Towards Knowledge Alignment in Code LLMs: Contrastive Unlearning for Evolving APIs
Pith reviewed 2026-07-01 01:51 UTC · model grok-4.3
The pith
CURE uses contrastive unlearning to steer code LLMs away from deprecated APIs toward valid replacements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CURE is a contrastive unlearning method that jointly discourages deprecated APIs while encouraging their valid alternatives, enabling more reliable adaptation to evolving software libraries than methods that only suppress outdated knowledge.
What carries the argument
CURE, the contrastive unlearning approach that shifts from pure suppression of outdated knowledge to explicitly promoting correct API replacements.
If this is right
- Reduces deprecated API usage in generated code.
- Increases the frequency of correct API replacements.
- Preserves general code generation performance on tasks unrelated to the updated APIs.
- Outperforms two state-of-the-art baselines on multiple quality metrics for the adaptation task.
Where Pith is reading between the lines
- Contrastive unlearning could extend to other targeted knowledge updates in LLMs, such as correcting factual errors or domain-specific terminology.
- The dual suppression-plus-replacement pattern may lower the frequency of full retraining needed when libraries evolve.
- Testing CURE on larger models or additional languages would reveal whether the observed steering effect scales beyond the current benchmark.
Load-bearing premise
The assumption that contrastive signals can reliably steer models toward correct replacements without introducing new mismatches or degrading unrelated capabilities, tested only on the referenced benchmark dataset.
What would settle it
If, on a new collection of deprecated APIs not seen in the original benchmark, CURE produces more incomplete or erroneous generations than a pure-suppression baseline, the steering benefit would be falsified.
Figures
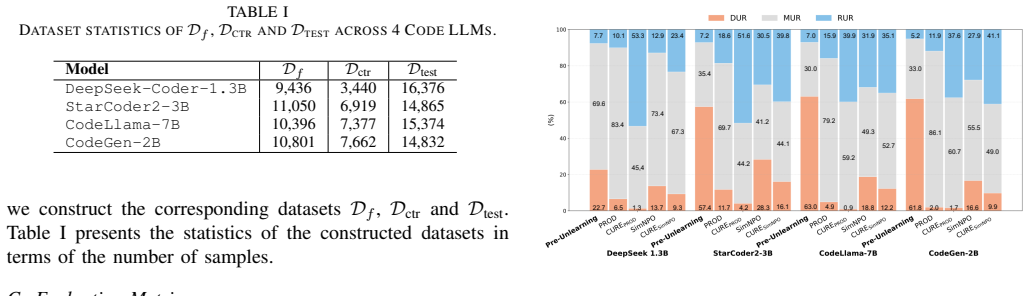
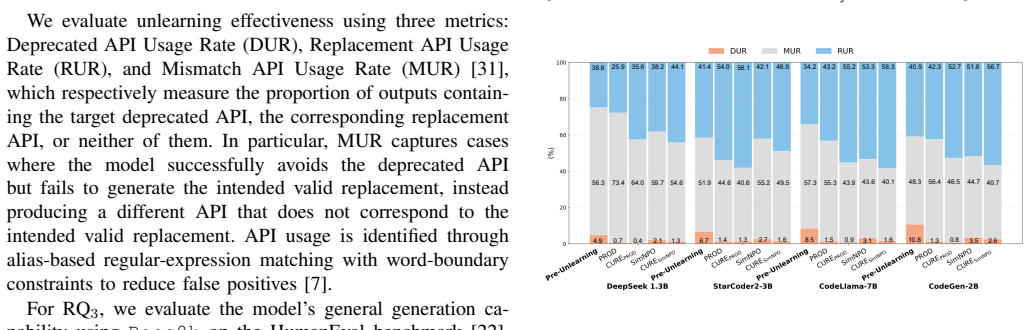
read the original abstract
Large Language Models (LLMs) have recently achieved strong performance in code generation. However, due to knowledge cut-off and the rapid evolution of software libraries, they often generate deprecated API usages that lead to unreliable and incompatible code. Existing fine-tuning methods lack selectivity when only a small portion of model knowledge requires modification. Recent model-level approaches, such as machine unlearning and model editing, offer a promising direction for modifying parametric knowledge. However, their use for deprecated API mitigation remains largely unexplored. Moreover, existing methods primarily suppress outdated APIs, but do not explicitly steer models toward correct replacements, often leading to mismatched or incomplete generations. To address this limitation, we developed CURE, a contrastive unlearning approach that shifts unlearning from purely suppressing outdated knowledge to explicitly promoting correct API replacements. Concretely, CURE jointly discourages deprecated APIs while encouraging their valid alternatives, enabling more reliable adaptation to evolving software libraries. The experiments on recent deprecated API benchmark dataset show that CURE not only reduces deprecated API usage but also improves correct API replacement, while preserving general code generation performance. CURE substantially