Know Before You Fetch: Calibrated Retrieval-Budget Allocation for Retrieval-Augmented Generation
Pith reviewed 2026-06-30 04:22 UTC · model grok-4.3
The pith
Calibrated sequence log-probabilities let RAG systems choose per-query retrieval budgets instead of fixed k.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
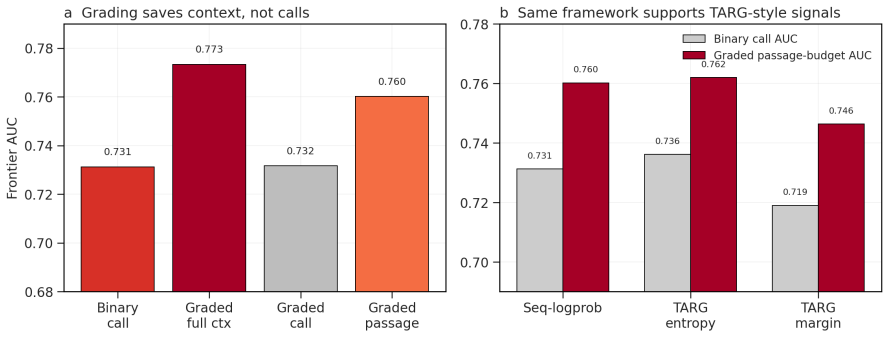
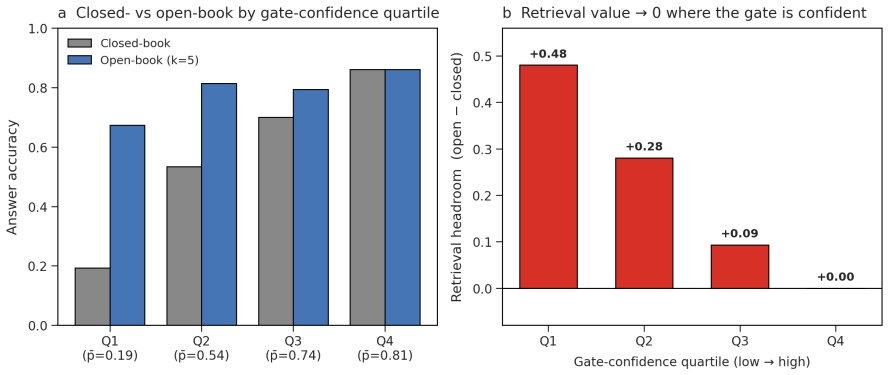
Diagnostic out-of-fold calibration converts sequence log-probability and prefix-logit signals into probabilities of correctness that support graded retrieval-budget allocation; across the three QA datasets this calibration reduces expected calibration error by factors of roughly four to seventy, and the resulting graded decisions improve both full-context and passage-budget frontiers while preserving retrieval-call AUC comparable to binary gating.
What carries the argument
The probability interface obtained by calibrating sequence log-probability into a probability of correctness, used for graded selection among closed-book, k=1, k=5, and abstain options.
