Preference-Based Reward Learning under Partial Observability with Inexact Dynamics
Pith reviewed 2026-06-30 05:16 UTC · model grok-4.3
The pith
Belief filter stability under mixing conditions bounds mismatch for preference reward learning in POMDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For finite log-linear POMDPs, stability of the belief filter to parametric model error under mixing conditions yields bounds on belief mismatch in expectation and with high probability. The mechanism extends to neural-softmax POMDP models with overparameterized networks. Propagating the resulting trajectory-level feature perturbations produces finite-sample guarantees for constrained Bradley-Terry reward estimation from preferences, decoupling statistical error from irreducible model-mismatch bias.
What carries the argument
Stability of the belief filter to parametric model error under mixing conditions in log-linear POMDPs
If this is right
- Belief mismatch is bounded in expectation and with high probability under the stated mixing conditions.
- The same stability argument extends directly to neural-softmax POMDP models with overparameterized networks.
- Trajectory feature perturbations admit finite-sample guarantees for constrained Bradley-Terry reward estimation.
- Statistical estimation error separates cleanly from the irreducible bias due to model mismatch.
Where Pith is reading between the lines
- If mixing conditions can be verified or enforced in applications such as robotics, approximate dynamics models may still permit reliable preference-based reward learning.
- The decoupling of bias and variance suggests that collecting more preferences cannot eliminate the model-mismatch term, so model refinement remains necessary.
- Similar stability arguments might apply to other latent-state inference methods beyond the log-linear and neural-softmax cases examined here.
Load-bearing premise
The POMDP satisfies mixing conditions that keep the belief filter stable to parametric model error.
What would settle it
An empirical measurement showing that belief mismatch grows without bound in a controlled log-linear POMDP whose mixing conditions are violated would falsify the stability claim.
Figures
read the original abstract
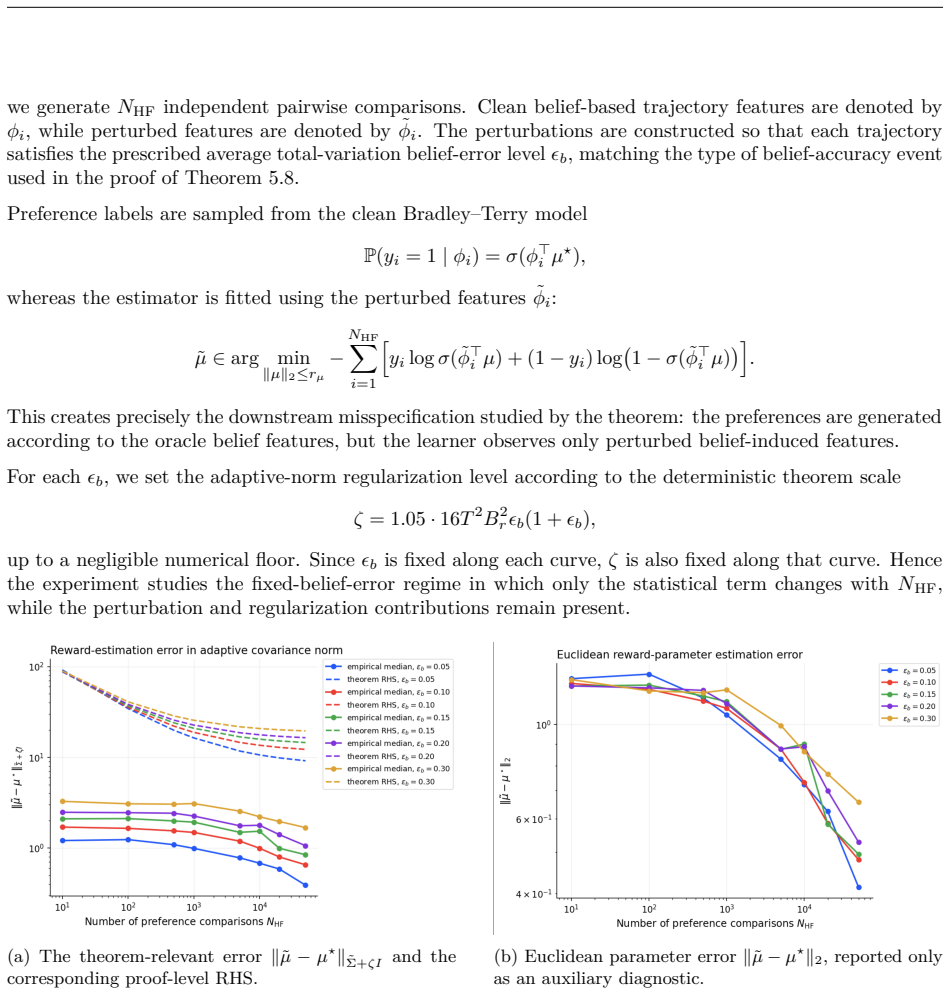
In this paper, we study how partial observability and inexact latent-state inference affect reward learning from preferences. To that end, we study preference-based reward learning under partial observability, where the learner forms latent-state estimates using an inexact learned POMDP model, so model error can accumulate over time. For finite log-linear POMDPs, we characterize this error term by establishing the stability of the belief filter to parametric model error under certain mixing conditions, yielding bounds on the belief mismatch in expectation and in high probability. We further extend this stability mechanism beyond the log-linear setting to neural-softmax POMDP models with overparameterized neural networks. We then propagate these errors into trajectory-level feature perturbations and derive finite-sample guarantees for constrained Bradley--Terry reward estimation from preferences. Our results decouple statistical error from an irreducible model-mismatch bias, and clarify when preference-based reward learning remains feasible under partial observability with imperfect dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies preference-based reward learning from preferences in POMDPs with partial observability and inexact learned dynamics models. For finite log-linear POMDPs it claims to establish stability of the belief filter to parametric model error under mixing conditions, yielding expectation and high-probability bounds on belief mismatch; it extends the mechanism to overparameterized neural-softmax POMDPs, propagates the resulting trajectory-feature perturbations, and derives finite-sample guarantees for constrained Bradley-Terry reward estimation that separate statistical error from an irreducible model-mismatch bias.
