Uncertainty Estimation in Pathology Foundation Models via Deep Mutual Learning
Pith reviewed 2026-06-30 06:29 UTC · model grok-4.3
The pith
Ensembling frozen pathology foundation models and aligning them with deep mutual learning makes their disagreement a reliable proxy for uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
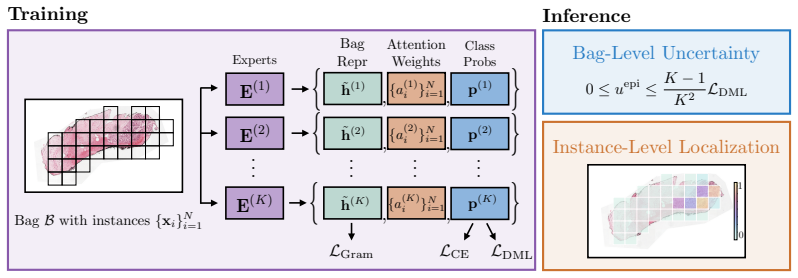
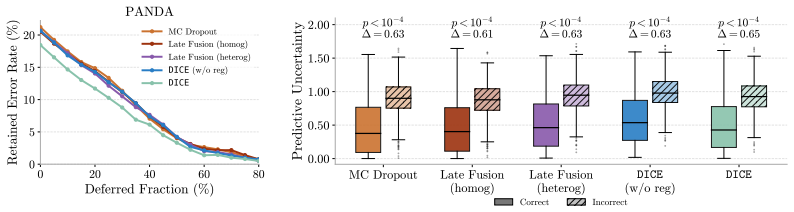
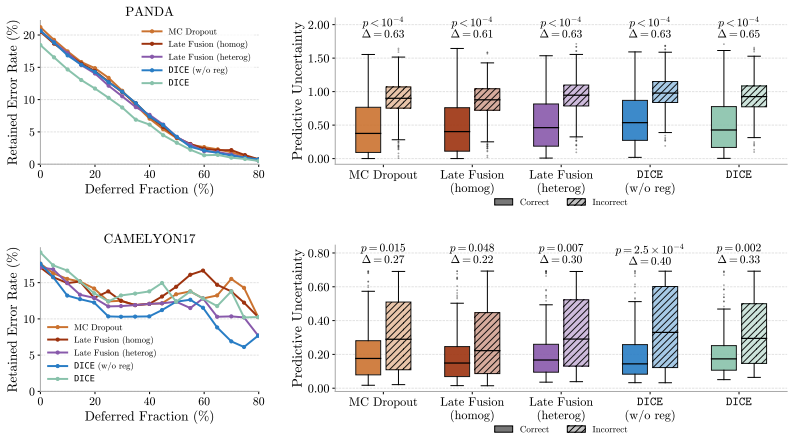
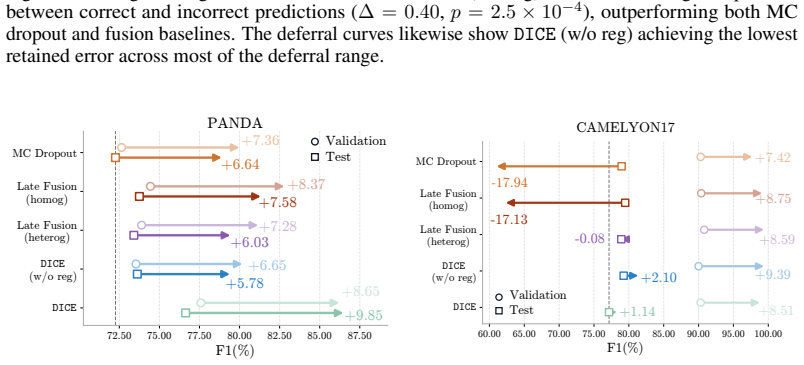
DICE ensembles K frozen PFMs, aligns the members via deep mutual learning so that disagreement serves as a proxy for uncertainty, and proves this objective upper-bounds model uncertainty. The ensemble consensus additionally localizes abnormalities at patch level without explicit supervision. On three WSI benchmarks the framework supplies reliable uncertainty estimates that flag failure-prone cases under in- and out-of-distribution conditions while matching or outperforming SOTA baselines in classification, calibration, and localization.
