Smooth Scaling Laws Hide Stepwise Token Learning
Pith reviewed 2026-06-30 06:05 UTC · model grok-4.3
The pith
The distribution of when individual tokens are learned governs the shape of scaling laws in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
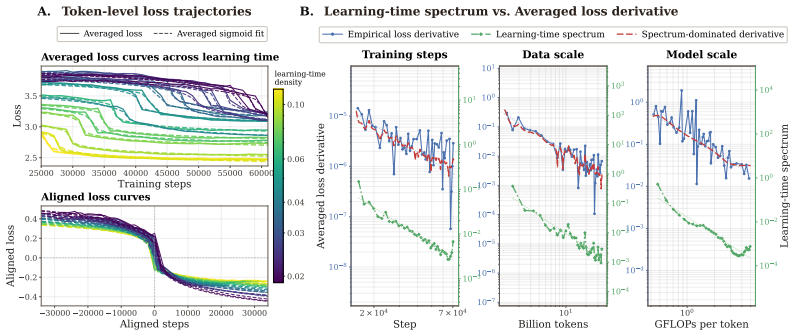
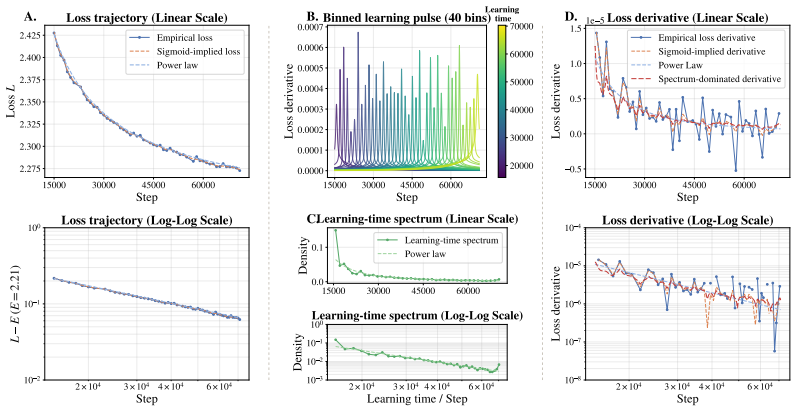
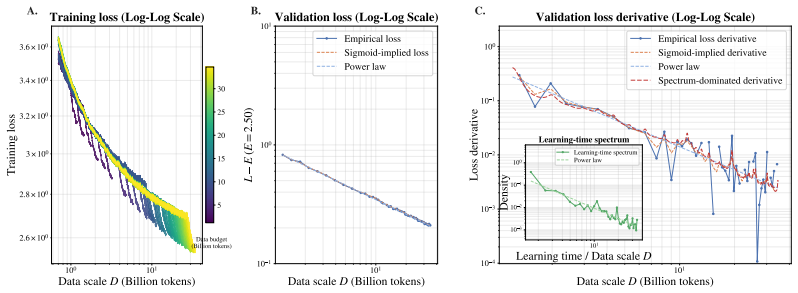
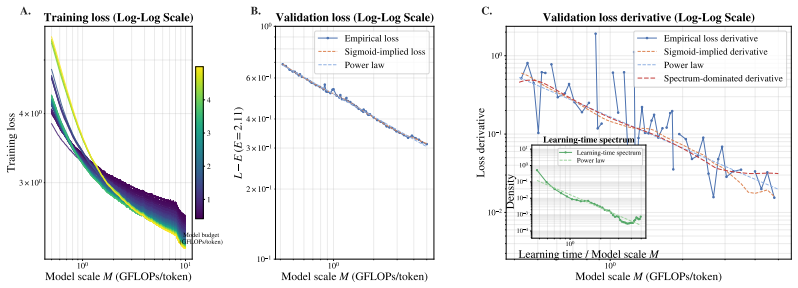
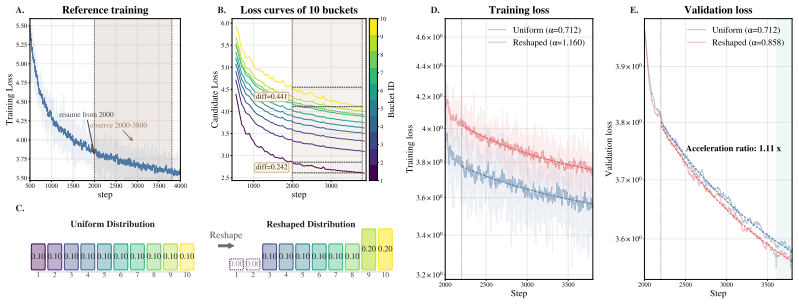
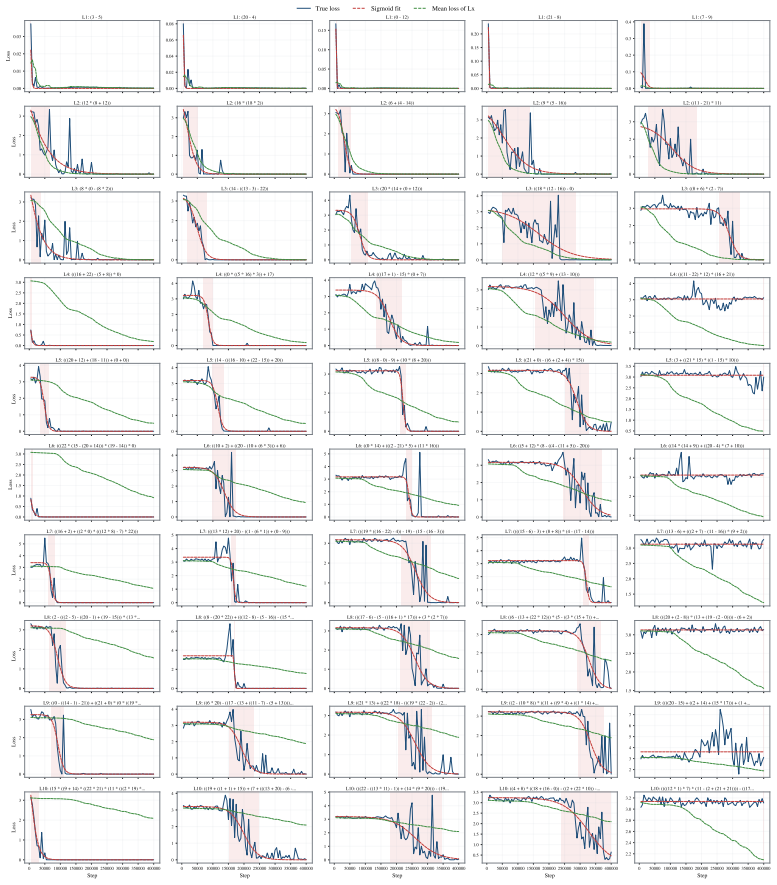
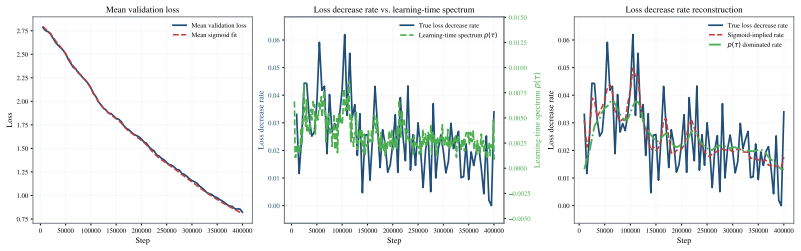
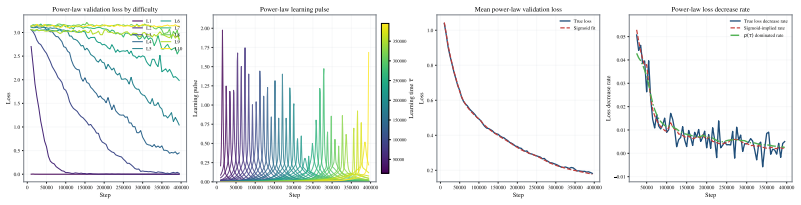
By fitting sigmoid curves to the loss trajectories of individual contextualized tokens across large-scale pre-training runs, the authors obtain a learning-time spectrum that dominates the scaling-law shape. This spectrum quantitatively reconstructs the validation loss derivative along the training-step T, data-scale D, and model-scale M axes. Reshaping the training distribution according to when tokens become learnable alters the optimization trajectory and yields faster validation-loss reduction.