Significance. If the stability results hold under well-characterized mixing conditions that apply to the POMDPs arising in preference-based settings, the work would clarify when reward learning remains feasible despite model error accumulation, with the explicit decoupling of statistical and bias terms constituting a useful theoretical contribution.
major comments (2)
- [Abstract] Abstract (and the central stability claim): the load-bearing step is the assertion that the belief filter remains stable to parametric model error 'under certain mixing conditions.' The precise form of these conditions (contraction rates, requirements on the transition kernel or observation model, etc.) is not stated, preventing verification of whether they hold for the log-linear POMDPs relevant to preference learning or whether they exclude the very regimes where partial observability is consequential. The same unverified step is inherited by the neural-softmax extension.
- [Abstract] The finite-sample guarantees for constrained Bradley-Terry estimation are stated to follow from propagating the belief-mismatch bounds; without an explicit statement of the mixing conditions and the resulting contraction constants, it is impossible to determine the dependence of the final sample-complexity bounds on the model error or to assess whether the 'irreducible bias' term is indeed decoupled in a useful way.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on the abstract's clarity regarding mixing conditions. We agree that greater precision is needed there to allow verification and will revise accordingly. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the central stability claim): the load-bearing step is the assertion that the belief filter remains stable to parametric model error 'under certain mixing conditions.' The precise form of these conditions (contraction rates, requirements on the transition kernel or observation model, etc.) is not stated, preventing verification of whether they hold for the log-linear POMDPs relevant to preference learning or whether they exclude the very regimes where partial observability is consequential. The same unverified step is inherited by the neural-softmax extension.
Authors: We agree the abstract is high-level. The precise mixing conditions appear in the main text: Definition 3.1 and Assumption 3.2 specify a uniform contraction rate γ<1 on the belief operator, positive reachability probability in the transition kernel, and informativeness of the observation model (minimum observation probability bounded away from zero). These are verified to hold for the ergodic log-linear POMDPs arising in preference learning (see Example 3.3). The neural-softmax case inherits the same structure via the overparameterized network approximation (Section 4). We will revise the abstract to state these conditions concisely. revision: yes
-
Referee: [Abstract] The finite-sample guarantees for constrained Bradley-Terry estimation are stated to follow from propagating the belief-mismatch bounds; without an explicit statement of the mixing conditions and the resulting contraction constants, it is impossible to determine the dependence of the final sample-complexity bounds on the model error or to assess whether the 'irreducible bias' term is indeed decoupled in a useful way.
