Relevance Is Not Permission: Warranted Attention for Value Contributions
Pith reviewed 2026-06-30 06:39 UTC · model grok-4.3
The pith
Attention relevance does not guarantee that a weighted value term becomes prediction evidence on the metric path.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
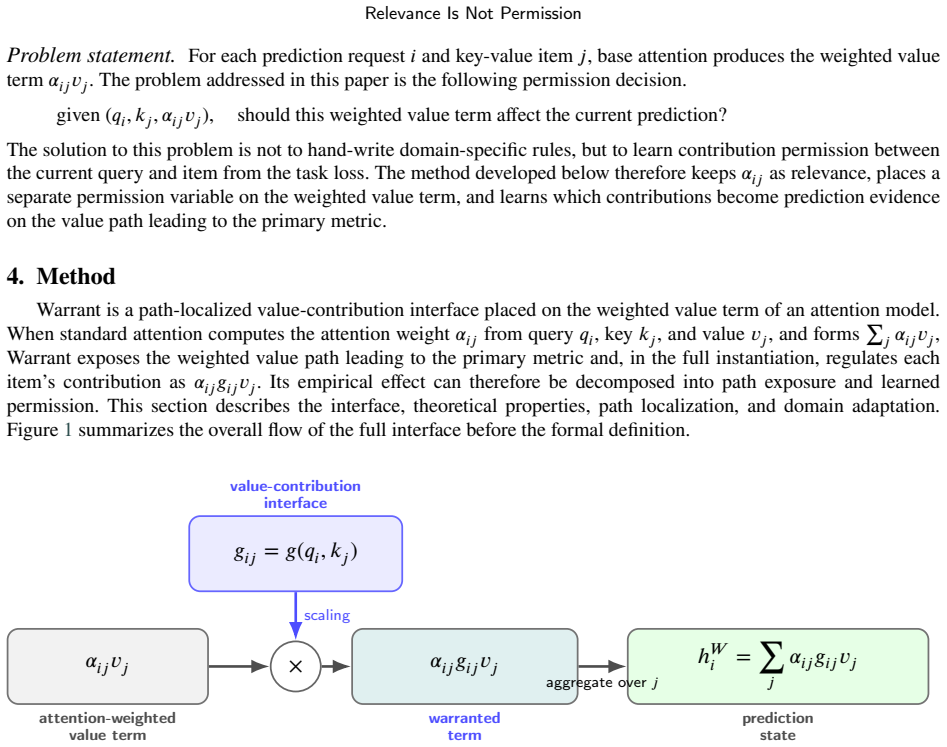
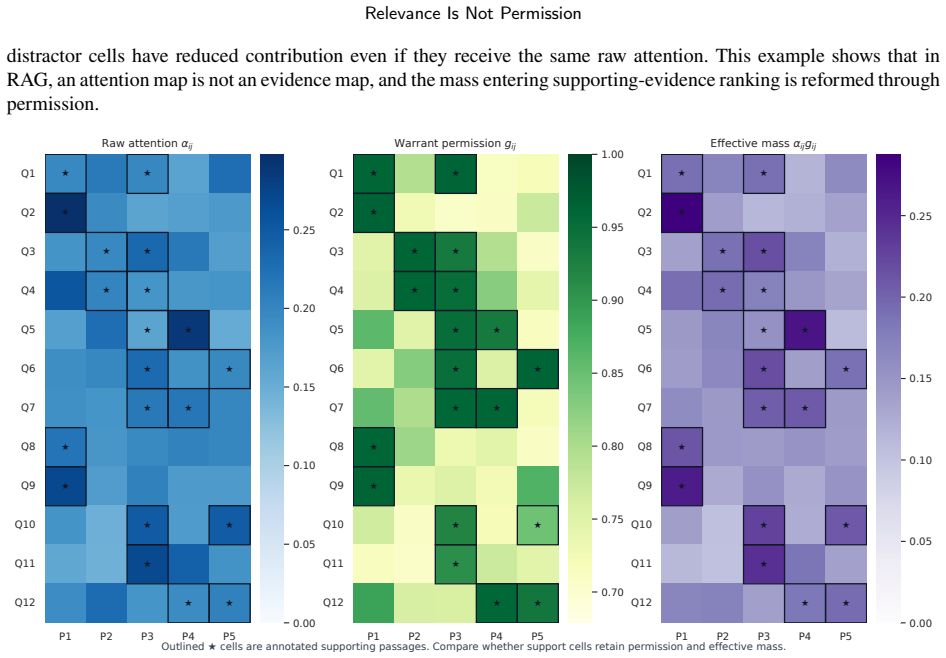
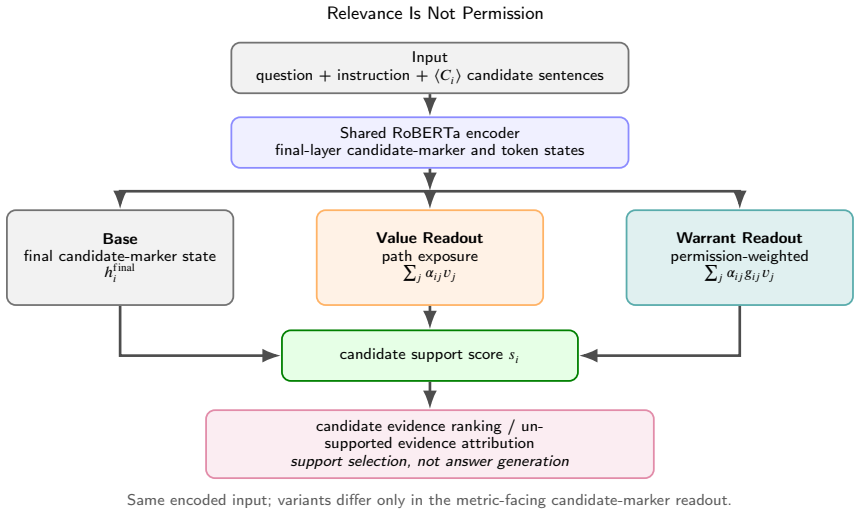
Relevance is not permission. Attention lets a model read key-value items related to the current query, but it does not guarantee that the value