Reactive Graphs for Efficient Markov Chain Monte Carlo Inference in Probabilistic Programming Languages
Pith reviewed 2026-06-30 03:41 UTC · model grok-4.3
The pith
Automatically translating probabilistic programs to dynamic graphs lets MCMC proposals recompute only the affected subgraph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
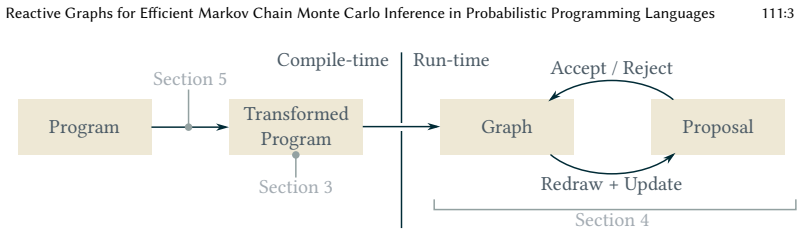
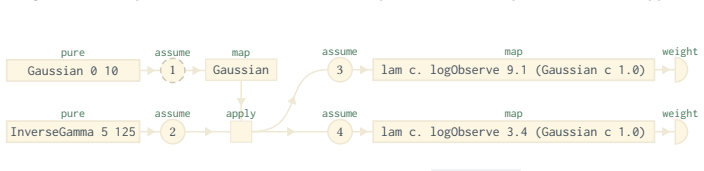
By automatically building a dynamic graph from the probabilistic program that makes data dependencies explicit, the method ensures that each MCMC proposal only requires recomputation of the subgraph reachable from the redrawn random variables.
What carries the argument
Dynamic graph built from the program that represents data dependencies, enabling incremental evaluation during inference.
If this is right
- Proposals require less computation time on average.
- The same program interface supports both Bayesian networks and universal probabilistic programs.
- Efficiency improvements scale with the size of the model and the locality of changes.
- More precise inference results are achievable within practical time limits.
Where Pith is reading between the lines
- The dependency graph could be reused across different inference algorithms that rely on repeated evaluations.
- This technique might apply to other domains involving repeated execution of programs with small changes.
- Extending the graph to handle continuous changes could support online learning scenarios.
Load-bearing premise
The automatic translation process correctly identifies every data dependency in the program so that no necessary recomputation is skipped.
What would settle it
Running the method on a test program with a hidden dependency and comparing the resulting MCMC samples to those from a naive full-recomputation implementation; mismatch would indicate failure.
Figures





read the original abstract
An important aspect of making inference based on a probabilistic program practical is efficiency; faster evaluation enables more work per unit of time, which can be translated into more precision. Inference via Markov chain Monte Carlo has a property that can be favorably exploited for efficiency: most proposed samples are computed as minor variations of previous samples, i.e., a clever implementation can skip computations pertaining to what is unchanged. This paper provides an approach for automatically translating a probabilistic program to a dynamic graph, reminiscent of functional reactive programming, that explicitly represents data dependencies, enabling proposals to only recompute the parts of the graph that depend on redrawn random variables. The graph-building interface follows familiar functional programming interfaces, which also connect to their expressiveness in terms of probabilistic programming: models using the applicative functor portion express Bayesian networks, while those using monads represent universal probabilistic programming languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide an approach for automatically translating a probabilistic program to a dynamic graph, reminiscent of functional reactive programming, that explicitly represents data dependencies. This enables MCMC proposals to only recompute the parts of the graph that depend on redrawn random variables. The graph-building interface follows familiar functional programming interfaces, connecting to expressiveness: applicative fragments yield Bayesian networks while monads represent universal PPLs.
Significance. If the automatic translation correctly and completely captures all data dependencies without error, the approach could improve the practical efficiency of MCMC inference in probabilistic programming languages by exploiting the incremental nature of proposals, potentially allowing more samples per unit time without changing the target distribution.
major comments (1)
- Abstract: The central efficiency claim depends on the translation procedure exactly capturing every data dependency so that MCMC proposals can safely skip unchanged subcomputations while preserving detailed balance. No mechanism, algorithm, or proof is supplied for how the translation handles monadic programs containing control flow (if, recursion, etc.) whose targets depend on sampled values; if even one link is missed, the resulting distribution differs from the intended model.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the importance of correctness in dependency tracking. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: The central efficiency claim depends on the translation procedure exactly capturing every data dependency so that MCMC proposals can safely skip unchanged subcomputations while preserving detailed balance. No mechanism, algorithm, or proof is supplied for how the translation handles monadic programs containing control flow (if, recursion, etc.) whose targets depend on sampled values; if even one link is missed, the resulting distribution differs from the intended model.