If this is right
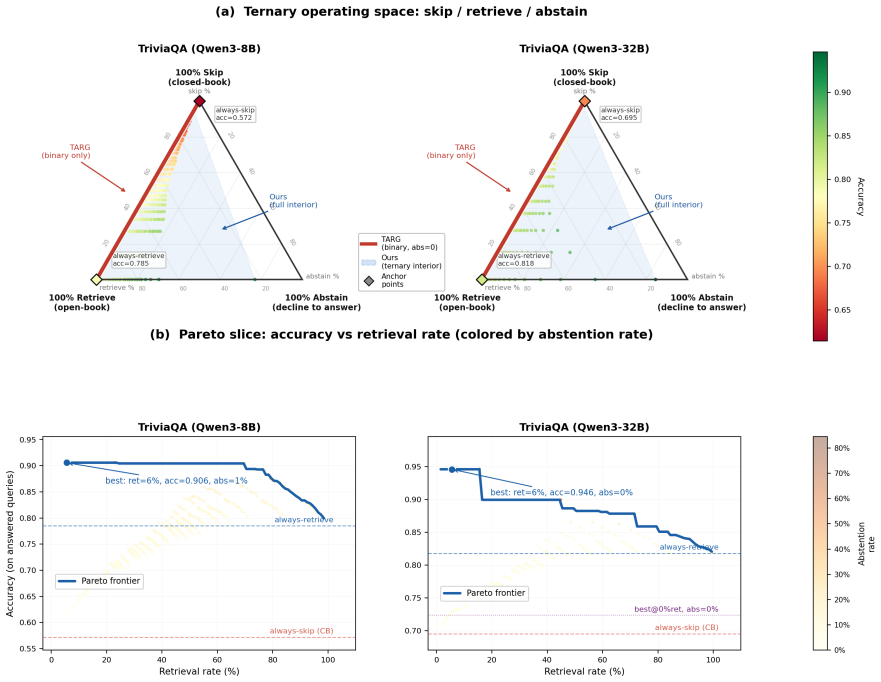
- Graded retrieval improves accuracy at both full-context and fixed passage-budget operating points for both the calibrated signal and TARG-style baselines.
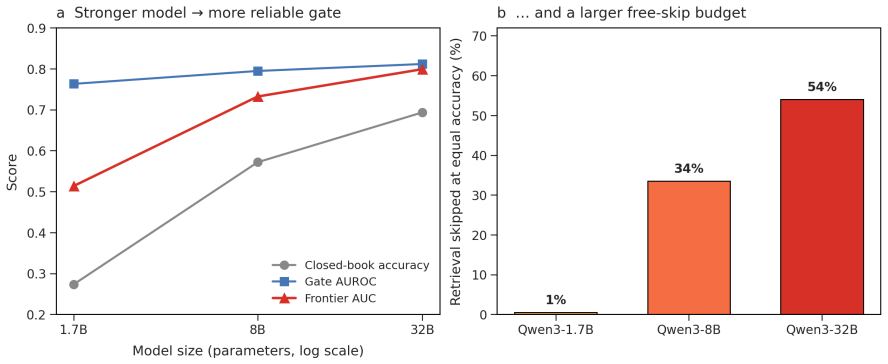
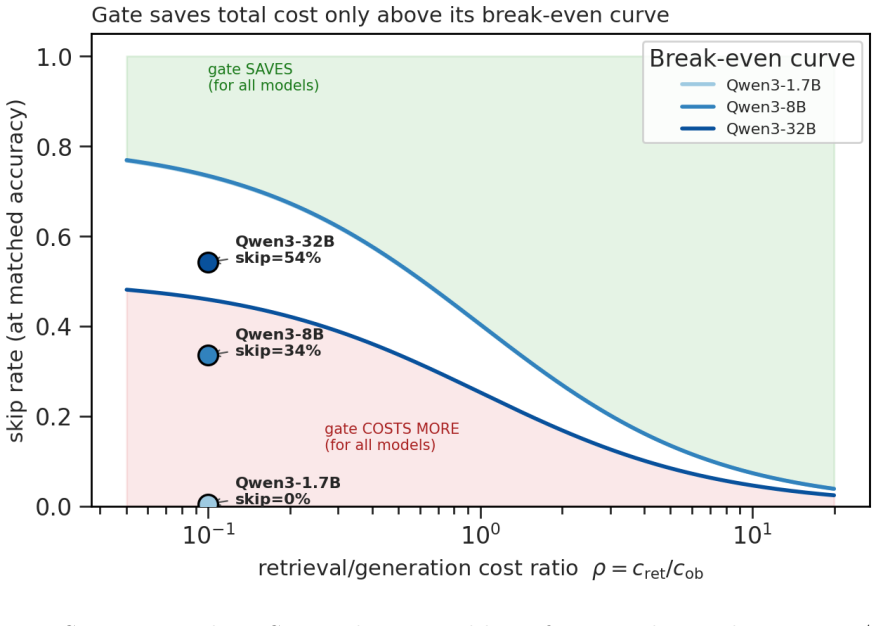
- At matched-accuracy frontier points the latency effect of gating is model-size dependent: roughly 27 percent slower on Qwen3-8B but 8 percent faster on Qwen3-32B.