What carries the argument
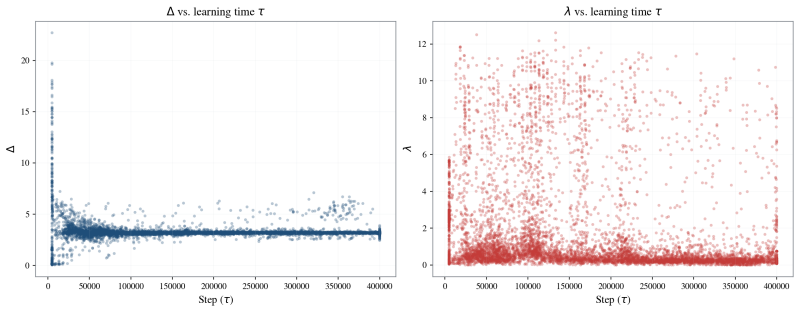
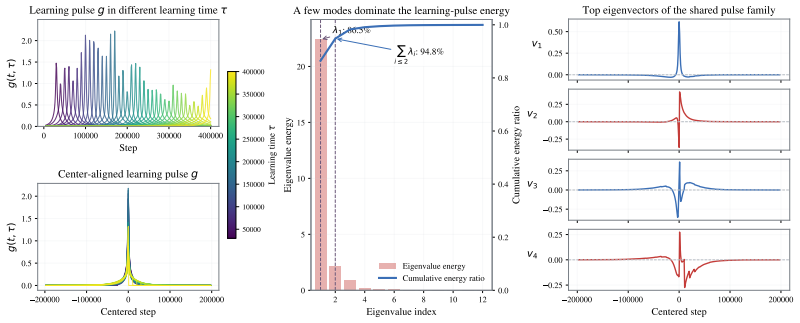
The learning-time spectrum extracted by fitting sigmoids to individual token loss trajectories.
If this is right
- The spectrum reconstructs validation loss derivatives along the T, D, and M axes.
- Reshaping the training distribution by token learnability times changes the optimization trajectory.
- The approach produces an 11 percent faster reduction in validation loss.
- Scaling laws are governed primarily by the distribution of token-level learning times rather than by a heavy-tailed difficulty spectrum.
Where Pith is reading between the lines
- The spectrum could be used to design data curricula that prioritize tokens according to their measured learnability times.
- If token interference remains low, the same fitting procedure might reveal stepwise structure in other sequence modeling domains.
- The method supplies a concrete way to test whether apparent smoothness in other scaling phenomena likewise hides discrete per-element transitions.
Load-bearing premise
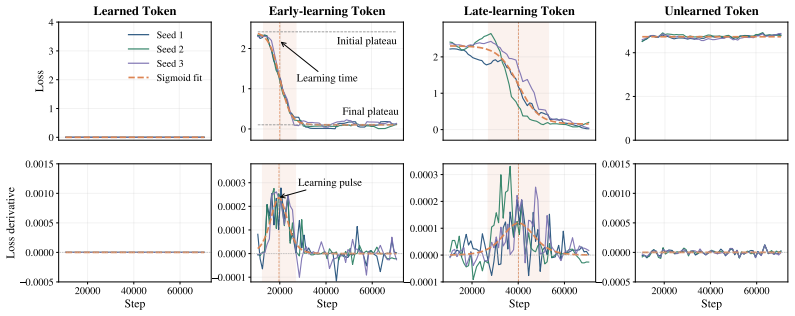
Individual token loss trajectories can be modeled accurately and independently as sigmoids that capture true localized learning events without substantial interference from other tokens or context changes.
