CaresAI at CT-DEB26: Detecting Dosing Errors In Clinical Trials Using Domain-Specific Transformer Embeddings and Classification Models
Pith reviewed 2026-06-30 05:50 UTC · model grok-4.3
The pith
Domain-specific transformer embeddings combined with trial metadata enable machine learning models to identify protocols at elevated dosing error risk with ROC-AUC scores of 0.821 to 0.853.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The integration of domain-specific transformer embeddings with structured metadata enables discrimination of trials meeting a predefined elevated dosing error risk criterion, with ROC-AUCs from 0.821 to 0.853. Under logistic regression, BioBERT embeddings reach 0.794 and outperform ClinicalBERT; gradient boosting, support vector classifiers, logistic regression, and residual neural networks produce the top scores; combining multiple embeddings yields no improvement.
What carries the argument
Domain-specific transformer embeddings (BioBERT, PubMedBERT, ClinicalBERT, MedCPT) of trial text, concatenated with categorical metadata and passed to gradient boosting, support vector, logistic regression, or residual neural network classifiers.
If this is right
- BioBERT embeddings outperform the other tested encoders when used with logistic regression.
- Stacking embeddings from multiple biomedical models does not improve discrimination.
- Gradient boosting, support vector classifiers, logistic regression, and residual neural networks reach the highest ROC-AUC range.
- Domain alignment of the encoder matters more than combining several encoders.
Where Pith is reading between the lines
- The same pipeline could be applied during protocol drafting to flag potential dosing issues before submission.
- If the original risk labels contain systematic bias, the reported AUCs would overstate real-world performance on new trials.
- Extending the approach to other preventable errors, such as eligibility or monitoring mistakes, would test whether the method generalizes beyond dosing.
- Integration into regulatory review software could reduce the volume of protocols requiring full manual safety checks.
Load-bearing premise
The binary labels marking elevated dosing error risk were created and validated independently of the protocol text that the embedding models read.
What would settle it
Apply the trained models to a fresh set of trial protocols whose dosing-error-risk labels have been assigned by independent experts who reviewed the full protocols without using the same text features.
Figures
read the original abstract
Medication errors, particularly dosing errors in clinical trials (CT), can lead to patient harm, adverse drug events and worse patient outcomes. Dosing errors are preventable, and early identification can improve trial integrity and mitigate subsequent clinical and financial burden. This study aims to detect dosing errors within CT protocols by evaluating text representations of trial information using transformer-based language models trained on biomedical corpora. CT textual data was encoded using several models, including ClinicalBERT, PubMedBERT, BioBERT, and MedCPT, and integrated with categorical features. These text embeddings were used as input to classical machine learning models and neural network architectures within an experimental framework. Performance was primarily assessed using ROC-AUC with respect to predicting dosage error. Under a logistic regression baseline, BioBERT consistently outperformed alternative encoders, achieving an ROC-AUC of 0.794, a 3.95% improvement over the ClinicalBERT baseline. Combining multiple embeddings did not yield improvements, indicating that domain alignment outweighs representational stacking. Gradient boosting models, support vector classifiers, logistic regression, and residual neural networks achieved the strongest performance for predicting dosage error, achieving ROC-AUCs: 0.821 to 0.853. Overall, the integration of domain-specific transformer embeddings with structured metadata enables discrimination of trials meeting a predefined elevated dosing error risk criterion, advancing safety monitoring and supporting informed regulatory decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an experimental framework that encodes clinical trial protocol text using domain-specific transformers (ClinicalBERT, PubMedBERT, BioBERT, MedCPT), concatenates the embeddings with structured metadata, and trains classical ML models plus residual networks to predict a binary label indicating elevated dosing-error risk, reporting ROC-AUC values between 0.821 and 0.853.
Significance. If the binary labels prove to be accurate, unbiased, and independent of the textual features, the approach could supply a practical signal for early safety monitoring of dosing regimens in trial protocols. The reported gains from BioBERT over ClinicalBERT and the lack of benefit from embedding concatenation are internally consistent observations that would be of interest to the clinical NLP community.
major comments (2)
- [Abstract / Methods] Abstract and Methods: the binary labels for the target variable ('elevated dosing error risk') are never defined. No description is supplied of the operational criterion, the source of the labels (expert review, rule-based extraction from the same protocols, or external database), blinding procedures, or inter-rater reliability. Because every reported ROC-AUC is computed against these labels, the absence of this information renders the numerical claims uninterpretable and constitutes a load-bearing omission.