What carries the argument
The DICE framework, which ensembles frozen PFMs and aligns them via deep mutual learning to turn disagreement into an uncertainty proxy that upper-bounds model uncertainty.
If this is right
- Disagreement among the aligned models accurately flags predictions likely to fail under both in-distribution and out-of-distribution conditions.
- The framework matches or exceeds state-of-the-art performance on classification accuracy, calibration metrics, and patch-level localization.
- The ensemble consensus localizes abnormalities without requiring any explicit localization supervision.
- DICE can be added to existing frozen pathology foundation models without retraining them.
Where Pith is reading between the lines
- The same alignment technique could be tested on foundation models from other medical imaging modalities to check if disagreement remains a useful uncertainty signal.
- Further experiments could measure how the number of ensemble members affects the tightness of the theoretical upper bound on uncertainty.
- The localization property might be combined with existing weakly-supervised methods to improve abnormality detection without new labels.
Load-bearing premise
Aligning the ensemble members via deep mutual learning makes their disagreement upper-bound the model uncertainty.
What would settle it
A test set where high-disagreement cases after alignment show no higher error rates than low-disagreement cases would falsify the claim that the proxy yields reliable uncertainty estimates.
Figures



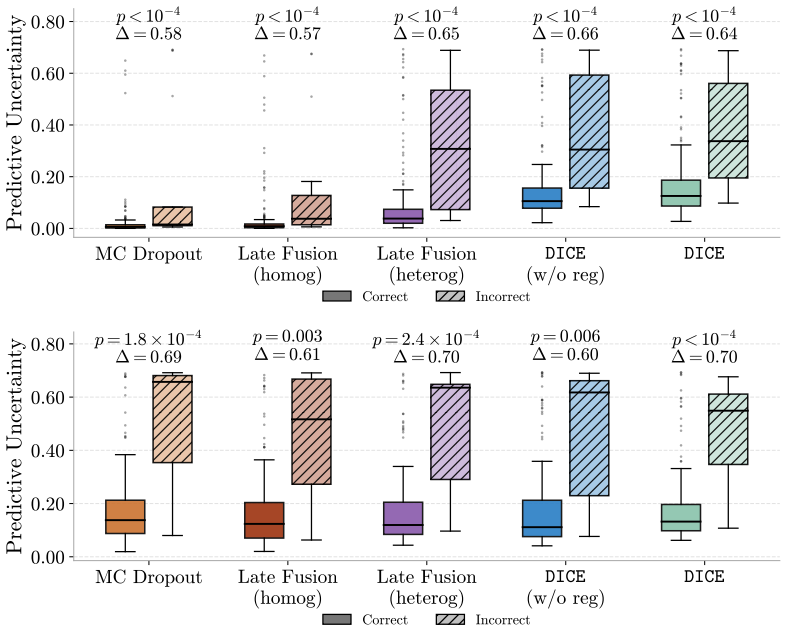
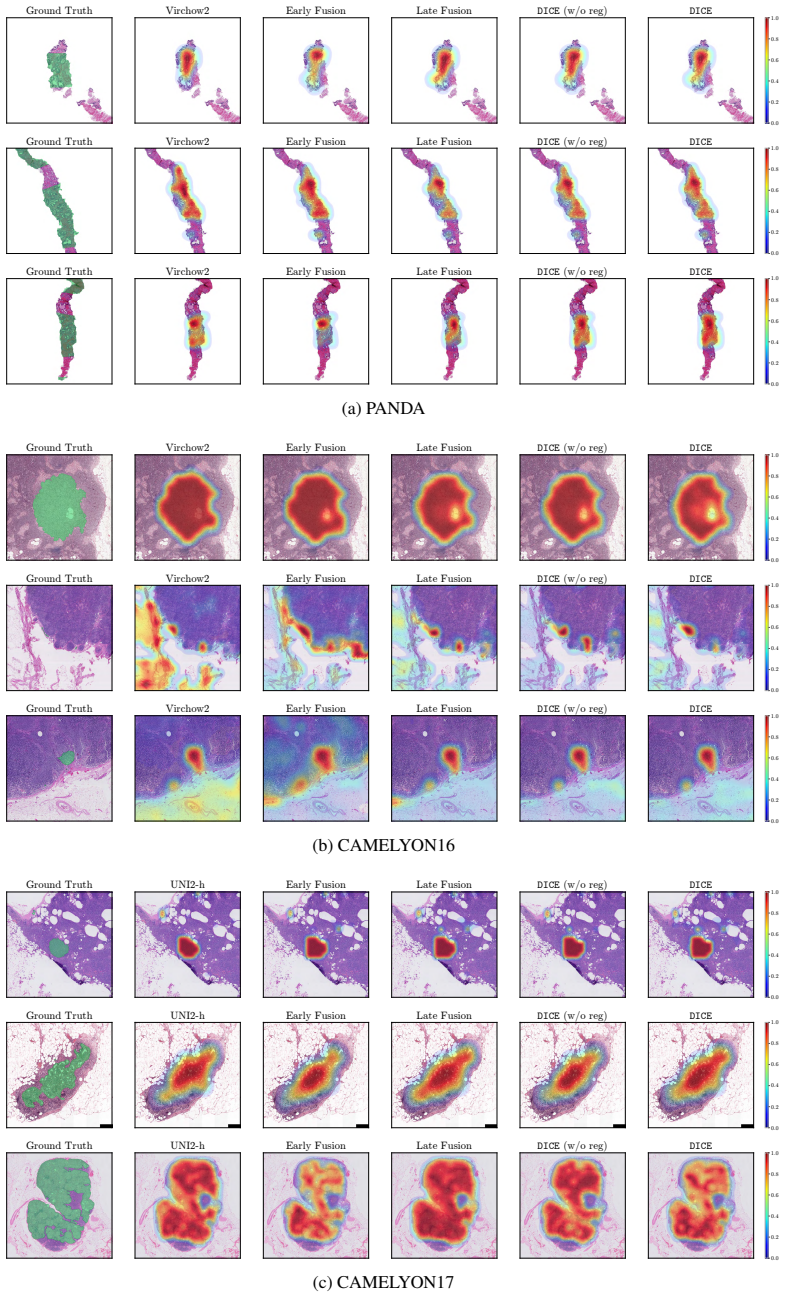
read the original abstract
