Predictable GRPO: A Closed-Form Model of Training Dynamics
Pith reviewed 2026-07-01 06:38 UTC · model grok-4.3
The pith
GRPO training dynamics reduce to a closed-form inertial system in a potential whose overdamped limit recovers the empirical saturation law.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
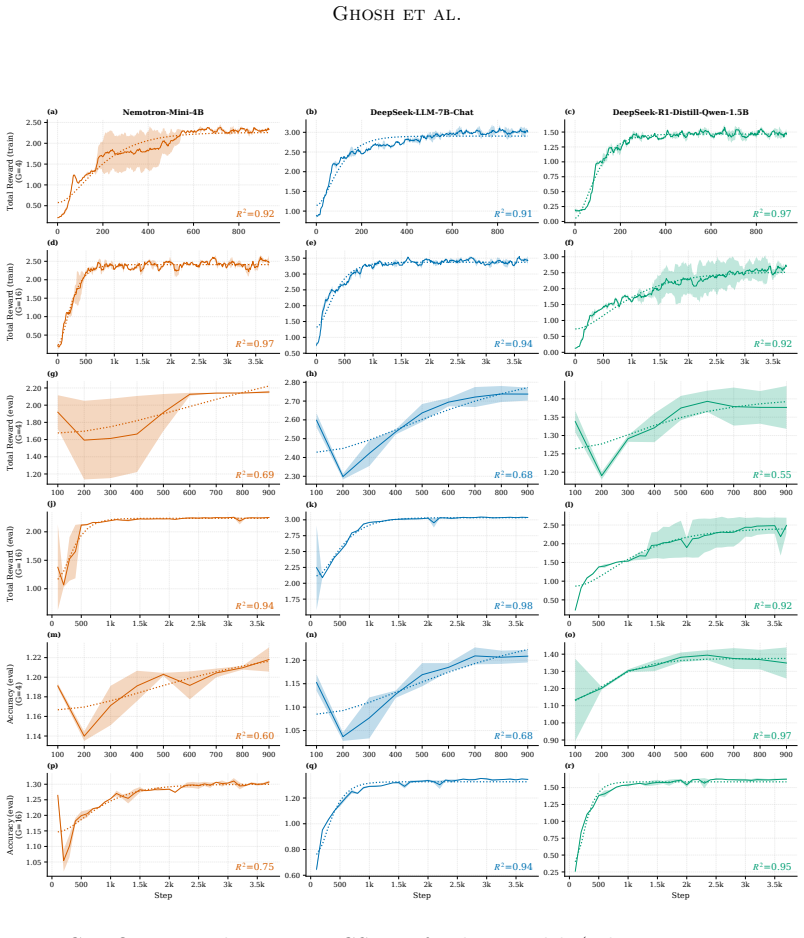
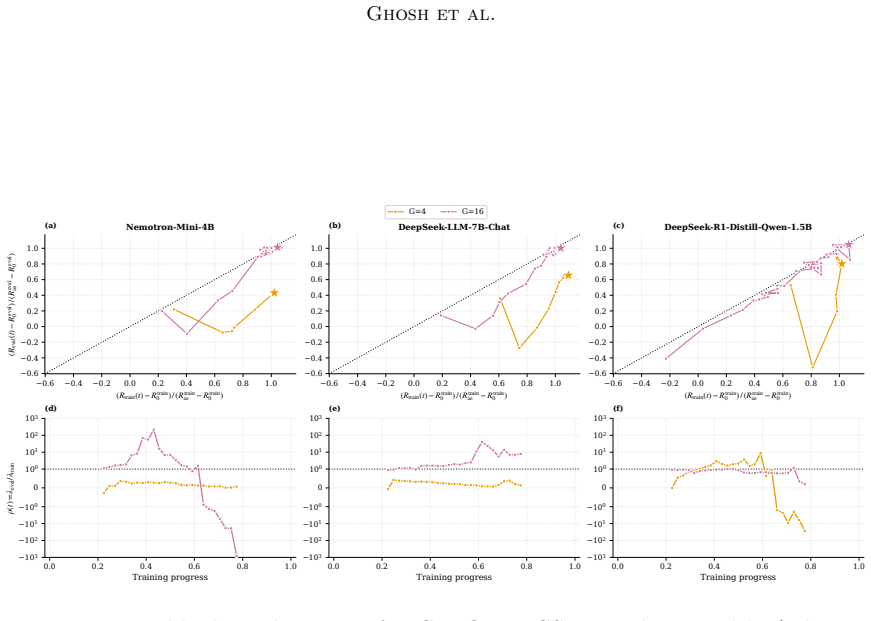
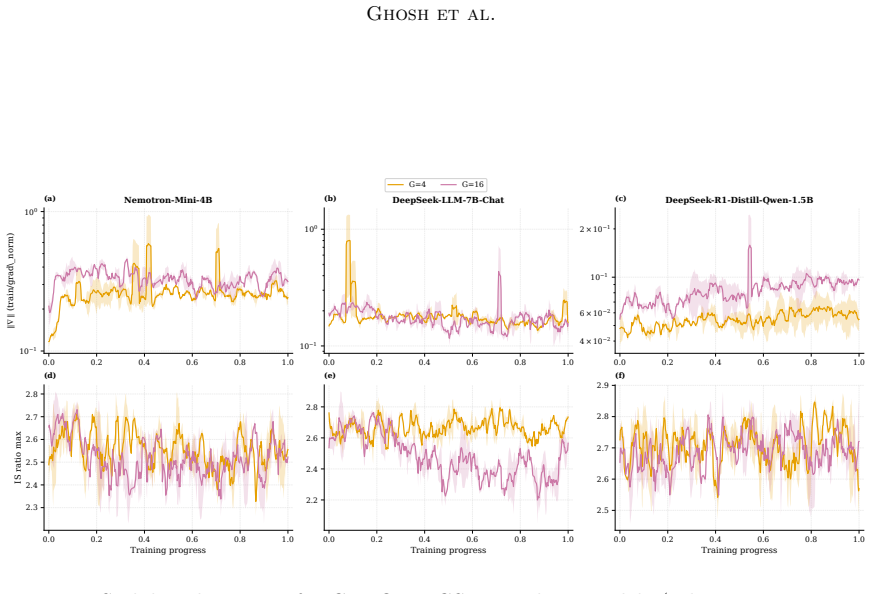
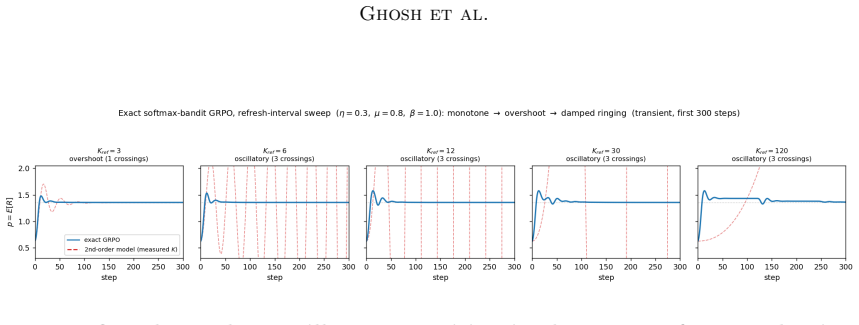
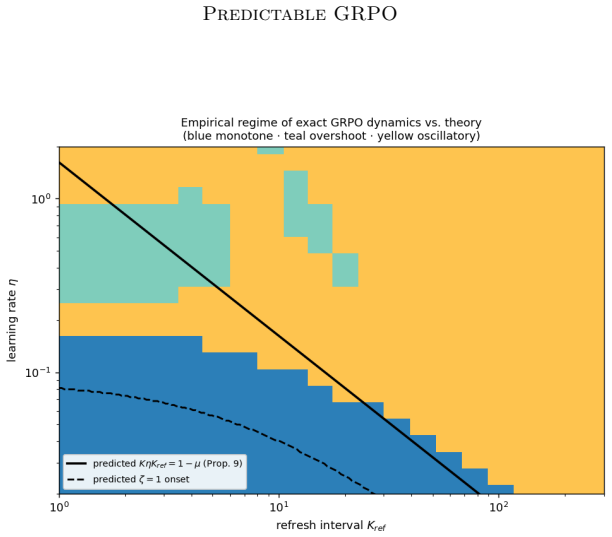
GRPO dynamics are captured by a deterministic inertial equation whose potential has a fixed point, a stiffness parameter, and a curvature-scaling exponent; the overdamped limit recovers the single-exponential saturation law with the added inertial term supplying the initial slow-start phase, and the full model supplies closed-form predictions for group-size invariance (deterministic trajectory unchanged, fluctuations ~1/G), refresh-interval stability threshold, and the overdamped-to-oscillatory transition, all verified to high accuracy on real training runs and exactly in the controlled bandit reduction.
