SA-Homo: Scale Adaptive Homography Estimation for Scale Variation Scenarios
Pith reviewed 2026-06-30 06:03 UTC · model grok-4.3
The pith
SA-Homo uses a global-to-local module sequence to estimate homography accurately when image scales differ by up to eight times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
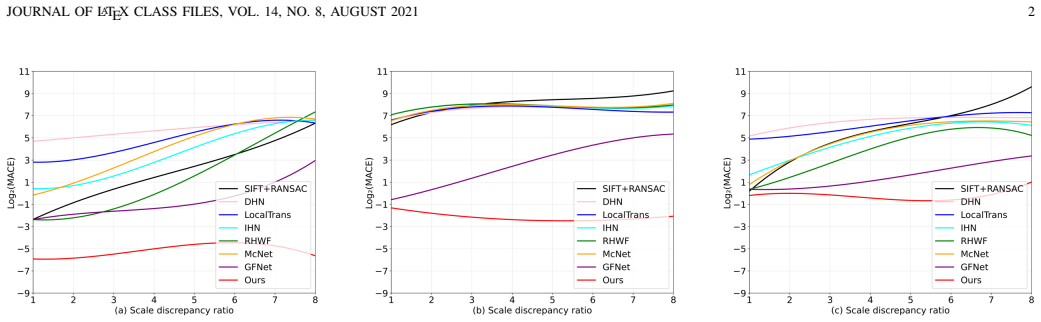
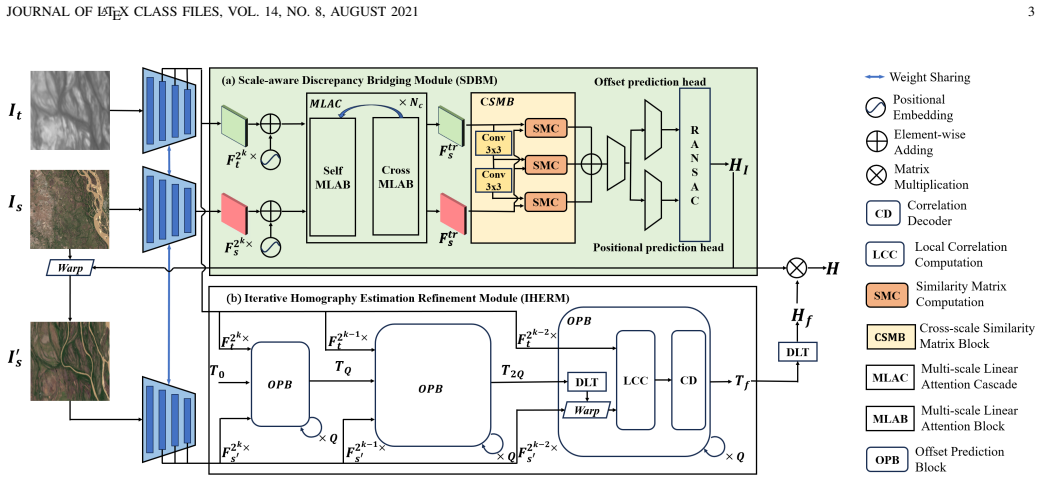
