From Failure Taxonomy to Intervention: A Diagnostic Methodology for Industry-Scale AVLM in Video and Live-Streaming Platform Moderation
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
A diagnostic methodology classifies AVLM failures into observable signatures and maps each to a targeted intervention space for video and live-streaming moderation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
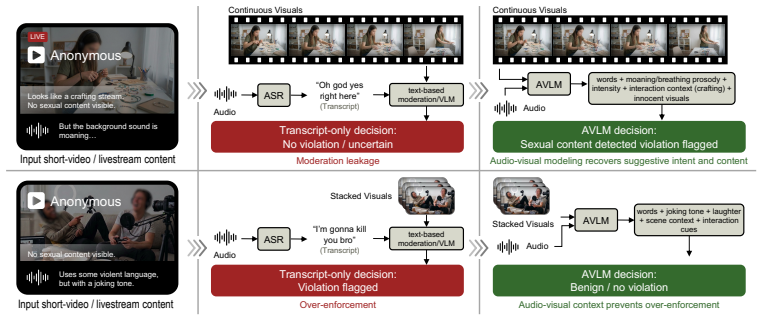
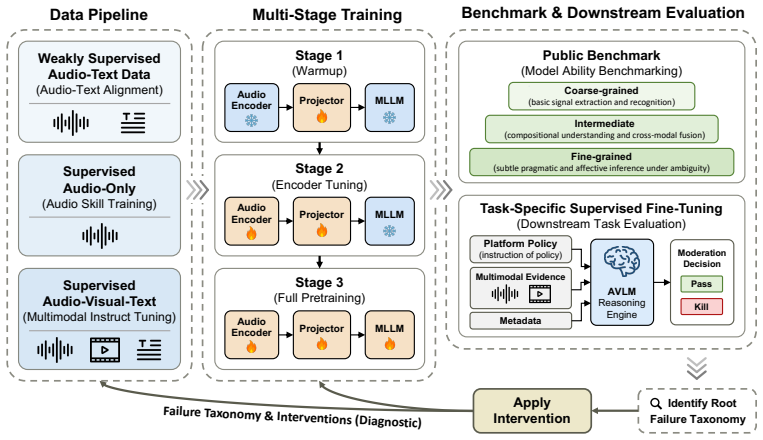
The central claim is that deployment failures in AVLMs are rarely self-explanatory and that similar failures can arise from different causes; therefore a taxonomy of observable failure signatures, when linked to an intervention space, allows failures to be localized and translated into targeted model-development actions rather than heuristic trial-and-error throughout the development and alignment lifecycle.
What carries the argument
The failure taxonomy that organizes observable failure signatures and maps each class to a distinct intervention space.
If this is right
- Improvement efforts shift from benchmark-driven trial-and-error to traceable, cause-specific changes.
- Benchmark gains become more attributable to particular interventions rather than opaque overall progress.
- Failures in noisy, ambiguous, or region-specific content become traceable to underlying model causes.
- The methodology applies across the entire development and alignment lifecycle of a production AVLM.
Where Pith is reading between the lines
- The same taxonomy structure could be tested on other multimodal moderation tasks outside video and live-streaming.
- If the signatures prove stable across different platforms, the methodology could reduce duplicated diagnostic work.
- Platform-specific policy objectives might be folded into the intervention space as an explicit dimension.
Load-bearing premise
Observable failure signatures can be reliably classified into distinct classes whose causes are sufficiently separable to allow targeted interventions.
What would settle it
A set of real platform failures classified by the taxonomy yields either multiple conflicting interventions for the same signature or no usable mapping to any intervention space.
Figures

read the original abstract
Industry-scale video and live-streaming moderation imposes requirements that are difficult to satisfy with generic pretrained public models or external APIs, including adaptation to platform-specific data distributions, policy-specific objectives, and product-level safety constraints. As a result, platforms must undertake internal model development, naturally turning to shared public research for guidance. However, existing multimodal foundation-model studies primarily report architectures, training recipes, data scaling strategies, and benchmark results, but provide less systematic guidance on how failures should be localized and translated into targeted model-development interventions. Interventions are essential because deployment failures are rarely self-explanatory. Similar failures can originate from different causes. Without targeted interventions, improvement reduces to heuristic trial-and-error, where benchmark improvements are weakly attributable, and failures are difficult to trace to their underlying causes. To address this gap, we present a diagnostic methodology for industry-scale Audio-Visual-Language Models AVLM development. The methodology maps model failures into a taxonomy of observable failure signatures and links each class of failure to an intervention space. We instantiate this methodology across the development and alignment lifecycle of an AVLM foundation model for a large-scale video and live-streaming platform. The resulting system supports over 100 regions and is designed for noisy, ambiguous, and highly diverse content drawn from global platform traffic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a diagnostic methodology for industry-scale Audio-Visual-Language Model (AVLM) development in video and live-streaming moderation. It maps observable model failures into a taxonomy of failure signatures and links each class to a corresponding intervention space. The methodology is instantiated across the full development and alignment lifecycle of an AVLM foundation model deployed on a large-scale platform supporting over 100 regions with noisy, ambiguous, and diverse global content.
