SoftBinary Coding: A New Information-Theoretic Neural Compression Paradigm
Pith reviewed 2026-06-30 01:51 UTC · model grok-4.3
The pith
SoftBinary Coding reaches optimal rate-distortion bounds in neural compression through stochastic binary latents and a rate-optimal channel simulation scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
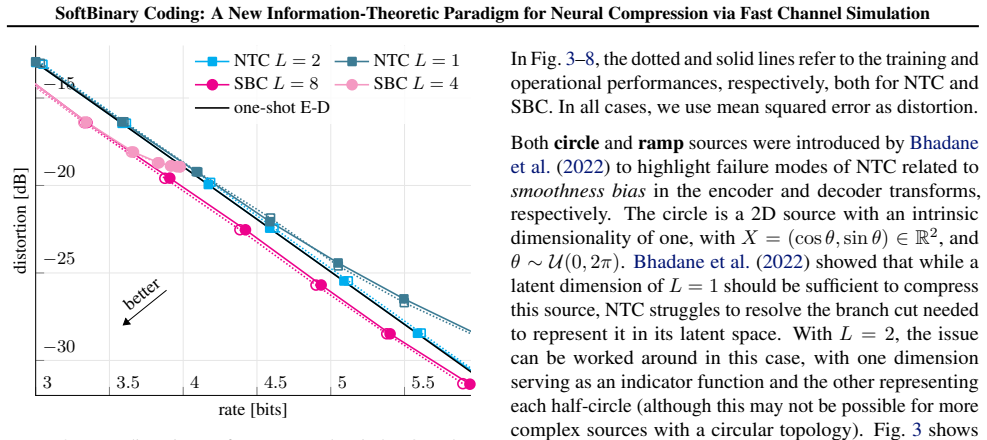
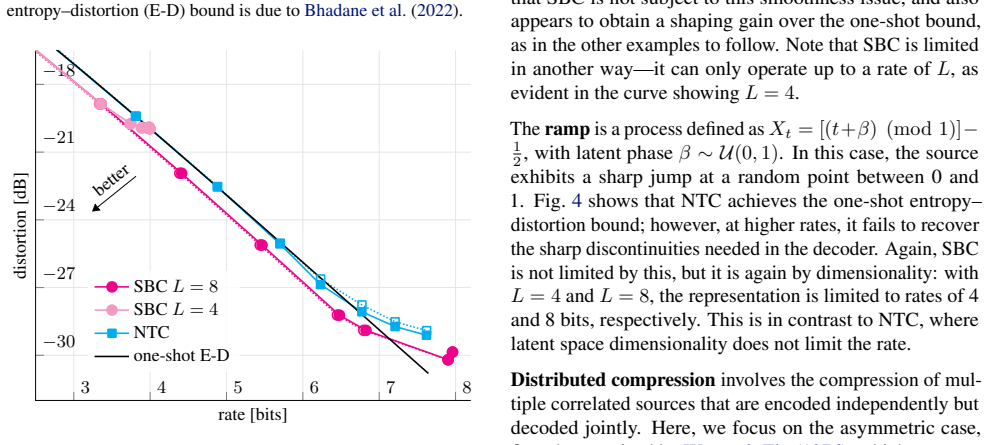
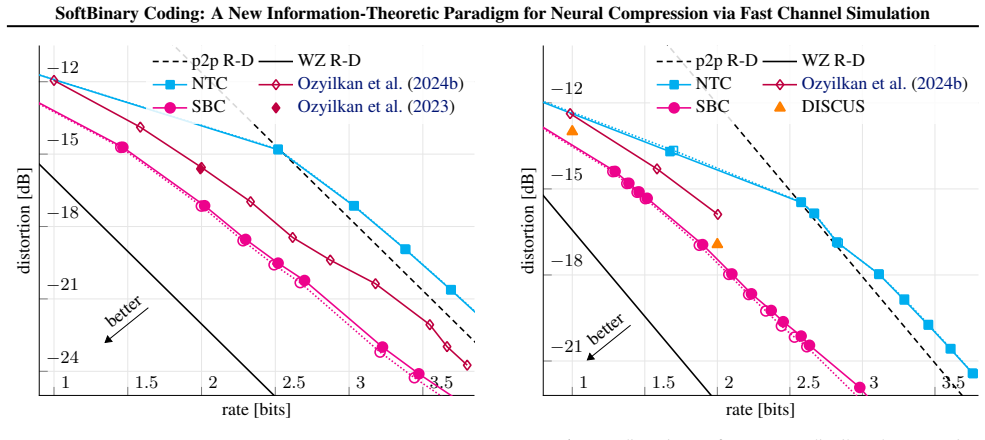
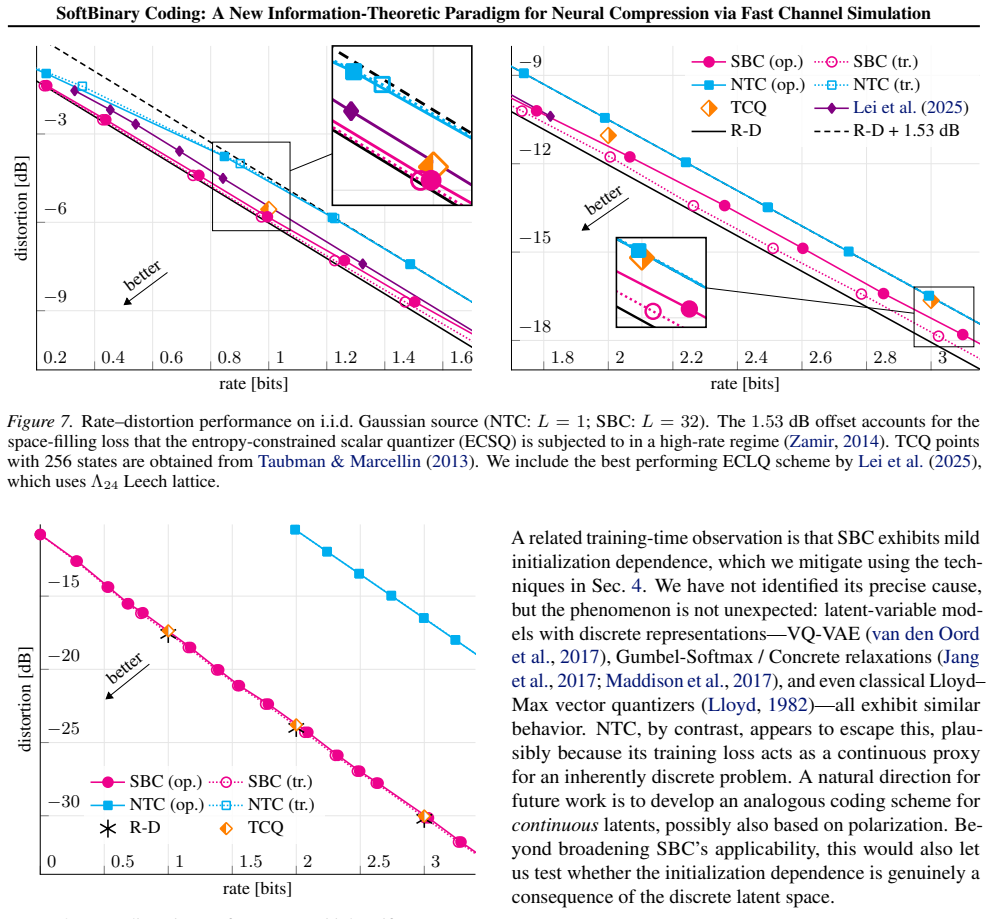
SBC employs discrete representations and compresses them through a novel fast binary channel simulation scheme, for which we provide a proof of rate optimality. Experimental gains on information-theoretic sources provide both theoretical and practical closure to NTC's limitations, establishing discrete binary structures as a viable path toward reaching optimal rate--distortion bounds. Surprisingly, SBC also achieves state-of-the-art performance on vector quantization of i.i.d. sources, exceeding Trellis Coded Quantization of the Gaussian source.
What carries the argument
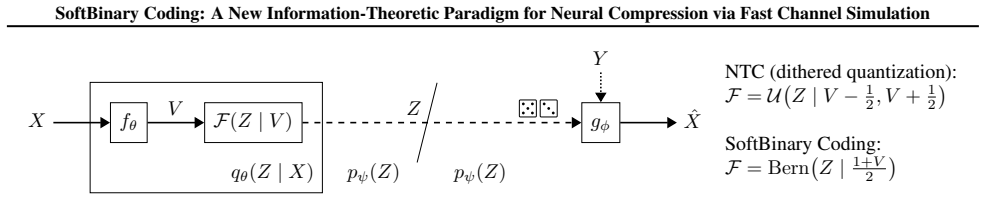
stochastic binary latent space with fast binary channel simulation scheme, which produces discrete representations and enables rate-optimal compression.