- Retrieval-call AUC stays essentially unchanged from binary gating because k=1 still counts as a retrieval call.
- Held-out train/validation/test threshold sweeps yield concrete deployable operating points for each dataset and model.
Where Pith is reading between the lines
- The same calibrated interface could be reused to allocate other costly resources such as tool calls or longer generation lengths.
- If the calibration mapping proves stable across domains, it supplies a reusable layer that downstream systems can query without re-deriving uncertainty signals.
- The modest latency savings observed only on larger models suggest that adaptive RAG may become more attractive as base models grow.
Load-bearing premise
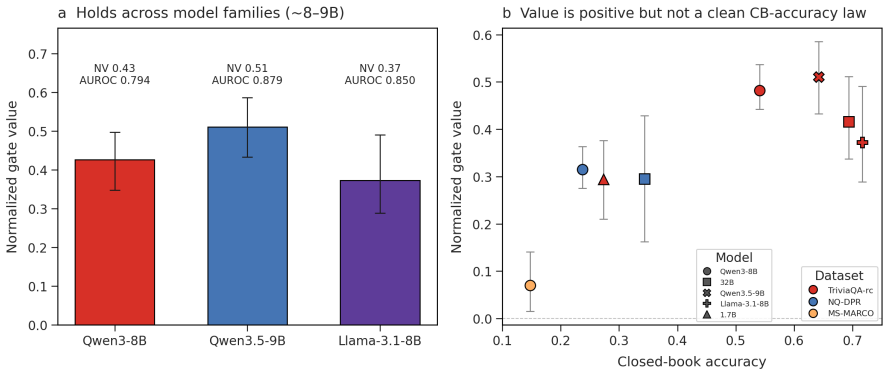
The calibration mapping learned on the training and validation splits of TriviaQA, NQ, and MS MARCO continues to produce reliable probabilities on unseen queries and on models outside the tested families.
What would settle it
Measure expected calibration error on a fresh held-out dataset or on a model from a different family; if ECE remains near the uncalibrated levels (0.27–0.71), the probability interface no longer supports the claimed budget-allocation gains.
Figures
read the original abstract
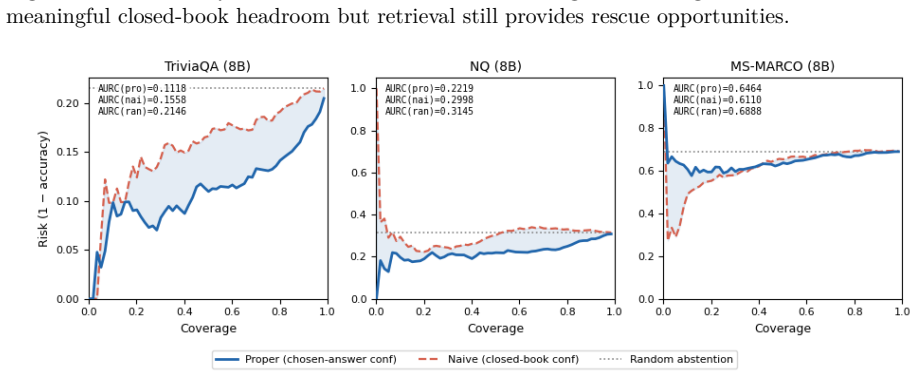
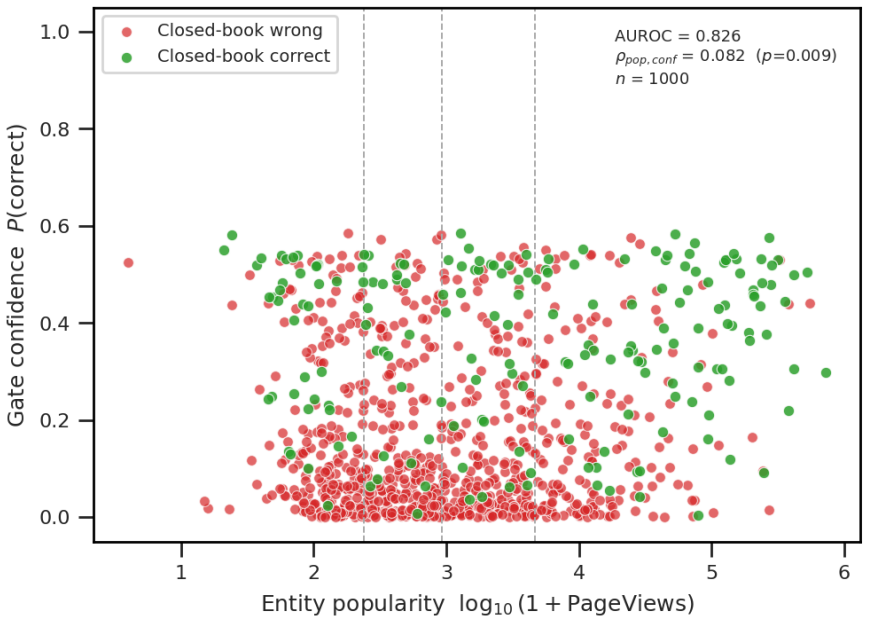
Retrieval-augmented generation (RAG) typically retrieves a fixed number of passages for every query. This is wasteful when the reader already knows the answer, and it can be harmful when irrelevant or partially relevant passages distract the reader. We formulate adaptive RAG as calibrated retrieval-budget allocation: given a query, decide whether to answer closed-book, retrieve a compact context (k=1), retrieve a full context (k=5), or abstain. The contribution is a probability interface rather than a new raw