The Forgetting-Retention Dilemma: Certified Unlearning Theory in Continual Learning
Pith reviewed 2026-06-30 07:10 UTC · model grok-4.3
The pith
Certified unlearning in continual learning must minimize post-unlearning excess risk that splits into a retention-forgetting trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate the CL's unlearning objective as the minimization of post-unlearning excess risk, which decomposes into CL excess risk and unlearning loss, characterizing the fundamental trade-off between preserving historical knowledge and targeted forgetting. Under mild assumptions, we first establish an upper bound for the CL excess risk in non-convex models. We then adapt two certified unlearning approaches, gradient-based and Hessian-based, to the CL framework. Our analysis reveals that while the gradient-based approach is less effective than the Hessian-based method in minimizing unlearning loss, it offers the distinct advantage of nearly zero storage overhead for enabling unlearning. Thi
What carries the argument
The decomposition of post-unlearning excess risk into CL excess risk plus unlearning loss, which isolates the retention-forgetting tension.
If this is right
- Gradient-based certified unlearning carries nearly zero storage overhead in the continual setting.
- Hessian-based certified unlearning reduces unlearning loss more effectively than the gradient version.
- A hybrid of the two methods lowers storage cost while preserving post-unlearning performance.
- The upper bound on CL excess risk applies to non-convex models under the stated assumptions.
- Experimental validation confirms the existence of the retention-forgetting trade-off.
Where Pith is reading between the lines
- The same excess-risk decomposition may extend to other sequential update regimes such as online or federated learning.
- Near-zero storage unlearning could enable privacy controls on memory-limited edge devices that run continual learners.
- Tightness of the excess-risk bound could be checked by varying model depth or data stream length in controlled trials.
- The hybrid approach might inform data-deletion compliance rules for streaming applications.
Load-bearing premise
The mild assumptions invoked to bound CL excess risk for non-convex models and to adapt the certified unlearning methods continue to hold.
What would settle it
