LatentRevise: Learning from Zero-Hit Reasoning
Pith reviewed 2026-06-30 06:34 UTC · model grok-4.3
The pith
LatentRevise recovers training signal from failed rollouts by revising reasoning prefix embeddings toward correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
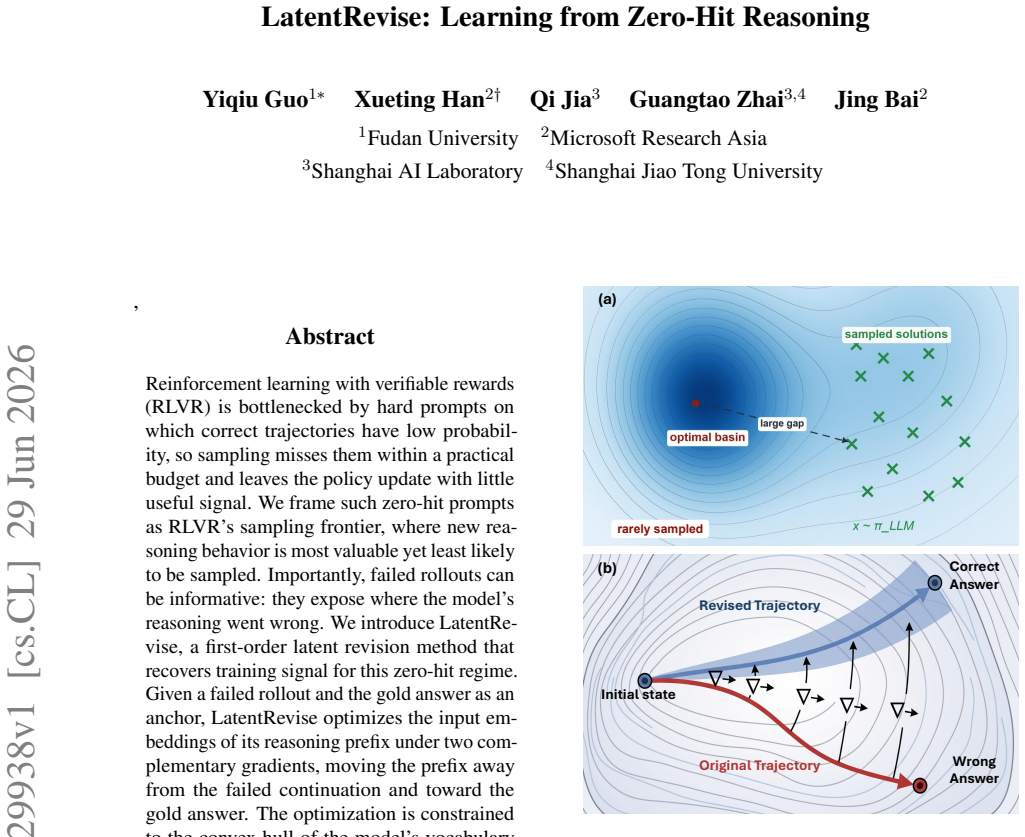
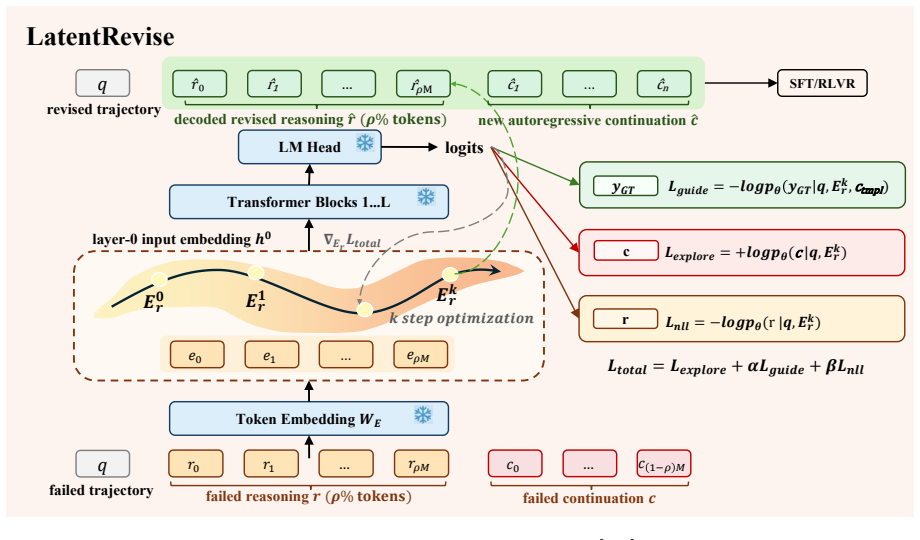
LatentRevise is a first-order latent revision method that, given a failed rollout and the gold answer, optimizes the input embeddings of the reasoning prefix under two complementary gradients while constraining updates to the convex hull of the model's vocabulary embeddings, thereby generating continuations that reach correct answers missed by the original policy.