- [Abstract] Abstract: no information is given on dataset size, number of positive/negative instances, train-test split strategy, or any form of cross-validation or error bars. Without these quantities the ROC-AUC range 0.821–0.853 cannot be assessed for statistical reliability or generalizability.
minor comments (2)
- [Abstract] The manuscript should state the exact number of trials, the proportion of the positive class, and the precise definition of the logistic-regression baseline against which the 3.95 % improvement is measured.
- Figure or table captions should explicitly list the hyper-parameter search ranges and the final selected values for each model (gradient boosting, SVC, ResNet).
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying important omissions that affect the interpretability of our results. We address each major comment below and will revise the manuscript to supply the requested details.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the binary labels for the target variable ('elevated dosing error risk') are never defined. No description is supplied of the operational criterion, the source of the labels (expert review, rule-based extraction from the same protocols, or external database), blinding procedures, or inter-rater reliability. Because every reported ROC-AUC is computed against these labels, the absence of this information renders the numerical claims uninterpretable and constitutes a load-bearing omission.
Authors: We agree that the absence of a precise definition for the binary labels is a significant omission. The manuscript refers to a 'predefined elevated dosing error risk criterion' but does not elaborate on its construction. In the revised version we will add a dedicated subsection in Methods that specifies the operational criterion, the source of the labels, any blinding or annotation procedures, and inter-rater reliability statistics (or note their absence if the labels were generated by a deterministic rule). This addition will make the reported ROC-AUC values interpretable. revision: yes
-
Referee: [Abstract] Abstract: no information is given on dataset size, number of positive/negative instances, train-test split strategy, or any form of cross-validation or error bars. Without these quantities the ROC-AUC range 0.821–0.853 cannot be assessed for statistical reliability or generalizability.
Authors: We concur that these experimental details are required to evaluate reliability. We will expand both the Abstract and a new Data subsection in Methods to report the total number of protocols, the number of positive and negative instances, the train-test split procedure (including any stratification or cross-validation), and confidence intervals or standard errors for the ROC-AUC figures. These quantities will also be added to the abstract. revision: yes
Circularity Check
No circularity: empirical ML classification on external labels with no derivations or self-referential reductions.
full rationale
The paper presents an applied machine-learning study that encodes CT protocol text with off-the-shelf biomedical transformers (BioBERT, ClinicalBERT, etc.) and feeds the resulting embeddings plus metadata into standard classifiers to predict a binary label. No equations, first-principles derivations, or parameter-fitting steps appear; performance is reported solely as ROC-AUC on held-out data against an externally supplied label. The label itself is described only as reflecting a “predefined elevated dosing error risk criterion,” with no indication that its construction re-uses the same text embeddings or is defined in terms of the model outputs. Consequently none of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) are instantiated. The reported discrimination is therefore an ordinary empirical result rather than a quantity forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Clinical trials provide the structured and rigorously controlledframeworkrequiredtoevaluatethesafety andefficacyofnovelpharmaceuticalcompoundsin human populations. However, this process is both costly and uncertain. Only 14% of compounds entering clinical trials ultimately receive regulatory approval (Wong et al., 2019), despite substantial f...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Brief summary
Methodology 2.1. Dataset and Problem Formulation As part of the CT-DEB’26 challenge (Detecting Dosing Errors from Clinical Trials) (Ferdowsi et al., 2026), a dataset was generated (Hêche et al., 2026), containing structured and unstructured information for a large number of different clinical trials (written in the English language), collected from the Cl...
