DEEPMED Search: An Open-Source Agentic Platform for Medical Deep Research with Introspective Verification
Pith reviewed 2026-06-30 06:47 UTC · model grok-4.3
The pith
DEEPMED Search is an open-source agentic platform that routes medical queries to PubMed or web sources then verifies evidence with multi-agent debate before producing structured reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
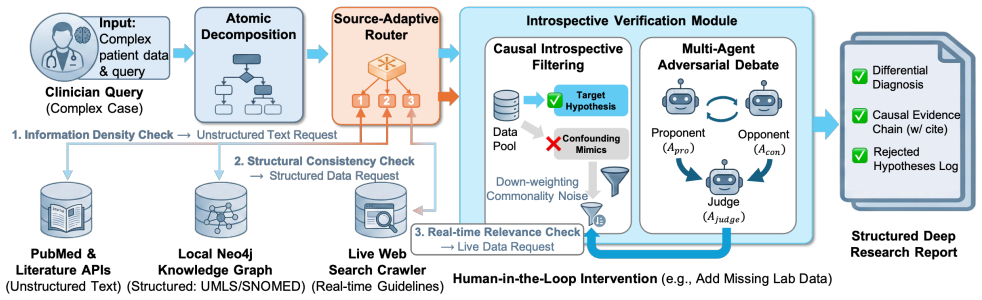
DEEPMED Search is a fully open-source agentic platform built on Next.js that contains a source-adaptive router dispatching sub-queries to PubMed, web search or local graph knowledge bases according to information density, together with an introspective verification module that applies a causal-consistent multi-agent debate framework to validate retrieved evidence against diagnostic logic prior to synthesis, thereby enabling autonomous decomposition of high-difficulty rare-disease queries into filtered, citation-backed structured reports.
What carries the argument
The introspective verification module powered by a causal-consistent multi-agent debate framework that validates retrieved evidence against diagnostic logic before synthesis.
If this is right
- Complex long-tail medical queries can be decomposed and answered with traceable citations without manual literature search.
- Noise from heterogeneous sources can be filtered before report generation.
- Open-source release supplies reusable infrastructure for glass-box medical reasoning in research settings.
- Report generation for rare-disease questions occurs on the order of minutes rather than hours or days.
Where Pith is reading between the lines
- The same routing-plus-verification pattern could be applied to other evidence-heavy domains such as legal case analysis.
- Adding more private clinical databases would test whether the router scales when local graph density increases.
- Measuring agreement between the multi-agent debate outputs and independent clinician review on the same queries would quantify verification reliability.
Load-bearing premise
The multi-agent debate reliably checks evidence against diagnostic logic without adding its own inconsistencies or overlooking key contradictions.
What would settle it
Run the system on a documented rare-disease case whose correct diagnostic logic is already settled in published guidelines; if the generated report includes a claim that directly contradicts those guidelines while citing the same sources, the verification claim is falsified.
Figures
read the original abstract
Navigating the deluge of heterogeneous medical data, from academic literature (PubMed) to clinical guidelines (Web) and private knowledge bases, remains a critical bottleneck for evidence-based medicine. While commercial black-box tools lack transparency, standard open-source RAG implementations frequently suffer from reasoning drift when handling complex, long-tail queries. We present DEEPMED Search, a fully open-source, agentic platform designed for transparent medical deep research. Built on a high-performance Next.js architecture, DEEPMED Search features a source-adaptive router that autonomously dispatches sub-queries to PubMed, web search, or local graph-based knowledge bases based on information density. Crucially, the platform integrates an introspective verification module, powered by a causal-consistent multi-agent debate framework, to validate retrieved evidence against diagnostic logic before synthesis. To demonstrate its robustness, we showcase DEEPMED Search's ability to autonomously decompose high-difficulty rare disease queries, filter out confounding noise, and generate structured, citation-backed research reports in minutes. By open-sourcing this software, we provide the community with a robust infrastructure to democratize access to trustworthy, glass-box medical reasoning in research and prototyping settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DEEPMED Search, a fully open-source agentic platform for transparent medical deep research built on Next.js. It features a source-adaptive router that dispatches sub-queries to PubMed, web search, or local graph-based knowledge bases according to information density, plus an introspective verification module that uses a causal-consistent multi-agent debate framework to validate retrieved evidence against diagnostic logic prior to synthesis. Robustness is demonstrated via narrative showcase examples in which the system autonomously decomposes high-difficulty rare-disease queries, filters confounding noise, and produces structured citation-backed reports in minutes.