Authors: The dependence is explicit in the main results. Theorem 5.3 gives sample complexity scaling as O((1/ε^{2})(1/(1-γ)^{2}) log(1/δ)) for the statistical term, where γ is the contraction constant from the mixing conditions, plus an additive bias term depending only on model mismatch δ_model (independent of sample size n). This decoupling is stated in Corollary 5.4. We will revise the abstract to indicate this dependence on γ and the separation of terms. revision: yes
Circularity Check
No circularity: forward derivation from mixing assumptions to stability bounds
full rationale
The paper assumes 'certain mixing conditions' on the POMDP to establish stability of the belief filter to parametric model error, then derives bounds on belief mismatch (in expectation and high probability) that are propagated to trajectory features and reward estimation. This is a standard one-directional derivation from stated assumptions to new bounds; the mixing conditions are not derived from or defined in terms of the target result. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided claims or abstract. The result remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The POMDP satisfies certain mixing conditions
Reference graph
Works this paper leans on
-
[1]
URLhttps://proceedings. neurips.cc/paper_files/paper/2011/file/e1d5be1c7f2f456670de3d53c7b54f4a-Paper.pdf. Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[2]
doi: https:// doi.org/10.1016/j.neunet.2025.108386
ISSN 0893-6080. doi: https:// doi.org/10.1016/j.neunet.2025.108386. URLhttps://www.sciencedirect.com/science/article/pii/ S0893608025012675. K. J. Åström. Optimal control of markov processes with incomplete state information.Journal of Mathematical Analysis and Applications, 10(1):174–205,
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
ISSN 0022-247X. doi: https://doi. org/10.1016/0022-247X(65)90154-X. URLhttps://www.sciencedirect.com/science/article/pii/ 0022247X6590154X. Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/0022-247x(65)90154-x
-
[4]
URLhttps://doi.org/10.1214/16-AOS1435
doi: 10.1214/ 16-AOS1435. URLhttps://doi.org/10.1214/16-AOS1435. Peter L. Bartlett, Philip M. Long, Gábor Lugosi, and Alexander Tsigler. Benign overfitting in lin- ear regression.Proceedings of the National Academy of Sciences, 117:30063 – 30070,
-
[5]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei
URLhttps://proceedings.neurips.cc/paper_files/paper/2019/file/ ae614c557843b1df326cb29c57225459-Paper.pdf. Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforce- ment learning from human preferences. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fer- gus, S. Vishwanathan, and R. Garnett (eds.),Advanc...
2019
-
[6]
SimonDu, AkshayKrishnamurthy, NanJiang, AlekhAgarwal, MiroslavDudik, andJohnLangford
URLhttps://proceedings.neurips.cc/paper_files/paper/ 2017/file/d5e2c0adad503c91f91df240d0cd4e49-Paper.pdf. SimonDu, AkshayKrishnamurthy, NanJiang, AlekhAgarwal, MiroslavDudik, andJohnLangford. Provably efficient rl with rich observations via latent state decoding. InInternational Conference on Machine Learning, pp. 1665–1674. PMLR,
2017
-
[7]
URLhttp://www.jstor.org/stable/2959268
ISSN 00911798, 2168894X. URLhttp://www.jstor.org/stable/2959268. Jiacheng Guo, Zihao Li, Huazheng Wang, Mengdi Wang, Zhuoran Yang, and Xuezhou Zhang. Provably efficient representation learning with tractable planning in low-rank pomdp. InInternational Conference on Machine Learning, pp. 11967–11997. PMLR,
-
[8]
AI Alignment: A Comprehensive Survey
URLhttps://proceedings.neurips.cc/paper_files/paper/2018/file/ 5a4be1fa34e62bb8a6ec6b91d2462f5a-Paper.pdf. Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, JiayiZhou, ZhaoweiZhang, etal. Aialignment: Acomprehensivesurvey.arXiv preprint arXiv:2310.19852,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
doi: https://doi.org/10.1016/S0004-3702(98)00023-X
ISSN 0004-3702. doi: https: //doi.org/10.1016/S0004-3702(98)00023-X. URLhttps://www.sciencedirect.com/science/article/ pii/S000437029800023X. Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke Hüllermeier. A survey of reinforcement learning from human feedback.Transactions on Machine Learning Research,
-
[10]
URLhttps: //openreview.net/forum?id=f7OkIurx4b
ISSN 2835-8856. URLhttps: //openreview.net/forum?id=f7OkIurx4b. Survey Certification. Chinmaya Kausik, Mirco Mutti, Aldo Pacchiano, and Ambuj Tewari. A theoretical framework for partially observed reward-states in rlhf.arXiv preprint arXiv:2402.03282,
-
[11]
neurips.cc/paper_files/paper/2016/file/2387337ba1e0b0249ba90f55b2ba2521-Paper.pdf
URLhttps://proceedings. neurips.cc/paper_files/paper/2016/file/2387337ba1e0b0249ba90f55b2ba2521-Paper.pdf. Yuanzhi Li and Yingyu Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett (eds.),Advances in Neural Information Pr...
