Be Faithful When Response: Returning Fluent and Grounded Answers for Vision-Language Models Reinforcement Learning
Pith reviewed 2026-06-30 06:10 UTC · model grok-4.3
The pith
A warm-start phase on curated visually faithful samples before RL makes VLM answers more accurate and grounded.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
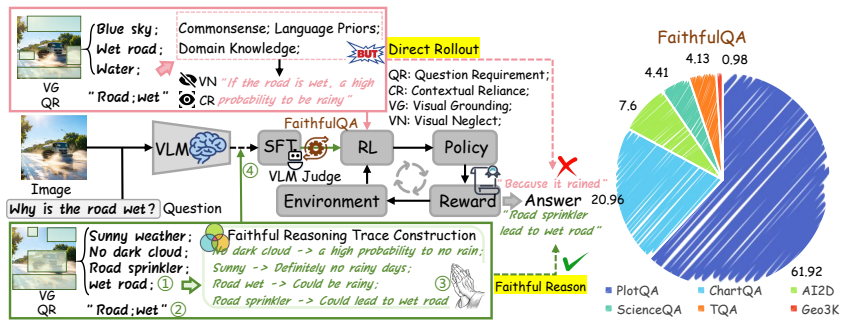
The central claim is that equipping a VLM with the capability to understand causally grounded vision-language patterns through a Faithful Warm-Start (FWS) stage—constructed by curating samples from general VQA benchmarks into FaithfulQA and purifying them via a VLM-based judge—improves answer accuracy, stabilizes subsequent RL training under sparse rewards, and reduces generation of visually unsupported reasoning traces.
What carries the argument
The Faithful Warm-Start (FWS) strategy, which first assembles and purifies a dataset of image-question pairs exhibiting explicit vision-language causal relationships before any RL optimization begins.
If this is right
- Faithful supervision raises final answer accuracy on the target tasks.
- The warm-start phase reduces variance and instability during the RL optimization loop.
- Models produce fewer reasoning traces that lack support from the input image.
Where Pith is reading between the lines
- The same curation step could be inserted before RL fine-tuning of text-only models to enforce grounding in external knowledge sources.
- A tighter coupling between the VLM judge and the reward model might further reduce the need for a separate warm-start phase.
- The approach suggests testing whether similar pre-filtering helps when RL is applied to other multimodal tasks such as visual navigation or captioning.
Load-bearing premise
Samples taken from ordinary VQA benchmarks and filtered by a VLM judge will supply causal consistency and visual faithfulness that carry over to the policy once RL begins with only answer-level rewards.
What would settle it
Running the identical RL procedure on the same VLM both with and without the FWS stage on a held-out VQA benchmark and finding no measurable difference in accuracy, training stability, or rate of visually unsupported reasoning steps.
Figures

read the original abstract
Reinforcement Learning (RL) is an important paradigm for improving the reasoning capabilities of Vision-Language Models (VLMs). However, directly applying RL to rollout multimodal reasoning can lead to instability, due to the exploitation of language priors, the neglect of visual evidence, and the generation of reasoning traces that are fluent yet not visually grounded. The question arises: Can initially steer the policy toward visually faithful reasoning regime before applying reinforcement learning? To this end, we propose a Faithful Warm-Start (FWS) strategy that first curates samples with explicit vision-language causal relationships from six general VQA benchmarks to construct the FaithfulQA dataset, where each of the image-question pairs gains a certain degree of visual observations, question requirements, commonsense knowledge, domain knowledge, and the final answer. Subsequently, a VLM-based judge is employed to further purify the dataset, ensuring strong causal consistency and visual faithfulness. This warm-start stage equips the model with the capability to understand causally grounded vision-language patterns before subsequent RL optimization under sparse answer-level rewards. Experimental results show that such faithful supervision improves answer accuracy, stabilizes RL training, and reduces visually unsupported reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Faithful Warm-Start (FWS) strategy for RL on VLMs: curate FaithfulQA from six general VQA benchmarks by annotating image-question pairs with visual observations, question requirements, commonsense/domain knowledge and answers; apply a VLM-based judge to purify for causal consistency and visual faithfulness; then warm-start the policy before sparse-reward RL. The central claim is that this faithful supervision improves answer accuracy, stabilizes training, and reduces visually unsupported reasoning.