What carries the argument
The reduced-order inertial particle in a potential, obtained by mean-field closure of the GRPO update rule, whose solution yields the closed-form reward trajectory.
If this is right
- The deterministic reward trajectory remains unchanged when group size is varied while stationary fluctuations scale exactly as 1/G.
- A sharp stability threshold appears in the refresh interval at the independently measured stiffness value.
- An overdamped-to-oscillatory transition occurs when the damping ratio crosses a critical value set by the stiffness.
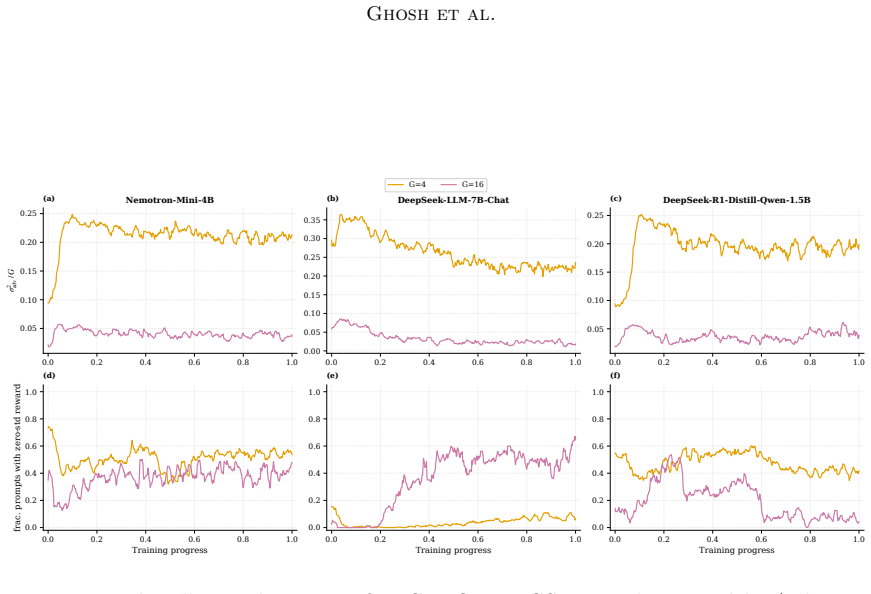
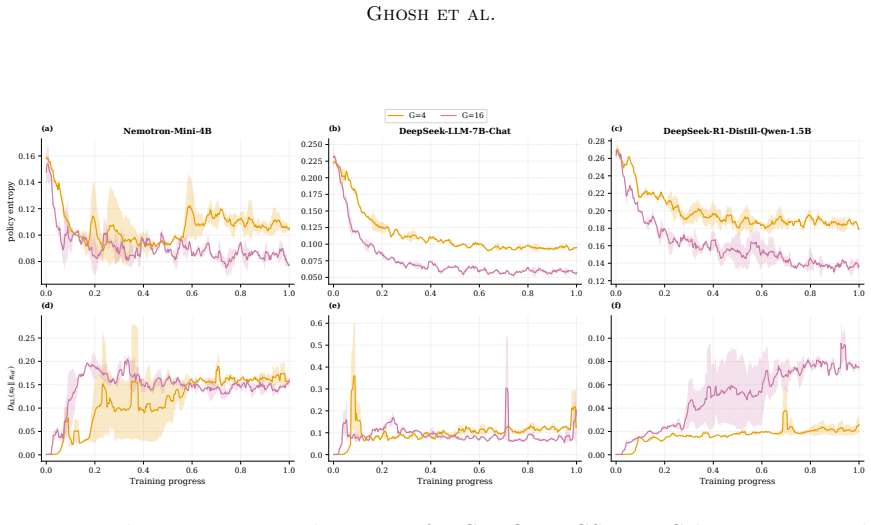
- Four distinct failure modes (reward hacking, advantage degeneracy, policy concentration, dynamical instability) produce qualitatively different signatures on the same reward curve.