What would settle it
New scaling runs in which the derivatives reconstructed from the measured spectrum fail to match the observed changes in validation loss along the T, D, or M axes would falsify the central claim.
Figures
read the original abstract
Language model loss follows remarkably regular scaling laws over model and data size, yet it remains unclear why the aggregate loss should exhibit a power-law form. Existing explanations often attribute this regularity to a heavy-tailed spectrum of pattern difficulty in natural language, but this view has not been directly validated at token-level granularity in large-scale real-data training. We present a token-level framework that decomposes scaling laws into localized learning events of individual contextualized tokens. By fitting token loss trajectories with sigmoids, we show that token learning is concentrated in localized transitions, giving rise to a learning-time spectrum that dominates the scaling-law shape. Across more than one hundred pre-training runs on large and diverse real-language corpora with modern LLM architectures, scaling up to 6B parameters and 300B training tokens, the measured learning-time spectrum quantitatively reconstructs the validation loss derivative along the training-step $T$, data-scale $D$, and model-scale $M$ axes. We further show that the same signal is actionable: by reshaping the training distribution according to when tokens become learnable, we alter the optimization trajectory and achieve 11\% faster validation-loss reduction. These results provide direct empirical evidence that scaling laws are governed primarily by the distribution of token-level learning times, and that this distribution can be used not only to explain scaling behavior but also to improve training performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fitting sigmoids to per-token loss trajectories across >100 pretraining runs (up to 6B parameters, 300B tokens) extracts a 'learning-time spectrum' that dominates scaling-law shape. This spectrum is asserted to quantitatively reconstruct validation-loss derivatives along the T, D, and M axes, and reshaping the training distribution according to token learnability yields an 11% faster validation-loss reduction.
Significance. If the reconstruction supplies evidence independent of the fitting process itself, the work would supply a token-granular, mechanistic account of why aggregate scaling laws are smooth and power-law-like, backed by unusually large-scale empirical coverage and an actionable downstream experiment. The scale of the experimental campaign is a clear strength.
major comments (2)
- [Abstract / reconstruction claim] Abstract and reconstruction results: because validation loss is defined as the mean of the contextualized token losses, and each trajectory is independently fit to a sigmoid, summation of the fitted sigmoids necessarily recovers the aggregate loss curve and its derivative by algebraic construction. The manuscript must demonstrate that the spectrum extracted from one subset of runs or tokens predicts the derivatives on held-out scales, architectures, or data regimes without refitting, rather than merely reproducing the curves from which the spectrum was derived.
- [actionable experiment] The 11% improvement experiment: the claim that reshaping the training distribution according to the spectrum alters the optimization trajectory requires explicit controls showing that the gain is not explained by changes in token frequency, total compute, or post-hoc selection of easier tokens. Without these, the result does not yet isolate the spectrum as the causal mechanism.
minor comments (2)
- [Abstract / results] The abstract and results sections should report fit quality metrics (R², residual distributions), error bars on the spectrum parameters, and any correction for multiple testing or post-hoc token selection.
- [methods] Notation for the per-token sigmoid parameters (midpoint, slope, asymptotes) should be introduced once and used consistently when discussing the spectrum.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of our claims regarding the reconstruction and the causal interpretation of the distribution-reshaping experiment. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / reconstruction claim] Abstract and reconstruction results: because validation loss is defined as the mean of the contextualized token losses, and each trajectory is independently fit to a sigmoid, summation of the fitted sigmoids necessarily recovers the aggregate loss curve and its derivative by algebraic construction. The manuscript must demonstrate that the spectrum extracted from one subset of runs or tokens predicts the derivatives on held-out scales, architectures, or data regimes without refitting, rather than merely reproducing the curves from which the spectrum was derived.