Pathology foundation models (PFMs) offer generalizable representations for whole-slide image (WSI) analysis, yet their clinical adoption remains limited. Specifically, their predictions lack reliable confidence estimates, and no single PFM is universally best across tasks, which severely undermines trust in medical settings. To overcome this, we propose $\mathtt{DICE}$, a plug-and-play framework that ensembles $K$ frozen PFMs and models their disagreement as a proxy for uncertainty estimation. To ensure this proxy yields meaningful estimates, we align the ensemble members via deep mutual learning, and theoretically show that this objective upper-bounds the model uncertainty. Additionally, we demonstrate that the ensemble's consensus localizes abnormalities at the patch level without any explicit supervision. We evaluate $\mathtt{DICE}$ on three challenging WSI benchmarks. Notably, our framework provides reliable uncertainty estimates that accurately flag failure-prone cases under in- and out-of-distribution settings, while matching or outperforming SOTA baselines in classification, calibration, and localization. Overall, $\mathtt{DICE}$ takes a crucial step toward translating PFMs into uncertainty-aware decision-support systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DICE, a plug-and-play ensemble framework for uncertainty estimation in pathology foundation models (PFMs). It aligns K frozen PFMs via deep mutual learning (DML), claims a theoretical result that the DML objective upper-bounds model uncertainty, treats post-alignment disagreement as an uncertainty proxy, and reports that the ensemble consensus localizes abnormalities at patch level without explicit supervision. On three WSI benchmarks the method is stated to deliver reliable uncertainty estimates that flag failure cases under in- and out-of-distribution shifts while matching or exceeding SOTA baselines on classification, calibration, and localization tasks.