contribution of such an item becomes prediction evidence. A retrieved passage may be relevant to a question without being supporting evidence, and a historical fact or temporal neighbor may even blur true-tail ranking or the current edge score. Warrant preserves attention relevance alpha_ij, exposes the value path leading to the primary metric, and turns alpha_ij * v_j into alpha_ij * g_ij * v_j through learned query-item permission g_ij. Correct-path placement outperforms direction-aware baselines in every domain and exceeds generic attention placem
What carries the argument
Warrant, a path-localized interface that preserves attention relevance alpha_ij, exposes the value path, and multiplies by learned query-item permission g_ij to produce alpha_ij * g_ij * v_j.
If this is right
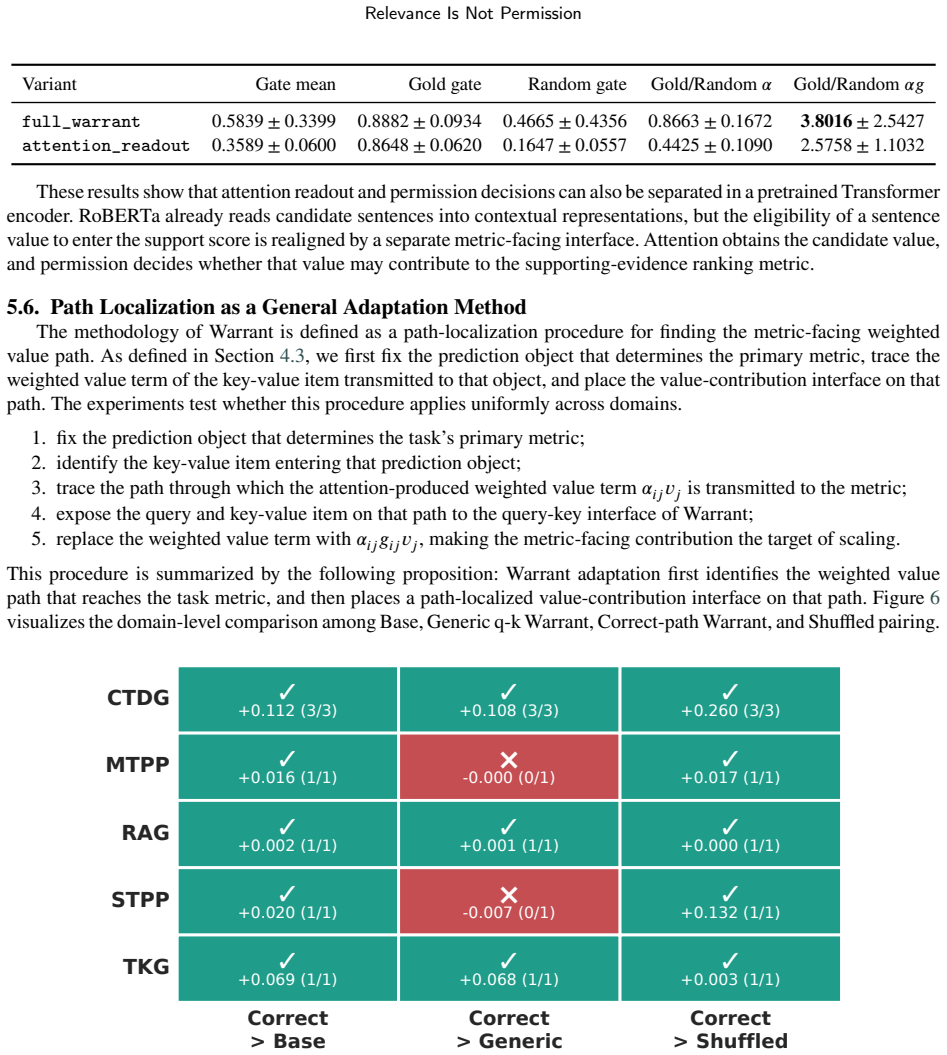
- Correct-path placement of Warrant outperforms direction-aware base performance in every domain.
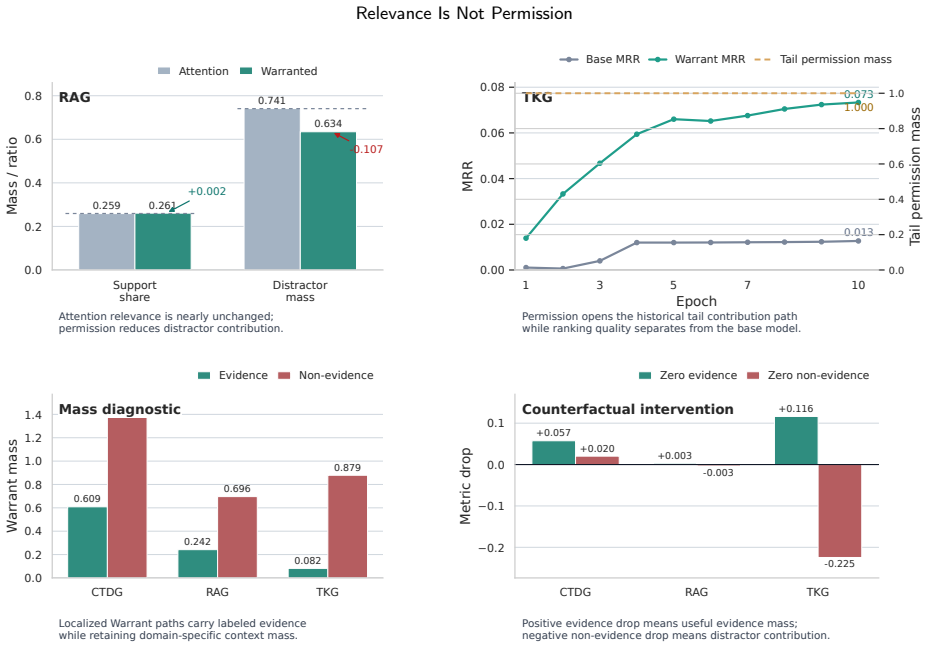
- Path-localization exceeds generic attention placement by +0.1076 AUC in CTDG and +0.0683 MRR in TKG.
- Most TKG gains arise from historical-tail value path exposure.