Significance. If the taxonomy classes prove separable by cause and the linked interventions demonstrably improve traceability and attribution over heuristic approaches, the work would address a documented gap in multimodal foundation-model literature, which focuses primarily on architectures, scaling, and benchmarks rather than systematic failure localization for deployment. The explicit positioning as a methodology contribution (rather than an empirical result) is appropriate and strengthens the framing.
major comments (1)
- [Abstract] Abstract: The central claim that the methodology 'maps model failures into a taxonomy of observable failure signatures and links each class of failure to an intervention space' and is 'instantiated across the development and alignment lifecycle' is presented without any concrete taxonomy entries, example failure signatures, intervention mappings, or outcome metrics from the claimed instantiation. This absence makes the load-bearing premise—that signatures are reliably classifiable with separable causes—impossible to evaluate from the text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the potential contribution of a systematic failure-localization methodology in the multimodal foundation-model literature. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the methodology 'maps model failures into a taxonomy of observable failure signatures and links each class of failure to an intervention space' and is 'instantiated across the development and alignment lifecycle' is presented without any concrete taxonomy entries, example failure signatures, intervention mappings, or outcome metrics from the claimed instantiation. This absence makes the load-bearing premise—that signatures are reliably classifiable with separable causes—impossible to evaluate from the text.
Authors: We agree that the abstract, in its current form, is high-level and omits concrete illustrations, which prevents a reader from directly assessing the separability of the claimed failure signatures. The body of the manuscript supplies these elements (Section 3 defines the taxonomy with eight classes; Table 2 provides labeled failure-signature examples with observable traits; Section 4 enumerates the corresponding intervention spaces; Section 6 reports attribution and traceability metrics from the full lifecycle deployment). Nevertheless, the referee’s observation is correct for the abstract itself. We will therefore revise the abstract to include one concise, representative example of a failure signature, its assigned class, the linked intervention, and a high-level outcome metric, while remaining within the word limit. This change will make the central claim evaluable from the abstract alone. revision: yes
Circularity Check
No significant circularity in methodology framework
full rationale
The paper presents a diagnostic methodology mapping observable failure signatures in AVLMs to a taxonomy and intervention spaces, instantiated in an industry lifecycle. No equations, derivations, fitted parameters, or predictions appear. The central premise (classifiable signatures with separable causes) is definitional to the framework rather than derived or fitted. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained as a methodology contribution without reducing claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nouar AlDahoul, Myles Joshua Toledo Tan, Harishwar Reddy Kasireddy, and Yasir Zaki. Advancing content moderation: Evaluating large language models for detecting sensitive content across text, images, and videos.arXiv preprint arXiv:2411.17123, 2024
-
[2]
Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837, 2024
Niki Amini-Naieni, Tengda Han, and Andrew Zisserman. Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837, 2024
2024
-
[3]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor C˘arbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. Screenai: A vision-language model for ui and infographics understanding.arXiv preprint arXiv:2402.04615, 2024
-
[4]
Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
2024
-
[5]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Fleurs: Few-shot learning evaluation of universal representations of speech
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. Fleurs: Few-shot learning evaluation of universal representations of speech. In2022 IEEE Spoken Language Technology Workshop (SLT), pages 798–805. IEEE, 2023
2023
-
[7]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346–355, 2024
2024
-
[8]
FlagEval. ERQA. https://huggingface.co/datasets/FlagEval/ERQA, 2025. Hugging Face dataset repository adapted from embodiedreasoning/ERQA. Accessed: 2026-05-03
2025
-
[9]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[11]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[12]
Content moderation by llm: from accuracy to legitimacy.Artificial Intelligence Review, 58(10):320, 2025
Tao Huang. Content moderation by llm: from accuracy to legitimacy.Artificial Intelligence Review, 58(10):320, 2025
2025
-
[13]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[14]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
2016
-
[15]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[18]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[19]
Yizhi Li, Yinghao Ma, Ge Zhang, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, et al. Omnibench: Towards the future of universal omni-language models.arXiv preprint arXiv:2409.15272, 2024
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[21]
Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
2024
-
[22]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
2022
-
[23]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
2022
-
[24]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
2021
-
[25]
Policy-as-prompt: Rethinking content moderation in the age of large language models
Konstantina Palla, José Luis Redondo García, Claudia Hauff, Francesco Fabbri, Andreas Damianou, Henrik Lindström, Dan Taber, and Mounia Lalmas. Policy-as-prompt: Rethinking content moderation in the age of large language models. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 840–854, 2025
2025
-
[26]
Facebook’s flood of languages leaves it struggling to monitor content.Reuters, May 2019
Reuters Staff. Facebook’s flood of languages leaves it struggling to monitor content.Reuters, May 2019. URL https://www.reuters.com/article/world/facebooks-flood-o f-languages-leaves-it-struggling-to-monitor-content-idUSKCN1RZ0DL/ . Accessed: 2026-03-17
2019
-
[27]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[29]
Avhbench: A cross-modal hallucination benchmark for audio-visual large language models
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. Avhbench: A cross-modal hallucination benchmark for audio-visual large language models. arXiv preprint arXiv:2410.18325, 2024
-
[30]
Our sixth transparency report on content moderation in europe
TikTok. Our sixth transparency report on content moderation in europe. https://newsroom .tiktok.com/digital-services-act-our-sixth-transparency-report-on-con tent-moderation-in-europe?lang=en-150 , February 2026. Reports around 112 million violating pieces of content removed in July–December 2025; 93.8% actioned without human review; 97.6% automated decis...
2026
-
[31]
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark.arXiv preprint arXiv:2506.04779, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive benchmark for robust multi-image understanding.arXiv preprint arXiv:2406.09411, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
2025
-
[34]
Filter-and-refine: A mllm based cascade system for industrial-scale video content moderation
Zixuan Wang, Jinghao Shi, Hanzhong Liang, Xiang Shen, Vera Wen, Zhiqian Chen, Yifan Wu, Zhixin Zhang, and Hongyu Xiong. Filter-and-refine: A mllm based cascade system for industrial-scale video content moderation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 873–880, 2025
2025
-
[35]
RealWorldQA
xAI. RealWorldQA. https://huggingface.co/datasets/xai-org/RealworldQA, 2024. Hugging Face dataset repository. Accessed: 2026-05-03
2024
-
[36]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.