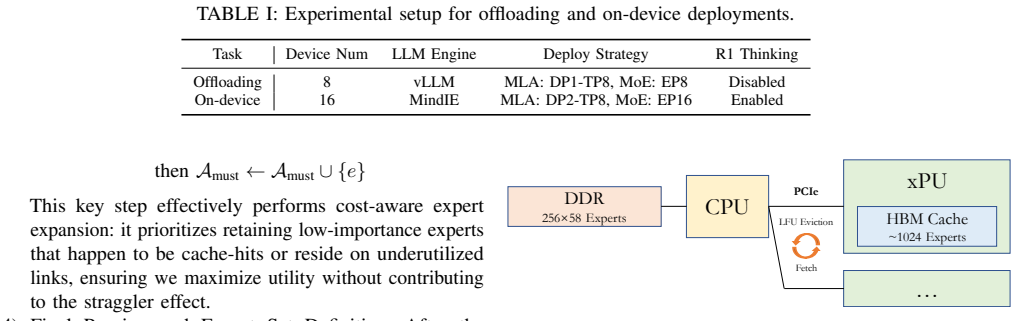
Beyond Uniform Experts: Cost-Aware Expert Execution for Efficient Multi-Device MoE Inference
Pith reviewed 2026-06-30 04:24 UTC · model grok-4.3
The pith
Cost-Aware Expert Execution reduces MoE inference latency 8-18% by pruning low-value high-cost experts and redistributing their work.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAEE jointly optimizes per-token expert importance against measured system-level execution cost by using calibrated cost models to selectively prune low-importance high-cost experts and applying a low-overhead compensation mechanism that redistributes their contributions without extra data movement.
What carries the argument
CAEE, a hardware-guided runtime framework that combines token-level importance scoring with per-expert cost estimation to decide which experts to execute and how to compensate for skipped ones.
Load-bearing premise
