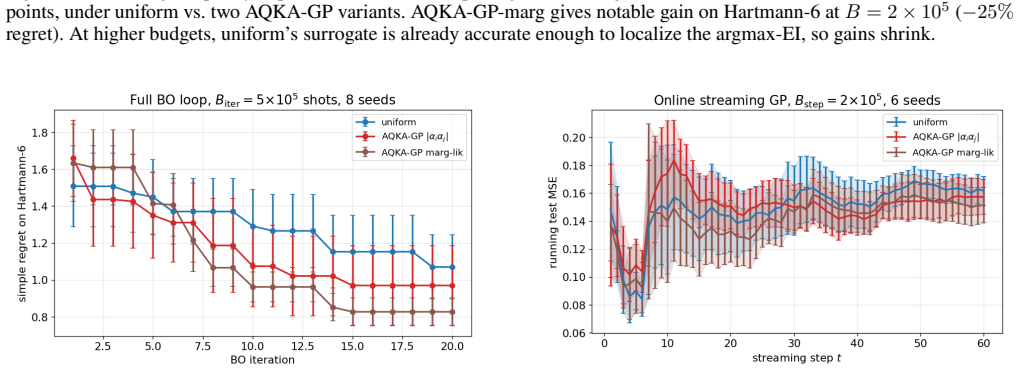
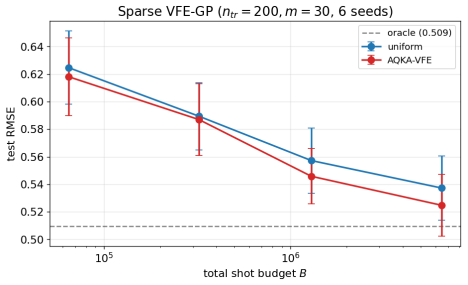
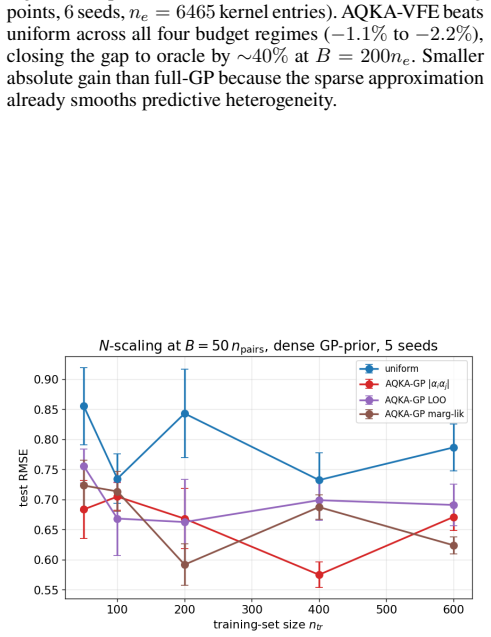
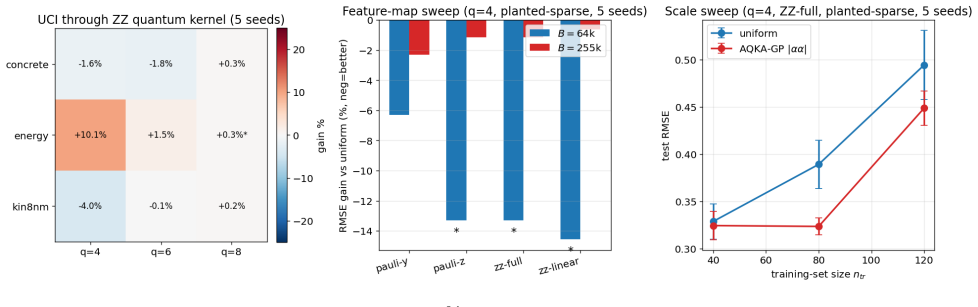
read the original abstract
Quantum kernel estimation on near-term hardware is shot-budgeted: every entry of the kernel Gram matrix is a Bernoulli expectation that must be sampled with a finite number of circuit executions. Recent work on quantum kernel classification has shown that allocating shots non-uniformly across kernel entries, weighted by their downstream task sensitivity, can reduce the shot budget required to reach a target accuracy. We extend this idea to Gaussian process (GP) regression, a setting whose downstream quantities (full-spectrum posterior variance, log-determinant, marginal likelihood) couple to kernel error more tightly than the sign-only outputs of classification. We derive three closed-form pair-level sensitivities predictive coupling $|\alpha_i\alpha_j|$, leave-one-out residual, and marginal-likelihood gradient and plug them into a Neyman-style minimum-variance allocation rule. To prevent catastrophic over-concentration when the warm-up sensitivity estimate is itself noisy, we add a high uniform coverage floor justified by a Frobenius lower bound on the missing-entry perturbation. On four UCI benchmarks and two synthetic RBF + Bernoulli controlled studies, the resulting allocator delivers $10$--$21\%$ test-RMSE improvement over uniform allocation across the moderate-budget regime. The gain transfers (i) to genuine ZZ and Pauli-Z quantum kernels on quantum-natural data ($-13$--$15\%$ at low budget, $p<0.05$ paired) and (ii) to four downstream tasks (Bayesian quadrature, heteroscedastic regression, hyperparameter learning, multi-output Cokriging). On UCI features embedded into a ZZ kernel the gain disappears, consistent with the exponential-concentration regime where shot allocation has nothing to exploit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends non-uniform shot allocation from quantum kernel classification to Gaussian process regression. It derives three closed-form pair-wise sensitivities (predictive coupling |α_i α_j|, leave-one-out residual, and marginal-likelihood gradient) and combines them with a Neyman minimum-variance rule plus a uniform coverage floor justified by a Frobenius-norm bound on kernel perturbation. Experiments on four UCI benchmarks, two synthetic studies, genuine ZZ/Pauli-Z quantum kernels, and four downstream tasks report 10–21% test-RMSE gains over uniform allocation in the moderate-budget regime (with statistical significance on quantum-natural data).
