CellDETR: A Detection-Guided Framework for Scalable Cell Representation Learning from Histopathology Images
Pith reviewed 2026-06-30 07:22 UTC · model grok-4.3
The pith
CellDETR adds location feature decoupling and box-constrained attention to Deformable DETR to extract cell embeddings from whole-slide images that outperform prior methods on PanNuke and transfer across datasets after pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CellDETR, constructed by incorporating location feature decoupling and box-constrained attention into Deformable DETR, automates the extraction of cell-level embeddings from WSIs. This yields superior supervised cell classification on PanNuke compared to state-of-the-art approaches. Incorporating contrastive learning enables pretraining on unlabeled WSIs that enhances downstream classification, while pretraining with Xenium-derived annotations achieves accurate cross-dataset cell classification, indicating the embeddings' transferability and biological relevance.
What carries the argument
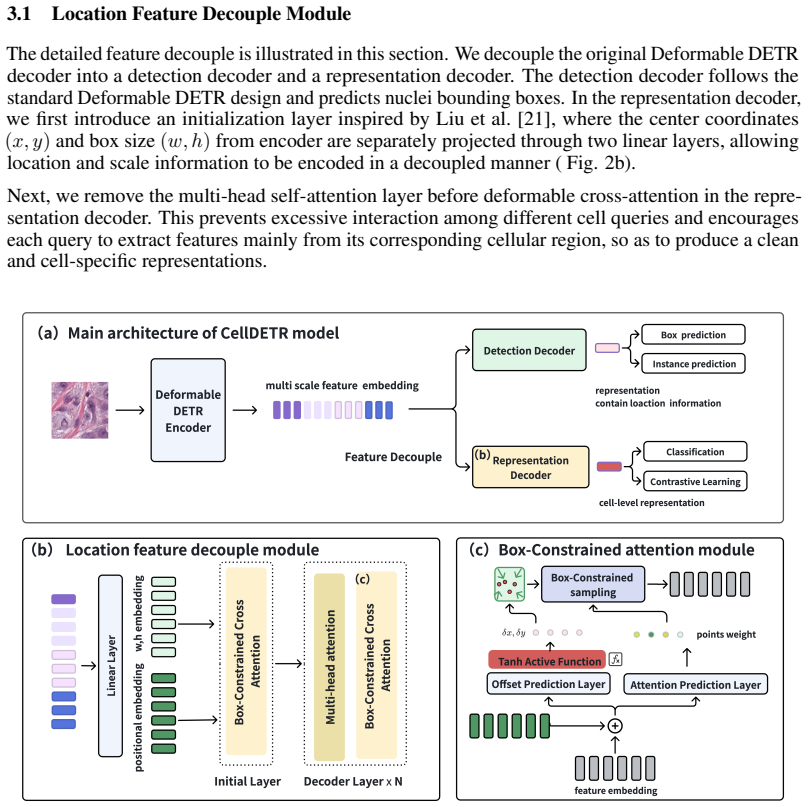
location feature decoupling and box-constrained attention mechanism, which separate positional information and restrict attention to detected bounding boxes to produce cell-specific embeddings.
If this is right
- Outperforms existing state-of-the-art methods in supervised cell classification on PanNuke data.
- A CellDETR-based contrastive pretraining model on unlabeled WSIs improves downstream cell classification performance.
- Pretraining with Xenium spatial transcriptomics-derived cell annotations enables accurate cross-dataset cell classification.
Where Pith is reading between the lines
- The learned embeddings could support more detailed mapping of cell types and interactions within tissue microenvironments.
- The detection-guided design may extend to representation learning for other small-scale objects in imaging domains beyond pathology.
- Cross-dataset transfer success suggests the embeddings capture features general enough for use in settings with limited labeled data.
Load-bearing premise
The performance gains in cell embeddings and transfer come primarily from the location feature decoupling and box-constrained attention rather than from training choices, hyperparameters, or the base Deformable DETR architecture.
What would settle it
Training a standard Deformable DETR on PanNuke data without location feature decoupling or box-constrained attention and obtaining cell classification accuracy equal to or higher than CellDETR.