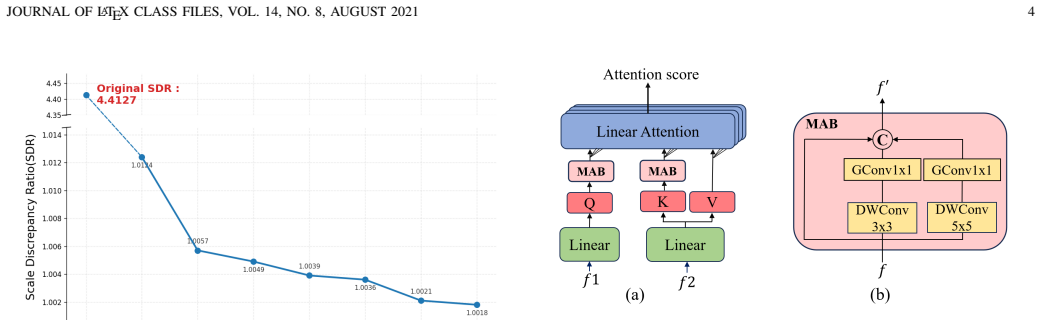
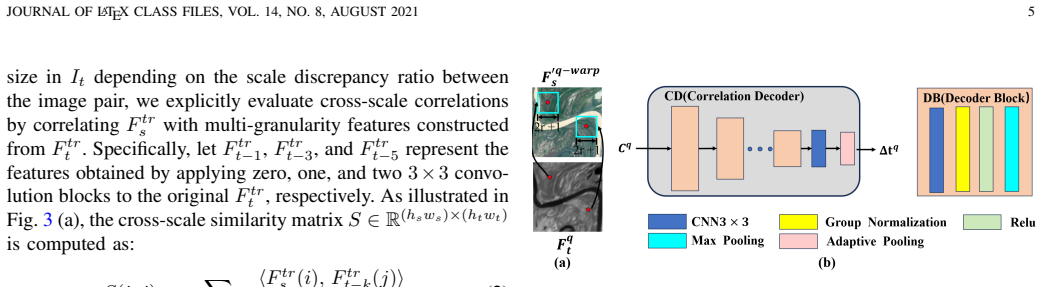
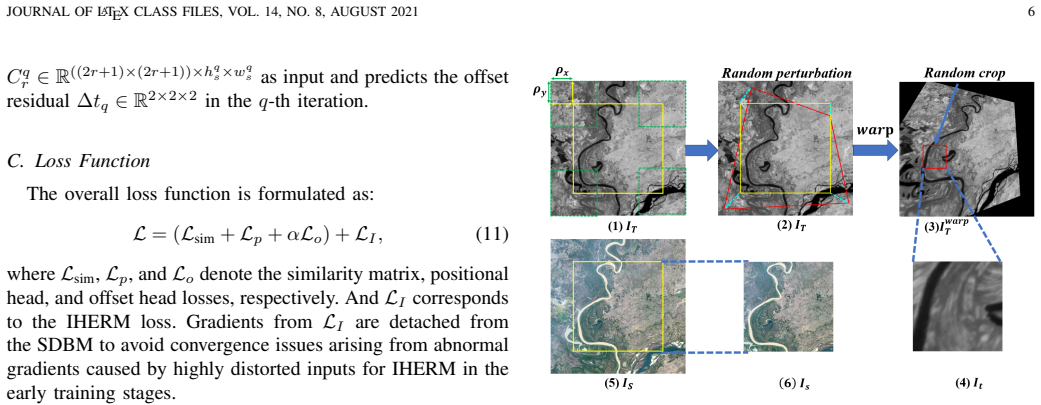
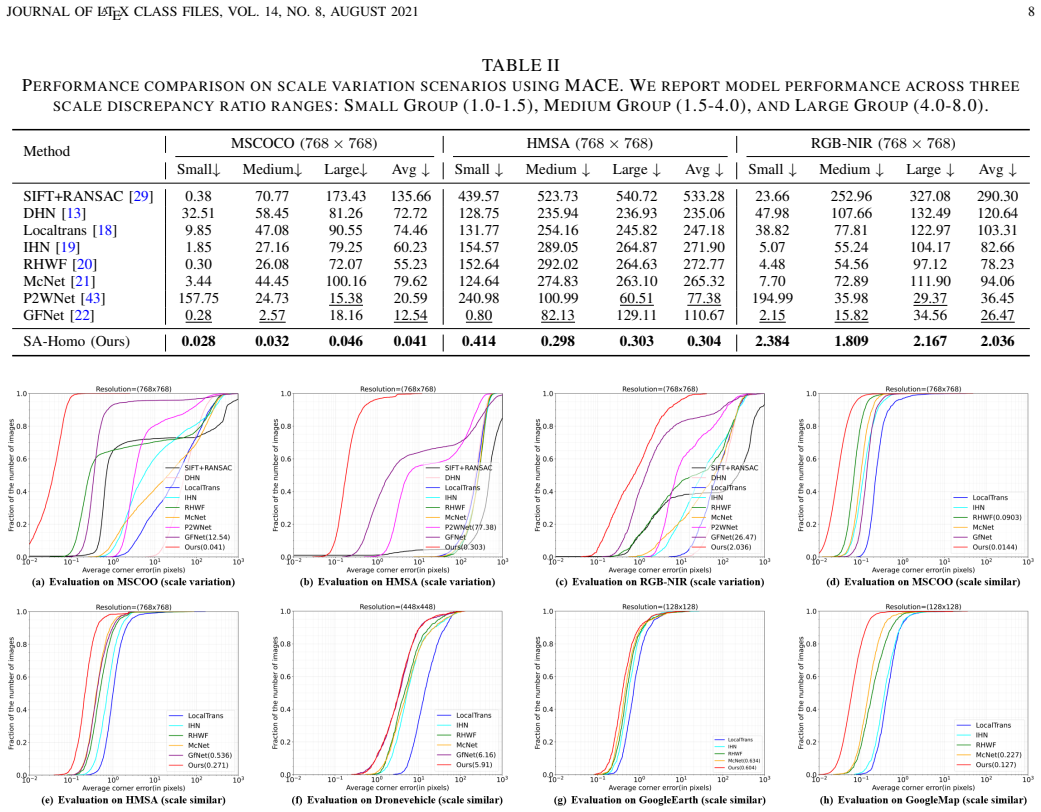
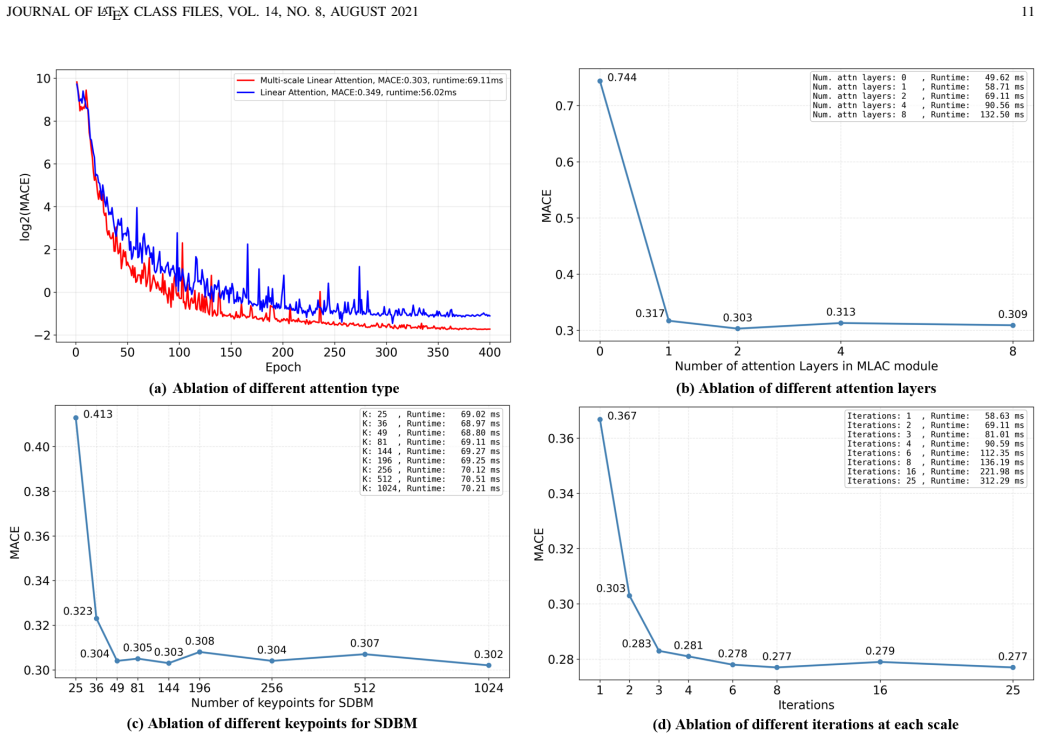
SA-Homo maintains high precision even under 8× scale discrepancies by adopting a hierarchical scale alignment strategy that transitions from the global perspective with a heavy module to a local perspective with a light module. The Scale-aware Discrepancy Bridging Module uses Multi-scale Linear Attention Cascade to capture long-range dependencies and a Cross-scale Similarity Matrix Block for robust correlation, after which the Iterative Homography Estimation Refinement Module progressively refines the result using local correlations.