outperforms two SOTA baselines with respect to different quality metrics. These findings highlight the importance of combining suppression with replacement when adapting LLMs to evolving software ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CURE, a contrastive unlearning method for code LLMs that jointly discourages deprecated API usages and encourages valid replacements to address knowledge cutoffs in evolving software libraries. On a deprecated API benchmark dataset, the authors claim CURE reduces deprecated API usage, improves correct API replacement rates, preserves general code generation performance, and substantially outperforms two SOTA baselines across multiple quality metrics.
Significance. If the empirical claims hold with proper controls and auxiliary benchmarks, the work would be significant for practical maintenance of code LLMs in dynamic environments. The shift from pure suppression to contrastive promotion of replacements is a targeted idea that could influence knowledge alignment techniques more broadly. The emphasis on selectivity when only a small portion of knowledge needs updating is a useful framing, though the single-benchmark scope limits immediate impact.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The central claims of outperformance, improved correct replacements, and preservation of general performance are asserted without any reported metrics, tables, statistical tests, dataset details, or controls. This is load-bearing because the headline result cannot be evaluated from the text.
- [Method / Experiments] Method and Experiments sections: No description is given of how positive/negative pairs are constructed for the contrastive signals, the exact form of the contrastive loss, or any auxiliary benchmarks (e.g., HumanEval, MBPP) used to verify that unrelated capabilities remain unchanged. Without these, the assumption that joint discouragement and encouragement produces reliable steering without new mismatches cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on clarity and completeness. We address each point below and will revise the manuscript to incorporate the requested details and metrics.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central claims of outperformance, improved correct replacements, and preservation of general performance are asserted without any reported metrics, tables, statistical tests, dataset details, or controls. This is load-bearing because the headline result cannot be evaluated from the text.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised version, we will update the abstract to report key metrics from the experiments (e.g., deprecated API usage reduction rates, correct replacement improvements, and general performance scores), reference the relevant tables, and note dataset details and any statistical tests performed. The Experiments section will be expanded to ensure all controls and auxiliary results are clearly presented. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: No description is given of how positive/negative pairs are constructed for the contrastive signals, the exact form of the contrastive loss, or any auxiliary benchmarks (e.g., HumanEval, MBPP) used to verify that unrelated capabilities remain unchanged. Without these, the assumption that joint discouragement and encouragement produces reliable steering without new mismatches cannot be assessed.