Significance. If the empirical results hold and the judge step demonstrably removes language-prior shortcuts, the method would offer a practical way to mitigate a known failure mode in multimodal RL. The approach is empirical rather than axiomatic and supplies no machine-checked proofs or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: the claim that the VLM-based judge 'ensures strong causal consistency and visual faithfulness' is load-bearing for the entire pipeline, yet the description supplies no prompt template, decision threshold, or independent verification (human annotation, image-ablation test, or inter-annotator agreement) that the judge actually rejects fluent but visually unsupported answers rather than accepting them.
- [Abstract] Abstract / Method description: curation begins with general VQA benchmarks that are known to contain language-prior shortcuts; without a quantitative comparison (e.g., fraction of samples rejected by the judge, or accuracy on an image-ablated subset) it is unclear whether the resulting FaithfulQA set actually exhibits the claimed causal consistency that is supposed to transfer to subsequent RL.
minor comments (1)
- [Abstract] Abstract: experimental claims are stated without any metrics, baselines, dataset sizes, training details, or statistical significance tests, making it impossible to assess the magnitude or reliability of the reported improvements.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful review and valuable suggestions. Below we respond to each major comment. We plan to incorporate clarifications and additional quantitative details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the VLM-based judge 'ensures strong causal consistency and visual faithfulness' is load-bearing for the entire pipeline, yet the description supplies no prompt template, decision threshold, or independent verification (human annotation, image-ablation test, or inter-annotator agreement) that the judge actually rejects fluent but visually unsupported answers rather than accepting them.
Authors: We agree that the abstract claim requires more supporting documentation. In the revision we will add the exact prompt template for the VLM-based judge and the numerical decision threshold to the appendix. The original work did not include separate human annotation or inter-annotator agreement for the judge itself; the validation rests on downstream accuracy gains and reduced unsupported reasoning. We will explicitly note this scope in the revised text. revision: yes
-
Referee: [Abstract] Abstract / Method description: curation begins with general VQA benchmarks that are known to contain language-prior shortcuts; without a quantitative comparison (e.g., fraction of samples rejected by the judge, or accuracy on an image-ablated subset) it is unclear whether the resulting FaithfulQA set actually exhibits the claimed causal consistency that is supposed to transfer to subsequent RL.
Authors: We accept that a quantitative measure of the judge's filtering effect is needed. We will report the fraction of samples rejected during purification in the revised manuscript. An image-ablated accuracy evaluation was not performed; the paper instead relies on the explicit visual-observation annotations and the observed empirical improvements in grounding. We will add the rejection-rate statistic and clarify the evidential basis. revision: partial
Circularity Check
No significant circularity; empirical curation + RL pipeline
full rationale
The paper describes an empirical pipeline: curating FaithfulQA from six VQA benchmarks, purifying via VLM-based judge for causal consistency, then applying standard RL under sparse rewards. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations/uniqueness theorems appear. The central claim rests on experimental results rather than any reduction of outputs to inputs by construction. This is the common honest case of a self-contained empirical method evaluated on external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A VLM-based judge can reliably detect and remove samples lacking causal consistency and visual faithfulness.
