ALM2Vec: Learning Audio Embeddings for Universal Audio Retrieval with Large Audio-Language Models
Pith reviewed 2026-07-01 06:45 UTC · model grok-4.3
The pith
ALM2Vec derives universal audio embeddings from large audio-language models to enable instruction-guided retrieval across tasks and domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that transferring audio understanding, instruction-following, and reasoning from large-scale multimodal training produces a unified embedding space supporting retrieval across audio domains and task types, including instruction-aware scenarios like audio question answering and aspect-conditioned retrieval.
What carries the argument
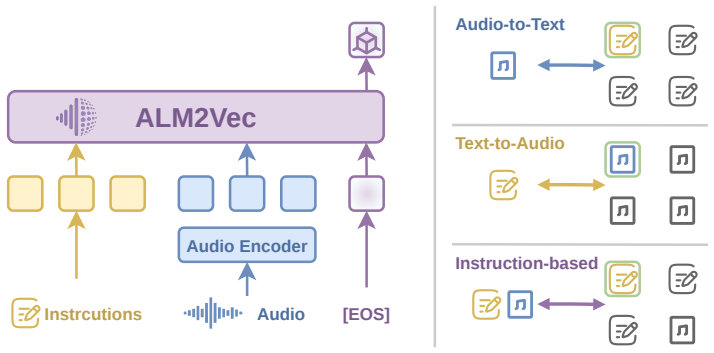
ALM2Vec, the embedding framework derived from pretrained large audio-language models that transfers their multimodal capabilities into a retrieval embedding space.
If this is right
- ALM2Vec achieves competitive performance on standard audio and speech retrieval benchmarks.
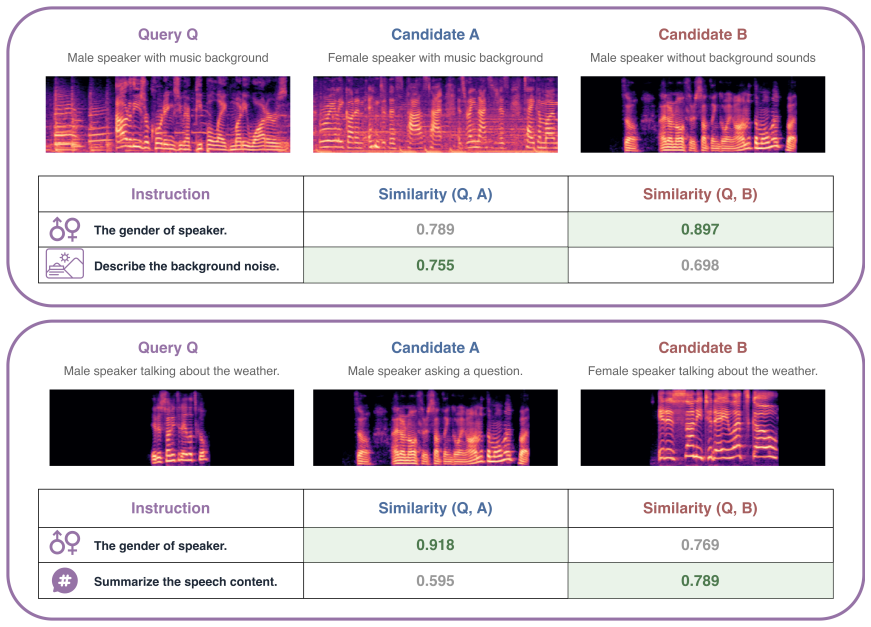
- It enables instruction-aware retrieval for tasks such as audio question answering.
- It supports aspect-conditioned retrieval and shows compositional capabilities.
- It acts as a unified embedding model for retrieval across different domains, tasks, and user intents.
Where Pith is reading between the lines
- Such an approach might allow audio retrieval systems to adapt to new user intents without retraining separate models for each scenario.
- Integration with existing language models could extend to more complex multimodal interactions involving audio.
- Testing on unseen instruction types would reveal the limits of the transferred reasoning abilities.
- Deployment in real-world applications could simplify audio search interfaces by relying on natural language control.
Load-bearing premise
The capabilities developed during large audio-language model pretraining transfer effectively to create useful retrieval embeddings.
What would settle it
A direct comparison where ALM2Vec shows no advantage over conventional contrastive embeddings on instruction-based retrieval tasks would indicate that the transferred capabilities do not improve retrieval performance.