What carries the argument
The hierarchical scale alignment strategy that starts with the Scale-aware Discrepancy Bridging Module (SDBM) containing Multi-scale Linear Attention Cascade (MLAC) and Cross-scale Similarity Matrix Block (CSMB) to reduce global scale gaps before applying the lightweight Iterative Homography Estimation Refinement Module (IHERM).
If this is right
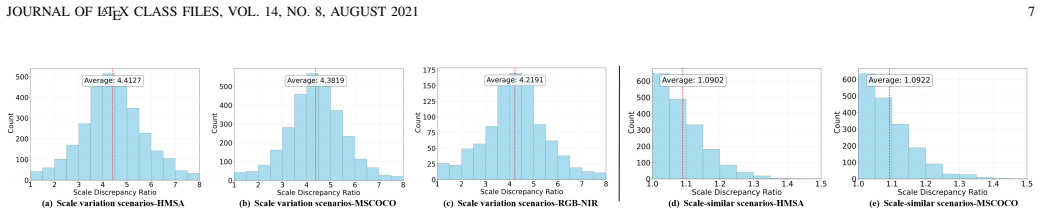
- Homography estimation remains accurate in satellite and multi-modal image pairs that differ by factors up to 8 in scale.
- The same framework improves results on conventional scale-similar pairs as well as the new challenging cases.
- The released HMSA dataset supplies a benchmark for developing and comparing future scale-robust methods.
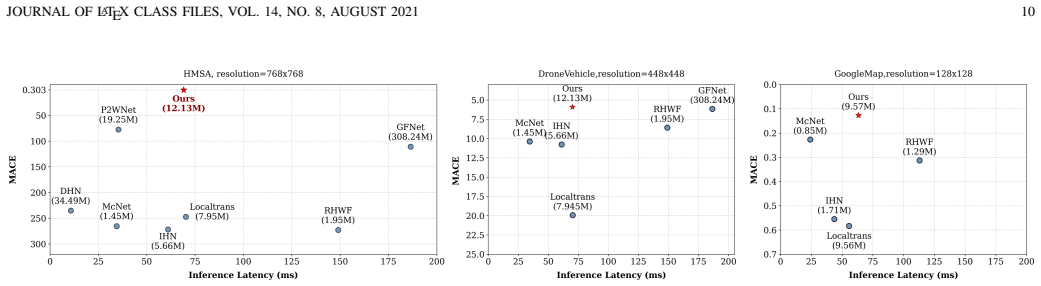
- The two-stage design allows heavy computation only at the start and keeps later refinement efficient.
Where Pith is reading between the lines
- The same global-to-local bridging pattern may transfer to other geometric tasks such as essential-matrix estimation when focal lengths or distances vary.
- Image-registration pipelines could drop explicit scale-normalization steps if the bridging module generalizes beyond the tested satellite domain.
- Real-time video applications with changing camera distances could be tested to measure whether the refinement stage stays fast enough for live use.