uncertainty signal. We calibrate sequence log-probability and prefix-logit uncertainty signals into probabilities of correctness, then use these probabilities for graded context selection, selective abstention, and explicit latency/token trade-offs. Across core QA experiments on TriviaQA, Natural Questions, and MS MARCO, with auxiliary PopQA motivation and Qwen/Llama family checks, diagnostic out-of-fold calibration improves probability quality dramatically: for sequence log-probability, ECE drops from 0.275 to 0.062 on TriviaQA, 0.643 to 0.009 on NQ, and 0.711 to 0.031 on MS MARCO. Graded retrieval improves full-context and passage-budget frontiers for both our signal and TARG-style prefix entropy/margin, while retrieval-call AUC remains essentially tied with binary gating because k=1 is still a retrieval call. Held-out train/validation/test threshold experiments report deployable operating points. At matched-accuracy frontier operating points, a measured cost model reveals that gating is not universally faster: it increases latency by about 27% on Qwen3-8B but saves about 8% on Qwen3-32B. These results support a nuanced view of adaptive RAG: calibrated confidence is best understood as a reusable interface for allocating retrieval budget under task and system constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates adaptive RAG as calibrated retrieval-budget allocation, using out-of-fold calibration of sequence log-probability and prefix-logit signals to produce probabilities of correctness. These probabilities drive graded decisions (closed-book, k=1, k=5, or abstain) and are evaluated on TriviaQA, Natural Questions, and MS MARCO with Qwen/Llama models, reporting large ECE reductions and improved full-context and passage-budget frontiers while providing deployable operating points and a cost model for latency/token trade-offs.