What carries the argument
The constrained optimization of reasoning prefix embeddings using gradients from failed and correct paths within the convex hull of vocabulary embeddings.
If this is right
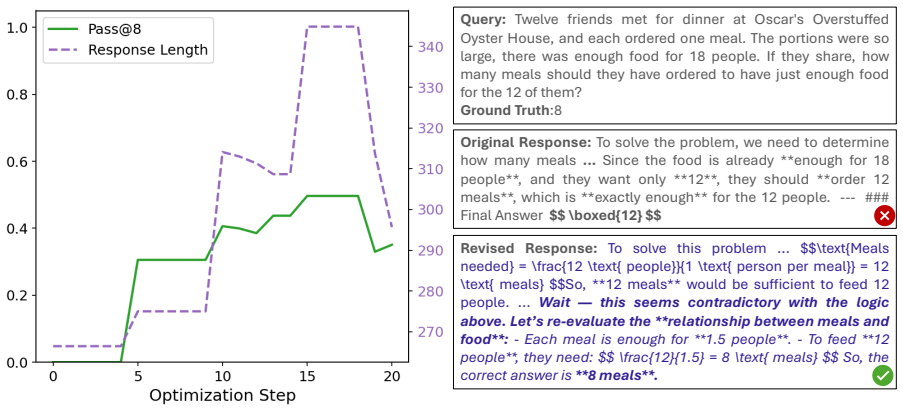
- The revised prefixes produce continuations that lengthen and exhibit self-reflection.
- These continuations reach correct answers that the original sampling missed.
- Trajectories from the revised prefixes improve performance when used for supervised fine-tuning on math benchmarks.
- The same trajectories also improve reinforcement learning with verifiable rewards over standard baselines.
Where Pith is reading between the lines
- Applying this revision process could lower the sampling budget needed to find useful signals in RLVR setups.
- The method might extend to other tasks with verifiable outcomes where sampling correct paths is rare.
- Further tests could check if removing the convex hull constraint leads to less useful or harmful training examples.
Load-bearing premise
Gradient updates to the reasoning prefix embedding within the convex hull of vocabulary embeddings will generate continuations that are correct and beneficial for training rather than unhelpful or misleading ones.
What would settle it
Running the method on a set of zero-hit prompts and finding that the generated trajectories do not lead to higher benchmark scores than training on the original failed rollouts or random data.
Figures
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) is bottlenecked by hard prompts on which correct trajectories have low probability, so sampling misses them within a practical budget and leaves the policy update with little useful signal. We frame such zero-hit prompts as RLVR's sampling frontier, where new reasoning behavior is most valuable yet least likely to be sampled. Importantly, failed rollouts can be informative: they expose where the model's reasoning went wrong. We introduce LatentRevise, a first-order latent revision method that recovers training signal for this zero-hit regime. Given a failed rollout and the gold answer as an anchor, LatentRevise optimizes the input embeddings of its reasoning prefix under two complementary gradients, moving the prefix away from the failed continuation and toward the gold answer. The optimization is constrained to the convex hull of the model's vocabulary embeddings, so each update moves the latent toward a real token embedding rather than an arbitrary feature direction. We find that continuations from the revised prefix lengthen, exhibit self-reflection, and reach correct answers missed by the original rollouts. Used as training data, these trajectories improve SFT and RLVR on math benchmarks over standard baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LatentRevise, a first-order optimization method for zero-hit prompts in RLVR. Given a failed rollout and gold answer, it revises the reasoning prefix embedding by applying complementary gradients (away from the failed continuation, toward the gold answer) while constraining updates to the convex hull of the model's vocabulary embeddings. The resulting continuations are claimed to be longer, self-reflective, and correct; when used as training data they improve both SFT and RLVR performance on math benchmarks relative to standard baselines.