Authors: We agree that, for any fixed set of fitted trajectories, the mean of the sigmoids algebraically recovers the observed aggregate loss and its derivative. The manuscript's reconstruction claim is that the extracted learning-time spectrum (i.e., the distribution of sigmoid midpoints and widths) is the dominant factor shaping the observed derivatives when T, D, or M is varied. To address the concern about independence from the fitting process, we will add a new subsection with cross-validation experiments: the spectrum parameters will be estimated from a subset of runs (or tokens) at smaller scales and then used, without refitting individual trajectories, to predict the shape of the loss derivatives on held-out larger-scale runs. These results will be reported in the revised manuscript. revision: yes
-
Referee: [actionable experiment] The 11% improvement experiment: the claim that reshaping the training distribution according to the spectrum alters the optimization trajectory requires explicit controls showing that the gain is not explained by changes in token frequency, total compute, or post-hoc selection of easier tokens. Without these, the result does not yet isolate the spectrum as the causal mechanism.
Authors: We accept that the current presentation of the 11% result does not sufficiently isolate the spectrum as the causal factor. In the revision we will add matched-control experiments that (i) preserve the same token-frequency distribution and total compute budget while applying a non-learnability-based reweighting, (ii) compare against a baseline that simply up-weights tokens that happen to be easier under the original distribution, and (iii) report training curves with identical optimizer settings and data ordering except for the spectrum-derived weights. These controls will be included to demonstrate that the observed acceleration is attributable to the timing information in the spectrum rather than frequency or selection artifacts. revision: yes
Circularity Check
Fitted sigmoid spectrum reconstructs aggregate loss derivative by direct summation
specific steps
-
fitted input called prediction
[Abstract]
"By fitting token loss trajectories with sigmoids, we show that token learning is concentrated in localized transitions, giving rise to a learning-time spectrum that dominates the scaling-law shape. [...] the measured learning-time spectrum quantitatively reconstructs the validation loss derivative along the training-step $T$, data-scale $D$, and model-scale $M$ axes."
Validation loss equals the mean of the contextualized token losses. Once sigmoids are fitted to the individual trajectories, their average directly yields the aggregate loss curve (and its derivative) by summation. The reported 'quantitative reconstruction' therefore holds by construction from the same fitted quantities rather than providing independent confirmation that the distribution of learning times governs the scaling laws.
full rationale
The paper extracts a learning-time spectrum by fitting sigmoids to per-token loss trajectories, then claims this spectrum quantitatively reconstructs the validation-loss derivatives. Because validation loss is defined as the mean of those same token losses, averaging the fitted sigmoids necessarily recovers the aggregate curve and its derivative by algebraic construction. This matches the 'fitted_input_called_prediction' pattern: the reconstruction is statistically forced once the per-token fits are performed and does not supply independent evidence that the spectrum governs scaling-law shape. The 11% training-distribution experiment supplies limited external grounding, but the core reconstruction step remains tied to the fitted inputs, producing partial circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-token sigmoid parameters (midpoint, slope, asymptotes)
axioms (1)
- domain assumption Token losses evolve independently and can be modeled as isolated sigmoid transitions without significant cross-token interference during training.