Figures
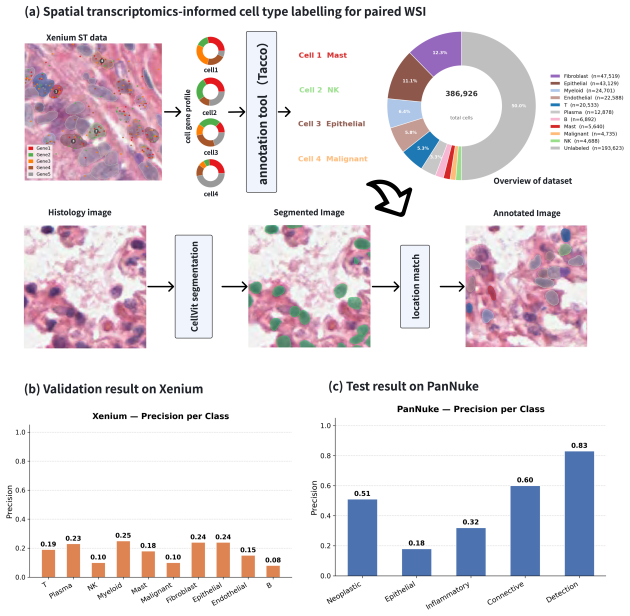
read the original abstract
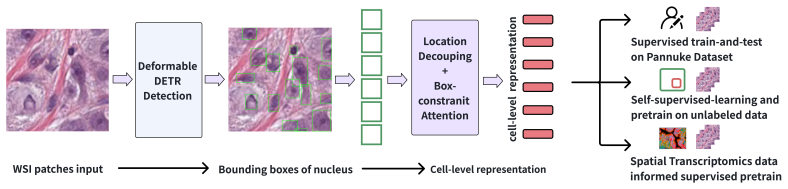
Recent advances in pathology foundation models have substantially improved patch and slide level representation learning from whole-slide images (WSIs).However, cell-level representations learning remain underexplored, limiting cell resolved interpretability, biological discovery, and clinical translation. We propose CellDETR, a detection-guided framework built on Deformable DETR for scalable cell representation learning from WSIs. By introducing location feature decoupling and box-constrained attention mechanism, CellDETR enables automated extraction of cell-level embeddings, and outperform existing state-of-the-art methods in supervised cell classification on PanNuke data. In addition, by incorporating contrastive learning design, we build a CellDETR-based pretraining model for scalable cell representation learning from unlabeled WSIs, which improves downstream cell classification performance. Furthermore, we show that after pretraining with Xenium spatial transcriptomics-derived cell annotations, CellDETR achieves accurate cross-dataset cell classification, demonstrating the transferability and biological relevance of the learned cell embeddings. Together, CellDETR provides a scalable route toward general cell-level representation learning framework for interpretable computational patholog
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CellDETR, a detection-guided framework extending Deformable DETR with two modifications—location feature decoupling and box-constrained attention—for automated extraction of cell-level embeddings from whole-slide histopathology images. It claims these changes enable outperformance of existing methods on supervised cell classification using the PanNuke dataset, that adding a contrastive learning component yields a scalable pretraining approach on unlabeled WSIs that boosts downstream classification, and that pretraining with Xenium spatial transcriptomics annotations produces accurate cross-dataset cell classification, demonstrating transferability.
Significance. If the empirical claims hold after proper controls, the work could advance cell-resolved representation learning in computational pathology beyond current patch- or slide-level foundation models, supporting more interpretable biological discovery. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the central attribution of performance gains and transferability to 'location feature decoupling and box-constrained attention' is unsupported because no ablation studies, quantitative metrics, baseline comparisons to unmodified Deformable DETR, or statistical tests are referenced; without these, the claim that the modifications are the primary drivers cannot be evaluated.
- [Abstract] Abstract: the statements of outperformance on PanNuke, improvement from contrastive pretraining, and cross-dataset accuracy with Xenium annotations are presented without any reported numbers, error bars, dataset splits, or implementation details, rendering the soundness of the empirical claims impossible to assess from the provided text.
minor comments (1)
- [Abstract] Abstract contains grammatical issues ('remain underexplored', 'outperform existing', 'provides a scalable route toward general ... framework') that should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and agree that revisions to the abstract are warranted to better support the claims with references to the experimental evidence presented in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central attribution of performance gains and transferability to 'location feature decoupling and box-constrained attention' is unsupported because no ablation studies, quantitative metrics, baseline comparisons to unmodified Deformable DETR, or statistical tests are referenced; without these, the claim that the modifications are the primary drivers cannot be evaluated.