Where Pith is reading between the lines
- If the inertial model continues to hold at larger scales, hyperparameter search for refresh interval and group size could be replaced by direct stiffness measurements rather than grid search.
- The same potential-based description may supply analogous closed-form trajectories for other group-relative or advantage-based RL algorithms once their update rules are written in mean-field form.
- Diagnostics that separate the four failure modes could be turned into automated early-stopping rules that act on the shape of the observed trajectory rather than on final reward alone.
Load-bearing premise
The mean-field reduction that collapses the full policy update into a single inertial equation with a fixed potential holds exactly only in the softmax-bandit setting and is treated as an approximation for deep networks.
What would settle it
A training run in which the deterministic reward trajectory changes shape with group size G, or in which the observed stability threshold for refresh interval deviates from the independently measured stiffness, would falsify the central reduction.
Figures
read the original abstract
Group Relative Policy Optimization (GRPO) has become a standard tool for improving the reasoning ability of large language models, yet its training dynamics are still described empirically: reward trajectories are fit with low-parameter functional forms whose constants carry no mechanistic meaning, and hyperparameter choices remain a matter of trial and error. We develop a first-principles reduced-order model of these dynamics. The reduction has three consequences. First, it subsumes the empirical single-exponential saturation law as its overdamped limit, recasting the fitted plateau, timescale, and size exponent as the fixed point, inverse stiffness, and curvature-scaling exponent of the underlying potential, and adding, through the retained inertial term, the slow-start phase the single exponential cannot represent. Second, it yields predictions tied to independently measurable quantities rather than fitted ones: group-size invariance of the deterministic trajectory with a $1/G$ stationary fluctuation, a sharp stability threshold in the refresh interval, and an overdamped-to-oscillatory transition. Third, it furnishes diagnostics that separate failure modes a reward curve alone conflates -- reward hacking, advantage degeneracy, policy concentration, and dynamical instability. Across three models and two group sizes, the closed-form trajectory fits training reward to $R^2 \geq 0.91$ and the predicted group-size invariance holds on both the reward curve and out-of-distribution transfer to eight math benchmarks. The stability and oscillatory predictions are exercised in a controlled exact-reduction setting where the mean-field assumption holds exactly: a softmax-bandit reduction reproduces the predicted overdamped-to-oscillatory transition and locates the refresh-interval stability threshold at the independently measured stiffness, with a deep-network demonstration left to future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a first-principles reduced-order inertial model with an underlying potential for GRPO training dynamics. This model subsumes the empirical single-exponential saturation law as its overdamped limit (recasting plateau, timescale, and size exponent as fixed point, inverse stiffness, and curvature-scaling exponent), adds a slow-start phase via the inertial term, and yields predictions including group-size invariance of the deterministic trajectory (with 1/G stationary fluctuation), a sharp stability threshold in the refresh interval, and an overdamped-to-oscillatory transition. It reports closed-form trajectory fits to training reward with R² ≥ 0.91 across three models and two group sizes, verifies the predicted group-size invariance on both reward curves and OOD transfer to eight math benchmarks, and confirms the transition and threshold exactly in a softmax-bandit reduction where the mean-field assumption holds; the stability and oscillatory predictions for deep networks are left to future work.