Significance. If the described routing and verification components function as stated, the work would supply a glass-box, reproducible infrastructure that could help democratize trustworthy medical reasoning tools and serve as a baseline for future agentic medical systems. The explicit open-sourcing of the full platform is a concrete strength that enables community inspection and extension.
major comments (2)
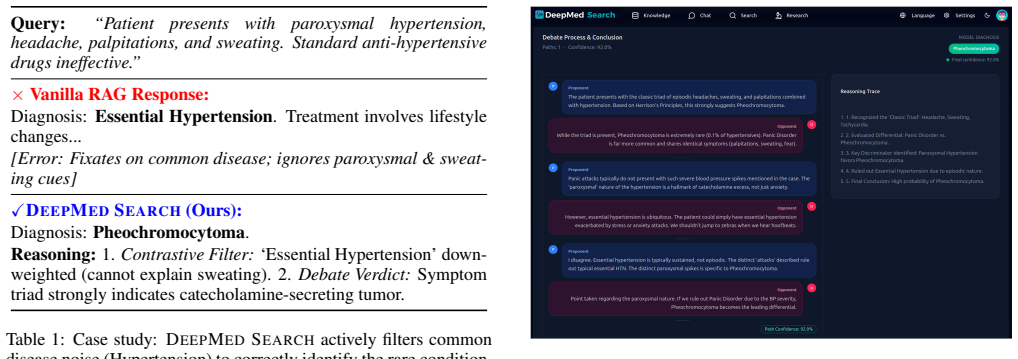
- [Abstract] Abstract: the central claim that the introspective verification module 'reliably validates retrieved evidence against diagnostic logic' and that the system 'autonomously decomposes high-difficulty rare disease queries, filters out confounding noise, and generates structured, citation-backed research reports in minutes' rests solely on unquantified narrative showcase examples; no success rates, latency distributions, clinician agreement scores, ablation results on the verification module, or comparisons against standard RAG or commercial baselines are reported anywhere in the manuscript.
- [Platform Architecture] The description of the source-adaptive router and causal-consistent multi-agent debate framework supplies only architectural intent and intended behavior; without any implementation-level pseudocode, parameter settings, or controlled evaluation of routing accuracy or debate outcomes, it is impossible to assess whether these components support the performance assertions.
minor comments (1)
- [Discussion] The manuscript would benefit from an explicit limitations section that discusses failure modes of the multi-agent debate (e.g., hallucination propagation or source bias) even if quantitative data are added later.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate additional implementation details and preliminary quantitative results where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the introspective verification module 'reliably validates retrieved evidence against diagnostic logic' and that the system 'autonomously decomposes high-difficulty rare disease queries, filters out confounding noise, and generates structured, citation-backed research reports in minutes' rests solely on unquantified narrative showcase examples; no success rates, latency distributions, clinician agreement scores, ablation results on the verification module, or comparisons against standard RAG or commercial baselines are reported anywhere in the manuscript.
Authors: We agree that the current manuscript supports its claims primarily through narrative showcase examples rather than quantitative metrics. As this is a systems paper focused on releasing an open-source platform, the examples were intended as demonstrations of capability. In the revised version we will (1) moderate the abstract language to avoid overstatement, (2) add a new evaluation section reporting success rates on a held-out set of rare-disease queries, latency distributions, ablation results isolating the verification module, and comparisons against a standard RAG baseline, and (3) explicitly list clinician agreement studies as future work outside the scope of the present contribution. revision: partial
-
Referee: [Platform Architecture] The description of the source-adaptive router and causal-consistent multi-agent debate framework supplies only architectural intent and intended behavior; without any implementation-level pseudocode, parameter settings, or controlled evaluation of routing accuracy or debate outcomes, it is impossible to assess whether these components support the performance assertions.
Authors: We will expand the Platform Architecture section with (a) pseudocode for both the source-adaptive router and the causal-consistent multi-agent debate procedure, (b) the concrete parameter settings and model choices used in the released implementation, and (c) controlled measurements of routing accuracy and verification-module outcomes on a small test suite. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: system description with no derivations or fitted predictions
full rationale
The manuscript is an architectural and implementation description of an open-source agentic platform. It defines components (source-adaptive router, introspective verification module, causal-consistent multi-agent debate) narratively and demonstrates behavior via showcase examples. No equations, parameter fitting, predictions, or self-citation chains appear in the provided text. The central claims are design assertions illustrated by examples rather than results derived from prior inputs by construction. This matches the default non-circular case for system papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
[Chanet al., 2023 ] Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate.arXiv preprint arXiv:2308.07201,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Improving fac- tuality and reasoning in language models through multi- agent debate
[Duet al., 2024 ] Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving fac- tuality and reasoning in language models through multi- agent debate. InForty-first international conference on machine learning,
2024
-
[3]
Leveraging passage retrieval with generative mod- els for open domain question answering
[Izacard and Grave, 2021] Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative mod- els for open domain question answering. InProceedings of the 16th conference of the european chapter of the asso- ciation for computational linguistics: main volume, pages 874–880,
2021
-
[4]
Survey of halluci- nation in natural language generation.ACM Computing Surveys, 55(12):1–38, March
[Jiet al., 2023 ] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of halluci- nation in natural language generation.ACM Computing Surveys, 55(12):1–38, March
2023
-
[5]
Large language models struggle to learn long-tail knowledge
[Kandpalet al., 2023 ] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learn- ing, ICML 2023, 23-29 July 2023, Honolu...