Authors: We agree that any missed dependency would invalidate the target distribution, so the construction must be complete by design. The manuscript (Section 3) describes a runtime graph builder that instruments the monadic interface: each bind registers a dependency edge from the sampled value to all subsequent computations that use it. Control flow (conditionals, recursion) is handled because the program is executed to build the graph; only the taken branch or recursion depth is materialized, with edges recorded exactly for the values that flow through. When a proposal redraws an upstream variable, the reactive update propagates only along existing edges and re-executes the affected suffix, rebuilding any control-flow decisions that now differ. This is the same mechanism that lets the monadic fragment express universal PPLs. The current text argues correctness by construction rather than supplying a separate inductive proof; we will add a short pseudocode listing of the builder and a one-paragraph argument that every data flow in the original program appears as an edge. revision: partial
Circularity Check
No circularity: technique is a proposed implementation with no self-referential derivations
full rationale
The paper presents a translation of probabilistic programs to dynamic reactive graphs for efficient MCMC proposals by skipping unchanged subcomputations. The abstract and description frame this as an engineering approach connecting functional interfaces to PPL expressiveness (applicative for Bayesian networks, monads for universal PPLs). No equations, fitted parameters, or predictions are defined in terms of themselves. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim is an implementation technique whose correctness is an external engineering question, not a derivation that reduces to its own inputs by construction. This matches the default case of a self-contained contribution without circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Most MCMC proposals are minor variations of previous samples, so selective recomputation is beneficial.
- domain assumption Probabilistic programs can be translated into dynamic graphs that correctly represent data dependencies.
invented entities (1)
-
Reactive graph for probabilistic programs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Conditional Expectation and Unbiased Sequential Estimation
“Conditional Expectation and Unbiased Sequential Estimation. ”The Annals of Mathematical Statistics, 18, 1, (Mar. 1947), 105–110. doi:10.1214/aoms/1177730497. William Brandon, Benjamin Driscoll, Frank Dai, Wilson Berkow, and Mae Milano. June 6,
-
[2]
Better Defunctionalization through Lambda Set Specialization
“Better Defunctionalization through Lambda Set Specialization. ”Reproduction Package for Article "Better Defunctionalization Through Lambda Set Specialization", 7, (June 6, 2023), 146:977–146:1000, PLDI, (June 6, 2023). doi:10.1145/3591260. David Broman. Oct. 20,
-
[3]
“A Vision of Miking: Interactive Programmatic Modeling, Sound Language Composition, and Self-Learning Compilation. ” In:Proceedings of the 12th ACM SIGPLAN International Conference on Software Language Engineering(SLE 2019). Association for Computing Machinery, New York, NY, USA, (Oct. 20, 2019), 55–60.isbn: 978-1- 4503-6981-7. doi:10.1145/3357766.3359531...
-
[4]
A Probabilistic Epidemiological Model for Infectious Diseases: The Case of COVID-19 at Global-Level
“A Probabilistic Epidemiological Model for Infectious Diseases: The Case of COVID-19 at Global-Level. ”Risk Analysis, 43, 1, 183–201. doi:10.1111/risa.13950. Conal Elliott and Paul Hudak. Aug. 1,
-
[5]
“Functional Reactive Animation. ” In:Proceedings of the Second ACM SIGPLAN International Conference on Functional Programming(ICFP ’97). Association for Computing Machinery, New York, NY, USA, (Aug. 1, 1997), 263–273.isbn: 978-0-89791-918-0. doi:10.1145/258948.258973. Joseph Felsenstein. Sept. 1,
-
[6]
“Maximum Likelihood and Minimum-Steps Methods for Estimating Evolutionary Trees from Data on Discrete Characters. ”Systematic Biology, 22, 3, (Sept. 1, 1973), 240–249. doi:10.1093/sysbio/22.3.240. Walter R Gilks, Sylvia Richardson, and David Spiegelhalter. 1995.Markov Chain Monte Carlo in Practice. CRC press. W. K. Hastings. Apr. 1,