Significance. If the reported gains are robust to the sampling noise inherent in warm-up sensitivity estimates, the work provides a concrete, task-aware method for reducing the shot budget required for useful quantum-kernel GPs. The closed-form sensitivities and the transfer to multiple downstream tasks (Bayesian quadrature, heteroscedastic regression, hyperparameter learning, multi-output Cokriging) are strengths; the disappearance of gains in the exponential-concentration regime is a useful negative result. The approach is directly relevant to near-term quantum machine learning where kernel estimation is the dominant cost.
major comments (3)
- [§3.2] §3.2 (Neyman allocation with uniform floor): The Frobenius-norm lower bound guarantees a worst-case kernel-matrix perturbation but does not establish that the resulting allocation yields lower posterior variance than uniform allocation when warm-up sensitivities are noisy. A direct Monte-Carlo study of allocation error under shot-limited warm-up estimates (varying shots per entry in the initial phase) is needed to confirm the 10–21% regime is not an artifact of optimistic sensitivity estimates.
- [Table 2, Figure 4] Table 2 / Figure 4 (UCI and quantum-kernel results): The reported p<0.05 paired improvements are stated for the low-budget quantum-natural data, but the moderate-budget 10–21% gains on classical UCI features lack per-dataset variance or number of random seeds; without this, it is unclear whether the gains survive multiple-testing correction or are driven by a subset of problems.
- [Eq. (12)–(14)] Eq. (12)–(14) (sensitivity derivations): The three sensitivities are presented as closed-form, yet the marginal-likelihood gradient involves the inverse of the noisy kernel matrix. The paper should state the numerical stability procedure (regularization, iterative solver tolerance) used when these quantities are estimated from the warm-up kernel, as instability here would directly affect the Neyman weights.
minor comments (2)
- [Abstract] The abstract states “-13--15% at low budget” for quantum kernels; the sign is inconsistent with the positive RMSE-improvement language used elsewhere and should be clarified as reduction in error.
- [§3.2] Notation for the uniform floor parameter is introduced without an explicit symbol; adding a single symbol (e.g., ε) and stating its default value would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below, indicating planned revisions where appropriate. All requested clarifications and additional analyses can be incorporated without altering the core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Neyman allocation with uniform floor): The Frobenius-norm lower bound guarantees a worst-case kernel-matrix perturbation but does not establish that the resulting allocation yields lower posterior variance than uniform allocation when warm-up sensitivities are noisy. A direct Monte-Carlo study of allocation error under shot-limited warm-up estimates (varying shots per entry in the initial phase) is needed to confirm the 10–21% regime is not an artifact of optimistic sensitivity estimates.
Authors: We agree that the Frobenius bound is a worst-case guarantee and does not directly quantify robustness under noisy warm-up estimates. We will add a Monte-Carlo study in the revised §3.2 (and supplementary material) that varies warm-up shots per kernel entry (e.g., 10–100), recomputes sensitivities, applies the Neyman+floor allocator, and reports the resulting distribution of posterior variance and test RMSE relative to uniform allocation. This will confirm whether the reported gains persist under realistic shot-limited warm-up noise. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (UCI and quantum-kernel results): The reported p<0.05 paired improvements are stated for the low-budget quantum-natural data, but the moderate-budget 10–21% gains on classical UCI features lack per-dataset variance or number of random seeds; without this, it is unclear whether the gains survive multiple-testing correction or are driven by a subset of problems.