2023
-
[6]
Dense passage retrieval for open-domain question answering
[Karpukhinet al., 2020 ] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural lan- guage processing (EMNLP), pages 6769–6781,
2020
-
[7]
Causal reason- ing and large language models: Opening a new frontier for causality.Transactions on Machine Learning Research (TMLR), August
[Kicimanet al., 2024 ] Emre Kiciman, Robert Osazuwa Ness, Amit Sharma, and Chenhao Tan. Causal reason- ing and large language models: Opening a new frontier for causality.Transactions on Machine Learning Research (TMLR), August
2024
-
[8]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural infor- mation processing systems, 33:9459–9474,
[Lewiset al., 2020 ] Patrick Lewis, Ethan Perez, Aleksan- dra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K ¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural infor- mation processing systems, 33:9459–9474,
2020
-
[9]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
[Mallenet al., 2023 ] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the associ- ation for computational linguistics (volume 1: Long pa- pers), pages 9802–9822,
2023
-
[10]
[Park and Lee, 2024] Seong-Il Park and Jay-Yoon Lee. To- ward robust ralms: Revealing the impact of imperfect re- trieval on retrieval-augmented language models.Trans- actions of the Association for Computational Linguistics, 12:1686–1702,
2024
-
[11]
Cambridge University Press, Cambridge, 2nd edition,
[Pearl, 2009] Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge, 2nd edition,
2009
-
[12]
Quantifying the reasoning abilities of llms on real-world clinical cases
[Qiuet al., 2025 ] Pengcheng Qiu, Chaoyi Wu, Shuyu Liu, Weike Zhao, Zhuoxia Chen, Hongfei Gu, Chuanjin Peng, Ya Zhang, Yanfeng Wang, and Weidi Xie. Quantifying the reasoning abilities of llms on real-world clinical cases. arXiv preprint arXiv:2503.04691,
-
[13]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215,
[Rudin, 2019] Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215,
2019
-
[14]
Toward expert-level medical question an- swering with large language models.Nature medicine, 31(3):943–950,
[Singhalet al., 2025 ] Karan Singhal, Tao Tu, Juraj Got- tweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole- Lewis, et al. Toward expert-level medical question an- swering with large language models.Nature medicine, 31(3):943–950,
2025
-
[15]
Corrado, Yossi Matias, Karan Singhal, Pete Flo- rence, Alan Karthikesalingam, and Vivek Natarajan
[Tuet al., 2023 ] Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Si- mon Kornblith, David Fleet, Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, Christopher Sem- turs, S Sara Mahdavi, Bradley Green, Ewa D...
2023
-
[16]
[Wanget al., 2025 ] Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, and Yueming Jin. Medagent-pro: Towards evidence-based multi-modal medical diagnosis via reasoning agentic workflow.arXiv preprint arXiv:2503.18968,
-
[17]
Benchmarking retrieval-augmented generation for medicine
[Xionget al., 2024 ] Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. In Lun-Wei Ku, Andre Mar- tins, and Vivek Srikumar, editors,Findings of the Asso- ciation for Computational Linguistics ACL 2024, pages 6233–6251, Bangkok, Thailand and virtual meeting, Au- gust
2024
-
[18]
Association for Computational Linguistics. [Yanget al., 2022 ] Xi Yang, Aokun Chen, Nima PourNe- jatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Mona G Flores, Ying Zhang, Tanja Magoc, Christopher A Harle, Gloria Lipori, Duane A Mitchell, William R Hogan, Elizabeth A Shenkman, Jiang Bian, and Yonghui Wu. Gatortron...
2022
-
[19]
React: Synergizing reasoning and acting in language mod- els
[Yaoet al., 2022 ] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language mod- els. InThe eleventh international conference on learning representations, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.