Significance. If the claimed theoretical upper bound can be established with explicit assumptions and a verifiable derivation, and if the empirical gains prove robust, the work would meaningfully advance trustworthy deployment of PFMs in clinical pathology by supplying a lightweight uncertainty signal without retraining the underlying models. The plug-and-play design and unsupervised localization aspect are attractive if substantiated.
major comments (3)
- [Abstract / theoretical development] Abstract and theoretical section: the central claim that 'deep mutual learning ... theoretically show[s] that this objective upper-bounds the model uncertainty' is load-bearing for the assertion that disagreement is a reliable proxy, yet no derivation, stated assumptions on the disagreement measure, properties of the frozen PFMs, or data-distribution conditions appear; without these the link between the training objective and the reported ability to flag failure-prone cases remains unsecured.
- [Uncertainty estimation / experimental validation] § on uncertainty estimation (presumably the methods section describing the proxy): the manuscript asserts that post-DML disagreement accurately flags in- and out-of-distribution failures, but provides no quantitative verification that the bound is tight enough for the observed AUROC or failure-detection rates; a concrete counter-example or tightness analysis would be required to support the claim.
- [Localization experiments] Localization results: the claim that 'the ensemble's consensus localizes abnormalities at the patch level without any explicit supervision' is presented as an additional contribution, but the evaluation lacks a controlled comparison against supervised localization baselines or an ablation removing the DML alignment step, making it impossible to isolate the contribution of the proposed alignment.
minor comments (2)
- [Methods] Notation for the disagreement measure and the precise form of the DML loss should be introduced with explicit equations rather than prose descriptions only.
- [Experiments] The three WSI benchmarks and the precise in-/out-of-distribution splits should be named and referenced with dataset DOIs or accession numbers for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the theoretical grounding, empirical validation, and experimental controls in the manuscript.
read point-by-point responses
-
Referee: [Abstract / theoretical development] Abstract and theoretical section: the central claim that 'deep mutual learning ... theoretically show[s] that this objective upper-bounds the model uncertainty' is load-bearing for the assertion that disagreement is a reliable proxy, yet no derivation, stated assumptions on the disagreement measure, properties of the frozen PFMs, or data-distribution conditions appear; without these the link between the training objective and the reported ability to flag failure-prone cases remains unsecured.
Authors: We agree that the current version states the upper-bound result without supplying the full derivation or explicit assumptions. In the revised manuscript we will insert a dedicated theoretical subsection that derives the bound step-by-step, states the required assumptions on the disagreement measure, the frozen PFMs, and the data distribution, and clarifies how the bound justifies using post-alignment disagreement as an uncertainty proxy. revision: yes
-
Referee: [Uncertainty estimation / experimental validation] § on uncertainty estimation (presumably the methods section describing the proxy): the manuscript asserts that post-DML disagreement accurately flags in- and out-of-distribution failures, but provides no quantitative verification that the bound is tight enough for the observed AUROC or failure-detection rates; a concrete counter-example or tightness analysis would be required to support the claim.
Authors: We acknowledge that a direct tightness analysis is missing. We will add quantitative experiments that measure the gap between the theoretical bound and the empirical disagreement, report how this gap correlates with the observed AUROC and failure-detection rates, and include a brief discussion of any counter-examples encountered. revision: yes
-
Referee: [Localization experiments] Localization results: the claim that 'the ensemble's consensus localizes abnormalities at the patch level without any explicit supervision' is presented as an additional contribution, but the evaluation lacks a controlled comparison against supervised localization baselines or an ablation removing the DML alignment step, making it impossible to isolate the contribution of the proposed alignment.