-
[12]
Qinghua Liu, Csaba Szepesvári, and Chi Jin
URLhttps://proceedings.neurips.cc/paper_files/paper/2018/file/ 54fe976ba170c19ebae453679b362263-Paper.pdf. Qinghua Liu, Csaba Szepesvári, and Chi Jin. Sample-efficient reinforcement learning of partially observable markov games.Advances in Neural Information Processing Systems, 35:18296–18308,
2018
-
[13]
Ellen Novoseller, Yibing Wei, Yanan Sui, Yisong Yue, and Joel Burdick
doi: 10.1214/20-ECP333. Ellen Novoseller, Yibing Wei, Yanan Sui, Yisong Yue, and Joel Burdick. Dueling posterior sampling for preference-based reinforcement learning. In Jonas Peters and David Sontag (eds.),Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), volume 124 ofProceedings of Machine Learning Research, pp. 1029–10...
-
[14]
Aldo Pacchiano, Aadirupa Saha, and Jonathan Lee
URLhttps://api.semanticscholar.org/CorpusID:61153563. Aldo Pacchiano, Aadirupa Saha, and Jonathan Lee. Dueling rl: reinforcement learning with trajectory preferences.arXiv preprint arXiv:2111.04850,
-
[15]
URLhttps://doi.org/10.1109/CDC42340. 2020.9304386. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
-
[16]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
ISSN 1935-8237. doi: 10.1561/2200000001. URLhttp://dx.doi.org/10.1561/2200000001. Shaojun Wang and Yunxin Zhao. Almost sure convergence of titterington’s recursive estimator for mixture models.Statistics and Probability Letters, 76(18):2001–2006,
-
[18]
doi: https://doi.org/10.1016/j.spl.2006.05.017
ISSN 0167-7152. doi: https://doi.org/10.1016/j.spl.2006.05.017. URLhttps://www.sciencedirect.com/science/article/ pii/S0167715206001842. Christian Wirth, Riad Akrour, Gerhard Neumann, and Johannes Fürnkranz. A survey of preference-based reinforcement learning methods.Journal of Machine Learning Research, 18(136):1–46,
-
[19]
Fine-Tuning Language Models from Human Preferences
URLhttps://proceedings.mlr.press/v202/zhu23f.html. Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Chris- tiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
Plus, similar to the argument in Lemma A.2 that we have uniformly boundedPθ(s′|s,a)in Eq
21 B Proof of Theorem 4.1 RemarkB.1.First, recall 1 where we assumed1>ν max≥ν0(s)≥νmin >0. Plus, similar to the argument in Lemma A.2 that we have uniformly boundedPθ(s′|s,a)in Eq. 34 and 35, and given the similar log-linear structure of modelsPθandΦ w assumed in 3.1 and bounded feature maps in 3.1, we can establish uniform bounds overΦ w andP θ. Denote P...