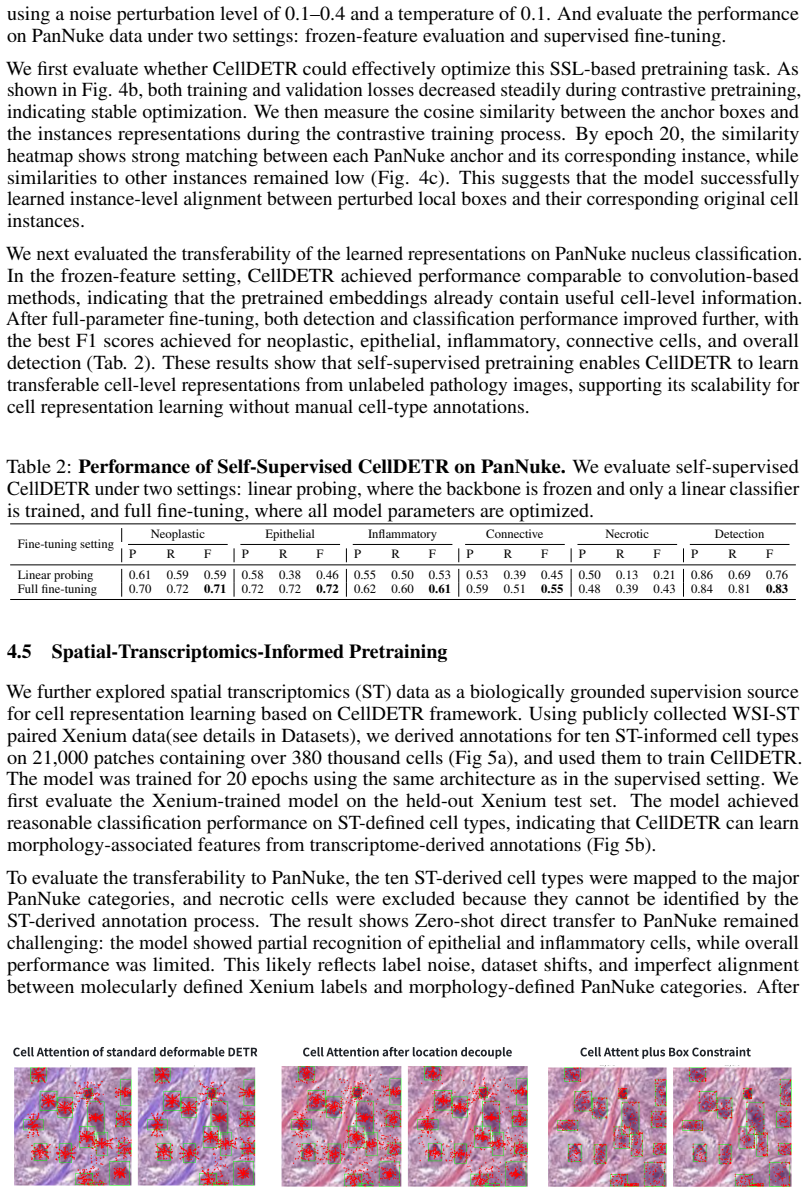
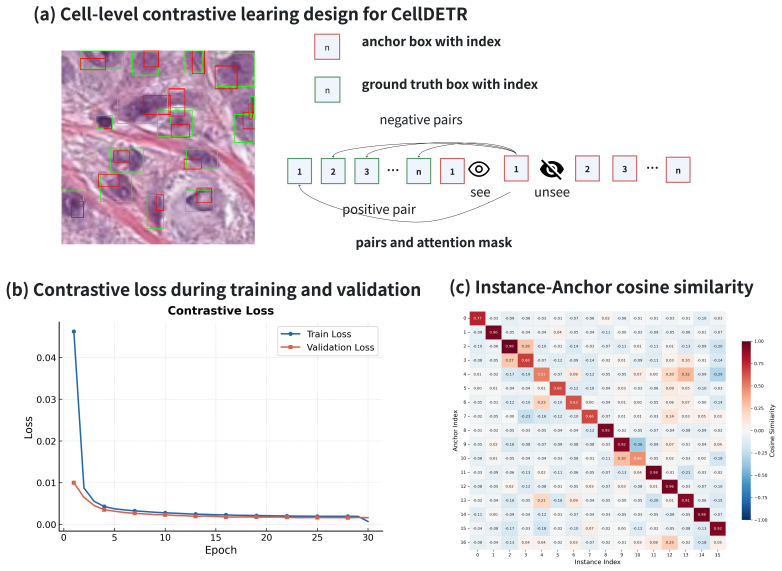
Authors: The main manuscript includes ablation studies (Section 4.2), direct comparisons against the unmodified Deformable DETR baseline, quantitative metrics, and statistical tests demonstrating the contribution of the proposed modifications. We will revise the abstract to explicitly reference these ablations and key supporting results. revision: yes
-
Referee: [Abstract] Abstract: the statements of outperformance on PanNuke, improvement from contrastive pretraining, and cross-dataset accuracy with Xenium annotations are presented without any reported numbers, error bars, dataset splits, or implementation details, rendering the soundness of the empirical claims impossible to assess from the provided text.
Authors: We agree that the abstract would benefit from including representative quantitative results. The full manuscript reports these details with numbers, error bars, dataset splits, and implementation information in Sections 4.1, 4.3, and 4.4. We will update the abstract to incorporate key performance metrics from the PanNuke and Xenium experiments. revision: yes
Circularity Check
No circularity; empirical architecture proposal with reported experimental outcomes
full rationale
The paper introduces CellDETR as a detection-guided framework extending Deformable DETR, with added location feature decoupling and box-constrained attention. All claims concern empirical performance on PanNuke classification, contrastive pretraining on WSIs, and cross-dataset transfer after Xenium pretraining. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central results are framed as experimental measurements rather than quantities defined in terms of themselves, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021. URL...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Chen, Tong Ding, Ming Y
