Conversational Domain Adaptation of IndicTrans2 across 21 Indic Languages via Experience Replay and Model Soups
Pith reviewed 2026-06-30 09:35 UTC · model grok-4.3
The pith
Experience replay combined with model averaging lets IndicTrans2 handle conversational input across 21 languages while preserving general-domain accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
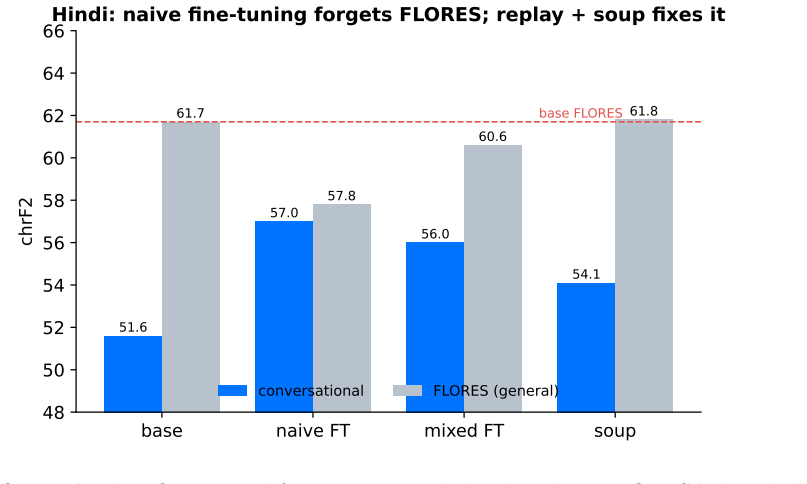
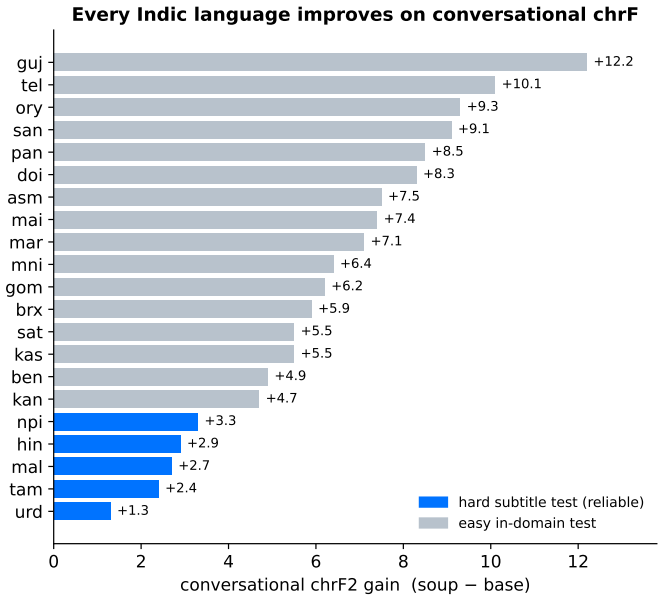
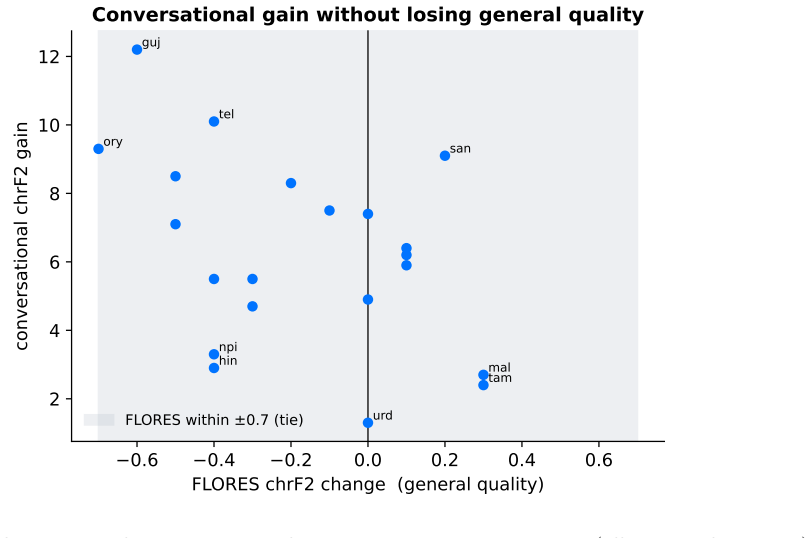
IndicTrans2-1B can be adapted to conversational register across all 21 Indic languages by mixing general-domain data back into the fine-tuning process and then averaging the fine-tuned weights with the base model weights. This combination eliminates the typical trade-off where conversational improvements come at the expense of general-domain performance. The resulting models show higher chrF scores on conversational test sets in every language and statistically indistinguishable scores on the FLORES general-domain test set.
What carries the argument
Experience replay, which mixes general data into conversational fine-tuning, combined with model souping, which averages the fine-tuned weights with the original base weights.
If this is right
- Conversational chrF rises in all 21 languages with a mean gain of 6.2 points.