Figures
read the original abstract
Recent advances in language--audio retrieval have been largely driven by contrastive dual-encoder architectures that align audio and text in a shared embedding space. While effective, existing retrieval embeddings are primarily optimized for audio--caption matching, limiting their ability to support diverse retrieval objectives and controllable retrieval behaviors. We present ALM2Vec, a universal audio embedding framework derived from pretrained large audio--language models (LALMs). By transferring the audio understanding, instruction-following, and reasoning capabilities acquired through large-scale multimodal training, ALM2Vec learns a unified embedding space for retrieval across audio domains and task types. Beyond conventional text--audio retrieval, ALM2Vec incorporates natural-language instructions into the embedding process, enabling instruction-aware retrieval for scenarios such as audio question answering and aspect-conditioned retrieval. Experimental results show that ALM2Vec achieves competitive performance on standard audio and speech retrieval benchmarks while exhibiting promising compositional and controllable retrieval capabilities, highlighting its potential as a unified audio embedding model for retrieval across domains, tasks, and user intents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALM2Vec, a universal audio embedding framework derived from pretrained large audio-language models (LALMs). It claims that by transferring audio understanding, instruction-following, and reasoning capabilities from large-scale multimodal training, the model learns a unified embedding space supporting retrieval across audio domains and task types, including instruction-aware retrieval for audio question answering and aspect-conditioned scenarios. Experimental results are reported to show competitive performance on standard audio and speech retrieval benchmarks alongside new compositional and controllable behaviors.
Significance. If the transfer of LALM capabilities to a retrieval embedding space holds with the reported experimental support, the work could provide a more flexible alternative to contrastive dual-encoder models, enabling unified handling of diverse retrieval objectives without domain- or task-specific retraining.
major comments (2)
- [§4] §4 (Experimental Setup): The manuscript reports competitive results on standard benchmarks but does not specify the exact LALM backbone used for ALM2Vec derivation, the projection layer architecture, or the contrastive loss formulation; without these details the transfer claim cannot be fully assessed for reproducibility.
- [Table 2] Table 2 (Instruction-aware retrieval results): The reported gains on aspect-conditioned retrieval lack ablation on the instruction encoder component, making it unclear whether the controllability stems from LALM pretraining or from additional fine-tuning steps.
minor comments (2)
- [Abstract] The abstract and §1 use 'competitive performance' without quantifying the baselines or margins; adding explicit delta values would improve clarity.
- [Figure 1] Figure 1 (architecture diagram) omits the exact dimensionality of the final embedding space and the pooling strategy over audio tokens.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The manuscript reports competitive results on standard benchmarks but does not specify the exact LALM backbone used for ALM2Vec derivation, the projection layer architecture, or the contrastive loss formulation; without these details the transfer claim cannot be fully assessed for reproducibility.
Authors: We agree that these implementation details are necessary for full reproducibility and assessment of the transfer claim. The current §4 provides high-level description but omits the precise LALM backbone, projection layer architecture, and contrastive loss formulation. In the revised manuscript we will expand §4 to explicitly state the LALM backbone, detail the projection layer architecture, and provide the contrastive loss formulation. revision: yes
-
Referee: [Table 2] Table 2 (Instruction-aware retrieval results): The reported gains on aspect-conditioned retrieval lack ablation on the instruction encoder component, making it unclear whether the controllability stems from LALM pretraining or from additional fine-tuning steps.