Richard J. Chen, Tong Ding, Ming Y . Lu, Drew F. K. Williamson, Guillaume Jaume, Bowen Chen, Andrew Zhang, Daniel Shao, Andrew H. Song, Muhammad Shaban, et al. To- wards a general-purpose foundation model for computational pathology.Nature Medicine,
-
[3]
URL https://www.nature.com/articles/ s41591-024-02857-3
doi: 10.1038/s41591-024-02857-3. URL https://www.nature.com/articles/ s41591-024-02857-3
-
[4]
Eugene V orontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Kristen Severson, Eric Zimmermann, James Hall, Neil Tenenholtz, Nicolo Fusi, Ellen Yang, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kunz, Matthew C. H. Lee, Jan H. Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Mil...
-
[5]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Shen...
-
[6]
Peter Neidlinger, Omar S. M. El Nahhas, Hannah Sophie Muti, Tim Lenz, et al. Benchmarking foundation models as feature extractors for weakly-supervised computational pathology.Nature Biomedical Engineering, 2025. doi: 10.1038/s41551-025-01516-3. arXiv:2408.15823
-
[7]
A clinical benchmark of public self-supervised pathology foundation models.Nature Communications, 16(1):3640,
Gabriele Campanella, Shengjia Chen, Manan Singh, Ruchika Verma, et al. A clinical benchmark of public self-supervised pathology foundation models.Nature Communications, 16(1):3640,
-
[8]
doi: 10.1038/s41467-025-58796-1
-
[9]
K. Ding et al. A large-scale synthetic pathological dataset for deep learning-enabled segmenta- tion of breast cancer.Scientific Data, 10(1):231, 2023. doi: 10.1038/s41597-023-02125-y
-
[10]
Fabian Hörst, Moritz Rempe, Lukas Heine, Constantin Seibold, Julius Keyl, Giulia Baldini, Selma Ugurel, Jens Siveke, Barbara Grünwald, Jan Egger, and Jens Kleesiek. CellViT: Vision transformers for precise cell segmentation and classification.Medical Image Analysis, 94: 103143, 2024. doi: 10.1016/j.media.2024.103143. URL https://www.sciencedirect. com/sci...