- FLORES scores stay within 0.7 chrF of the base model, with a mean change of -0.17.
- Paired bootstrap tests confirm the conversational improvements are significant while FLORES changes are not.
- The procedure uses only publicly available data sources and applies uniformly across the 21 languages.
Where Pith is reading between the lines
- The same replay-plus-souping sequence could be applied to other multilingual models facing domain-shift trade-offs.
- Further tests could measure whether the adapted models reduce the need for separate general and conversational systems in production pipelines.
- Extending the method to additional low-resource language pairs would test whether the observed pattern holds beyond the current set of 21 Indic languages.
Load-bearing premise
The public conversational corpora used for adaptation are representative enough of real user conversational language that gains on held-out splits will appear in deployed systems.
What would settle it
A blind human preference study on fresh conversational inputs in which the adapted model is not preferred over the base model would show that the chrF gains do not translate to perceived quality.
Figures
read the original abstract
IndicTrans2 is the strongest open English to Indic translation system, but like most systems it is trained on general text and tends to sound stiff on casual, conversational input. We adapt IndicTrans2-1B to conversational register across all 21 Indic languages using only public data (OpenSubtitles, BPCC-H-Daily, Tatoeba). Plain fine-tuning improves conversational chrF but forgets the general domain (it drops 3.9 chrF on FLORES for Hindi). Mixing general data back into training (experience replay) and then averaging the fine-tuned weights with the base (model souping) removes that trade-off: the resulting model beats IndicTrans2-1B on conversational chrF in every one of the 21 languages (mean +6.2) while matching it on FLORES (mean change -0.17, all within 0.7 chrF). Paired bootstrap tests confirm the conversational gains are significant (p <= 0.004) and that FLORES is not significantly degraded. We are deliberate about scope: these are chrF gains, and a blind human plus multi-model LLM check does not confirm them as a perceived quality improvement, so we treat the conversational gain as largely a register match to the references rather than proof of better translation. The techniques are not new; the contribution is the honest, end-to-end study in the Indic conversational setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that combining experience replay (mixing general-domain data into conversational fine-tuning) with model souping (averaging the resulting weights with the base IndicTrans2-1B model) adapts the system to conversational register across all 21 Indic languages using only public corpora (OpenSubtitles, BPCC-H-Daily, Tatoeba). This yields a mean +6.2 chrF gain on held-out conversational test sets while preserving general-domain performance on FLORES (mean change -0.17, all changes within 0.7 chrF). Paired bootstrap tests confirm significance for the conversational gains (p <= 0.004) but not for FLORES degradation. The authors explicitly scope the result to register matching with references rather than perceived quality improvement, citing a blind human plus multi-model LLM evaluation that does not confirm the metric gains as quality advances.
Significance. If the empirical pattern holds, the work supplies a reproducible, public-data-only recipe for domain adaptation that avoids catastrophic forgetting in a 21-language Indic setting. Strengths include the consistent directional gains across every language, explicit paired bootstrap testing, and the deliberate scoping that distinguishes metric improvement from human-perceived quality. The contribution lies in the end-to-end documentation rather than methodological novelty.
minor comments (2)
- The methods section should report the precise experience-replay mixing ratios, learning-rate schedules, and souping coefficients (or the procedure used to select them) so that the reported chrF deltas can be exactly reproduced.
- A per-language table of conversational and FLORES chrF scores (with the base model, fine-tuned model, replay-only, and soup variants) would allow readers to verify the uniformity of the +6.2 mean gain beyond the aggregate statistic.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the consistent gains across all 21 languages, the explicit statistical testing, and the deliberate scoping of results to register matching rather than perceived quality. The recommendation of minor revision is noted. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central claims consist of direct empirical measurements: chrF scores on held-out splits from public conversational corpora (OpenSubtitles, BPCC-H-Daily, Tatoeba) and FLORES after applying experience replay plus model souping to IndicTrans2-1B. No equations, fitted parameters, or self-citations are used to derive the reported deltas (+6.2 mean conversational, -0.17 mean FLORES); the numbers are computed from independent test evaluations with bootstrap significance tests. The methods (experience replay, model souping) are explicitly described as non-novel, and the paper includes explicit scope caveats that the gains reflect register matching rather than proven quality improvement. The derivation chain is therefore self-contained empirical reporting with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption chrF is an appropriate automatic metric for measuring both conversational register match and general-domain translation quality
- domain assumption The chosen public conversational corpora are suitable proxies for the target conversational register across 21 Indic languages
Reference graph
Works this paper leans on
-
[1]
Re-evaluating the Role of BLEU in MT Research
• Callison-Burch, Osborne, Koehn. Re-evaluating the Role of BLEU in MT Research. EACL 2006. • Chu, Dabre, Kurohashi. An Empirical Comparison of Domain Adaptation Methods for NMT. ACL 2017. • Freitag, Foster, Grangier, et al. Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for MT. TACL 2021. • Gala et al. IndicTrans2: Towards High-Qua...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.