The lightweight cost models give accurate enough predictions of each expert's hardware cost at runtime, and the compensation step keeps output quality intact without creating new system bottlenecks.
What would settle it
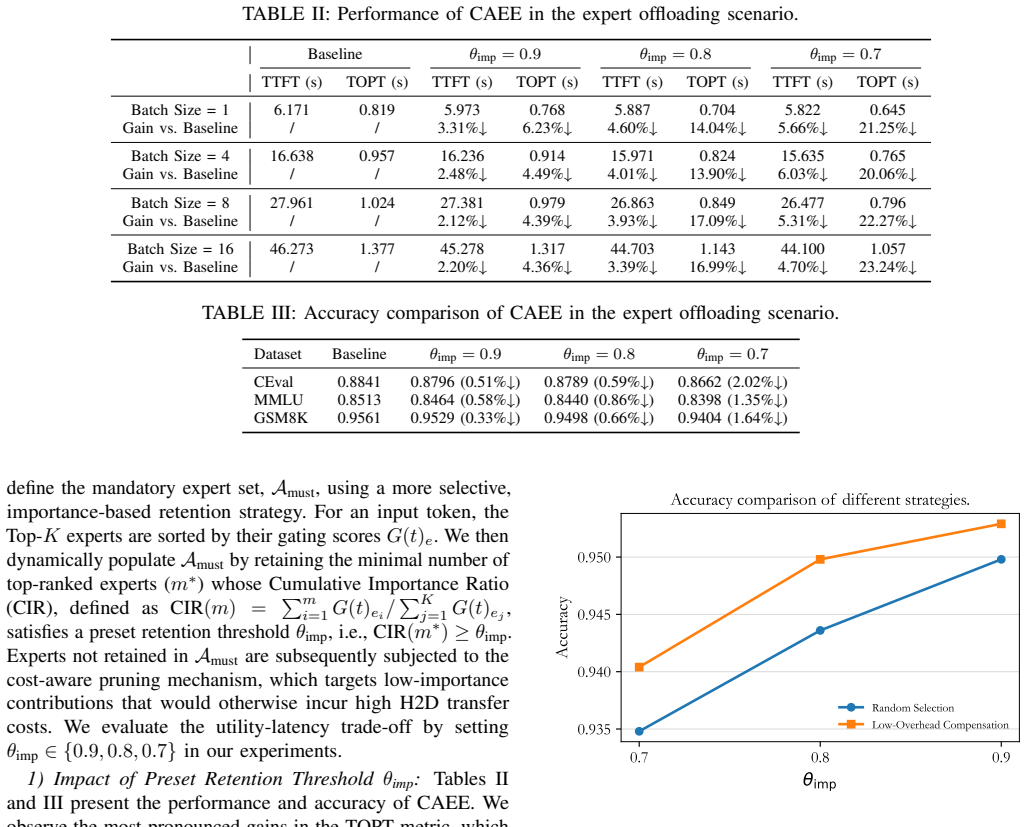
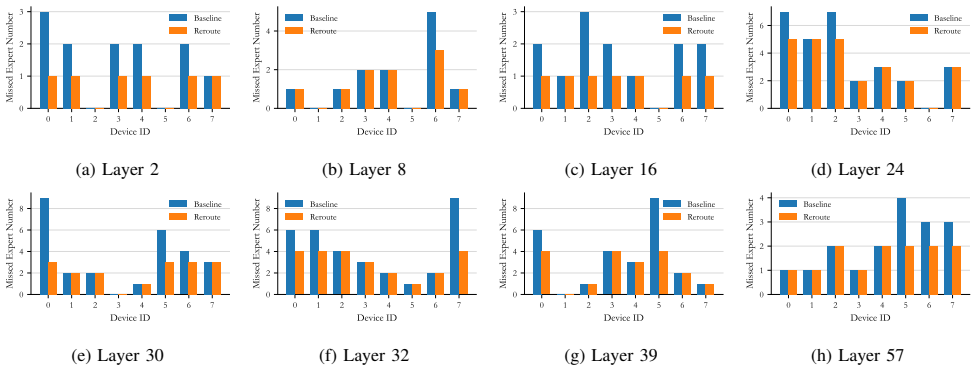
Measure end-to-end latency and accuracy on the same 671B model and deployment settings both with and without CAEE; if latency does not drop by at least 8% or accuracy falls more than 1%, the central claim does not hold.
Figures
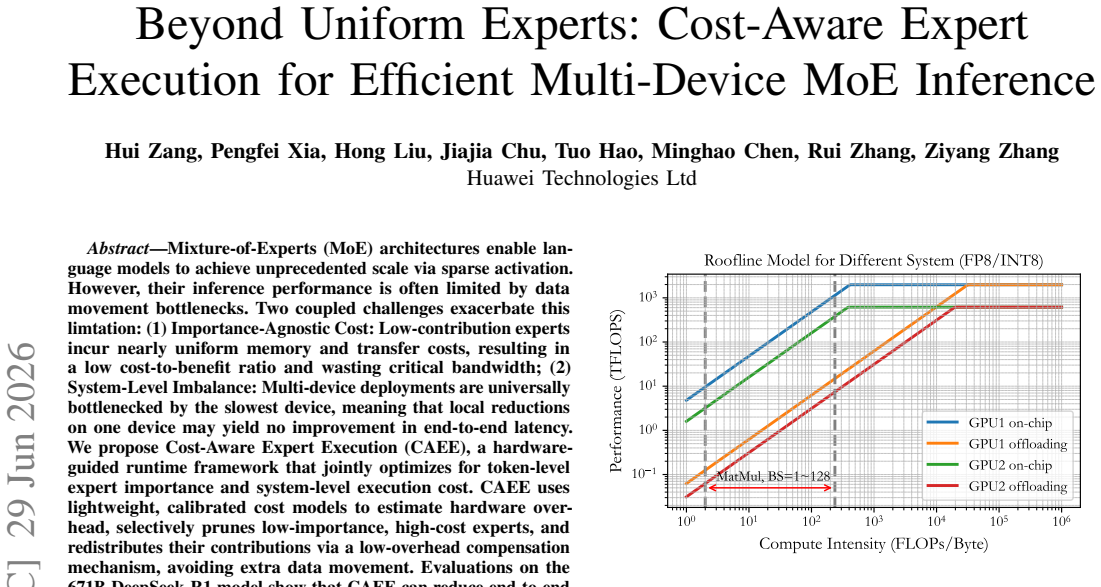

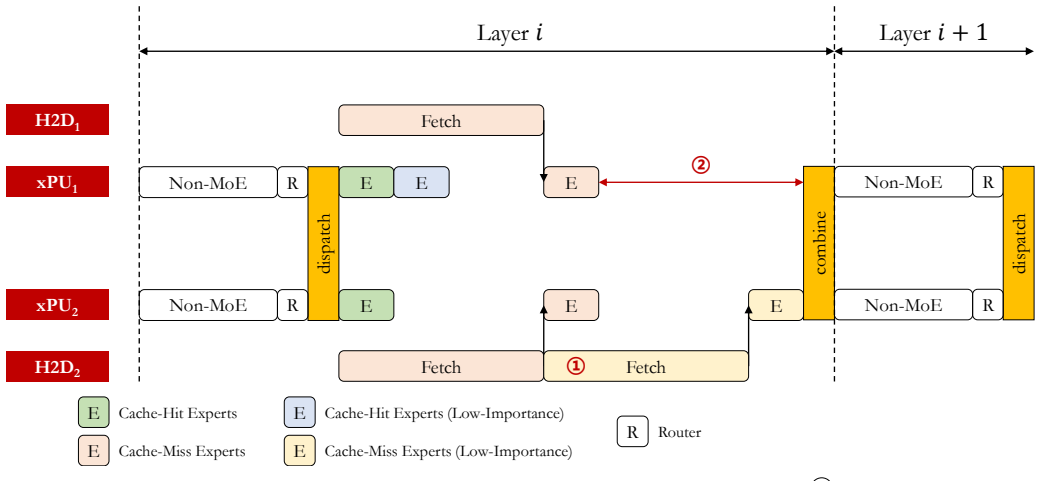
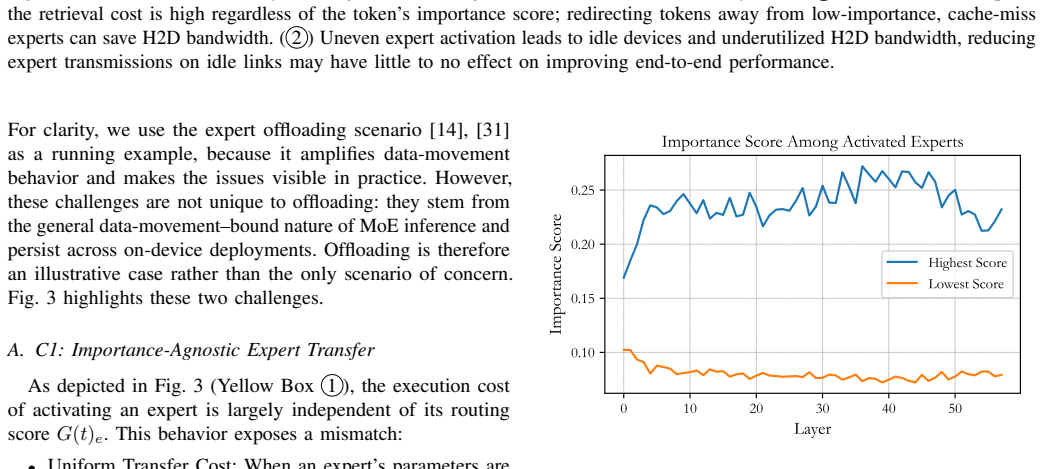


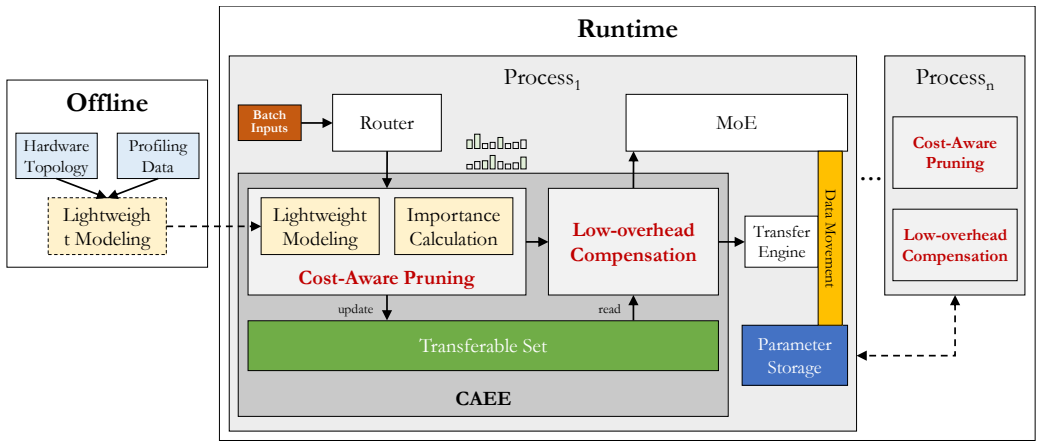
read the original abstract
Mixture-of-Experts (MoE) architectures enable language models to achieve unprecedented scale via sparse activation. However, their inference performance is often limited by data movement bottlenecks. Two coupled challenges exacerbate this limtation: (1) Importance-Agnostic Cost: Low-contribution experts incur nearly uniform memory and transfer costs, resulting in a low