Significance. If the calibration mapping generalizes, the work supplies a reusable probability interface for RAG budget allocation under accuracy, latency, and cost constraints. The explicit finding that gating is not universally faster (27% latency increase on Qwen3-8B vs. 8% savings on Qwen3-32B at matched accuracy) and the use of held-out threshold experiments are practical strengths.
major comments (3)
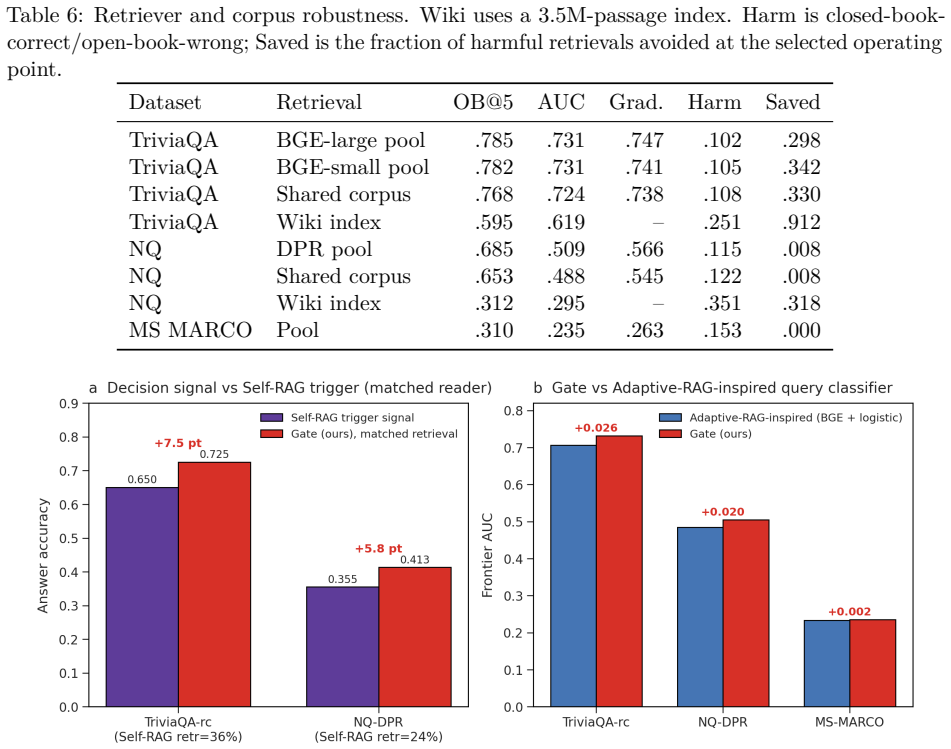
- [Experiments] Experiments section: ECE reductions (0.275→0.062 on TriviaQA, 0.643→0.009 on NQ, 0.711→0.031 on MS MARCO) and graded-retrieval frontier gains rest on calibration performed on in-distribution train/val splits of the same three datasets; no cross-dataset transfer results are reported to test whether the learned mapping from log-probability to P(correct) holds on new query distributions.
- [Abstract] Abstract and threshold experiments: decision thresholds for the four-way allocation (k=0/1/5/abstain) are selected on held-out data from the evaluation benchmarks, creating moderate dependence between the fitting procedure and the reported gains that is load-bearing for the claim of deployable operating points.
- [Results] Cost-model results: the reported latency changes (+27% on Qwen3-8B, -8% on Qwen3-32B) at matched-accuracy frontiers are presented without error bars, multiple random seeds, or details on how the underlying cost model was constructed, undermining the nuanced conclusion about when gating helps or hurts.
minor comments (2)
- [Abstract] The abstract states that retrieval-call AUC remains tied with binary gating because k=1 still counts as a retrieval call; this point could be expanded with a short table comparing binary vs. graded call rates.
- Notation for prefix-logit uncertainty signals is introduced without an explicit equation; adding a short definition would improve clarity for readers unfamiliar with TARG-style baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting both the practical contributions and areas needing clarification. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: ECE reductions (0.275→0.062 on TriviaQA, 0.643→0.009 on NQ, 0.711→0.031 on MS MARCO) and graded-retrieval frontier gains rest on calibration performed on in-distribution train/val splits of the same three datasets; no cross-dataset transfer results are reported to test whether the learned mapping from log-probability to P(correct) holds on new query distributions.