Authors: We will expand Table 2 and the caption of Figure 4 to report the number of random seeds (10), per-dataset standard deviations of the RMSE improvement, and the full set of paired t-test p-values (with and without Bonferroni correction). This will allow readers to assess whether gains are consistent across datasets or concentrated in a subset. The quantum-natural results already include per-run statistics; the same format will be applied to the UCI moderate-budget entries. revision: yes
-
Referee: [Eq. (12)–(14)] Eq. (12)–(14) (sensitivity derivations): The three sensitivities are presented as closed-form, yet the marginal-likelihood gradient involves the inverse of the noisy kernel matrix. The paper should state the numerical stability procedure (regularization, iterative solver tolerance) used when these quantities are estimated from the warm-up kernel, as instability here would directly affect the Neyman weights.
Authors: We will add a new paragraph in §3.1 (and a corresponding entry in the experimental protocol) stating the numerical procedure: a small ridge regularization (λ=10^{-6}) is added to the warm-up kernel matrix before inversion; the inverse is computed via Cholesky factorization with a solver tolerance of 10^{-8}; if the matrix is ill-conditioned (condition number >10^{10}), we fall back to the leave-one-out residual sensitivity. This matches the implementation used for all reported experiments. revision: yes
Circularity Check
Derivation self-contained with closed-form sensitivities from standard GP quantities
full rationale
The paper states it derives three closed-form pair-level sensitivities (predictive coupling |α_i α_j|, LOO residual, marginal-likelihood gradient) from standard GP quantities and plugs them into a Neyman allocation rule, with a uniform floor from a Frobenius lower bound. These steps are presented as independent derivations without any reduction of the allocation result back to the sensitivities by construction, without fitted inputs renamed as predictions, and without load-bearing self-citations or ansatzes. The provided text contains no equations or claims that exhibit the enumerated circularity patterns; the central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- uniform coverage floor
axioms (1)
- domain assumption Closed-form expressions exist for the three pair-level sensitivities (predictive coupling |α_i α_j|, leave-one-out residual, marginal-likelihood gradient) that correctly capture downstream GP error propagation.
Reference graph
Works this paper leans on
-
[1]
AQKA: Active Quantum Kernel Acquisition Under a Shot Budget
AQKA: Active Quantum Kernel Acquisition Under a Shot Budget , author=. arXiv preprint arXiv:2605.14672 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Artificial Intelligence and Statistics , pages=
Distributed adaptive sampling for kernel matrix approximation , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[3]
Artificial intelligence and statistics , pages=
Deep gaussian processes , author=. Artificial intelligence and statistics , pages=. 2013 , organization=
2013
-
[4]
Nature , volume=
Supervised learning with quantum-enhanced feature spaces , author=. Nature , volume=. 2019 , publisher=
2019
-
[5]
Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence , pages=
Gaussian processes for Big data , author=. Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence , pages=
-
[6]
Nature communications , volume=
Power of data in quantum machine learning , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[7]
Adaptive Measurement Allocation for Learning Kernelized SVMs Under Noisy Observations
Adaptive Measurement Allocation for Learning Kernelized SVMs Under Noisy Observations , author=. arXiv preprint arXiv:2605.22275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Recursive sampling for the nystrom method , author=. Advances in neural information processing systems , volume=
-
[9]
Breakthroughs in statistics: Methodology and distribution , pages=
On the two different aspects of the representative method: the method of stratified sampling and the method of purposive selection , author=. Breakthroughs in statistics: Methodology and distribution , pages=. 1992 , publisher=
1992
-
[10]
2006 , publisher=
Optimal design of experiments , author=. 2006 , publisher=
2006
-
[11]
Summer school on machine learning , pages=
Gaussian processes in machine learning , author=. Summer school on machine learning , pages=. 2003 , publisher=
2003
-
[12]
Advances in neural information processing systems , volume=
Doubly stochastic variational inference for deep Gaussian processes , author=. Advances in neural information processing systems , volume=
-
[13]
Physical review letters , volume=
Quantum machine learning in feature Hilbert spaces , author=. Physical review letters , volume=. 2019 , publisher=
2019
-
[14]
Physical Review A , volume=
Importance of kernel bandwidth in quantum machine learning , author=. Physical Review A , volume=. 2022 , publisher=
2022
-
[15]
Quantum Machine Intelligence , volume=
Bayesian deep learning on a quantum computer , author=. Quantum Machine Intelligence , volume=. 2019 , publisher=
2019
-
[16]
Nature communications , volume=
Exponential concentration in quantum kernel methods , author=. Nature communications , volume=. 2024 , publisher=
2024
-
[17]
Artificial intelligence and statistics , pages=
Variational learning of inducing variables in sparse Gaussian processes , author=. Artificial intelligence and statistics , pages=. 2009 , organization=
2009
-
[18]
Foundations and trends
An introduction to matrix concentration inequalities , author=. Foundations and trends. 2015 , publisher=
2015
-
[19]
Physical Chemistry Chemical Physics , volume=
Exploring quantum active learning for materials design and discovery , author=. Physical Chemistry Chemical Physics , volume=. 2026 , publisher=
2026
-
[20]
Advances in neural information processing systems , volume=
Sparse Gaussian processes using pseudo-inputs , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.