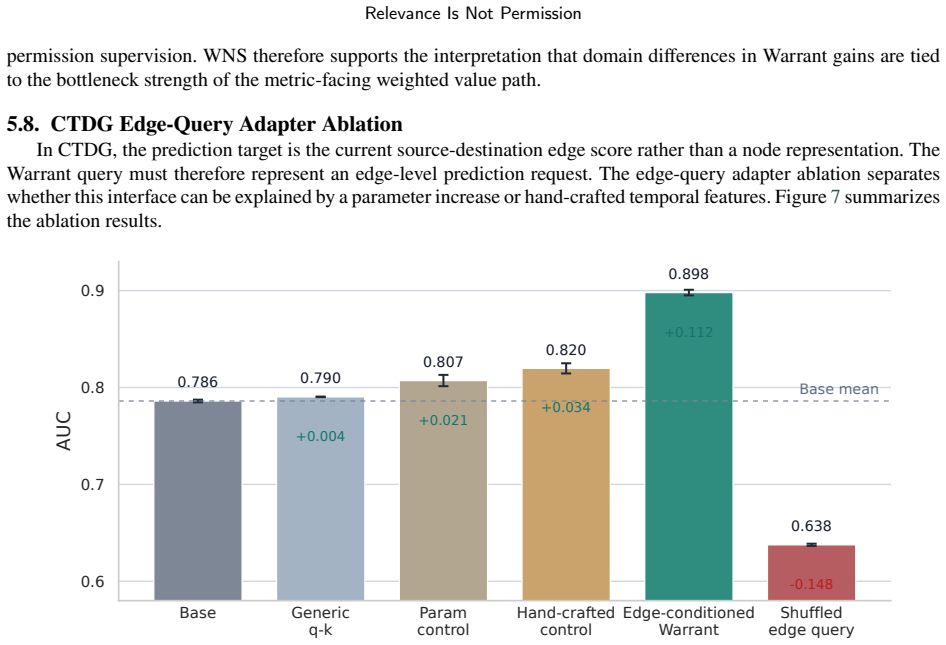
- The core CTDG gain arises from edge-conditioned query-item permission.
- The same operator improves the primary metric in 27 of 32 paired comparisons across five task domains.
Where Pith is reading between the lines
- If path-localized placement fails to outperform generic placement, the necessity of exposing and gating the specific value path would be undermined.
- Gains that disappear when g_ij is trained without path conditioning would indicate that the operator functions mainly by adding capacity rather than by supplying permission.
- The distinction between relevance and permission could be tested by inserting similar gates on value paths in attention models outside the five domains examined here.
Load-bearing premise
The learned query-item permission g_ij can be trained to supply genuine path-specific permission rather than merely adding fitted parameters that increase model capacity.
What would settle it
Observing equal or better performance when the permission gate is applied only to non-metric paths or replaced by random values would falsify the claim that path-localized permission is required for the value term to become evidence.
Figures
read the original abstract
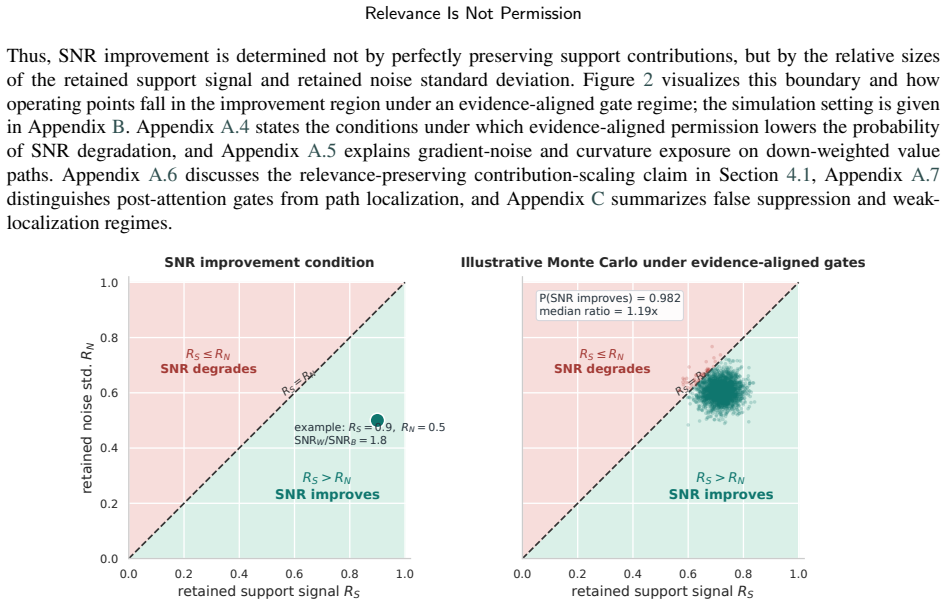
Relevance is not permission. Attention lets a model read key-value items related to the current query, but it does not guarantee that the value contribution of such an item becomes prediction evidence. A retrieved passage may be relevant to a question without being supporting evidence, and a historical fact or temporal neighbor may even blur true-tail ranking or the current edge score. This paper formalizes this gap as a permission problem for the weighted value term alpha_ij * v_j that is actually added to the prediction path. We propose Warrant, a path-localized interface that preserves attention relevance alpha_ij, exposes the value path leading to the primary metric, and, in the full model, turns alpha_ij * v_j into alpha_ij * g_ij * v_j through learned query-item permission g_ij. We place the same operator on the metric-defining value paths of CTDG link prediction, MTPP next-mark ranking, RAG supporting evidence selection, STPP next-location forecasting, and TKG tail prediction. Across 32 paired comparisons, 3 seeds, and 192 total runs, Warrant improves the primary metric in 27 comparisons; practical tiers consist of 10 substantial effects, 1 marginal effect, 8 positive but uncertain effects, 8 tie/negligible effects, and 5 drops. In the path-localization check, correct-path placement outperforms direction-aware Base performance in every domain and exceeds generic attention placement by +0.1076 AUC in CTDG and +0.0683 MRR in TKG. Ablations show that most TKG gains come from historical-tail value path exposure, whereas the core CTDG gain comes from edge-conditioned query-item permission. In conclusion, prediction evidence is not attention mass. A weighted value term becomes evidence only when it is warranted on the path to the metric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that attention provides relevance (alpha_ij) but not permission for value terms (v_j) to become prediction evidence on the metric path. It introduces Warrant, which augments the value