-
[11]
Fabian Hörst, Moritz Rempe, Helmut Becker, Lukas Heine, Julius Keyl, and Jens Kleesiek. CellViT++: Energy-efficient and adaptive cell segmentation and classification using foundation models, 2025. URLhttps://arxiv.org/abs/2501.05269
-
[12]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, pages 5998–6008,
-
[13]
URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[14]
Deformable DETR: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: Deformable transformers for end-to-end object detection. InInternational Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/forum?id= gZ9hCDWe6ke. 10
2021
-
[15]
Pannuke dataset extension, insights and baselines.arXiv preprint arXiv:2003.10778, 2020
Jevgenij Gamper, Navid Alemi Koohbanani, Simon Graham, Mostafa Jahanifar, Syed Ali Khurram, Ayesha Azam, Katherine Hewitt, and Nasir Rajpoot. Pannuke dataset extension, insights and baselines.arXiv preprint arXiv:2003.10778, 2020
-
[16]
S. Marco Salas et al. Optimizing xenium in situ data utility by quality assess- ment and best-practice analysis workflows.Nature Methods, 22:813–823, 2025. doi: 10.1038/s41592-025-02617-2. URL https://www.nature.com/articles/ s41592-025-02617-2
-
[17]
Patrik L. Ståhl, Fredrik Salmén, Sanja Vickovic, Anna Lundmark, José Fernández Navarro, Jens Magnusson, Stefania Giacomello, Michaela Asp, Jakub O. Westholm, Mikael Huss, Annelie Mollbrink, Sten Linnarsson, Simone Codeluppi, Åsa Borg, Fredrik Pontén, Paul Igor Costea, Pelin Sahlén, Jan Mulder, Jonas Nilsson, and Joakim Lundeberg. Visualization and analysi...
-
[18]
Mask R-CNN
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2961–2969, 2017
2017
-
[19]
Shan E Ahmed Raza, Linda Cheung, Muhammad Shaban, Simon Graham, David Epstein, Stella Pelengaris, Michael Khan, and Nasir M Rajpoot. Micro-net: A unified model for segmentation of various objects in microscopy images.Medical Image Analysis, 52:160–173, 2019. doi: 10.1016/j.media.2018.12.003
-
[20]
Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019. doi: 10.1016/j.media. 2019.101563
-
[21]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision (ECCV), pages 213–229. Springer, 2020. doi: 10.1007/978-3-030-58452-8_13. URLhttps://arxiv.org/abs/2005.12872
-
[22]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021
2021
-
[23]
Nuclear morphology is a deep learning biomarker of cellular senescence and predicts clinical outcomes in cancer.Nature Aging, 2022
Ines Heckenbach et al. Nuclear morphology is a deep learning biomarker of cellular senescence and predicts clinical outcomes in cancer.Nature Aging, 2022. doi: 10.1038/ s43587-022-00263-3
2022
-
[24]
DAB-DETR: Dynamic anchor boxes are better queries for DETR
Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. InInternational Conference on Learning Representations (ICLR), 2022. URLhttps://arxiv.org/abs/2201.12329
-
[25]
Decoupled detr: Spatially disentangling localization and classification for improved end-to-end object detection
Minghan Zhang et al. Decoupled detr: Spatially disentangling localization and classification for improved end-to-end object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), page ..., 2023. URL https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_Decoupled_ DETR_Spatially_Disentangling_Localization_and_Cla...
2023
-
[26]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. InarXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Cell-detr: Efficient cell detection and classification in wsis with transformers
Oscar Pina et al. Cell-detr: Efficient cell detection and classification in wsis with transformers. InMedical Imaging with Deep Learning (MIDL), 2024
2024
-
[28]
Tacco: a novel method for cell type annotation in spatial transcriptomics
Maria Efremova et al. Tacco: a novel method for cell type annotation in spatial transcriptomics. Nature Methods, 2024. doi: 10.1038/s41592-024-02291-8. 11 A Supplementary A.1 Two training mode In thesequential trainingstrategy, predicted boxes from the detection decoder are directly passed to the representation decoder, allowing the model to learn detecti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.