-
[7]
Monte Carlo Sampling Methods Using Markov Chains and Their Applications
“Monte Carlo Sampling Methods Using Markov Chains and Their Applications. ”Biometrika, 57, 1, (Apr. 1, 1970), 97–109. doi:10.1093/biomet/57.1.97. Sebastian Höhna, Tracy A. Heath, Bastien Boussau, Michael J. Landis, Fredrik Ronquist, and John P. Huelsenbeck. Sept. 1,
-
[8]
Probabilistic Graphical Model Representation in Phylogenetics
“Probabilistic Graphical Model Representation in Phylogenetics. ”Systematic Biology, 63, 5, (Sept. 1, 2014), 753–771. doi:10.1093/sysbio/syu039. Matthew D. Homan and Andrew Gelman. Jan. 1,
-
[9]
The No-U-turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo
“The No-U-turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. ”J. Mach. Learn. Res., 15, 1, (Jan. 1, 2014), 1593–1623. Retrieved Apr. 7, 2026 from https://dl.acm .org/doi/10.5555/2627435.2638586. Alan M. Horowitz. Oct. 10,
-
[10]
A Generalized Guided Monte Carlo Algorithm
“A Generalized Guided Monte Carlo Algorithm. ”Physics Letters B, 268, 2, (Oct. 10, 1991), 247–252. doi:10.1016/0370-2693(91)90812-5. Dexter Kozen. Oct
-
[11]
Semantics of Probabilistic Programs
“Semantics of Probabilistic Programs. ” In:20th Annual Symposium on Foundations of Computer Science (Sfcs 1979). 20th Annual Symposium on Foundations of Computer Science (Sfcs 1979). (Oct. 1979), 101–114. doi:10.1109/SFCS.1979.38. Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. June 1,
-
[12]
Equation of State Calculations by Fast Computing Machines
“Equation of State Calculations by Fast Computing Machines. ”The Journal of Chemical Physics, 21, 6, (June 1, 1953), 1087–1092. doi:10.1063/1.1699114. Lawrence Murray, Daniel Lundén, Jan Kudlicka, David Broman, and Thomas Schön. Mar. 31,
-
[13]
Delayed Sampling and Automatic Rao-Blackwellization of Probabilistic Programs
“Delayed Sampling and Automatic Rao-Blackwellization of Probabilistic Programs. ” In:Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics. International Conference on Artificial Intelligence and Statistics. PMLR, (Mar. 31, 2018), 1037–1046. Retrieved Apr. 7, 2026 from https://proceedings.mlr.press/v84/murray18...
2018
-
[14]
Retrieved Apr
Curran Associates, Inc. Retrieved Apr. 7, 2026 from https://proceedings.neurips.cc/paper/2008/hash/92cc227532d17e56e07902b254dfad10-Abstract.html. Benjamin D Redelings. Sept. 29,
2026
-
[15]
BAli-Phy Version 3: Model-Based Co-Estimation of Alignment and Phylogeny
“BAli-Phy Version 3: Model-Based Co-Estimation of Alignment and Phylogeny. ” Bioinformatics, 37, 18, (Sept. 29, 2021), 3032–3034. doi:10.1093/bioinformatics/btab129. Daniel Ritchie, Andreas Stuhlmüller, and Noah Goodman. May 2,
-
[16]
“C3: Lightweight Incrementalized MCMC for Probabilistic Programs Using Continuations and Callsite Caching. ” In:Proceedings of the 19th International Conference on Artificial Intelligence and Statistics. Artificial Intelligence and Statistics. PMLR, (May 2, 2016), 28–37. Retrieved Mar. 23, 2026 from https://proceedings.mlr.press/v51/ritchie16.html. Viktor...
-
[17]
Past, Present and Future of Software for Bayesian Inference
“Past, Present and Future of Software for Bayesian Inference. ”Statistical Science, 39, 1, (Feb. 2024), 46–61. doi:10.1214/23-STS907. Saifuddin Syed, Alexandre Bouchard-Côté, George Deligiannidis, and Arnaud Doucet
-
[18]
Non-Reversible Parallel Tempering: A Scalable Highly Parallel MCMC Scheme
“Non-Reversible Parallel Tempering: A Scalable Highly Parallel MCMC Scheme. ”Journal of the Royal Statistical Society: Series B (Statistical Methodology), 84, 2, 321–350. doi:10.1111/rssb.12464. Martin J Wainwright and Michael I Jordan
-
[19]
Graphical Models, Exponential Families, and Variational Inference
“Graphical Models, Exponential Families, and Variational Inference. ” Foundations and Trends®in Machine Learning, 1, 1–2, 1–305. Ziheng Yang. 2006.Computational Molecular Evolution. OUP Oxford
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.