Authors: We agree that an ablation isolating the alignment step and a comparison against supervised localization baselines would improve interpretability. In the revision we will add (i) an ablation that removes the DML alignment while keeping the ensemble and (ii) a controlled comparison against available supervised patch-level localization baselines on the same WSI benchmarks. revision: yes
Circularity Check
No significant circularity; theoretical bound claim stands as independent derivation step
full rationale
The abstract and reader summary describe alignment via deep mutual learning followed by a claimed theoretical upper bound on uncertainty, with disagreement used as proxy. No equations, definitions, or self-citations are provided that reduce the bound or proxy to fitted parameters by construction, nor does any step rename a known result or import uniqueness via self-citation chain. The central claim retains independent content outside the inputs, consistent with the reader's assessment of score 2.0 but warranting 0 given absence of explicit reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence in digital pathology—time for a reality check.Nature Reviews Clinical Oncology, 22(4):283–291, 2025
Arpit Aggarwal, Satvika Bharadwaj, German Corredor, Tilak Pathak, Sunil Badve, and Anant Madabhushi. Artificial intelligence in digital pathology—time for a reality check.Nature Reviews Clinical Oncology, 22(4):283–291, 2025
2025
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InACM SIGKDD, 2019
2019
-
[3]
The need for uncertainty quantifi- cation in machine-assisted medical decision making.Nature Machine Intelligence, 1(1):20–23, 2019
Edmon Begoli, Tanmoy Bhattacharya, and Dimitri Kusnezov. The need for uncertainty quantifi- cation in machine-assisted medical decision making.Nature Machine Intelligence, 1(1):20–23, 2019
2019
-
[4]
H-optimus-1, 2025
Bioptimus. H-optimus-1, 2025. URL https://huggingface.co/bioptimus/ H-optimus-1
2025
-
[5]
Artificial intelligence for diagnosis and Gleason grading of prostate cancer: the PANDA challenge.Nature Medicine, 28(1):154–163, 2022
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Ström, Hans Pinckaers, Kunal Nagpal, Yuannan Cai, David F Steiner, Hester van Boven, Robert Vink, et al. Artificial intelligence for diagnosis and Gleason grading of prostate cancer: the PANDA challenge.Nature Medicine, 28(1):154–163, 2022
2022
-
[6]
A clinical benchmark of public self-supervised pathology foundation models.Nature Communications, 16(1):3640, 2025
Gabriele Campanella, Shengjia Chen, Manbir Singh, Ruchika Verma, Silke Muehlstedt, Jennifer Zeng, Aryeh Stock, Matt Croken, Brandon Veremis, Abdulkadir Elmas, et al. A clinical benchmark of public self-supervised pathology foundation models.Nature Communications, 16(1):3640, 2025. 10
2025
-
[7]
Real-world deployment of a fine-tuned pathology foundation model for lung cancer biomarker detection
Gabriele Campanella, Neeraj Kumar, Swaraj Nanda, Siddharth Singi, Eugene Fluder, Ricky Kwan, Silke Muehlstedt, Nicole Pfarr, Peter J Schüffler, Ida Häggström, et al. Real-world deployment of a fine-tuned pathology foundation model for lung cancer biomarker detection. Nature Medicine, 31(9):3002–3010, 2025
2025
-
[8]
Towards a general- purpose foundation model for computational pathology.Nature Medicine, 30(3):850–862, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general- purpose foundation model for computational pathology.Nature Medicine, 30(3):850–862, 2024
2024
-
[9]
Gramian multimodal representation learning and alignment
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello. Gramian multimodal representation learning and alignment. InICLR, 2025
2025
-
[10]
Yufei Cui, Ziquan Liu, Xiangyu Liu, Xue Liu, Cong Wang, Tei-Wei Kuo, Chun Jason Xue, and Antoni B. Chan. Bayes-MIL: A new probabilistic perspective on attention-based multiple instance learning for whole slide images. InICLR, 2023
2023
-
[11]
Decomposition of uncertainty in Bayesian deep learning for efficient and risk-sensitive learning
Stefan Depeweg, José Miguel Hernández-Lobato, Finale Doshi-Velez, and Steffen Udluft. Decomposition of uncertainty in Bayesian deep learning for efficient and risk-sensitive learning. InICML, 2018