If this is right
- Neural compression can avoid train-test mismatch and smoothness bias by switching to discrete binary latents.
- The channel simulation scheme achieves rate optimality, allowing the system to reach theoretical rate-distortion bounds.
- SBC delivers measurable gains on information-theoretic sources and sets new performance records for vector quantization of i.i.d. sources.
- Discrete binary structures serve as a practical alternative to continuous transforms for optimal compression.
Where Pith is reading between the lines
- If the binary latent approach extends to image or video data, it could serve as a drop-in replacement for continuous NTC pipelines in deployed codecs.
- The rate-optimality proof for the simulation scheme may generalize to other discrete alphabets beyond binary.
- Hybrid systems that combine SBC latents with existing learned transforms could improve compression for sources where NTC currently underperforms.
Load-bearing premise
The stochastic binary latent space combined with the channel simulation scheme can be trained end-to-end without reintroducing train-test mismatch or smoothness bias.
What would settle it
Run SBC on a standard Gaussian source at a fixed rate and measure whether the achieved distortion meets or beats the known rate-distortion bound while the simulation rate stays at or below the source entropy.
Figures

read the original abstract
Neural compression is currently dominated by Nonlinear Transform Coding (NTC), which maps data to real-valued latents via continuous transforms. Despite its success, NTC suffers from train-test mismatch due to non-differentiable quantization, a ``smoothness bias" inherent in continuous transforms that precludes optimality for certain sources, and a loss of ``shaping gain" due to the complexity of including high-dimensional vector quantization. We propose SoftBinary Coding (SBC), an end-to-end learning paradigm that bypasses these limitations by using a stochastic binary latent space. In the spirit of vector quantization, SBC employs discrete representations and compresses them through a novel fast binary channel simulation scheme, for which we provide a proof of rate optimality. Experimental gains on information-theoretic sources provide both theoretical and practical closure to NTC's limitations, establishing discrete binary structures as a viable path toward reaching optimal rate--distortion bounds. Surprisingly, SBC also achieves state-of-the-art performance on vector quantization of i.i.d. sources, exceeding Trellis Coded Quantization of the Gaussian source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SoftBinary Coding (SBC), an end-to-end neural compression paradigm that replaces the continuous latents of Nonlinear Transform Coding (NTC) with a stochastic binary latent space. Data are mapped to discrete binary representations that are then compressed via a novel fast binary channel simulation scheme; the authors provide a proof of rate optimality for this scheme. The work claims that SBC eliminates NTC's train-test mismatch, smoothness bias, and loss of shaping gain, delivers experimental gains on information-theoretic sources, and achieves state-of-the-art vector-quantization performance on i.i.d. sources, surpassing Trellis Coded Quantization on the Gaussian source.
Significance. If the rate-optimality guarantee survives composition with the learned transform and the reported gains are reproducible, the result would establish discrete binary structures as a practical route to optimal rate-distortion performance, directly addressing three long-standing limitations of the dominant NTC framework.
major comments (2)
- [Proof of rate optimality (binary channel simulation scheme)] The abstract asserts a proof of rate optimality for the fast binary channel simulation scheme, yet the central claim (closure of NTC limitations and attainment of optimal bounds) requires this optimality to hold after the scheme is embedded inside an end-to-end learned transform. The manuscript must explicitly state whether the proof assumes i.i.d. binary inputs or a memoryless channel independent of the preceding transform; if dependencies introduced by the learned mapping alter the effective channel, the optimality guarantee does not automatically transfer.
- [Experimental results] Experimental claims of superiority and SOTA vector-quantization performance are presented without dataset descriptions, error bars, or training details in the abstract; the full manuscript must supply these controls so that the reported gains can be verified against the information-theoretic sources and the Gaussian VQ benchmark.
minor comments (2)
- [Method] Notation for the stochastic binary latent space and the channel simulation parameters should be introduced with explicit definitions before the proof is presented.