cost-to-benefit ratio and wasting critical bandwidth; (2) System-Level Imbalance: Multi-device deployments are universally bottlenecked by the slowest device, meaning that local reductions on one device may yield no improvement in end-to-end latency. We propose Cost-Aware Expert Execution (CAEE), a hardware-guided runtime framework that jointly optimizes for token-level expert importance and system-level execution cost. CAEE uses lightweight, calibrated cost models to estimate hardware overhead, selectively prunes low-importance, high-cost experts, and redistributes their contributions via a low-overhead compensation mechanism, avoiding extra data movement. Evaluations on the 671B DeepSeek-R1 model show that CAEE can reduce end-to-end inference latency by 8\%-18\% across diverse deployment settings, including expert offloading and on-device execution on multi-device systems, while maintaining a model accuracy drop of less than 1\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cost-Aware Expert Execution (CAEE), a hardware-guided runtime framework for Mixture-of-Experts (MoE) inference. It jointly optimizes token-level expert importance and system-level execution costs using lightweight calibrated cost models to selectively prune low-importance, high-cost experts and redistribute their contributions via a low-overhead compensation mechanism that avoids extra data movement. On the 671B DeepSeek-R1 model, CAEE is reported to reduce end-to-end inference latency by 8%-18% across multi-device settings (expert offloading and on-device execution) while keeping accuracy drop below 1%.
Significance. If the empirical results hold under the stated conditions, the work addresses practical bottlenecks in large-scale MoE deployment on heterogeneous hardware by moving beyond uniform expert treatment. The combination of per-expert cost modeling with a compensation step that preserves output quality offers a concrete, deployable technique for reducing data-movement overhead in distributed inference.