2018
-
[12]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.JAMA, 318(22):2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul Johannes van Diest, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen AWM van der Laak, CAMELYON16 consortium, Meyke Hermsen, Quirine F Manson, et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.JAMA, 318(22):2199–2210, 2017
2017
-
[13]
Dropout as a Bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. InICML, 2016
2016
-
[14]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InICML, 2018
2018
-
[15]
Foundation models in pathology and the challenge of clinical time.Annals of Oncology, 2026
Guillaume Jaume. Foundation models in pathology and the challenge of clinical time.Annals of Oncology, 2026
2026
-
[16]
HEST-1k: A dataset for spatial transcriptomics and histology image analysis
Guillaume Jaume, Paul Doucet, Andrew H Song, Ming Y Lu, Cristina Almagro-Perez, Sophia J Wagner, Anurag J Vaidya, Richard J Chen, Drew FK Williamson, Ahrong Kim, and Faisal Mahmood. HEST-1k: A dataset for spatial transcriptomics and histology image analysis. In NeurIPS, 2024
2024
-
[17]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InNeurIPS, 2017
2017
-
[18]
Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning
Bin Li, Yin Li, and Kevin W Eliceiri. Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. InIEEE CVPR, 2021
2021
-
[19]
Divergence measures based on the Shannon entropy.IEEE Transactions on Information Theory, 37(1):145–151, 1991
Jianhua Lin. Divergence measures based on the Shannon entropy.IEEE Transactions on Information Theory, 37(1):145–151, 1991
1991
-
[20]
Comprehensive benchmark dataset for pathological lymph node metastasis in breast cancer sections.Scientific Data, 12(1):1381, 2025
Xitong Ling, Yuanyuan Lei, Jiawen Li, Junru Cheng, Wenting Huang, Tian Guan, Jian Guan, and Yonghong He. Comprehensive benchmark dataset for pathological lymph node metastasis in breast cancer sections.Scientific Data, 12(1):1381, 2025
2025
-
[21]
1399 H&E-stained sentinel lymph node sections of breast cancer patients: the CAMELYON dataset
Geert Litjens, Peter Bandi, Babak Ehteshami Bejnordi, Oscar Geessink, Maschenka Balkenhol, Peter Bult, Altuna Halilovic, Meyke Hermsen, Rob van de Loo, Rob V ogels, et al. 1399 H&E-stained sentinel lymph node sections of breast cancer patients: the CAMELYON dataset. GigaScience, 7(6):giy065, 2018
2018
-
[22]
SGPMIL: Sparse Gaussian process multiple instance learning
Andreas Lolos, Stergios Christodoulidis, Aris L Moustakas, Jose Dolz, and Maria Vakalopoulou. SGPMIL: Sparse Gaussian process multiple instance learning. InWACV, 2026
2026
-
[23]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 11
2019
-
[24]
Data-efficient and weakly supervised computational pathology on whole-slide images.Nature Biomedical Engineering, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature Biomedical Engineering, 5(6):555–570, 2021
2021
-
[25]
A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guil- laume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024
2024
-
[26]
Ensemble learning of foundation models for precision oncology.arXiv preprint arXiv:2508.16085, 2025
Xiangde Luo, Xiyue Wang, Feyisope Eweje, Xiaoming Zhang, Sen Yang, Ryan Quinton, Jinxi Xiang, Yuchen Li, Yuanfeng Ji, Zhe Li, et al. Ensemble learning of foundation models for precision oncology.arXiv preprint arXiv:2508.16085, 2025
-
[27]
Dmitry Nechaev, Alexey Pchelnikov, and Ekaterina Ivanova. Hibou: A family of foundational vision transformers for pathology.arXiv preprint arXiv:2406.05074, 2024
-
[28]
Benchmarking foundation models as feature extractors for weakly supervised computational pathology.Nature Biomedical Engineering, pages 1–11, 2025
Peter Neidlinger, Omar SM El Nahhas, Hannah Sophie Muti, Tim Lenz, Michael Hoffmeis- ter, Hermann Brenner, Marko van Treeck, Rupert Langer, Bastian Dislich, Hans Michael Behrens, et al. Benchmarking foundation models as feature extractors for weakly supervised computational pathology.Nature Biomedical Engineering, pages 1–11, 2025
2025
-
[29]
GrapHist: Graph self-supervised learning for histopathology.arXiv preprint arXiv:2603.00143, 2026