Significance. If the empirical results hold, the method supplies a concrete mechanism for extracting usable training signal from the RLVR sampling frontier. The vocabulary-hull constraint is a notable design choice that keeps revisions token-like rather than arbitrary. The paper supplies a clear, non-circular description of the procedure and correctly identifies the zero-hit regime as a high-value target.
major comments (1)
- [Abstract] Abstract: the central claim is that revised trajectories improve SFT and RLVR on math benchmarks, yet the abstract supplies no quantitative results, error bars, ablation studies, or verification that the generated trajectories remain distributionally safe for training. This absence prevents evaluation of the empirical claim from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive assessment of the method's potential significance. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim is that revised trajectories improve SFT and RLVR on math benchmarks, yet the abstract supplies no quantitative results, error bars, ablation studies, or verification that the generated trajectories remain distributionally safe for training. This absence prevents evaluation of the empirical claim from the provided text.
Authors: We agree that the abstract is currently high-level and lacks the requested quantitative details, which limits immediate evaluation of the empirical claims. This is a fair observation. In the revised manuscript we will update the abstract to report the main performance deltas on the math benchmarks (with reference to error bars from repeated runs), note the key ablations, and explicitly state that the vocabulary-hull constraint keeps revised prefixes within the convex hull of the model's token embeddings, thereby preserving distributional compatibility for downstream SFT and RLVR training. The body of the paper already contains these results and analyses; the revision will make the abstract self-contained. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical optimization procedure (gradient-based revision of prefix embeddings within the vocabulary convex hull, using signals from failed rollouts and gold answers) to generate training trajectories for SFT/RLVR. No equations, derivations, or first-principles results are presented that reduce any claimed prediction or improvement to a quantity defined in terms of itself. The central claim is that the generated trajectories empirically improve benchmarks, which is an external, falsifiable outcome rather than a self-referential identity or fitted input renamed as prediction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the provided description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. 2024 , eprint=
2024
-
[2]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv.org , author =
Revisiting. arXiv.org , author =. 2026 , file =
2026
-
[4]
arXiv.org , author =
Reinforcement. arXiv.org , author =. 2026 , file =
2026
-
[5]
arXiv.org , author =
Rethinking. arXiv.org , author =. 2026 , file =
2026
-
[6]
arXiv.org , author =
The. arXiv.org , author =. 2025 , file =
2025
-
[7]
arXiv.org , author =
Self-. arXiv.org , author =. 2026 , file =
2026
-
[8]
arXiv.org , author =
Seek in the. arXiv.org , author =. 2025 , file =
2025
-
[9]
arXiv.org , author =
Measuring. arXiv.org , author =. 2021 , file =
2021
-
[10]
arXiv.org , author =
T1:. arXiv.org , author =. 2025 , file =
2025
-
[11]
2024 , file =
arXiv.org , author =. 2024 , file =
2024
-
[12]
Laminar: A scalable asynchronous RL post-training framework
arXiv.org , author =. 2024 , doi =. doi:10.1145/3689031.3696075 , abstract =
-
[13]
arXiv.org , author =
\. arXiv.org , author =. 2026 , file =
2026
-
[14]
arXiv.org , author =
Qwen2.5. arXiv.org , author =. 2024 , file =
2024
-
[15]
arXiv.org , author =
Qwen3. arXiv.org , author =. 2025 , file =
2025
-
[16]
arXiv.org , author =
Does. arXiv.org , author =. 2025 , file =
2025
-
[17]
2025 , file =
arXiv.org , author =. 2025 , file =
2025
-
[18]
arXiv.org , author =
Inference-time. arXiv.org , author =. 2025 , file =
2025
-
[19]
arXiv.org , author =
Scaling. arXiv.org , author =. 2023 , file =
2023
-
[20]
2022 , file =
arXiv.org , author =. 2022 , file =
2022
-
[21]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[22]
2025 , month = apr, howpublished =
On-Policy Distillation: An Effective and Efficient Training Paradigm for Language Models , author =. 2025 , month = apr, howpublished =. doi:10.64480/xwxw-9c67 , url =
-
[23]
American Invitational Mathematics Examination (AIME) 2024 , author=
2024
-
[24]
American Invitational Mathematics Examination (AIME) 2025 , author=
2025
-
[25]
2026 , file =
math-ai/amc23 ·. 2026 , file =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.