invented entities (1)
-
learning-time spectrum
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems, pages 30016–30030, 2022
2022
-
[3]
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, et al. Language models scale reliably with over-training and on downstream tasks. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[4]
Hutter, Learning curve theory, arXiv preprint arXiv:2102.04074 (2021)
Marcus Hutter. Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
-
[5]
The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36:28699–28722, 2023
Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36:28699–28722, 2023
2023
-
[6]
Alexander Maloney, Daniel A. Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
-
[7]
Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
Ari Brill. Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
-
[8]
Learning curves theory for hierarchi- cally compositional data with power-law distributed features
Francesco Cagnetta, Hyunmo Kang, and Matthieu Wyart. Learning curves theory for hierarchi- cally compositional data with power-law distributed features. InInternational Conference on Machine Learning, pages 6149–6164. PMLR, 2025
2025
-
[9]
Zipf’s word frequency law in natural language: A critical review and future directions.Psychonomic bulletin & review, 21(5):1112–1130, 2014
Steven T Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions.Psychonomic bulletin & review, 21(5):1112–1130, 2014
2014
-
[10]
Zipf’s law revisited: Spoken dialog, linguistic units, parameters, and the principle of least effort.Psychonomic Bulletin & Review, 30(1):77–101, 2023
Guido M Linders and Max M Louwerse. Zipf’s law revisited: Spoken dialog, linguistic units, parameters, and the principle of least effort.Psychonomic Bulletin & Review, 30(1):77–101, 2023
2023
-
[11]
Yian Zhang, Alex Warstadt, Xiaocheng Li, and Samuel Bowman. When do you need billions of words of pretraining data? InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 1112–1125, 2021. 10
2021
-
[12]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[13]
Curriculum learning for natural language understanding
Benfeng Xu, Licheng Zhang, Zhendong Mao, Quan Wang, Hongtao Xie, and Yongdong Zhang. Curriculum learning for natural language understanding. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 6095–6104, 2020
2020
-
[14]
Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36: 69798–69818, 2023
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36: 69798–69818, 2023
2023
-
[15]
Efficient online data mixing for language model pre-training.arXiv preprint arXiv:2312.02406, 2023
Alon Albalak, Liangming Pan, Colin Raffel, and William Yang Wang. Efficient online data mixing for language model pre-training.arXiv preprint arXiv:2312.02406, 2023
-
[16]
Beyond random sampling: Efficient language model pretraining via curriculum learning
Yang Zhang, Amr Mohamed, Hadi Abdine, Guokan Shang, and Michalis Vazirgiannis. Beyond random sampling: Efficient language model pretraining via curriculum learning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5776–5794, 2026
2026
-
[17]
Resolving discrepancies in compute-optimal scaling of language models.Advances in Neural Information Processing Systems, 37:100535–100570, 2024
Tomer Porian, Mitchell Wortsman, Jenia Jitsev, Ludwig Schmidt, and Yair Carmon. Resolving discrepancies in compute-optimal scaling of language models.Advances in Neural Information Processing Systems, 37:100535–100570, 2024
2024
-
[18]
Revisiting scaling laws for language models: The role of data quality and training strategies
Zhengyu Chen, Siqi Wang, Teng Xiao, Yudong Wang, Shiqi Chen, Xunliang Cai, Junxian He, and Jingang Wang. Revisiting scaling laws for language models: The role of data quality and training strategies. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23881–23899, 2025
2025
-
[19]
Binghui Li, Fengling Chen, Zixun Huang, Lean Wang, and Lei Wu. Functional scaling laws in kernel regression: Loss dynamics and learning rate schedules.arXiv preprint arXiv:2509.19189, 2025
-
[20]
A multi-power law for loss curve prediction across learning rate schedules
Kairong Luo, Haodong Wen, Shengding Hu, Zhenbo Sun, Zhiyuan Liu, Maosong Sun, Kaifeng Lyu, and Wenguang Chen. A multi-power law for loss curve prediction across learning rate schedules. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[21]
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 1, learning hierarchical language structures.arXiv preprint arXiv:2305.13673, 2023
-
[22]
Maissam Barkeshli, Alberto Alfarano, and Andrey Gromov. On the origin of neural scaling laws: from random graphs to natural language.arXiv preprint arXiv:2601.10684, 2026