Reference graph
Works this paper leans on
-
[1]
2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=
Boosting Audio-Visual Segmentation via Triple-Modalities Alignment , author=. 2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=. 2025 , organization=
2025
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
How Do Optical Flow and Textual Prompts Collaborate to Assist in Audio-Visual Semantic Segmentation? , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[3]
IEEE transactions on pattern analysis and machine intelligence , volume=
Vision-language models for vision tasks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Visual-rft: Visual reinforcement fine-tuning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
arXiv preprint arXiv:2508.08189 , year=
Reinforcement Learning for Large Model: A Survey , author=. arXiv preprint arXiv:2508.08189 , year=
-
[6]
Reward Modeling for Reinforcement Learning-Based LLM Reasoning: Design, Challenges, and Evaluation
Reward modeling for reinforcement learning-based LLM reasoning: Design, challenges, and evaluation , author=. arXiv preprint arXiv:2602.09305 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2509.03871 , year=
A comprehensive survey on trustworthiness in reasoning with large language models , author=. arXiv preprint arXiv:2509.03871 , year=
-
[8]
arXiv preprint arXiv:2510.11196 , year=
Evaluating Reasoning Faithfulness in Medical Vision-Language Models using Multimodal Perturbations , author=. arXiv preprint arXiv:2510.11196 , year=
-
[9]
arXiv preprint arXiv:2511.16660 , year=
Cognitive foundations for reasoning and their manifestation in llms , author=. arXiv preprint arXiv:2511.16660 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
When thinking drifts: Evidential grounding for robust video reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
and Kumar, Pratyush , title =
Methani, Nitesh and Ganguly, Pritha and Khapra, Mitesh M. and Kumar, Pratyush , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
-
[14]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[15]
Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV , series =
Aniruddha Kembhavi and Mike Salvato and Eric Kolve and Min Joon Seo and Hannaneh Hajishirzi and Ali Farhadi , title =. Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV , series =. 2016 , doi =
2016
-
[16]
The 36th Conference on Neural Information Processing Systems (NeurIPS) , year =
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author =. The 36th Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[17]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Kembhavi, Aniruddha and Seo, Minjoon and Schwenk, Dustin and Choi, Jonghyun and Farhadi, Ali and Hajishirzi, Hannaneh , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[18]
I nter- GPS : Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
Lu, Pan and Gong, Ran and Jiang, Shibiao and Qiu, Liang and Huang, Siyuan and Liang, Xiaodan and Zhu, Song-Chun. I nter- GPS : Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Lan...
-
[19]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Faithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization , author=. arXiv preprint arXiv:2604.08476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2603.19532 , year=
EvidenceRL: Reinforcing Evidence Consistency for Trustworthy Language Models , author=. arXiv preprint arXiv:2603.19532 , year=
-
[22]
arXiv preprint arXiv:2602.01348 , year=
CRAFT: Calibrated Reasoning with Answer-Faithful Traces via Reinforcement Learning for Multi-Hop Question Answering , author=. arXiv preprint arXiv:2602.01348 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Seeing is Believing? Mitigating OCR Hallucinations in Multimodal Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
PaLMR: Towards Faithful Visual Reasoning via Multimodal Process Alignment
PaLMR: Towards Faithful Visual Reasoning via Multimodal Process Alignment , author=. arXiv preprint arXiv:2603.06652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
REVEAL: Reasoning-Enhanced Forensic Evidence Analysis for Explainable AI-Generated Image Detection
REVEAL: Reasoning-Enhanced Forensic Evidence Analysis for Explainable AI-Generated Image Detection , author=. arXiv preprint arXiv:2511.23158 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Warmup Generations: A Task-Agnostic Approach for Guiding Sequence-to-Sequence Learning with Unsupervised Initial State Generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
Proceedings of the 1st Workshop on NLP for Empowering Justice (JUST-NLP 2025) , pages=
Cold Starts and Hard Cases: A Two-Stage SFT-RLVR Approach for Legal Machine Translation (Just-NLP L-MT shared task) , author=. Proceedings of the 1st Workshop on NLP for Empowering Justice (JUST-NLP 2025) , pages=
2025
-
[29]
Advancing multimodal reasoning via reinforcement learning with cold start
Advancing multimodal reasoning via reinforcement learning with cold start , author=. arXiv preprint arXiv:2505.22334 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.