An experiment on a non-convex continual learner in which measured post-unlearning excess risk either exceeds the derived upper bound or fails to exhibit the predicted storage-performance trade-off between the two adapted methods.
Figures



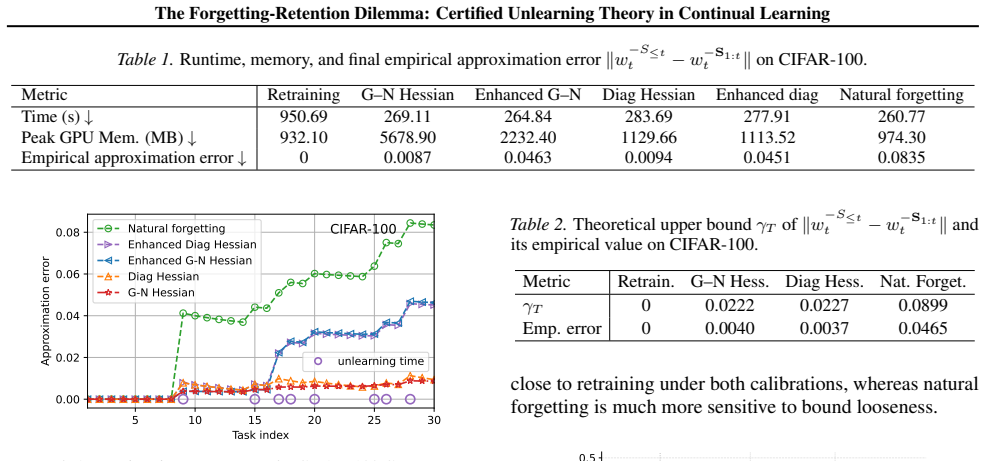

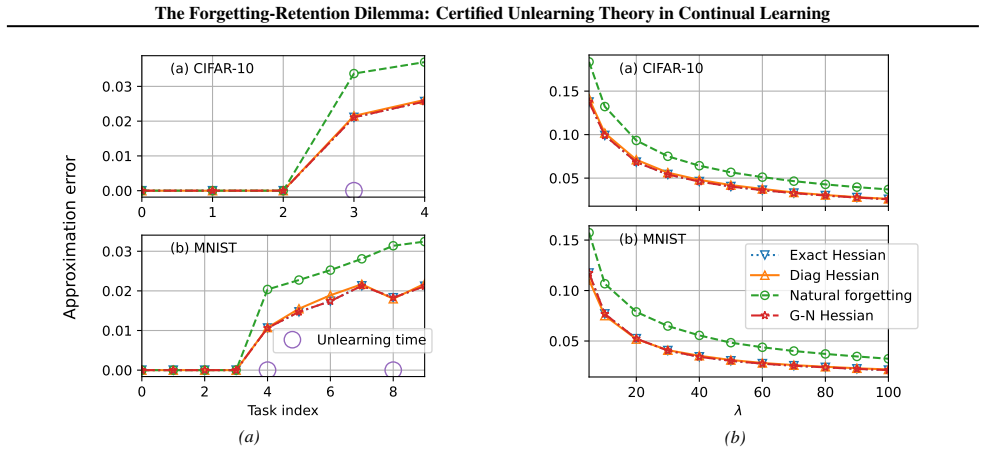
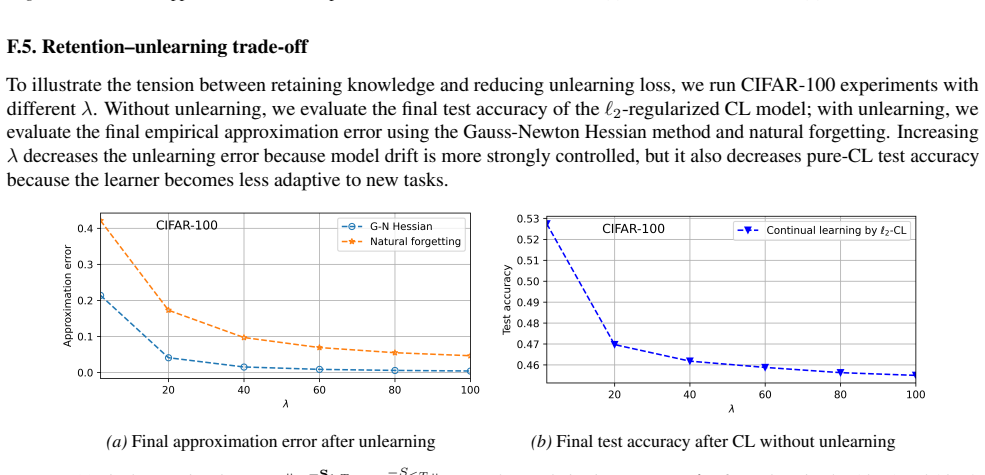
read the original abstract
Machine unlearning aims to eliminate the influence of specific data from trained models to safeguard privacy. However, this presents a significant challenge in the context of continual learning (CL), where models update sequentially on dynamic datasets. A major limitation is that current certified unlearning algorithms fail to account for the complex, cumulative model evolution inherent to CL framework. In this work, we establish the first theoretical foundation bridging CL and machine unlearning. We formulate the CL's unlearning objective as the minimization of post-unlearning excess risk, which decomposes into CL excess risk and unlearning loss, characterizing the fundamental trade-off between preserving historical knowledge and targeted forgetting. Under mild assumptions, we first establish an upper bound for the CL excess risk in non-convex models. We then adapt two certified unlearning approaches, gradient-based and Hessian-based, to the CL framework. Our analysis reveals that while the gradient-based approach is less effective than the Hessian-based method in minimizing unlearning loss, it offers the distinct advantage of nearly zero storage overhead for enabling unlearning. This insight motivates a hybrid strategy that reduces storage costs while maintaining post-unlearning performance. Experimental results further validate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish the first theoretical bridge between continual learning (CL) and certified machine unlearning. It formulates the unlearning objective as minimization of post-unlearning excess risk, which decomposes into CL excess risk plus unlearning loss to characterize the forgetting-retention trade-off. Under mild assumptions it derives an upper bound on CL excess risk for non-convex models, adapts gradient-based and Hessian-based certified unlearning methods to the CL setting, shows that the gradient approach has near-zero storage cost while the Hessian approach is more effective at minimizing unlearning loss, and proposes a hybrid strategy; experiments are said to validate the theory.