Load-bearing premise
The initial global bridging step reduces the scale gap enough for the later lightweight local module to finish the alignment without itself handling the full discrepancy.
What would settle it
On the HMSA dataset, a direct comparison showing that SA-Homo's homography error under 8× scale difference is not lower than current state-of-the-art methods would falsify the performance claim.
Figures



read the original abstract
Homography estimation, as one of the fundamental problems in computer vision, remains challenged by scale variation scenarios where image pairs potentially exhibit significant scale discrepancies. Existing deep learning frameworks frequently suffer from a significant performance degradation in such cases, as they rely on limited displacement assumptions and local feature consistency that might not hold under large scale gaps. In this paper, we propose SA-Homo, a novel scale-adaptive homography estimation framework designed to achieve robust alignment across a wide range of scale discrepancy ratios. We adopt a hierarchical scale alignment strategy that transitions from the global perspective with a heavy module to a local perspective with a light module. Specifically, we introduce the Scale-aware Discrepancy Bridging Module (SDBM) for initial alignment, which utilizes a Multi-scale Linear Attention Cascade (MLAC) to capture long-range dependencies and mitigate feature inconsistencies, along with a global Cross-scale Similarity Matrix Block (CSMB) for scale robust correlation representation. Once the initial scale gap is bridged, a lightweight Iterative Homography Estimation Refinement Module (IHERM) progressively polishes the result using local correlations. To facilitate this research, we contribute the HMSA dataset, a high-resolution, multi-modal satellite benchmark specifically tailored for scale-variant challenges. Extensive experiments demonstrate that SA-Homo maintains high precision even under 8$\times$ scale discrepancies, outperforming state-of-the-art methods in both conventional scale-similar scenarios and challenging scale variation scenarios. Code and collected datasets are available at https://github.com/shangxuanx330/SA_Homo
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SA-Homo, a scale-adaptive homography estimation framework that uses a hierarchical scale alignment strategy. It features the Scale-aware Discrepancy Bridging Module (SDBM) utilizing Multi-scale Linear Attention Cascade (MLAC) to capture long-range dependencies and Cross-scale Similarity Matrix Block (CSMB) for scale robust correlation, followed by the lightweight Iterative Homography Estimation Refinement Module (IHERM) for progressive refinement. The work also presents the HMSA dataset for scale-variant challenges and demonstrates through experiments that SA-Homo outperforms state-of-the-art methods in both conventional and challenging scale variation scenarios, maintaining high precision under 8× scale discrepancies.
Significance. If validated, the results would represent a meaningful advance in handling scale variations in homography estimation, which is critical for multi-modal and satellite imaging applications. The contribution of the HMSA dataset and the open-sourcing of code are notable strengths that facilitate reproducibility and future work in the area.
minor comments (3)
- [Abstract] The description of the modules is high-level; consider adding a brief mention of key performance metrics or number of baselines in the abstract to strengthen the claim.
- [Method] Ensure that the transition from global to local perspective is clearly motivated with references to prior work on hierarchical methods if applicable.
- [Experiments] Verify that all figures and tables have clear captions and that error bars or statistical significance are reported where appropriate.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work, recognition of its significance for multi-modal and satellite imaging applications, and recommendation for minor revision. We appreciate the acknowledgment of the HMSA dataset and code release as strengths for reproducibility.
Circularity Check
No significant circularity detected
full rationale
The paper proposes a new neural architecture (SA-Homo) with modules SDBM (MLAC + CSMB) and IHERM, plus a contributed dataset HMSA, and validates performance claims empirically on scale-variation benchmarks. No mathematical derivation chain, fitted-parameter predictions, or self-referential equations appear; the central claim rests on experimental results rather than reducing to inputs by construction. No load-bearing self-citations or ansatz smuggling are present in the text.