Significance. If the mean-field reduction holds beyond the bandit case, the work would provide a mechanistic framework that recasts empirical fitting parameters into quantities with physical interpretation (fixed point, stiffness) and supplies diagnostics separating failure modes such as reward hacking from dynamical instability. The exact verification of the core reduction and transition in the controlled softmax-bandit setting is a clear strength, as is the reported invariance on both in-distribution reward and OOD benchmarks. However, the headline empirical results on deep models rest on an approximation whose accuracy for the predictive claims has not been established.
major comments (3)
- [Abstract] Abstract: The assertion that the model yields 'predictions tied to independently measurable quantities rather than fitted ones' is undercut by the explicit recasting of stiffness and curvature-scaling exponent from previously fitted empirical parameters; these remain the two free parameters of the model, so the claimed independence from fitting is not realized for the central predictions.
- [Abstract] Abstract and main empirical section: The diagnostic separation of failure modes (reward hacking, advantage degeneracy, policy concentration, dynamical instability) is exercised only in the exact-reduction bandit setting; for the three deep models on which the R² ≥ 0.91 fits and group-size invariance are claimed, the stability threshold and overdamped-to-oscillatory transition predictions are explicitly left to future work, so the mechanistic diagnostics for those results depend on an unverified assumption.
- [The mean-field assumption (as described in abstract and skeptic note)] The mean-field reduction to a closed-form inertial system: While the reduction is exact in the softmax-bandit case (where the overdamped-to-oscillatory transition and refresh-interval threshold at the measured stiffness are verified), its validity as an approximation for general deep networks is stated to be left to future work; this makes the recasting of parameters and the predictive claims for LLMs load-bearing on an assumption whose accuracy is not established in the reported experiments.
minor comments (1)
- [Abstract / Introduction] The abstract and introduction would benefit from an explicit equation defining the inertial system and potential early in the text to clarify the reduction steps before the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. We address the major comments point by point below. Our responses clarify the scope of the claims as already presented in the paper, particularly the distinction between the bandit verification and the deep model results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the model yields 'predictions tied to independently measurable quantities rather than fitted ones' is undercut by the explicit recasting of stiffness and curvature-scaling exponent from previously fitted empirical parameters; these remain the two free parameters of the model, so the claimed independence from fitting is not realized for the central predictions.
Authors: The independence claimed refers to the fact that once the two parameters are determined from the reward trajectory fit, the listed predictions (group-size invariance, stability threshold location, and transition) follow without further fitting or adjustment. The stiffness, for example, is measured from the fit and then used to predict the refresh-interval threshold, which is verified exactly in the bandit setting at the measured value. The group-size invariance is a structural prediction that holds across different group sizes without refitting. Thus, while the parameters are fitted, the predictions are not. revision: no
-
Referee: [Abstract] Abstract and main empirical section: The diagnostic separation of failure modes (reward hacking, advantage degeneracy, policy concentration, dynamical instability) is exercised only in the exact-reduction bandit setting; for the three deep models on which the R² ≥ 0.91 fits and group-size invariance are claimed, the stability threshold and overdamped-to-oscillatory transition predictions are explicitly left to future work, so the mechanistic diagnostics for those results depend on an unverified assumption.
Authors: This is accurate, and the manuscript already makes this distinction explicit: the diagnostics and stability/oscillatory predictions are shown in the bandit reduction where the assumption holds exactly, while for deep models we report the fits and invariance. The abstract does not claim the full set of diagnostics for the deep model results. No change is required as the scope is already qualified. revision: no
-
Referee: [The mean-field assumption (as described in abstract and skeptic note)] The mean-field reduction to a closed-form inertial system: While the reduction is exact in the softmax-bandit case (where the overdamped-to-oscillatory transition and refresh-interval threshold at the measured stiffness are verified), its validity as an approximation for general deep networks is stated to be left to future work; this makes the recasting of parameters and the predictive claims for LLMs load-bearing on an assumption whose accuracy is not established in the reported experiments.