Significance. If the decomposition and bound are valid, the work supplies a formal characterization of the privacy-utility tension in sequential learning and a practical storage-performance trade-off via the hybrid method. The explicit decomposition of excess risk and the identification of storage advantages for gradient-based unlearning are concrete contributions that could guide future certified unlearning designs in non-stationary environments.
major comments (2)
- [Abstract / theoretical contributions paragraph] Abstract (theoretical contributions paragraph) and the section presenting the upper bound: the claim that an upper bound on CL excess risk holds for non-convex models under 'mild assumptions' is load-bearing for the central forgetting-retention trade-off, yet the assumptions are never listed explicitly and no verification is supplied that they survive the distribution shifts and cumulative parameter evolution that define CL. Without this, the bound does not demonstrably apply to the regimes the paper targets.
- [Adaptation of certified unlearning approaches] Section adapting certified unlearning methods: the adaptation of gradient-based and Hessian-based approaches to the CL framework is described at a high level without explicit modification steps, error-propagation analysis across sequential updates, or comparison of how each method interacts with the derived CL excess-risk bound. This leaves the claimed superiority of the hybrid strategy unsupported by the stated theory.
minor comments (1)
- [Abstract] The abstract states that experiments 'further validate our theoretical findings' but provides no quantitative metrics, baseline comparisons, or ablation on the hybrid strategy; adding these details would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our theoretical contributions. We address each major comment below and will revise the manuscript to improve explicitness and detail where needed.
read point-by-point responses
-
Referee: [Abstract / theoretical contributions paragraph] Abstract (theoretical contributions paragraph) and the section presenting the upper bound: the claim that an upper bound on CL excess risk holds for non-convex models under 'mild assumptions' is load-bearing for the central forgetting-retention trade-off, yet the assumptions are never listed explicitly and no verification is supplied that they survive the distribution shifts and cumulative parameter evolution that define CL. Without this, the bound does not demonstrably apply to the regimes the paper targets.
Authors: The assumptions (L-smoothness of the loss, bounded gradient norms, and bounded Hessian Lipschitz constants) are stated in the proof appendix and used in the non-convex excess-risk bound derivation. We agree that explicit listing and CL-specific verification would strengthen the main text. In revision we will enumerate the assumptions immediately before the bound statement and add a short paragraph confirming that the bound derivation already incorporates cumulative parameter evolution via the excess-risk decomposition, with the same assumptions holding across distribution shifts under standard CL bounded-variation conditions. revision: yes
-
Referee: [Adaptation of certified unlearning approaches] Section adapting certified unlearning methods: the adaptation of gradient-based and Hessian-based approaches to the CL framework is described at a high level without explicit modification steps, error-propagation analysis across sequential updates, or comparison of how each method interacts with the derived CL excess-risk bound. This leaves the claimed superiority of the hybrid strategy unsupported by the stated theory.
Authors: We accept that the adaptation section would benefit from greater granularity. The revision will expand the relevant section with (i) explicit algorithmic modification steps for both gradient- and Hessian-based methods in the sequential CL setting, (ii) an error-propagation analysis that tracks how approximation errors accumulate over task sequences, and (iii) a direct comparison of each method's effect on the CL excess-risk term in the decomposition. These additions will supply the missing theoretical linkage and better justify the hybrid strategy. revision: yes
Circularity Check
No circularity: derivation remains self-contained with no reductions to fitted inputs or self-citations
full rationale
The abstract defines the unlearning objective via a decomposition into CL excess risk and unlearning loss, then claims an upper bound under mild assumptions for non-convex models. No equations, proofs, or self-citations appear in the provided text that would allow any bound or prediction to reduce by construction to its inputs. The decomposition is a modeling choice rather than a tautology, and the bound is presented as derived rather than fitted or renamed. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild assumptions enabling upper bound on CL excess risk in non-convex models