Axiom & Free-Parameter Ledger
free parameters (1)
- Network hyperparameters and training settings for MLAC, CSMB, and IHERM
axioms (1)
- domain assumption Multi-scale linear attention can capture long-range dependencies to mitigate feature inconsistencies under large scale gaps
invented entities (2)
-
Scale-aware Discrepancy Bridging Module (SDBM)
no independent evidence
-
Iterative Homography Estimation Refinement Module (IHERM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fast georeferenced aerial image stitching with absolute rotation averaging and planar- restricted pose graph,
Y . Zhao, G. Liu, S. Xu, S. Bu, H. Jiang, and G. Wan, “Fast georeferenced aerial image stitching with absolute rotation averaging and planar- restricted pose graph,”IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 4, pp. 3502–3517, 2020
2020
-
[2]
Seam-adaptive structure-preserving image stitching for drone images,
J. Li and Y . Zhou, “Seam-adaptive structure-preserving image stitching for drone images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–12, 2024
2024
-
[3]
Megastitch: Robust large-scale image stitching,
A. Zarei, E. Gonzalez, N. Merchant, D. Pauli, E. Lyons, and K. Barnard, “Megastitch: Robust large-scale image stitching,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–9, 2022
2022
-
[4]
Multimodal image fusion framework for end-to-end remote sensing image registration,
L. Li, L. Han, M. Ding, and H. Cao, “Multimodal image fusion framework for end-to-end remote sensing image registration,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023
2023
-
[5]
Uncertainty guided deep lucas-kanade homography for multimodal im- age alignment,
Z. Zhou, J. Luo, Q. Zhu, Y . Wang, H. Zhong, M. Feng, and L. Chen, “Uncertainty guided deep lucas-kanade homography for multimodal im- age alignment,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–14, 2024
2024
-
[6]
Rcvs: A unified registration and fusion framework for video streams,
H. Xie, M. Sang, Y . Zhang, Y . Yang, S. Zhao, and J. Zhong, “Rcvs: A unified registration and fusion framework for video streams,”IEEE Transactions on Multimedia, vol. 26, pp. 11 031–11 043, 2024
2024
-
[7]
An integrated inter-frame stabilization and fast imaging method for video synthetic aperture radar,
S. Wang, G. Wang, Y . Wang, R. Zhou, M. Zhao, and Y . Wang, “An integrated inter-frame stabilization and fast imaging method for video synthetic aperture radar,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[8]
Cinematic- l1 video stabilization with a log-homography model,
A. Bradley, J. Klivington, J. Triscari, and R. van der Merwe, “Cinematic- l1 video stabilization with a log-homography model,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1041–1049
2021
-
[9]
Dut: Learning video stabilization by simply watching unstable videos,
Y . Xu, J. Zhang, S. J. Maybank, and D. Tao, “Dut: Learning video stabilization by simply watching unstable videos,”IEEE Transactions on Image Processing, vol. 31, pp. 4306–4320, 2022
2022
-
[10]
Homography decomposition networks for planar object tracking,
X. Zhan, Y . Liu, J. Zhu, and Y . Li, “Homography decomposition networks for planar object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 3, 2022, pp. 3234– 3242
2022
-
[11]
Smalltrack: Wavelet pooling and graph enhanced classification for uav small object tracking,
Y . Xue, G. Jin, T. Shen, L. Tan, N. Wang, J. Gao, and L. Wang, “Smalltrack: Wavelet pooling and graph enhanced classification for uav small object tracking,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023
2023
-
[12]
Aerial image registration for track- ing,
M. E. Linger and A. A. Goshtasby, “Aerial image registration for track- ing,”IEEE Transactions on Geoscience and Remote Sensing, vol. 53, no. 4, pp. 2137–2145, 2014
2014
-
[13]
Deep Image Homography Estimation
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Deep image homogra- phy estimation,”arXiv preprint arXiv:1606.03798, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Homography estimation from image pairs with hierarchical convolutional networks,