contribution to alpha_ij * g_ij * v_j via a learned query-item permission factor g_ij. The operator is placed on metric-defining value paths in five domains (CTDG link prediction, MTPP next-mark ranking, RAG evidence selection, STPP next-location forecasting, TKG tail prediction). Across 32 paired comparisons, 3 seeds and 192 runs, it improves the primary metric in 27 cases, with path-localization ablations showing correct-path placement outperforming generic attention (+0.1076 AUC in CTDG, +0.0683 MRR in TKG) and domain-specific sources of gains (historical-tail exposure in TKG, edge-conditioned permission in CTDG).
Significance. If the gains are shown to arise from path-specific permission rather than generic capacity increases, the result could influence attention design in temporal and graph domains by formalizing the distinction between relevance and evidential warrant. The multi-domain application, path-localization checks, and use of 3 seeds with 192 total runs are strengths that support reproducibility and breadth.
major comments (3)
- [Abstract] Abstract: the central claim that alpha_ij * g_ij * v_j supplies warranted evidence (rather than merely adding trainable parameters) is not supported by any control that inserts a comparable number of parameters (e.g., an unstructured learned multiplier of identical size) at the same alpha_ij * v_j location without query-item conditioning; the 27/32 improvement count is therefore compatible with a pure capacity explanation.
- [Path-localization check] Path-localization check: while correct-path placement is reported to outperform direction-aware Base and generic attention placement, the comparison does not include a parameter-matched unstructured control at the value path, leaving the interpretation that 'a weighted value term becomes evidence only when it is warranted' without direct empirical support.
- [Empirical results] Empirical results: no equations, parameterization details, or training procedure for g_ij are supplied, nor are statistical tests or per-comparison variance across the 3 seeds; this is load-bearing because the reported gains cannot be assessed for robustness against the added fitting capacity introduced by g_ij.
minor comments (2)
- [Abstract] The abstract would be clearer if it included the explicit mathematical definition of the Warrant operator and g_ij early in the text.
- [Introduction] Minor notation: the distinction between 'permission' and 'relevance' is used throughout but would benefit from a concise one-sentence definition in the introduction.
Simulated Author's Rebuttal
Thank you for the detailed and constructive report. We address each major comment below. Where the comments identify gaps in controls or reporting, we agree that revisions will strengthen the manuscript and will incorporate the requested elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that alpha_ij * g_ij * v_j supplies warranted evidence (rather than merely adding trainable parameters) is not supported by any control that inserts a comparable number of parameters (e.g., an unstructured learned multiplier of identical size) at the same alpha_ij * v_j location without query-item conditioning; the 27/32 improvement count is therefore compatible with a pure capacity explanation.