Authors: We acknowledge that an ablation isolating the instruction encoder would strengthen the interpretation of the results. The current experiments demonstrate overall gains but do not include such an ablation. In the revised manuscript we will add a targeted ablation study on the instruction encoder (or, if space-constrained, a concise discussion of its contribution) to clarify the source of controllability. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper claims ALM2Vec is obtained by transferring capabilities from pretrained large audio-language models into a unified embedding space, with instruction-aware retrieval as an additional capability. The abstract and description present this as a transfer-learning construction followed by benchmark validation, without any equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs by construction. No self-definitional steps, ansatz smuggling, or uniqueness theorems imported from the same authors appear in the provided text. The derivation therefore remains self-contained against external benchmarks and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Clap learning audio con- cepts from natural language supervision
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap learning audio con- cepts from natural language supervision. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 1–5. IEEE, 2023
2023
-
[2]
Large- scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large- scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 1–5. IEEE, 2023
2023
-
[3]
Jiarui Hai, Y ong Xu, Hao Zhang, Chenxing Li, Helin Wang, Mounya Elhilali, and Dong Yu. Ezaudio: En- hancing text-to-audio generation with efficient diffusion transformer.arXiv preprint arXiv:2409.10819, 2024
-
[4]
Synsonic: Augmenting sound event detection through text-to-audio diffusion controlnet and effective sample filtering
Jiarui Hai and Mounya Elhilali. Synsonic: Augmenting sound event detection through text-to-audio diffusion controlnet and effective sample filtering. In 2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 1–5. IEEE, 2025
2025
-
[5]
Sam audio: Segment anything in audio
Bowen Shi, Andros Tjandra, John Hoffman, Helin Wang, Yi-Chiao Wu, Luya Gao, Julius Richter, Matt Le, Apoorv Vyas, Sanyuan Chen, et al. Sam audio: Segment anything in audio. arXiv preprint arXiv:2512.18099, 2025
-
[6]
Audioldm: Text-to-audio generation with latent diffusion models
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumb- ley. Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503 , 2023
-
[7]
Text-to-audio generation us- ing instruction guided latent diffusion model
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. Text-to-audio generation us- ing instruction guided latent diffusion model. In Proceedings of the 31st ACM international conference on multimedia, pages 3590–3598, 2023
2023
-
[8]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 736–740. IEEE, 2020
2020
-
[9]
End-to-end contrastive language-speech pretraining model for long-form spoken question answering
Jiliang Hu, Zuchao Li, Baoyuan Qi, Guoming Liu, and Ping Wang. End-to-end contrastive language-speech pretraining model for long-form spoken question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31041–31049, 2026
2026
-
[10]
Midashenglm: Efficient audio understanding with general audio captions
Heinrich Dinkel, Gang Li, Jizhong Liu, Jian Luan, Y adong Niu, Xingwei Sun, Tianzi Wang, Qiyang Xiao, Junbo Zhang, and Jiahao Zhou. Midashenglm: Efficient audio understanding with general audio captions. arXiv preprint arXiv:2508.03983, 2025
-
[11]
Yunfei Chu, Jin Xu, Qian Y ang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Boyong Wu, Chao Y an, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report. arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Lau- rent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Y ong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36:34892–34916, 2023. 6
2023
-
[17]
Mingxin Li, Y anzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state- of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y anzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
jina-embeddings-v3: Multilingual em- beddings with task lora
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, et al. jina-embeddings-v3: Multilingual em- beddings with task lora. arXiv preprint arXiv:2409.10173, 2024
-
[20]
arXiv preprint arXiv:2406.06992 , year=
Heinrich Dinkel, Zhiyong Y an, Y ongqing Wang, Junbo Zhang, Yujun Wang, and Bin Wang. Scaling up masked audio encoder learning for general audio classification. arXiv preprint arXiv:2406.06992, 2024
-
[21]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Y ang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report. arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning , pages 8748–8763. PmLR, 2021
2021
-
[23]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 119–132, 2019
2019
-
[24]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models, 2025
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang gil Lee, Chao-Han Huck Y ang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models, 2025
2025
-
[25]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities. arXiv preprint arXiv:2503.03983, 2025
-
[26]
Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuex- ian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Audio, Speech, and Language Process- ing, 32:3339–3354, 2024
2024
-
[27]
jina-embeddings-v5-omni: Geometry-preserving Embeddings via Locked Aligned Towers
Florian Hönicke, Michael Günther, Andreas Koukounas, Kalim Akram, Scott Martens, Saba Sturua, and Han Xiao. jina-embeddings-v5-omni: Text-geometry-preserving multimodal embeddings via frozen-tower composition. arXiv preprint arXiv:2605.08384, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Librisqa: A novel dataset and frame- work for spoken question answering with large language models.IEEE Transactions on Artificial Intelligence, 2024
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yu Wang, and Y anfeng Wang. Librisqa: A novel dataset and frame- work for spoken question answering with large language models.IEEE Transactions on Artificial Intelligence, 2024
2024
-
[29]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[30]
Retrieve anything to augment large language models, 2023
Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian- Yun Nie. Retrieve anything to augment large language models, 2023
2023
-
[31]
Mmau: A massive multi-task audio understanding and reasoning benchmark
Sakshi Sakshi, Utkarsh T yagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark. In International Conference on Learning Representations, volume 2025, pages 84929– 84964, 2025
2025
-
[32]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.