Authors: We will revise the Method section to explicitly describe the construction of positive and negative pairs for the contrastive signals, provide the precise mathematical form of the contrastive loss, and detail the auxiliary benchmarks (including HumanEval and MBPP) along with results showing preservation of unrelated capabilities. This will allow readers to evaluate the selectivity of the updates. revision: yes
Circularity Check
No circularity detected; conceptual method proposal with external benchmark evaluation
full rationale
The paper proposes CURE as a contrastive unlearning technique at a descriptive level, with no equations, derivations, or mathematical chains present in the abstract or described method. Claims rest on experimental results from a referenced benchmark dataset rather than any self-referential fitting, self-definition of terms, or load-bearing self-citations that reduce the result to its inputs by construction. No steps match the enumerated circularity patterns, and the approach is presented as an independent combination of suppression and promotion signals.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parametric knowledge in LLMs can be selectively modified through unlearning techniques without full retraining
Reference graph
Works this paper leans on
-
[1]
Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,
F. Mu, L. Shi, S. Wang, Z. Yu, B. Zhang, C. Wang, S. Liu, and Q. Wang, “Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 2332–2354, 2024
2024
-
[2]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” in2025 IEEE/ACM 47th Interna- tional Conference on Software Engineering (ICSE). IEEE, 2025, pp. 2188–2200
2025
-
[3]
Mutation-guided llm-based test generation at meta,
M. Harman, J. Ritchey, I. Harper, S. Sengupta, K. Mao, A. Gulati, C. Foster, and H. Robert, “Mutation-guided llm-based test generation at meta,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 180–191
2025
-
[4]
Can llms replace human evaluators? an empirical study of llm-as-a-judge in soft- ware engineering,
R. Wang, J. Guo, C. Gao, G. Fan, C. Y . Chong, and X. Xia, “Can llms replace human evaluators? an empirical study of llm-as-a-judge in soft- ware engineering,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 1955–1977, 2025
1955
-
[5]
Llm-as-a-judge for software engineering: Literature review, vision, and the road ahead,
J. He, J. Shi, T. Y . Zhuo, C. Treude, J. Sun, Z. Xing, X. Du, and D. Lo, “Llm-as-a-judge for software engineering: Literature review, vision, and the road ahead,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[6]
Large language models for software engineering: Sur- vey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Sur- vey and open problems,” in2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 2023, pp. 31–53
2023
-
[7]
Llms meet library evolution: Evaluating deprecated api usage in llm- based code completion,
C. Wang, K. Huang, J. Zhang, Y . Feng, L. Zhang, Y . Liu, and X. Peng, “Llms meet library evolution: Evaluating deprecated api usage in llm- based code completion,” in2025 ieee/acm 47th international conference on software engineering (icse). IEEE, 2025, pp. 885–897
2025
-
[8]
Is your llm outdated? a deep look at temporal generalization,
C. Zhu, N. Chen, Y . Gao, Y . Zhang, P. Tiwari, and B. Wang, “Is your llm outdated? a deep look at temporal generalization,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 7433–7457
2025
-
[9]
Humanevo: An evolution-aware benchmark for more realistic evalu- ation of repository-level code generation,
D. Zheng, Y . Wang, E. Shi, R. Zhang, Y . Ma, H. Zhang, and Z. Zheng, “Humanevo: An evolution-aware benchmark for more realistic evalu- ation of repository-level code generation,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1372–1384
2025
-
[10]
Libevolutioneval: A benchmark and study for version-specific code generation,
S. Kuhar, W. Ahmad, Z. Wang, N. Jain, H. Qian, B. Ray, M. K. Ra- manathan, X. Ma, and A. Deoras, “Libevolutioneval: A benchmark and study for version-specific code generation,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2...
2025
-
[11]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, L. Phanet al., “The wmdp benchmark: Measuring and reducing malicious use with unlearning,”arXiv preprint arXiv:2403.03218, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Model editing for llms4code: How far are we?