Reference graph
Works this paper leans on
-
[1]
Y., Ahmed, S
Basaran, U. Y., Ahmed, S. M., Roy-Chowdhury, A., and Guler, B. A certified unlearning approach without access to source data. In Forty-second International Conference on Machine Learning, 2025
2025
-
[2]
Learning to unlearn: Instance-wise unlearning for pre-trained classifiers
Cha, S., Cho, S., Hwang, D., Lee, H., Moon, T., and Lee, M. Learning to unlearn: Instance-wise unlearning for pre-trained classifiers. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pp.\ 11186--11194, 2024
2024
-
[3]
A unified framework for continual learning and machine unlearning
Chatterjee, R., Chundawat, V., Tarun, A., Mali, A., and Mandal, M. A unified framework for continual learning and machine unlearning. arXiv e-prints, pp.\ arXiv--2408, 2024
2024
-
[4]
Efficient model updates for approximate unlearning of graph-structured data
Chien, E., Pan, C., and Milenkovic, O. Efficient model updates for approximate unlearning of graph-structured data. In The Eleventh International Conference on Learning Representations, 2022
2022
-
[5]
Certified machine unlearning via noisy stochastic gradient descent
Chien, E., Wang, H., Chen, Z., and Li, P. Certified machine unlearning via noisy stochastic gradient descent. Advances in Neural Information Processing Systems, 37: 0 38852--38887, 2024 a
2024
-
[6]
Langevin unlearning: A new perspective of noisy gradient descent for machine unlearning
Chien, E., Wang, H., Chen, Z., and Li, P. Langevin unlearning: A new perspective of noisy gradient descent for machine unlearning. Advances in neural information processing systems, 37: 0 79666--79703, 2024 b
2024
-
[7]
On lazy training in differentiable programming
Chizat, L., Oyallon, E., and Bach, F. On lazy training in differentiable programming. In Wallach, H., Larochelle, H., Beygelzimer, A., d Alch\' e -Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[8]
Unlocking the power of rehearsal in continual learning: A theoretical perspective
Deng, J., Wu, Q., Ju, P., Lin, S., Liang, Y., and Shroff, N. Unlocking the power of rehearsal in continual learning: A theoretical perspective. In Forty-second International Conference on Machine Learning, 2025
2025
-
[9]
The algorithmic foundations of differential privacy
Dwork, C., Roth, A., et al. The algorithmic foundations of differential privacy. Foundations and trends in theoretical computer science , 9 0 (3--4): 0 211--407, 2014
2014
-
[10]
How catastrophic can catastrophic forgetting be in linear regression? In Conference on Learning Theory, pp.\ 4028--4079
Evron, I., Moroshko, E., Ward, R., Srebro, N., and Soudry, D. How catastrophic can catastrophic forgetting be in linear regression? In Conference on Learning Theory, pp.\ 4028--4079. PMLR, 2022
2022
-
[11]
Certified data removal from machine learning models
Guo, C., Goldstein, T., Hannun, A., and Van Der Maaten, L. Certified data removal from machine learning models. In International Conference on Machine Learning, pp.\ 3832--3842. PMLR, 2020
2020
-
[12]
Adaptive machine unlearning
Gupta, V., Jung, C., Neel, S., Roth, A., Sharifi-Malvajerdi, S., and Waites, C. Adaptive machine unlearning. Advances in Neural Information Processing Systems, 34: 0 16319--16330, 2021
2021
-
[13]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
2016
-
[14]
Unlearning or obfuscating? jogging the memory of unlearned llms via benign relearning
Hu, S., Fu, Y., Wu, S., and Smith, V. Unlearning or obfuscating? jogging the memory of unlearned llms via benign relearning. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Neural tangent kernel: Convergence and generalization in neural networks
Jacot, A., Gabriel, F., and Hongler, C. Neural tangent kernel: Convergence and generalization in neural networks. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[17]
A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114 0 (13): 0 3521--3526, 2017
2017
-
[18]
Certified unlearning for neural networks
Koloskova, A., Allouah, Y., Jha, A., Guerraoui, R., and Koyejo, S. Certified unlearning for neural networks. In Forty-second International Conference on Machine Learning, 2025
2025
-
[19]
and Liang, Y
Li, Y. and Liang, Y. Learning overparameterized neural networks via stochastic gradient descent on structured data. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[20]
Theory on forgetting and generalization of continual learning
Lin, S., Ju, P., Liang, Y., and Shroff, N. Theory on forgetting and generalization of continual learning. In International Conference on Machine Learning, pp.\ 21078--21100. PMLR, 2023
2023
-
[21]
Continual learning and private unlearning
Liu, B., Liu, Q., and Stone, P. Continual learning and private unlearning. In Conference on Lifelong Learning Agents, pp.\ 243--254. PMLR, 2022
2022
-
[22]
Certified minimax unlearning with generalization rates and deletion capacity
Liu, J., Lou, J., Qin, Z., and Ren, K. Certified minimax unlearning with generalization rates and deletion capacity. Advances in Neural Information Processing Systems, 36: 0 62821--62852, 2023