- [Experiments] The abstract states that SBC 'achieves state-of-the-art performance on vector quantization of i.i.d. sources'; the corresponding table or figure should report the exact rate-distortion points and the baseline Trellis Coded Quantization implementation used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Proof of rate optimality (binary channel simulation scheme)] The abstract asserts a proof of rate optimality for the fast binary channel simulation scheme, yet the central claim (closure of NTC limitations and attainment of optimal bounds) requires this optimality to hold after the scheme is embedded inside an end-to-end learned transform. The manuscript must explicitly state whether the proof assumes i.i.d. binary inputs or a memoryless channel independent of the preceding transform; if dependencies introduced by the learned mapping alter the effective channel, the optimality guarantee does not automatically transfer.
Authors: We thank the referee for this important observation. The provided proof establishes rate optimality of the fast binary channel simulation under the standard assumptions of i.i.d. binary inputs and a memoryless channel. In the SBC architecture the learned transform produces the binary latents that are subsequently passed to this simulation module; the end-to-end training therefore optimizes the overall rate-distortion trade-off while the simulation step itself remains rate-optimal for any binary sequence it receives. We will revise the manuscript to state these assumptions explicitly and to clarify that dependencies, if present, are absorbed into the learned transform parameters rather than violating the simulation guarantee. revision: yes
-
Referee: [Experimental results] Experimental claims of superiority and SOTA vector-quantization performance are presented without dataset descriptions, error bars, or training details in the abstract; the full manuscript must supply these controls so that the reported gains can be verified against the information-theoretic sources and the Gaussian VQ benchmark.
Authors: Space limitations prevent inclusion of these details in the abstract. The full manuscript already contains a dedicated experimental section that describes the information-theoretic sources, the Gaussian VQ benchmark, training procedures, and reports results with error bars obtained from multiple independent runs. These controls are provided to enable verification of the claimed gains. We will ensure the presentation is sufficiently prominent and, if the referee deems any aspect still insufficient, we are prepared to expand it. revision: no
Circularity Check
No circularity detected in derivation chain
full rationale
The provided abstract and text present the rate-optimality result as a separate proof for the binary channel simulation scheme, independent of the learned transform. No equations or claims reduce the central results (rate-distortion closure, experimental gains) to inputs by construction, self-definition, or fitted parameters renamed as predictions. No self-citation load-bearing steps or ansatz smuggling are visible. The derivation chain is self-contained, relying on an external proof and experiments rather than circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
Integer Networks for Data Compression with Latent-Variable Models , year =
Ballé, Jona and Minnen, David and Johnston, Nick , booktitle =. Integer Networks for Data Compression with Latent-Variable Models , year =. S1zz2i0cY7 , eprinttype =
-
[3]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[4]
M. J. Kearns , title =
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[9]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
Ozyilkan, Ezgi and Ballé, Jona and Erkip, Elza , booktitle=. Learned. 2023 , volume=
2023
-
[11]
Neural Distributed Compressor Discovers Binning , year=
Ozyilkan, Ezgi and Ballé, Jona and Erkip, Elza , journal=. Neural Distributed Compressor Discovers Binning , year=
-
[12]
and Fischer, T.R
Marcellin, M.W. and Fischer, T.R. , journal=. Trellis coded quantization of memoryless and Gauss-Markov sources , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Approaching Rate-Distortion Limits in Neural Compression with Lattice Transform Coding , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
International Conference on Learning Representations , year=
End-to-end Optimized Image Compression , author=. International Conference on Learning Representations , year=
-
[15]
2020 , booktitle =
Agustsson, Eirikur and Theis, Lucas , title =. 2020 , booktitle =
2020
-
[16]
International Conference on Learning Representations , year=
Variational image compression with a scale hyperprior , author=. International Conference on Learning Representations , year=
-