F. Erlik Nowruzi, R. Laganiere, and N. Japkowicz, “Homography estimation from image pairs with hierarchical convolutional networks,” inProceedings of the IEEE international conference on computer vision workshops, 2017, pp. 913–920
2017
-
[15]
Stn-homography: Direct estimation of homography parameters for image pairs,
Q. Zhou and X. Li, “Stn-homography: Direct estimation of homography parameters for image pairs,”Applied Sciences, vol. 9, no. 23, p. 5187, 2019
2019
-
[16]
Clkn: Cascaded lucas- kanade networks for image alignment,
C.-H. Chang, C.-N. Chou, and E. Y . Chang, “Clkn: Cascaded lucas- kanade networks for image alignment,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2213– 2221
2017
-
[17]
Deep lucas-kanade homography for multimodal image alignment,
Y . Zhao, X. Huang, and Z. Zhang, “Deep lucas-kanade homography for multimodal image alignment,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 950–15 959
2021
-
[18]
Image stitching via deep homography estimation,
Q. Zhao, Y . Ma, C. Zhu, C. Yao, B. Feng, and F. Dai, “Image stitching via deep homography estimation,”Neurocomputing, vol. 450, pp. 219– 229, 2021
2021
-
[19]
Iterative deep homography estimation,
S.-Y . Cao, J. Hu, Z. Sheng, and H.-L. Shen, “Iterative deep homography estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1879–1888
2022
-
[20]
Recurrent homography estimation using homography-guided image warping and focus transformer,
S.-Y . Cao, R. Zhang, L. Luo, B. Yu, Z. Sheng, J. Li, and H.-L. Shen, “Recurrent homography estimation using homography-guided image warping and focus transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9833–9842
2023
-
[21]
Mcnet: Rethinking the core ingredients for accurate and efficient homography estimation,
H. Zhu, S.-Y . Cao, J. Hu, S. Zuo, B. Yu, J. Ying, J. Li, and H.-L. Shen, “Mcnet: Rethinking the core ingredients for accurate and efficient homography estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 932–25 941
2024
-
[22]
Adapting dense matching for homography estimation with grid-based acceleration,
K. Zhang, Y . Deng, J. Ma, and P. Favaro, “Adapting dense matching for homography estimation with grid-based acceleration,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6294–6303
2025
-
[23]
Deep homography estimation for dynamic scenes,
H. Le, F. Liu, S. Zhang, and A. Agarwala, “Deep homography estimation for dynamic scenes,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7652–7661
2020
-
[24]
Localtrans: A multiscale local transformer network for cross-resolution homography estimation,
R. Shao, G. Wu, Y . Zhou, Y . Fu, L. Fang, and Y . Liu, “Localtrans: A multiscale local transformer network for cross-resolution homography estimation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 14 890–14 899
2021
-
[25]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
2014
-
[26]
Multi-spectral sift for scene category recognition,
M. Brown and S. S ¨usstrunk, “Multi-spectral sift for scene category recognition,” inCVPR 2011. IEEE, 2011, pp. 177–184
2011
-
[27]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,
M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,”Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981
1981
-
[28]
Landsat-8: Science and product vision for terrestrial global change research,
D. P. Roy, M. A. Wulder, T. R. Loveland, W. Ce, R. G. Allen, M. C. Anderson, D. Helder, J. R. Irons, D. M. Johnson, R. Kennedyet al., “Landsat-8: Science and product vision for terrestrial global change research,”Remote sensing of Environment, vol. 145, pp. 154–172, 2014
2014
-
[29]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, pp. 91–110, 2004
2004
-
[30]
Surf: Speeded up robust features,
H. Bay, T. Tuytelaars, and L. Van Gool, “Surf: Speeded up robust features,” inComputer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, May 7-13, 2006. Proceedings, Part I 9. Springer, 2006, pp. 404–417
2006
-
[31]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571
2011
-
[32]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236
2018
-
[33]
Sosnet: Second order similarity regularization for local descriptor learning,