Authors: We agree that the absence of cross-dataset transfer experiments is a limitation. Our design isolates the calibration procedure within each benchmark using out-of-fold splits to demonstrate ECE reduction and frontier improvement; we did not claim universal generalization of the mapping. In revision we will add a limitations paragraph and, space permitting, a small cross-dataset probe (e.g., TriviaQA calibration evaluated on NQ). revision: partial
-
Referee: [Abstract] Abstract and threshold experiments: decision thresholds for the four-way allocation (k=0/1/5/abstain) are selected on held-out data from the evaluation benchmarks, creating moderate dependence between the fitting procedure and the reported gains that is load-bearing for the claim of deployable operating points.
Authors: Threshold selection on a held-out portion of each benchmark follows standard practice in selective-prediction and calibration papers (e.g., for reporting operating points after calibration). Calibration itself uses only the train/val out-of-fold procedure; the test split remains untouched. The dependence is therefore limited to post-hoc threshold choice rather than the probability mapping. We view this as acceptable for demonstrating deployable points and do not plan to alter the experimental design. revision: no
-
Referee: [Results] Cost-model results: the reported latency changes (+27% on Qwen3-8B, -8% on Qwen3-32B) at matched-accuracy frontiers are presented without error bars, multiple random seeds, or details on how the underlying cost model was constructed, undermining the nuanced conclusion about when gating helps or hurts.
Authors: We accept this criticism. The current manuscript reports point estimates from a single measured cost model without variance quantification. In the revision we will (i) describe the cost-model construction (token counts, measured per-token latency, and retrieval overhead) in an appendix, (ii) add error bars derived from multiple random seeds on the frontier points, and (iii) clarify the conditions under which the latency trade-off holds. revision: yes
Circularity Check
No significant circularity; empirical calibration is independent of reported outcomes
full rationale
The paper applies standard out-of-fold calibration to sequence log-probability and prefix-logit signals on train/val splits of TriviaQA, NQ, and MS MARCO, then evaluates ECE and RAG frontiers on held-out test portions. This follows conventional calibration protocols without reducing any claimed result to its inputs by construction. No self-citations, uniqueness theorems, ansatzes, or renamings appear as load-bearing steps. The graded retrieval improvements are demonstrated empirically against baselines rather than forced by the fitting procedure itself. The method remains self-contained against the external benchmarks used.
Axiom & Free-Parameter Ledger
free parameters (1)
- decision thresholds for k=0/1/5/abstain
axioms (1)
- domain assumption Sequence log-probability and prefix-logit signals remain informative after calibration across the tested model families and QA domains.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages=
2020
-
[3]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , pages=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , pages=
-
[4]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: A Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=
-
[5]
Nguyen, Tri and Rosenberg, Mir and Song, Xia and Gao, Jianfeng and Tiwary, Saurabh and Majumder, Rangan and Deng, Li , booktitle=
-
[6]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=
-
[7]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages=
-
[8]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle=
-
[9]
, booktitle=
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong C. , booktitle=
-
[10]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
Active Retrieval Augmented Generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[11]
Retrieval as a Decision: Training-Free Adaptive Gating for Efficient
Wang, Yufeng and Wei, Lu and Ling, Haibin , journal=. Retrieval as a Decision: Training-Free Adaptive Gating for Efficient
-
[12]
Proceedings of the 34th International Conference on Machine Learning , pages=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning , pages=
-
[13]
Advances in Neural Information Processing Systems , year=
Selective Classification for Deep Neural Networks , author=. Advances in Neural Information Processing Systems , year=
-
[14]
Geifman, Yonatan and El-Yaniv, Ran , booktitle=
-
[15]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
The. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas and Lian, Defu and Nie, Jian-Yun , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.