minor comments (1)
- [Abstract] Abstract: 'limtation' is a typo and should read 'limitation'.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on Cost-Aware Expert Execution (CAEE) and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central claims rest on empirical evaluations of end-to-end latency reductions (8%-18%) and accuracy preservation (<1% drop) on the 671B DeepSeek-R1 model across deployment settings. These are supported by described calibration procedures for cost models and measurements, with no equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes that reduce the reported gains to inputs by construction. The argument structure is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Online]
Compute Express Link. [Online]. Available: https://en.wikipedia.org/ wiki/Compute Express Link
-
[2]
[Online]
PCI Express. [Online]. Available: https://en.wikipedia.org/wiki/PCI Express
-
[3]
Da-MoE: Towards Dynamic Expert Allocation for Mixture-of-Experts Models,
M. A. Aghdam, H. Jin, and Y . Wu, “Da-MoE: Towards Dynamic Expert Allocation for Mixture-of-Experts Models,”arXiv preprint arXiv:2409.06669, 2024. 9
-
[4]
Language Models are Few-Shot Learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
-
[5]
Language Models are Few-Shot Learners
[Online]. Available: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[6]
MoE-Lightning: High-Throughput MoE Inference on Memory-Constrained Gpus,
S. Cao, S. Liu, T. Griggs, P. Schafhalter, X. Liu, Y . Sheng, J. E. Gonzalez, M. Zaharia, and I. Stoica, “MoE-Lightning: High-Throughput MoE Inference on Memory-Constrained Gpus,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2025, pp. 715–730
2025
-
[7]
Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering,
I.-C. Chen, H.-S. Liu, W.-F. Sun, C.-H. Chao, Y .-C. Hsu, and C.-Y . Lee, “Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering,” 2024
2024
-
[8]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Task-Specific Expert Pruning for Sparse Mixture-of-Experts,
T. Chen, S. Huang, Y . Xie, B. Jiao, D. Jiang, H. Zhou, J. Li, and F. Wei, “Task-Specific Expert Pruning for Sparse Mixture-of-Experts,”arXiv preprint arXiv:2206.00277, 2022
-
[10]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training Verifiers to Solve Math Word Problems,” 2021. [Online]. Available: https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Efficient LLM Inference: Bandwidth, Compute, Synchronization, and Capacity are all You Need,
M. Davies, N. Crago, K. Sankaralingam, and C. Kozyrakis, “Efficient LLM Inference: Bandwidth, Compute, Synchronization, and Capacity are all You Need,”arXiv preprint arXiv:2507.14397, 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model,
DeepSeek-AI, A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Yang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Chen, J. Yuan, J. Qiu, J. Song, K. Dong, K. Gao, K. Guan, L. Wan...
-
[14]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
[Online]. Available: https://arxiv.org/abs/2405.04434
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Fast Inference of Mixture-of-Experts Language Models with Offloading,
A. Eliseev and D. Mazur, “Fast Inference of Mixture-of-Experts Language Models with Offloading,”arXiv preprint arXiv:2312.17238, 2023
-
[17]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Mar...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Y . Guo, Z. Cheng, X. Tang, Z. Tu, and T. Lin, “Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models,” arXiv preprint arXiv:2405.14297, 2024
-
[19]
Demystifying the Compression of Mixture-of-Experts through a Unified Framework,
S. He, D. Dong, L. Ding, and A. Li, “Demystifying the Compression of Mixture-of-Experts through a Unified Framework,”arXiv e-prints, pp. arXiv–2406, 2024
2024
-
[20]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring Massive Multitask Language Understanding,” arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[21]
H. Huang, N. Ardalani, A. Sun, L. Ke, H.-H. S. Lee, A. Sridhar, S. Bhosale, C.-J. Wu, and B. Lee, “Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference,”arXiv preprint arXiv:2303.06182, 2023
-
[22]
C-Eval: A Multi-Level Multi- Discipline Chinese Evaluation Suite for Foundation Models,
Y . Huang, Y . Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y . Zhang, j. lei, Y . Fu, M. Sun, and J. He, “C-Eval: A Multi-Level Multi- Discipline Chinese Evaluation Suite for Foundation Models,”Advances in Neural Information Processing Systems, vol. 36, pp. 62 991–63 010, 2023
2023
-
[23]