Authors: We agree that an unstructured, parameter-matched multiplier control placed at the identical location would provide the most direct test against a capacity-only account. Our existing path-localization results already show that gains are larger when the operator is restricted to the metric-defining value path than when placed generically, which is inconsistent with a uniform capacity increase. Nevertheless, we will add the requested unstructured-multiplier ablation in the revision to isolate the contribution of query-item conditioning. revision: yes
-
Referee: [Path-localization check] Path-localization check: while correct-path placement is reported to outperform direction-aware Base and generic attention placement, the comparison does not include a parameter-matched unstructured control at the value path, leaving the interpretation that 'a weighted value term becomes evidence only when it is warranted' without direct empirical support.
Authors: The generic-attention placement already adds a comparable number of parameters without query-item conditioning on the value path, and correct-path placement still outperforms it. We nevertheless accept that an unstructured scalar or vector multiplier of identical size constitutes a cleaner control and will include this experiment in the revised manuscript. revision: yes
-
Referee: [Empirical results] Empirical results: no equations, parameterization details, or training procedure for g_ij are supplied, nor are statistical tests or per-comparison variance across the 3 seeds; this is load-bearing because the reported gains cannot be assessed for robustness against the added fitting capacity introduced by g_ij.
Authors: We will add the defining equations for g_ij, its exact parameterization and initialization, the training procedure, and per-seed means with standard deviations together with appropriate statistical tests for all 32 comparisons. revision: yes
Circularity Check
No circularity: empirical operator validated by external benchmarks
full rationale
The paper introduces the Warrant operator (alpha_ij * g_ij * v_j) as a path-localized modification and reports its effects via 32 paired comparisons, 192 runs, ablations, and path-localization checks across CTDG, MTPP, RAG, STPP, and TKG tasks. The claim that a weighted value term becomes evidence only when warranted is an interpretive conclusion drawn from observed metric gains and correct-path superiority, not a derivation that reduces to the inputs by construction. No equations equate the result to the fit itself, no self-citations are load-bearing for uniqueness or ansatz, and no fitted parameter is relabeled as an independent prediction. The work is self-contained against the reported external benchmarks and controls.
Axiom & Free-Parameter Ledger
free parameters (1)
- g_ij
axioms (1)
- domain assumption Value contribution paths in attention can be isolated and modified independently without affecting other model components.
invented entities (1)
-
Warrant
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural Machine Translation by Jointly Learning to Align and Translate
Bahdanau, D., Cho, K., Bengio, Y., 2015. Neural machine translation by jointly learning to align and translate, in: International Conference on Learning Representations. URL:https://arxiv.org/abs/1409.0473
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M.E., Cohan, A., 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150 URL:https: //arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Cho,K.,vanMerrienboer,B.,Gulcehre,C.,Bahdanau,D.,Bougares,F.,Schwenk,H.,Bengio,Y.,2014. Learningphraserepresentationsusing rnn encoder–decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 URL:https://arxiv.org/abs/1406.1078
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Language modeling with gated convolutional networks, in: Proceedings of the 34th International Conference on Machine Learning, pp
Dauphin, Y.N., Fan, A., Auli, M., Grangier, D., 2017. Language modeling with gated convolutional networks, in: Proceedings of the 34th International Conference on Machine Learning, pp. 933–941
2017
-
[5]
Dhingra,B.,Liu,H.,Yang,Z.,Cohen,W.W.,Salakhutdinov,R.,2017. Gated-attentionreadersfortextcomprehension,in:Proceedingsofthe 55th Annual Meeting of the Association for Computational Linguistics, pp. 1832–1846. URL:https://aclanthology.org/P17-1168/, doi:10.18653/v1/P17-1168
-
[6]
Selective classification for deep neural networks, in: Advances in Neural Information Processing Systems
Geifman, Y., El-Yaniv, R., 2017. Selective classification for deep neural networks, in: Advances in Neural Information Processing Systems. URL:https://papers.nips.cc/paper/7073-selective-classification-for-deep-neural-networks
2017
-
[7]
On calibration of modern neural networks, in: Proceedings of the 34th International Conference on Machine Learning, pp
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q., 2017. On calibration of modern neural networks, in: Proceedings of the 34th International Conference on Machine Learning, pp. 1321–1330. URL:https://proceedings.mlr.press/v70/guo17a.html
2017
-
[8]
Hochreiter,S.,Schmidhuber,J., 1997. Longshort-termmemory. NeuralComputation9,1735–1780. doi:10.1162/neco.1997.9.8.1735
-
[9]
Izacard,G.,Grave,E.,2021. Leveragingpassageretrievalwithgenerativemodelsforopendomainquestionanswering,in:Proceedingsofthe 16th Conference of the European Chapter of the Association for Computational Linguistics, pp. 874–880. URL:https://aclanthology. org/2021.eacl-main.74/, doi:10.18653/v1/2021.eacl-main.74
-
[10]
Dense passage retrieval for open-domain ques- tion answering,
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t., 2020. Dense passage retrieval for open-domain question answering, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp. 6769–6781. URL: https://aclanthology.org/2020.emnlp-main.550/, doi:10.18653/v1/2020.emnlp-main.550. Yu and Ha...