2026
-
[3]
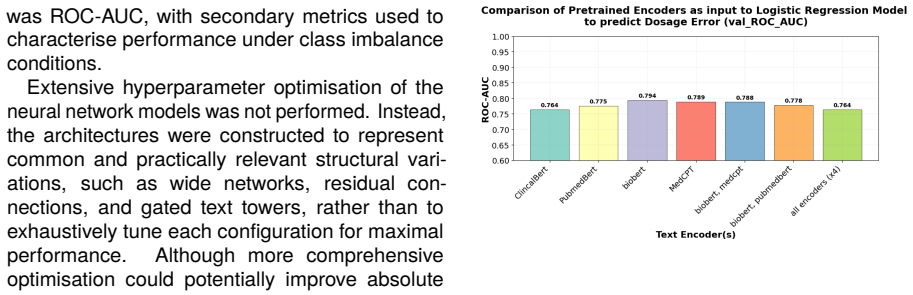
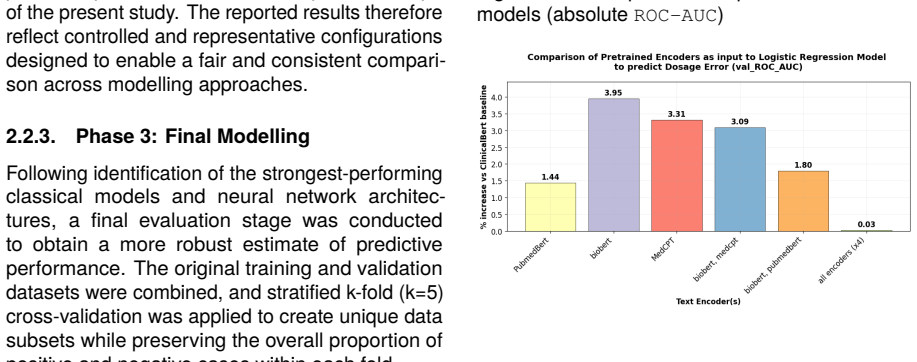
Discussion of Results 3.1. Results for Encoding of Text Columns BioBERT demonstrated the strongest individual encoder performance, achieving a ROC-AUC of 0.794 against the validation set under logistic regression, compared to 0.775 for PubMedBERT, 0.789 for MedCPT, and 0.764 for ClinicalBERT (see Figure 1). This is consistent with the design of BioBERT, w...
2019
-
[4]
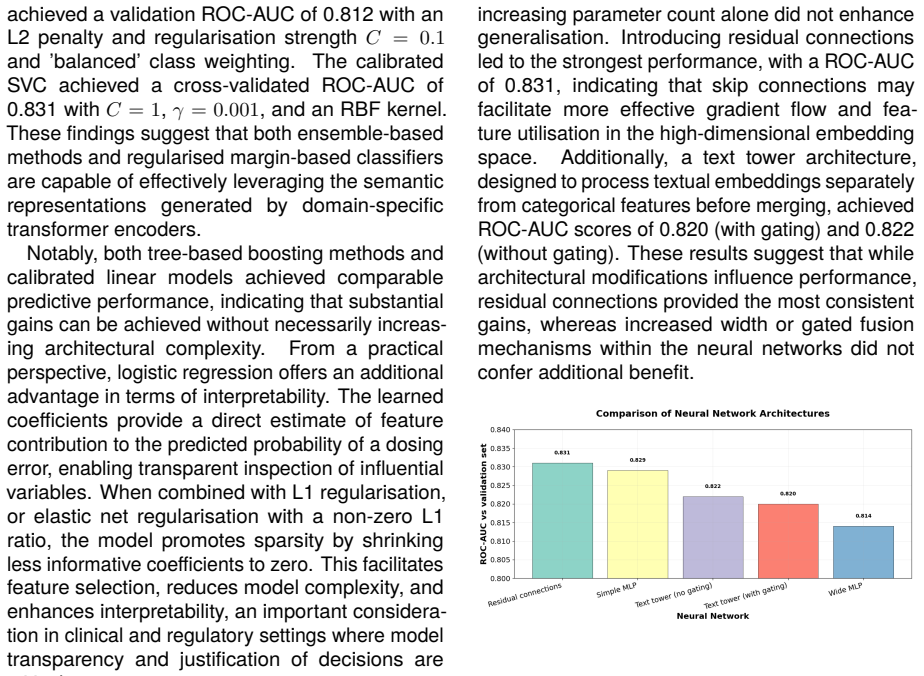
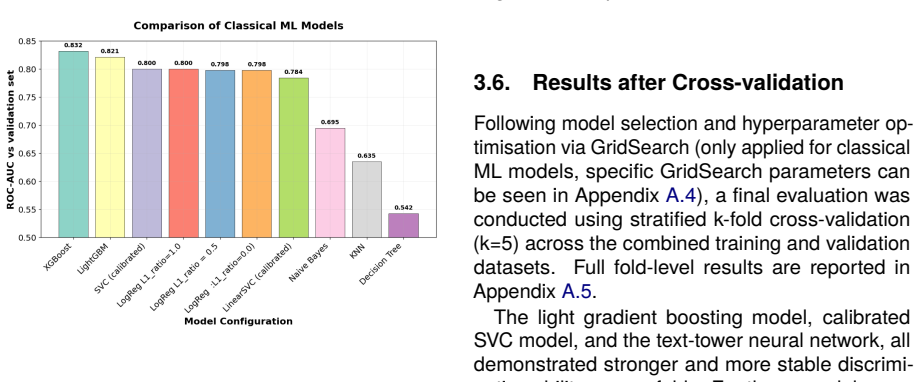
Conclusion This work demonstrates that domain-specific trans- former embeddings, particularly BioBERT, pro- vide highly effective representations for modelling unstructured clinical trial documentation. When integrated with structured trial metadata, these embeddings enable reliable discrimination of trials in which the estimated probability of dosing err...