2024
-
[21]
Using the Dobrushin coefficient ofQw⋆and then ofP ak θ⋆ gives Qw⋆ ( Pak θ⋆bΘ⋆ k ) −Qw⋆ ( Pak θ⋆bΘ k ) TV ≤(1−κΦ ) Pak θ⋆bΘ⋆ k −Pak θ⋆bΘ k TV ≤(1−κΦ )(1−κP )∥bΘ⋆ k −bΘ k∥TV.(56) Combining Eq. 55–Eq. 56 yields E [ (II)|Fk ] ≤B 2 (2−κΦ )δ(θ) + (1−κΦ )(1−κP )∥bΘ⋆ k −bΘ k∥TV.(57) RemarkB.2 (Dominance condition).We note that the dominance conditionP ...
2024
-
[22]
Unrolling Eq
Putting all together, and unrolling over time yields E [ ∥bΘ k+1−bΘ⋆ k+1∥TV ] =E [ E [ ∥bΘ k+1−bΘ⋆ k+1∥TV ⏐⏐⏐Fk ]] ≤E [ E [ (I)|Fk ] +E [ (II)|Fk ] +E [ (III)|Fk ]] ≤ ( (1−κP )(2−κΦ ) + 2(1−κP )(1−κΦ ) ) E [ ∥bΘ k−bΘ⋆ k ∥TV ] +Bδ(w) +B 2 ( (2−κΦ ) + (1−κΦ ) ) δ(θ) =αE [ ∥bΘ k−bΘ⋆ k ∥TV ] +Bδ(w) +B 2 (3−2κΦ )δ(θ),(59) withα= (1−κP )(4−3κΦ ). Unrolling Eq. ...
2018
-
[23]
The belief recursions are bW k+1 =ψΦWΦ ( Pak WpbW k ,ˆsk+1 ) , b W⋆ k+1 =ψΦW⋆ Φ ( Pak W⋆p bW⋆ k ,ˆsk+1 ) , b W 0 =b W⋆ 0 =ν0
D Proof of Corollary 4.5 Proof.Fora∈A, write (Pa Wpq)(s′) := ∑ s∈S PWp(s′|s,a)q(s),(Q WΦq)(ˆs) := ∑ s′∈S ΦWΦ (ˆs|s′)q(s′). The belief recursions are bW k+1 =ψΦWΦ ( Pak WpbW k ,ˆsk+1 ) , b W⋆ k+1 =ψΦW⋆ Φ ( Pak W⋆p bW⋆ k ,ˆsk+1 ) , b W 0 =b W⋆ 0 =ν0. We work underPW⋆(·|a0:t−1), with the same filtrationsF− k andF k as in the proof of Theorem 4.1. Thus ˆsk+1|...
2024
-
[24]
32 RemarkD.1 (Finite-width neural-network approximation).The quantitiesε NN p (m,δNN)andεNN Φ (m,δNN) measure the finite-width error incurred by replacing the nonlinear ReLU scores with their first-order NTK linearizations around initialization. In the NTK regime, sufficiently over-parameterized networks remain close to initialization and their outputs ar...
2018
-
[25]
Givenζ >0define the clean empirical covariance Σ := 1 NHF ∑NHF i=1 ϕiϕ⊤ i and regularized empirical covariance byΣ +ζI. Then, for anyδc ∈(0,1)with probability at least1−δc it holds ∇L(µ⋆) (Σ+ζI)−1≤ 1√NHF √ dlog ( 1 + 4T 2B2r ζd ) + 2 log (1 δc ) .(104) Proof of lemma E.1.Define the shorthandξi :=σ(ϕ⊤ i µ⋆)−yi∈[−1,1],S:=∑NHF i=1 ξiϕi, andV:=N HFζI+∑NH...
2011
-
[26]
we define per-sample gradients at µ⋆asg ⋆ i := ( σ(ϕ⊤ i µ⋆)−yi ) ϕi and˜g⋆ i := ( σ(˜ϕ⊤ i µ⋆)−yi )˜ϕi, with respect to exact and perturbed features. Hence,∇˜L(µ⋆) = 1 NHF ∑ i ˜gi(µ⋆), and we can write ∇˜L(µ⋆) =∇L(µ⋆) + 1 NHF NHF∑ i=1 ( ˜g⋆ i−g⋆ i ) .(119) 37 Consider the following decomposition ˜g⋆ i−g⋆ i = ( σ(ϕ⊤ i µ⋆+ ∆⊤ ϕ,iµ⋆)−σ(ϕ⊤ i µ⋆) ) ϕi (I...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.