-
[23]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[24]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International conference on machine learning, pages 2397–2430. PMLR, 2023
2023
-
[25]
Training trajectories of language models across scales
Mengzhou Xia, Mikel Artetxe, Chunting Zhou, Xi Victoria Lin, Ramakanth Pasunuru, Danqi Chen, Luke Zettlemoyer, and Veselin Stoyanov. Training trajectories of language models across scales. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13711–13738, 2023
2023
-
[26]
Not all tokens are what you need for pretraining.Advances in Neural Information Processing Systems, 37:29029–29063, 2024
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, et al. Not all tokens are what you need for pretraining.Advances in Neural Information Processing Systems, 37:29029–29063, 2024. 11
2024
-
[27]
Tyler A Chang, Zhuowen Tu, and Benjamin K Bergen. Characterizing learning curves during language model pre-training: Learning, forgetting, and stability.Transactions of the Association for Computational Linguistics, 12:1346–1362, 2024
2024
-
[28]
Language model behavioral phases are consistent across architecture, training data, and scale
James A Michaelov, Roger P Levy, and Ben Bergen. Language model behavioral phases are consistent across architecture, training data, and scale. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[29]
An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem.Advances in Neural Information Processing Systems, 37:39632–39693, 2024
Yoonsoo Nam, Nayara Fonseca, Seok H Lee, Chris Mingard, and Ard A Louis. An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem.Advances in Neural Information Processing Systems, 37:39632–39693, 2024
2024
-
[30]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
A hitchhiker’s guide to scaling law estimation
Leshem Choshen, Yang Zhang, and Jacob Andreas. A hitchhiker’s guide to scaling law estimation. InInternational Conference on Machine Learning, pages 10683–10699. PMLR, 2025
2025
-
[33]
A dynamical model of neural scaling laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws. InProceedings of the 41st International Conference on Machine Learning, pages 4345–4382, 2024
2024
-
[34]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Skill-it! a data-driven skills framework for understanding and training language models.Advances in Neural Information Processing Systems, 36:36000–36040, 2023
Mayee Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christo- pher Ré. Skill-it! a data-driven skills framework for understanding and training language models.Advances in Neural Information Processing Systems, 36:36000–36040, 2023
2023
-
[36]
Curriculum learning for small code language models
Marwa Naïr, Kamel Yamani, Lynda Lhadj, and Riyadh Baghdadi. Curriculum learning for small code language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop), pages 390–401, 2024
2024
-
[37]
Competence-based curriculum learning for neural machine translation
Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, and Tom Mitchell. Competence-based curriculum learning for neural machine translation. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 1162–1...
2019
-
[38]
Frequency explains the inverse correlation of large language models’ size, training data amount, and surprisal’s fit to reading times
Byung-Doh Oh, Shisen Yue, and William Schuler. Frequency explains the inverse correlation of large language models’ size, training data amount, and surprisal’s fit to reading times. InPro- ceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2644–2663, 2024
2024
-
[39]
Learning in-context n-grams with transformers: Sub-n-grams are near-stationary points
Aditya Varre, Gizem Yüce, and Nicolas Flammarion. Learning in-context n-grams with transformers: Sub-n-grams are near-stationary points. InInternational Conference on Machine Learning, pages 60924–60963. PMLR, 2025
2025
-
[40]
Francesco Cagnetta, Allan Raventós, Surya Ganguli, and Matthieu Wyart. Deriving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488, 2026
-
[41]
Physics of language models: Part 4.1, architecture design and the magic of canon layers
Zeyuan Allen-Zhu. Physics of language models: Part 4.1, architecture design and the magic of canon layers.arXiv preprint arXiv:2512.17351, 2025. 12 A Appendix Contents A Appendix 13 A.1 Why the token distribution in natural language is power-law . . . . . . . . . . . . 13 A.2 Alignment Between Learning Time and Macroscopic Data Consensus . . . . . . . 14 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.