Pre-Gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert inference,
R. Hwang, J. Wei, S. Cao, C. Hwang, X. Tang, T. Cao, and M. Yang, “Pre-Gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert inference,” in2024 ACM/IEEE 51st Annual Interna- tional Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 1018–1031
2024
-
[24]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of Experts,” 2024. [Onl...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Fiddler: Cpu-gpu Orchestration for Fast Inference of Mixture-of-Experts Models,
K. Kamahori, T. Tang, Y . Gu, K. Zhu, and B. Kasikci, “Fiddler: Cpu-gpu Orchestration for Fast Inference of Mixture-of-Experts Models,”arXiv preprint arXiv:2402.07033, 2024
-
[26]
Stun: Structured-then-Unstructured Pruning for Scalable MoE Pruning,
J. Lee, S.-w. Hwang, A. Qiao, D. F. Campos, Z. Yao, and Y . He, “Stun: Structured-then-Unstructured Pruning for Scalable MoE Pruning,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 13 660– 13 676
2025
-
[27]
Adaptive Gating in Mixture-of-Experts based Language Models,
J. Li, Q. Su, Y . Yang, Y . Jiang, C. Wang, and H. Xu, “Adaptive Gating in Mixture-of-Experts based Language Models,”arXiv preprint arXiv:2310.07188, 2023
-
[28]
A Survey on Inference Optimization Techniques for Mixture of Experts Models,
J. Liu, P. Tang, W. Wang, Y . Ren, X. Hou, P.-A. Heng, M. Guo, and C. Li, “A Survey on Inference Optimization Techniques for Mixture of Experts Models,”arXiv preprint arXiv:2412.14219, 2024
-
[29]
X. Lu, Q. Liu, Y . Xu, A. Zhou, S. Huang, B. Zhang, J. Yan, and H. Li, “Not All Experts Are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models,”arXiv preprint arXiv:2402.14800, 2024
-
[30]
OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V . Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brunda...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Deepspeed-MoE: Advancing Mixture-of- Experts Inference and Training to Power Next-Generation AI Scale,
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Aminabadi, A. A. Awan, J. Rasley, and Y . He, “Deepspeed-MoE: Advancing Mixture-of- Experts Inference and Training to Power Next-Generation AI Scale,” inInternational conference on machine learning. PMLR, 2022, pp. 18 332–18 346
2022
-
[32]
ProMoE: Fast MoE- Based LLM Serving Using Proactive Caching,
X. Song, Z. Zhong, R. Chen, and H. Chen, “ProMoE: Fast MoE- Based LLM Serving Using Proactive Caching,”arXiv preprint arXiv:2410.22134, 2024
-
[33]
Hobbit: A Mixed Precision Expert Offloading System for Fast MoE Inference,
P. Tang, J. Liu, X. Hou, Y . Pu, J. Wang, P.-A. Heng, C. Li, and M. Guo, “Hobbit: A Mixed Precision Expert Offloading System for Fast MoE Inference,”arXiv preprint arXiv:2411.01433, 2024
-
[34]
MoE-Pruner: Pruning Mixture-of-Experts Large Language Model Using the Hints from its Router,
Y . Xie, Z. Zhang, D. Zhou, C. Xie, Z. Song, X. Liu, Y . Wang, X. Lin, and A. Xu, “MoE-Pruner: Pruning Mixture-of-Experts Large Language Model Using the Hints from its Router,”arXiv preprint arXiv:2410.12013, 2024
-
[35]
Qwen3 Technical Report,
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
-
[36]
[Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
C. Yang, Y . Sui, J. Xiao, L. Huang, Y . Gong, Y . Duan, W. Jia, M. Yin, Y . Cheng, and B. Yuan, “MoE- I2: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition,”arXiv preprint arXiv:2411.01016, 2024
-
[38]
XMoE: Sparse Models with Fine-Grained and Adaptive Expert Selection,
Y . Yang, S. Qi, W. Gu, C. Wang, C. Gao, and Z. Xu, “XMoE: Sparse Models with Fine-Grained and Adaptive Expert Selection,”arXiv preprint arXiv:2403.18926, 2024
-
[39]
Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts,
Z. Zhang, X. Liu, H. Cheng, C. Xu, and J. Gao, “Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts,” in Findings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 86–102
2025
-
[40]
AdapMoE: Adaptive Sensitivity-Based Expert Gating and Management for Efficient MoE Inference,
S. Zhong, L. Liang, Y . Wang, R. Wang, R. Huang, and M. Li, “AdapMoE: Adaptive Sensitivity-Based Expert Gating and Management for Efficient MoE Inference,” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024, pp. 1–9
2024
-
[41]
LiteMoE: Customizing On-Device LLM Serving via Proxy Submodel Tuning,
Y . Zhuang, Z. Zheng, F. Wu, and G. Chen, “LiteMoE: Customizing On-Device LLM Serving via Proxy Submodel Tuning,” inProceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems, 2024, pp. 521–534. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.