2023
-
[23]
and Grosse, R
Martens, J. and Grosse, R. Optimizing neural networks with kronecker-factored approximate curvature. In Bach, F. and Blei, D. (eds.), Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pp.\ 2408--2417, Lille, France, 07--09 Jul 2015. PMLR
2015
-
[24]
Descent-to-delete: Gradient-based methods for machine unlearning
Neel, S., Roth, A., and Sharifi-Malvajerdi, S. Descent-to-delete: Gradient-based methods for machine unlearning. In Algorithmic Learning Theory, pp.\ 931--962. PMLR, 2021
2021
-
[25]
Numerical optimization, 2006
Nocedal, J. Numerical optimization, 2006
2006
-
[26]
and Soltanolkotabi, M
Oymak, S. and Soltanolkotabi, M. Overparameterized nonlinear learning: Gradient descent takes the shortest path? In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 4951--4960. PMLR, 09--15 Jun 2019
2019
-
[27]
Hessian-free online certified unlearning
Qiao, X., Zhang, M., Tang, M., and Wei, E. Hessian-free online certified unlearning. In International Conference on Learning Representations, volume 2025, pp.\ 32675--32711, 2025
2025
-
[28]
Sekhari, A., Acharya, J., Kamath, G., and Suresh, A. T. Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34: 0 18075--18086, 2021
2021
-
[29]
and Ben-David, S
Shalev-Shwartz, S. and Ben-David, S. Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014
2014
-
[30]
and Wilson, A
Suriyakumar, V. and Wilson, A. C. Algorithms that approximate data removal: New results and limitations. Advances in Neural Information Processing Systems, 35: 0 18892--18903, 2022
2022
-
[31]
Nearly optimal bounds for cyclic forgetting
Swartworth, W., Needell, D., Ward, R., Kong, M., and Jeong, H. Nearly optimal bounds for cyclic forgetting. Advances in neural information processing systems, 36: 0 68197--68206, 2023
2023
-
[32]
Tropp, J. A. An introduction to matrix concentration inequalities. Foundations and trends in machine learning , 8 0 (1-2): 0 1--230, 2015
2015
-
[33]
A., Zhang, Q., and Iosifidis, A
Vahedifar, M. A., Zhang, Q., and Iosifidis, A. Towards lifelong deep learning: A review of continual learning and unlearning methods, 2025
2025
-
[34]
High-Dimensional Probability: An Introduction with Applications in Data Science
Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2 edition, 2026
2026
-
[35]
Machine unlearning of features and labels
Warnecke, A., Pirch, L., Wressnegger, C., and Rieck, K. Machine unlearning of features and labels. In Proc. of the 30th Network and Distributed System Security (NDSS), 2023
2023
-
[36]
A statistical theory of regularization-based continual learning
Zhao, X., Wang, H., Huang, W., and Lin, W. A statistical theory of regularization-based continual learning. In International Conference on Machine Learning, pp.\ 61021--61039. PMLR, 2024
2024
-
[37]
The Thirteenth International Conference on Learning Representations , year=
Unlearning or obfuscating? jogging the memory of unlearned llms via benign relearning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[39]
Towards Lifelong Deep Learning: A Review of Continual Learning and Unlearning Methods , author=
-
[40]
Vershynin, Roman , title =
-
[41]
Understanding Machine Learning: From Theory to Algorithms , publisher=
Shalev-Shwartz, Shai and Ben-David, Shai , year=. Understanding Machine Learning: From Theory to Algorithms , publisher=
-
[42]
Learning Overparameterized Neural Networks via Stochastic Gradient Descent on Structured Data , volume =
Li, Yuanzhi and Liang, Yingyu , booktitle =. Learning Overparameterized Neural Networks via Stochastic Gradient Descent on Structured Data , volume =
-
[43]
Foundations and trends
An introduction to matrix concentration inequalities , author=. Foundations and trends. 2015 , publisher=
2015
-
[44]
2006 , publisher=
Numerical optimization , author=. 2006 , publisher=
2006
-
[45]
On Lazy Training in Differentiable Programming , volume =
Chizat, L\'. On Lazy Training in Differentiable Programming , volume =. Advances in Neural Information Processing Systems , editor =
-
[46]
Theory of Continual Learning Against Data Poisoning Attacks
Anonymous Authors. Theory of Continual Learning Against Data Poisoning Attacks
-
[47]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[48]
Quantitative Finance , volume =
Omiros Papaspiliopoulos , title =. Quantitative Finance , volume =. 2020 , publisher =
2020
-
[49]
Proceedings of the 36th International Conference on Machine Learning , pages =
Overparameterized Nonlinear Learning: Gradient Descent Takes the Shortest Path? , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[50]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , volume =
Jacot, Arthur and Gabriel, Franck and Hongler, Clement , booktitle =. Neural Tangent Kernel: Convergence and Generalization in Neural Networks , volume =
-
[51]
, author=
Learning with Selective Forgetting. , author=. IJCAI , volume=
-
[52]
, author=
Stochastic Convex Optimization. , author=. COLT , volume=
-
[53]