[17]
and Minnen, David and Singh, Saurabh and Johnston, Nick and Agustsson, Eirikur and Hwang, Sung Jin and Toderici, George , journal=
Ballé, Johannes and Chou, Philip A. and Minnen, David and Singh, Saurabh and Johnston, Nick and Agustsson, Eirikur and Hwang, Sung Jin and Toderici, George , journal=. Nonlinear Transform Coding , year=
-
[18]
Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
Breaking Smoothness: The Struggles of Neural Compressors with Discontinuous Mappings , author=. Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
2024
-
[19]
and Ziv, J
Wyner, A. and Ziv, J. , journal=. The Rate--Distortion Function for Source Coding with Side Information at the Decoder , year=
-
[20]
and Thomas, Joy A
Cover, Thomas M. and Thomas, Joy A. , title =. 2006 , isbn =
2006
-
[21]
and Ramchandran, K
Pradhan, S.S. and Ramchandran, K. , journal=. Distributed source coding using syndromes (DISCUS): design and construction , year=
-
[22]
Advances in Neural Information Processing Systems , volume =
Richter, Lorenz and Boustati, Ayman and N\". Advances in Neural Information Processing Systems , volume =
-
[23]
International Conference on Learning Representations (ICLR) , year =
Auto-Encoding Variational Bayes , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
and Ballé, Johannes , booktitle=
Bhadane, Sourbh and Wagner, Aaron B. and Ballé, Johannes , booktitle=. Do Neural Networks Compress Manifolds Optimally? , year=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Ball\'e, Jona and Versari, Luca and Dupont, Emilien and Kim, Hyunjik and Bauer, Matthias , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[26]
Advances in Neural Information Processing Systems , volume =
High-Fidelity Generative Image Compression , author =. Advances in Neural Information Processing Systems , volume =
-
[27]
Gray, R. M. , journal=. Vector quantization , year=
-
[28]
, journal=
Ziv, J. , journal=. On universal quantization , year=
-
[29]
, journal=
Schuchman, L. , journal=. Dither Signals and Their Effect on Quantization Noise , year=
-
[30]
IRE Transactions on Information Theory , volume =
Picture coding using pseudo-random noise , author =. IRE Transactions on Information Theory , volume =. 1962 , publisher =
1962
-
[31]
and Feder, M
Zamir, R. and Feder, M. , journal=. On universal quantization by randomized uniform/lattice quantizers , year=
-
[32]
Proceedings of the 34th International Conference on Machine Learning , pages =
Real-Time Adaptive Image Compression , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Joint Autoregressive and Hierarchical Priors for Learned Image Compression , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[34]
Theis and W
L. Theis and W. Shi and A. Cunningham and F. Huszár. Lossy Image Compression with Compressive Autoencoders. International Conference on Learning Representations
-
[35]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Fast Channel Simulation via Error-Correcting Codes , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[36]
Channel Polarization: A Method for Constructing Capacity-Achieving Codes for Symmetric Binary-Input Memoryless Channels , year=
Arikan, Erdal , journal=. Channel Polarization: A Method for Constructing Capacity-Achieving Codes for Symmetric Binary-Input Memoryless Channels , year=
-
[37]
, journal =
Rissanen, Jorma J. , journal =. Generalized. 1976 , publisher =
1976
-
[38]
1999 , publisher =
Sphere Packings, Lattices and Groups , author =. 1999 , publisher =
1999
-
[39]
2013 , publisher =
JPEG2000 Image Compression Fundamentals, Standards and Practice , author =. 2013 , publisher =
2013
-
[40]
2014 , isbn =
Zamir, Ram , title =. 2014 , isbn =
2014
-
[41]
and Ballé, Jona , booktitle=
Wagner, Aaron B. and Ballé, Jona , booktitle=. Neural Networks Optimally Compress the Sawbridge , year=
-
[42]
Li, Jiahao and Li, Bin and Lu, Yan , title =. 2022 , isbn =. doi:10.1145/3503161.3547845 , booktitle =
-
[43]
Kot and Bihan Wen , booktitle=
Yufei Wang and Zhihao Li and Lanqing Guo and Wenhan Yang and Alex C. Kot and Bihan Wen , booktitle=. Context. 2024 , url=
2024
-
[44]
Learning Convolutional Transforms for Lossy Point Cloud Geometry Compression , year=
Quach, Maurice and Valenzise, Giuseppe and Dufaux, Frederic , booktitle=. Learning Convolutional Transforms for Lossy Point Cloud Geometry Compression , year=
-
[45]
and Bourdev, Lubomir , title =
Rippel, Oren and Nair, Sanjay and Lew, Carissa and Branson, Steve and Anderson, Alexander G. and Bourdev, Lubomir , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
-
[46]
Strong Functional Representation Lemma and Applications to Coding Theorems , year=
Li, Cheuk Ting and El Gamal, Abbas , journal=. Strong Functional Representation Lemma and Applications to Coding Theorems , year=
-
[47]