Sevda Ö˘güt, Cédric Vincent-Cuaz, Natalia Dubljevic, Carlos Hurtado, Vaishnavi Subrama- nian, Pascal Frossard, and Dorina Thanou. GrapHist: Graph self-supervised learning for histopathology.arXiv preprint arXiv:2603.00143, 2026
-
[30]
George Shaikovski, Adam Casson, Kristen Severson, Eric Zimmermann, Yi Kan Wang, Jeremy D Kunz, Juan A Retamero, Gerard Oakley, David Klimstra, Christopher Kanan, et al. PRISM: A multi-modal generative foundation model for slide-level histopathology.arXiv preprint arXiv:2405.10254, 2024
-
[31]
TransMIL: Transformer based correlated multiple instance learning for whole slide image classification
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. TransMIL: Transformer based correlated multiple instance learning for whole slide image classification. In NeurIPS, 2021
2021
-
[32]
A foundation model for clinical-grade computational pathology and rare cancers detection.Nature Medicine, 30(10):2924–2935, 2024
Eugene V orontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Kristen Severson, Eric Zimmermann, James Hall, Neil Tenenholtz, Nicolo Fusi, et al. A foundation model for clinical-grade computational pathology and rare cancers detection.Nature Medicine, 30(10):2924–2935, 2024
2024
-
[33]
Transformer-based unsupervised contrastive learning for histopathological image classification.Medical Image Analysis, 81:102559, 2022
Xiyue Wang, Sen Yang, Jun Zhang, Minghui Wang, Jing Zhang, Wei Yang, Junzhou Huang, and Xiao Han. Transformer-based unsupervised contrastive learning for histopathological image classification.Medical Image Analysis, 81:102559, 2022
2022
-
[34]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[35]
A foundation model for generalizable cancer diagnosis and survival prediction from histopathological images.Nature Communications, 16(1):2366, 2025
Zhaochang Yang, Ting Wei, Ying Liang, Xin Yuan, Ruitian Gao, Yujia Xia, Jie Zhou, Yue Zhang, and Zhangsheng Yu. A foundation model for generalizable cancer diagnosis and survival prediction from histopathological images.Nature Communications, 16(1):2366, 2025
2025
-
[36]
Zhidong Yang, Xiuhui Shi, Wei Ba, Zhigang Song, Haijing Luan, Taiyuan Hu, Senlin Lin, Jiguang Wang, Shaohua Kevin Zhou, and Rui Yan. Fusion of multi-scale heterogeneous pathology foundation models for whole slide image analysis.arXiv preprint arXiv:2510.27237, 2025
-
[37]
Kaggle-PANDA-1st-place-solution, December 2024
Kentaro Yoshioka and Yusuke Fujimoto. Kaggle-PANDA-1st-place-solution, December 2024. URLhttps://github.com/kentaroy47/Kaggle-PANDA-1st-place-solution
2024
-
[38]
CoCa: Contrastive captioners are image-text foundation models.TMLR, 2022
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. CoCa: Contrastive captioners are image-text foundation models.TMLR, 2022
2022
-
[39]
FM2: Fusing multiple foundation models for pathology image analysis via disentangled consensus-divergence representation.Information Fusion, page 103840, 2025
Ziqi Yu, Shengjie Zhang, Nidan Qiao, Yao Zhao, Lequan Yu, Tingying Peng, and Xiao-Yong Zhang. FM2: Fusing multiple foundation models for pathology image analysis via disentangled consensus-divergence representation.Information Fusion, page 103840, 2025. 12
2025
-
[40]
Andrew Zhang, Guillaume Jaume, Anurag Vaidya, Tong Ding, and Faisal Mahmood. Ac- celerating data processing and benchmarking of AI models for pathology.arXiv preprint arXiv:2502.06750, 2025
-
[41]
Deep mutual learning
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. In IEEE CVPR, 2018
2018
-
[42]
Uncertainty-aware ensemble of foundation models differentiates glioblastoma from its mimics
Junhan Zhao, Shih-Yen Lin, Raphaël Attias, Liza Mathews, Christian Engel, Guillaume Larghero, Dmytro Vremenko, Ting-Wan Kao, Tsung-Hua Lee, Yu-Hsuan Wang, et al. Uncertainty-aware ensemble of foundation models differentiates glioblastoma from its mimics. Nature Communications, 16(1):8341, 2025
2025
-
[43]
Eric Zimmermann, Eugene V orontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, et al. Virchow2: Scaling self-supervised mixed magnification models in pathology.arXiv preprint arXiv:2408.00738, 2024. 13 Contents 1 Introduction 1 2 Related work 2 3 Disagreement-informed coordi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.