-
[11]
Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D., 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481...
2020
-
[12]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu,Y.,Ott,M.,Goyal,N.,Du,J.,Joshi,M.,Chen,D.,Levy,O.,Lewis,M.,Zettlemoyer,L.,Stoyanov,V.,2019. Roberta:Arobustlyoptimized bert pretraining approach. arXiv preprint arXiv:1907.11692 URL:https://arxiv.org/abs/1907.11692,arXiv:1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Mega: Moving average equipped gated attention, in: International Conference on Learning Representations
Ma, X., Zhou, C., Kong, X., He, J., Gui, L., Neubig, G., May, J., Zettlemoyer, L., 2023. Mega: Moving average equipped gated attention, in: International Conference on Learning Representations
2023
-
[14]
Nogueira,R.,Cho,K.,2019. Passagere-rankingwithbert. arXivpreprintarXiv:1901.04085URL:https://arxiv.org/abs/1901.04085
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Stabilizing transformers for reinforcement learning
Parisotto,E.,Song,H.F.,Rae,J.W.,Pascanu,R.,Gulcehre,C.,Jayakumar,S.M.,Jaderberg,M.,Kaufman,R.L.,Clark,A.,Noury,S.,Botvinick, M., Heess, N., Hadsell, R., 2020. Stabilizing transformers for reinforcement learning. Proceedings of the 37th International Conference on Machine Learning URL:https://proceedings.mlr.press/v119/parisotto20a.html
2020
-
[16]
FiLM: Visual Reasoning with a General Conditioning Layer
Perez,E.,Strub,F.,deVries,H.,Dumoulin,V.,Courville,A.,2018. Film:Visualreasoningwithageneralconditioninglayer,in:Proceedings of the AAAI Conference on Artificial Intelligence. URL:https://arxiv.org/abs/1709.07871
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Outrageously large neural networks: The sparsely- gated mixture-of-experts layer, in: International Conference on Learning Representations
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J., 2017. Outrageously large neural networks: The sparsely- gated mixture-of-experts layer, in: International Conference on Learning Representations. URL:https://openreview.net/forum?id= B1ckMDqlg
2017
-
[18]
Srivastava, R.K., Greff, K., Schmidhuber, J., 2015. Highway networks, in: ICML Deep Learning Workshop. URL:https://arxiv.org/ abs/1505.00387
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
End-to-end memory networks, in: Advances in Neural Information Processing Systems
Sukhbaatar, S., Weston, J., Fergus, R., et al., 2015. End-to-end memory networks, in: Advances in Neural Information Processing Systems. URL:https://papers.nips.cc/paper/5846-end-to-end-memory-networks
2015
-
[20]
Attention is all you need, in: Advances in Neural Information Processing Systems
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2017. Attention is all you need, in: Advances in Neural Information Processing Systems. URL:https://papers.nips.cc/paper/7181-attention-is-all-you-need
2017
-
[21]
Inductive representation learning on temporal graphs, in: International Conference on Learning Representations
Xu, D., Ruan, C., Körpeoğlu, E., Kumar, S., Achan, K., 2020. Inductive representation learning on temporal graphs, in: International Conference on Learning Representations. URL:https://openreview.net/forum?id=rJeW1yHYwH
2020
-
[22]
Yu, L., Sun, L., Du, B., Lv, W., 2023. Towards better dynamic graph learning: New architecture and unified library, in: Ad- vances in Neural Information Processing Systems. URL:https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d611019afba70d547bd595e8a4158f55-Abstract-Conference.html. Appendix A. Theoretical Derivations This appendix summarizes ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.