Authors: We concur that the mean-field approximation's accuracy for deep networks is not established here and is left for future work. The predictive claims for LLMs in the current work are the group-size invariance (verified empirically) and the closed-form fits; the stability threshold and transition are not claimed for the deep models. The bandit verification provides support for the reduction in a controlled setting. revision: no
Circularity Check
No significant circularity; derivation self-contained with independent verification
full rationale
The paper presents a first-principles mean-field reduction to a closed-form inertial dynamical system whose overdamped limit recovers the known single-exponential saturation while the inertial term supplies additional structure. Group-size invariance of the deterministic trajectory is derived directly from the reduction and tested on the three deep models; the stability threshold and overdamped-to-oscillatory transition are verified exactly inside the softmax-bandit setting where the mean-field assumption holds without approximation. No equation or claim reduces a stated prediction to a fitted constant, a self-citation, or an ansatz imported from prior work by the same authors; the mapping of empirical parameters to fixed-point, stiffness, and curvature quantities is an interpretive consequence of the independent derivation rather than a definitional identity. The paper explicitly flags that full applicability of the reduction to deep networks remains future work, but this does not render any load-bearing step circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- stiffness
- curvature-scaling exponent
axioms (2)
- domain assumption Training dynamics of GRPO admit a low-dimensional inertial reduction with an underlying potential whose fixed point, stiffness, and curvature govern the observed trajectories.
- domain assumption Mean-field assumption for group interactions.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI. DeepSeek LLM: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URLhttp://dx.doi.org/10. 1038/s41586-025-09422-z. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Ben...
-
[4]
NuminaMath, 2024.https: //github.com/project-numina/aimo-progress-prize
Li Jia, Beeching Edward, Tunstall Lewis, Lipkin Ben, Soletskyi Roman, Huang Shengyi, Rasul Kashif, Yu Longhui, Jiang Albert, Shen Ziju, Qin Zihan, Dong Bin, Zhou Li, Fleureau Yann, Lample Guillaume, and Polu Stanislas. NuminaMath, 2024.https: //github.com/project-numina/aimo-progress-prize. 29 Ghosh et al. Qintong Li, Leyang Cui, Xueliang Zhao, Lingpeng K...
2024
-
[5]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
URLhttps://arxiv.org/abs/2506.13585. Mistral-AI, :, Abhinav Rastogi, Albert Q. Jiang, Andy Lo, Gabrielle Berrada, Guil- laume Lample, Jason Rute, Joep Barmentlo, Karmesh Yadav, Kartik Khandelwal, Khy- athi Raghavi Chandu, L´ eonard Blier, Lucile Saulnier, Matthieu Dinot, Maxime Dar- rin, Neha Gupta, Roman Soletskyi, Sagar Vaze, Teven Le Scao, Yihan Wang, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/abs/2506.10910. Youssef Mroueh. Reinforcement learning with verifiable rewards: GRPO’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639,
-
[7]
Datta Nimmaturi, Vaishnavi Bhargava, Rajat Ghosh, Johnu George, and Debojyoti Dutta. Predictive scaling laws for efficient GRPO training of large reasoning models.arXiv preprint arXiv:2507.18014,
-
[8]
Nemotron-mini-4b-instruct.Hugging Face model card, 2024.https:// huggingface.co/nvidia/Nemotron-Mini-4B-Instruct
NVIDIA. Nemotron-mini-4b-instruct.Hugging Face model card, 2024.https:// huggingface.co/nvidia/Nemotron-Mini-4B-Instruct. OpenAI. Introducing OpenAI o3 and o4-mini.https://openai.com/index/ introducing-o3-and-o4-mini/, April
2024
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://arxiv.org/ abs/2402.03300. Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. OpenMathInstruct-2: Accelerating AI for math with massive open-source instruction data.arXiv preprint arXiv:2410.01560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
What is the alignment objective of GRPO?arXiv preprint arXiv:2502.18548,
Milan Vojnovic and Se-Young Yun. What is the alignment objective of GRPO?arXiv preprint arXiv:2502.18548,
-
[11]
Zhilin Wang, Yafu Li, Shunkai Zhang, Zhi Wang, Haoran Zhang, Xiaoye Qu, and Yu Cheng. New skills or sharper primitives? a probabilistic perspective on the emergence of reasoning in rlvr.arXiv preprint arXiv:2602.08281,
-
[12]
URLhttps://arxiv.org/abs/2601.11061. Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. MetaMath: Bootstrap your own mathematical questions for large language models. InInternational Conference on Learn- ing Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
URLhttps://arxiv.org/abs/2504.13837. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://arxiv.org/abs/2507.18071. 32
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.