Foundations and Trends® in Communications and Information Theory , title =. 2024 , volume =. doi:10.1561/0100000141 , issn =
-
[48]
Bounds for entropy and divergence for distributions over a two-element set , journal =
Tops. Bounds for entropy and divergence for distributions over a two-element set , journal =
-
[49]
2010 IEEE International Symposium on Information Theory , pages=
Source polarization , author=. 2010 IEEE International Symposium on Information Theory , pages=. 2010 , organization=
2010
-
[50]
IEEE Transactions on information Theory , volume=
Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels , author=. IEEE Transactions on information Theory , volume=. 2009 , publisher=
2009
-
[51]
IBM Journal of research and development , volume=
Arithmetic coding , author=. IBM Journal of research and development , volume=. 1979 , publisher=
1979
-
[52]
Inequalities of
Kadelburg, Zoran and Dukic, Dusan and Lukic, Milivoje and Matic, Ivan , journal=. Inequalities of. 2005 , publisher=
2005
-
[53]
Advances in Neural Information Processing Systems , volume=
Greedy Poisson rejection sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
European Conference on Computer Vision , year=
HAC: Hash-grid Assisted Context for 3D Gaussian Splatting Compression , author=. European Conference on Computer Vision , year=
-
[55]
Pang, Jiahao and Lodhi, Muhammad Asad and Tian, Dong , title =. Proceedings of the 1st International Workshop on Advances in Point Cloud Compression, Processing and Analysis , year =. doi:10.1145/3552457.3555727 , isbn =
-
[56]
Foundations and Trends
Polarization and polar codes , author=. Foundations and Trends. 2012 , publisher=
2012
-
[57]
IEEE Transactions on Information Theory , volume=
Finite-length scaling for polar codes , author=. IEEE Transactions on Information Theory , volume=. 2014 , publisher=
2014
-
[58]
The art of computer programming , volume=
Seminumerical algorithms , author=. The art of computer programming , volume=. 1981 , publisher=
1981
-
[59]
IEEE Transactions on Information Theory , volume=
Empirical and strong coordination via soft covering with polar codes , author=. IEEE Transactions on Information Theory , volume=. 2018 , publisher=
2018
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Channel Simulation and Distributed Compression with Ensemble Rejection Sampling , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
Canadian Journal of Mathematics , volume=
Notes on sphere packings , author=. Canadian Journal of Mathematics , volume=. 1967 , publisher=. doi:10.4153/CJM-1967-017-0 , issn=
-
[62]
Towards Reproducible Learning-Based Compression , year=
Pang, Jiahao and Lodhi, Muhammad Asad and Ahn, Junghyun and Huang, Yuning and Tian, Dong , booktitle=. Towards Reproducible Learning-Based Compression , year=
-
[63]
Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression , year=
Shi, Junqi and Lu, Ming and Ma, Zhan , journal=. Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression , year=
-
[64]
Forney, G. D. , journal=. Trellis shaping , year=
-
[65]
Deep Learning-Based Image Compression with Trellis Coded Quantization , year=
Li, Binglin and Akbari, Mohammad and Liang, Jie and Wang, Yang , booktitle=. Deep Learning-Based Image Compression with Trellis Coded Quantization , year=
-
[66]
, booktitle=
Ballé, Jona and Laparra, Valero and Simoncelli, Eero P. , booktitle=. End-to-end optimization of nonlinear transform codes for perceptual quality , year=
-
[67]
Advances in Neural Information Processing Systems 30 (NIPS 2017) , pages=
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems 30 (NIPS 2017) , pages=
2017
-
[68]
Algorithmic Polarization for Hidden Markov Models
Algorithmic polarization for hidden markov models , author=. arXiv preprint arXiv:1810.01969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Concatenated Codes. 1965
1965
-
[70]
IEEE Transactions on Information Theory , volume=
Polar coding for processes with memory , author=. IEEE Transactions on Information Theory , volume=. 2019 , publisher=
2019
-
[71]
List Decoding of Polar Codes , year=
Tal, Ido and Vardy, Alexander , journal=. List Decoding of Polar Codes , year=
-
[72]
Polar Coding for Non-Stationary Channels , year=
Mahdavifar, Hessam , journal=. Polar Coding for Non-Stationary Channels , year=
-
[73]
Categorical Reparameterization with
Jang, Eric and Gu, Shixiang and Poole, Ben , booktitle=. Categorical Reparameterization with
-
[74]
International Conference on Learning Representations (ICLR) , year=
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author=. International Conference on Learning Representations (ICLR) , year=
-
[75]
, journal=
Lloyd, Stuart P. , journal=. Least squares quantization in
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.