Y . Tian, X. Yu, B. Fan, F. Wu, H. Heijnen, and V . Balntas, “Sosnet: Second order similarity regularization for local descriptor learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 016–11 025
2019
-
[34]
D2-net: A trainable cnn for joint description and detection of local features,
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable cnn for joint description and detection of local features,” inProceedings of the ieee/cvf conference on computer vision and pattern recognition, 2019, pp. 8092–8101
2019
-
[35]
Loftr: Detector- free local feature matching with transformers,
J. Sun, Z. Shen, Y . Wang, H. Bao, and X. Zhou, “Loftr: Detector- free local feature matching with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922–8931
2021
-
[36]
Efficient loftr: Semi- dense local feature matching with sparse-like speed,
Y . Wang, X. He, S. Peng, D. Tan, and X. Zhou, “Efficient loftr: Semi- dense local feature matching with sparse-like speed,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 21 666–21 675
2024
-
[37]
Robust regression using itera- tively reweighted least-squares,
P. W. Holland and R. E. Welsch, “Robust regression using itera- tively reweighted least-squares,”Communications in Statistics-theory and Methods, vol. 6, no. 9, pp. 813–827, 1977
1977
-
[38]
Magsac: marginalizing sample consensus,
D. Barath, J. Matas, and J. Noskova, “Magsac: marginalizing sample consensus,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 197–10 205
2019
-
[39]
Multiple view geometry in computer vision,
R. Hartley, “Multiple view geometry in computer vision,” 2003
2003
-
[40]
Codinghomo: Bootstrapping deep homography with video coding,
Y . Liu, H. Li, S. Liu, and B. Zeng, “Codinghomo: Bootstrapping deep homography with video coding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11 214–11 228, 2024
2024
-
[41]
Crosshomo: Cross- modality and cross-resolution homography estimation,
X. Deng, E. Liu, C. Gao, S. Li, S. Gu, and M. Xu, “Crosshomo: Cross- modality and cross-resolution homography estimation,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[42]
Roma: Robust dense feature matching,
J. Edstedt, Q. Sun, G. B ¨okman, M. Wadenb¨ack, and M. Felsberg, “Roma: Robust dense feature matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 790–19 800
2024
-
[43]
P2wnet: Homography estimation for part-to-whole and cross-modality scenarios,
S. Xie, H. Wu, W. Li, and L. Duan, “P2wnet: Homography estimation for part-to-whole and cross-modality scenarios,” 06 2025, pp. 1–6
2025
-
[44]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” in International conference on machine learning. PMLR, 2020, pp. 5156– 5165. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2020
-
[45]
Efficientvit: Multi-scale linear attention for high-resolution dense prediction,
H. Cai, J. Li, M. Hu, C. Gan, and S. Han, “Efficientvit: Multi-scale linear attention for high-resolution dense prediction,”arXiv preprint arXiv:2205.14756, 2022
-
[46]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Sinkhorn distances: Lightspeed computation of optimal transport,
M. Cuturi, “Sinkhorn distances: Lightspeed computation of optimal transport,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[48]
Siamcorners: Siamese corner networks for visual tracking,
K. Yang, Z. He, W. Pei, Z. Zhou, X. Li, D. Yuan, and H. Zhang, “Siamcorners: Siamese corner networks for visual tracking,”IEEE Transactions on Multimedia, vol. 24, pp. 1956–1967, 2021
1956
-
[49]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988
2017
-
[50]
Generalized intersection over union: A metric and a loss for bounding box regression,
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2019, pp. 658–666
2019
-
[51]
Drone-based rgb-infrared cross- modality vehicle detection via uncertainty-aware learning,
Y . Sun, B. Cao, P. Zhu, and Q. Hu, “Drone-based rgb-infrared cross- modality vehicle detection via uncertainty-aware learning,”IEEE Trans- actions on Circuits and Systems for Video Technology, vol. 32, no. 10, pp. 6700–6713, 2022
2022
-
[52]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.