-
[5]
Encodings from these models may have produced stronger semantic representations of clinical trial protocol text
Limitations Firstly, compute constraints prevented the evalu- ation of language models with larger amounts of parameters, such as BioGPT (Luo et al., 2022) and SciFive (Phan et al., 2021). Encodings from these models may have produced stronger semantic representations of clinical trial protocol text. Secondly, the binary target variable conflates dosing e...
2022
-
[6]
Duetolicensingandgovernancerestric- tions, raw clinical trial and healthcare datasets are not redistributed by the authors
Ethics Statement and Code/Data Availability This study utilised publicly available clinical trial registry data and secondary benchmark healthcare datasets via the Hugging Face online platform and wassubjecttotheoriginaldataproviders’termsand conditions. Duetolicensingandgovernancerestric- tions, raw clinical trial and healthcare datasets are not redistri...
-
[7]
Bibliographical References Emily Alsentzer, John Murphy, William Boag, Wei-Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. 2019. Publicly available clinicalBERTembeddings. InProceedingsofthe 2nd Clinical Natural Language Processing Work- shop, pages 72–78, Minneapolis, Minnesota, USA. Association for Computational Linguistics. Victor W. Berge...
2019
-
[8]
Xiang Chen, Haoran Xie, Gong Cheng, Lai K
Trialbench: Multi-modal ai-ready datasets for clinical trial prediction.Scientific Data, 12(1):1564. Xiang Chen, Haoran Xie, Gong Cheng, Lai K. M. Poon, Min Leng, and Fei L. Wang. 2020. Trends and features of the applications of natural language processing techniques for clinical trials text analysis.Applied Sciences, 10(6):2157. Hyeon Nam Cho, Tae Jin Ju...
2020
-
[9]
Task-specific transformer-based language models in health care: Scoping review.JMIR Medical Informatics, 12:e49724. DanielChopard, MatthiasS.Treder, PaulCorcoran, Nadeem Ahmed, Chris Johnson, Monika Busse, and Irena Spasić. 2021. Text mining of adverse events in clinical trials: Deep learning approach. JMIR Medical Informatics, 9(12):e28632. Emilie Delavo...
-
[10]
Elizabeth McNeer, Cole Beck, Hannah L
How much do clinical trials cost?Nature Reviews Drug Discovery, 16(6):381–382. Elizabeth McNeer, Cole Beck, Hannah L. Weeks, Michael L. Williams, Nathan T. James, and Leena Choi. 2019. A post-processing algorithm for building longitudinal medication dose data from extracted medication information using natural language processing from electronic health re...
2019
-
[11]
Use of open access platforms for clinical trial data.JAMA, 315(12):1283–1284. Sai Nerella, Saptarshi Bandyopadhyay, Jiayu Zhang, Miguel Contreras, Samantha Siegel, AhmetBumin, BrunoSilva, JoseSena, Benjamin Shickel, Azra Bihorac, Kamran Khezeli, and Parisa Rashidi. 2024. Transformers and large language models in healthcare: A review. Artificial Intelligen...
2024
-
[12]
relu"), layers.Dropout(0.3), layers.Dense(64, activation=
Estimation of clinical trial success rates and related parameters.Biostatistics, 20(2):273– 286. Y. Zhu, L. Li, H. Lu, A. Zhou, and X. Qin. 2020. Extracting drug-drug interactions from texts with BioBERT and multiple entity-aware attentions. Journal of Biomedical Informatics, 106:103451. A. Appendices A.1. Full dataset column description Feature Feature m...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.