X. Li, S. Wang, S. Li, J. Ma, J. Yu, X. Liu, J. Wang, B. Ji, and W. Zhang, “Model editing for llms4code: How far are we?” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 937–949
2025
-
[13]
Lightweight model editing for llms to correct deprecated api recommendations,
G. Lin, X. Yu, J. Keung, X. Hu, X. Xia, and A. X. Liu, “Lightweight model editing for llms to correct deprecated api recommendations,” arXiv preprint arXiv:2511.21022, 2025
-
[15]
Large language model unlearning for source code,
X. Jiang, Y . Dong, H. Zhang, T. Wang, Z. Fang, Y . Ma, R. Cao, B. Li, Z. Jin, W. Jiaoet al., “Large language model unlearning for source code,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 37, 2026, pp. 31 346–31 355
2026
-
[16]
Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning,
Z. Chu, Y . Wan, Z. Zhang, D. Wang, Z. Yang, H. Zhang, P. Zhou, X. Shi, H. Jin, and D. Lo, “Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering, April 2026
2026
-
[17]
Regulation (EU) 2016/679 of the European Parliament and of the Council
C. Fan, J. Liu, L. Lin, J. Jia, R. Zhang, S. Mei, and S. Liu, “Simplicity prevails: Rethinking negative preference optimization for llm unlearn- ing,”arXiv preprint arXiv:2410.07163, 2024
-
[18]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Liet al., “Deepseek-coder: when the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
StarCoder 2 and The Stack v2: The Next Generation
A. Lozhkov, R. Li, L. B. Allal, F. Cassano, J. Lamy-Poirier, N. Tazi, A. Tang, D. Pykhtar, J. Liu, Y . Weiet al., “Starcoder 2 and the stack v2: The next generation,”arXiv preprint arXiv:2402.19173, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remezet al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Code- gen2: Lessons for training llms on programming and natural languages,
E. Nijkamp, H. Hayashi, C. Xiong, S. Savarese, and Y . Zhou, “Code- gen2: Lessons for training llms on programming and natural languages,” arXiv preprint arXiv:2305.02309, 2023
-
[22]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Towards knowledge alignment in code llms: Contrastive unlearning for evolving apis?
Anonymous, “Towards knowledge alignment in code llms: Contrastive unlearning for evolving apis?” https://figshare.com/s/ a8303a2ce6755cf25b0b, 2026, accessed: May 12, 2026
2026
-
[24]
An empirical study on the impact of refactoring activities on evolving client-used apis,
R. G. Kula, A. Ouni, D. M. German, and K. Inoue, “An empirical study on the impact of refactoring activities on evolving client-used apis,”Inf. Softw. Technol., vol. 93, no. C, p. 186–199, Jan. 2018. [Online]. Available: https://doi.org/10.1016/j.infsof.2017.09.007
-
[25]
Vulnerability detection with code language models: How far are we?
C. Wang, K. Huang, J. Zhang, Y . Feng, L. Zhang, Y . Liu, and X. Peng, “Llms meet library evolution: Evaluating deprecated api usage in llm-based code completion,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ser. ICSE ’25. IEEE Press, 2025, p. 885–897. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00245
-
[26]
Recode: Updating code api knowledge with reinforcement learning,
H. Wu, Y . Yao, W. Yu, and N. Zhang, “Recode: Updating code api knowledge with reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 40, 2026, pp. 33 908– 33 916
2026
-
[27]
Towards making systems forget with machine unlearning,
Y . Cao and J. Yang, “Towards making systems forget with machine unlearning,” in2015 IEEE symposium on security and privacy. IEEE, 2015, pp. 463–480
2015
-
[28]
Knowledge unlearning for mitigating privacy risks in language models,
J. Jang, D. Yoon, S. Yang, S. Cha, M. Lee, L. Logeswaran, and M. Seo, “Knowledge unlearning for mitigating privacy risks in language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 14 389– 14 408
2023
-
[29]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[30]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
R. Zhang, L. Lin, Y . Bai, and S. Mei, “Negative preference optimization: From catastrophic collapse to effective unlearning,”arXiv preprint arXiv:2404.05868, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
How and why llms use deprecated apis in code completion? an empirical study,
C. Wang, K. Huang, J. Zhang, Y . Feng, L. Zhang, Y . Liu, and X. Peng, “How and why llms use deprecated apis in code completion? an empirical study,” 06 2024
2024
-
[32]
Evaluating large language models in class-level code generation,
X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y . Chen, J. Feng, C. Sha, X. Peng, and Y . Lou, “Evaluating large language models in class-level code generation,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[33]
On the evaluation of large language models in unit test generation,
L. Yang, C. Yang, S. Gao, W. Wang, B. Wang, Q. Zhu, X. Chu, J. Zhou, G. Liang, Q. Wanget al., “On the evaluation of large language models in unit test generation,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1607–1619
2024
-
[34]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Transactions on Software Engineering and Methodology, vol. 35, no. 2, pp. 1–72, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.