Conference on Lifelong Learning Agents , pages=
Continual learning and private unlearning , author=. Conference on Lifelong Learning Agents , pages=. 2022 , organization=
2022
-
[54]
Conference on Learning Theory , pages=
How catastrophic can catastrophic forgetting be in linear regression? , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[55]
International Conference on Machine Learning , pages=
A Statistical Theory of Regularization-Based Continual Learning , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[56]
International Conference on Machine Learning , pages=
Theory on forgetting and generalization of continual learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[57]
Proceedings of the AAAI conference on artificial intelligence , volume=
Learning to unlearn: Instance-wise unlearning for pre-trained classifiers , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[58]
arXiv preprint arXiv:2505.15178 , year=
A unified gradient-based framework for task-agnostic continual learning-unlearning , author=. arXiv preprint arXiv:2505.15178 , year=
-
[59]
arXiv e-prints , pages=
A unified framework for continual learning and machine unlearning , author=. arXiv e-prints , pages=
-
[60]
International Conference on Machine Learning , pages=
Certified Data Removal from Machine Learning Models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[61]
Algorithmic Learning Theory , pages=
Descent-to-delete: Gradient-based methods for machine unlearning , author=. Algorithmic Learning Theory , pages=. 2021 , organization=
2021
-
[62]
Forty-second International Conference on Machine Learning , year=
Unlocking the Power of Rehearsal in Continual Learning: A Theoretical Perspective , author=. Forty-second International Conference on Machine Learning , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Remember what you want to forget: Algorithms for machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Advances in Neural Information Processing Systems , volume=
Algorithms that approximate data removal: New results and limitations , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Advances in Neural Information Processing Systems , volume=
Certified minimax unlearning with generalization rates and deletion capacity , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
The Eleventh International Conference on Learning Representations , year=
Efficient model updates for approximate unlearning of graph-structured data , author=. The Eleventh International Conference on Learning Representations , year=
-
[67]
International Conference on Learning Representations , volume=
Hessian-free online certified unlearning , author=. International Conference on Learning Representations , volume=
-
[68]
Advances in Neural Information Processing Systems , volume=
Adaptive machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
2023 , booktitle=
Machine Unlearning of Features and Labels , author=. 2023 , booktitle=
2023
-
[70]
Advances in Neural Information Processing Systems , volume=
Certified machine unlearning via noisy stochastic gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Langevin unlearning: A new perspective of noisy gradient descent for machine unlearning , author=. Advances in neural information processing systems , volume=
-
[72]
A Statistical Theory of Regularization-Based Continual Learning , author=
-
[73]
The 22nd international conference on artificial intelligence and statistics , pages=
A continuous-time view of early stopping for least squares regression , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
2019
-
[74]
International Conference on Machine Learning , pages=
Generalization properties and implicit regularization for multiple passes SGM , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[75]
Proceedings of the European conference on computer vision (ECCV) , pages=
Memory aware synapses: Learning what (not) to forget , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[76]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[77]
International conference on artificial intelligence and statistics , pages=
Orthogonal gradient descent for continual learning , author=. International conference on artificial intelligence and statistics , pages=. 2020 , organization=
2020
-
[78]
Foundations and trends
The algorithmic foundations of differential privacy , author=. Foundations and trends. 2014 , publisher=
2014
-
[79]
IEEE Transactions on Information Forensics and Security , year=
On the Impact of Uncertainty and Calibration on Likelihood-Ratio Membership Inference Attacks , author=. IEEE Transactions on Information Forensics and Security , year=
-
[80]
2022 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , pages=. 2022 , organization=
2022
-
[81]
2017 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks against machine learning models , author=. 2017 IEEE symposium on security and privacy (SP) , pages=. 2017 , organization=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.