Demystify, Use, Reflect, Assess (DURA): An Experience Report on LLM Integration in CS2
Pith reviewed 2026-07-01 01:06 UTC · model grok-4.3
The pith
The DURA framework lets CS2 students use LLMs while they keep seeking human help and engaging with course content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying the DURA sequence of demystifying LLMs, guiding their use with required attribution, inserting reflections at three points, and raising the stakes of proctored assessments while allowing retakes and adding assignment-linked questions, the course permitted LLM access while students continued to seek human assistance, monitor Piazza, review course content, and report strategic approaches to LLM use.
What carries the argument
The DURA framework (Demystify-Use-Reflect-Assess), a four-stage structure that sequences LLM introduction, guided practice, meta-cognitive reflection, and assessment redesign.
If this is right
- Students reported using LLMs for clarifying concepts, debugging code, understanding assignment guidelines, and generating test cases.
- Students continued to seek human assistance through office hours and TAs while monitoring course forums and reviewing materials.
- Students described thoughtful, strategic decisions about when and how to use LLMs.
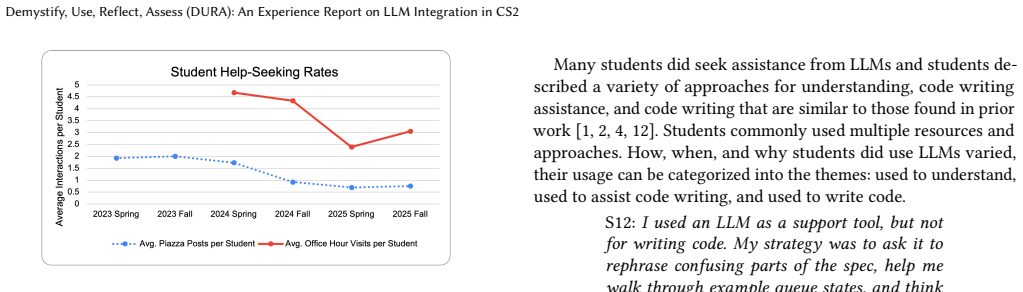
- Office-hour attendance increased slightly compared with prior semesters.
- Student ratings of instructor care for their learning rose.
- Students valued both the LLM guidance and the instructional content from course staff.
Where Pith is reading between the lines
- Similar staged integration might apply in other introductory computing courses that face the same access-to-LLMs pressure.
- The framework's emphasis on reflections could be tested for effects on long-term retention of programming concepts.
- Departments considering policy changes around AI tools could adopt the assessment-retake component as a low-cost first step.
- Instructors in non-computing fields might adapt the demystify-and-reflect sequence when introducing other generative tools.
Load-bearing premise
The shifts in student behavior and perceptions were produced by the DURA interventions rather than semester-specific factors, self-reporting bias, or population changes.
What would settle it
A follow-up semester run without the DURA components, or a side-by-side comparison of sections with and without the framework, measuring the same self-reported behaviors, office-hour counts, and perception survey items.
Figures
read the original abstract
Student access to Large Language Models (LLMs) is reshaping learning behaviors; at the same time students are entering the workforce where effective LLM use is becoming an expected skill. In this Experience Report we share our DURA framework (Demystify-Use-Reflect-Assess) and materials we used to restructure our CS2 course to allow the use of LLMs. We first demystified LLMs, then provided guidance on use with required attribution. We also added reflections related to LLM use at three points throughout the semester to encourage student meta-cognition around LLM use. We increased the value of proctored assessments in tandem with allowing retakes and including questions that explicitly assess skills from programming assignments. Students reported using LLMs for clarifying course concepts, debugging, understanding assignment guidelines, and determining test cases, but also still sought assistance via office hours and TAs, monitored Piazza, and reviewing course content. Students articulated thoughtful and strategic approaches to LLM use and also valued the instructional content and guidance from course staff. Student use of office hours increased slightly this semester and student perceptions that the instructor cares about them and their learning improved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is an experience report on the DURA framework (Demystify-Use-Reflect-Assess) implemented in one offering of CS2. The authors describe demystifying LLMs, providing usage guidance with required attribution, adding three reflection points on meta-cognition, and raising the weight of proctored assessments (with retakes and questions targeting assignment skills). From within-semester student self-reports the paper claims students used LLMs for clarifying concepts, debugging, understanding guidelines, and generating test cases, yet continued seeking human help via office hours and TAs, monitoring Piazza, and reviewing course materials; students articulated strategic approaches and valued staff guidance. The report notes a slight increase in office-hour attendance and improved student perceptions that the instructor cares about their learning.
Significance. If the reported behavioral and perceptual shifts are attributable to the interventions, the work supplies a concrete, replicable sequence of course-design changes plus shared materials that other CS instructors could adapt when deciding how to permit LLM use. The explicit provision of reflection prompts and assessment adjustments constitutes a practical contribution to the growing literature on LLM integration in introductory computing education.
major comments (2)
- [Abstract] Abstract: the statements that 'Student use of office hours increased slightly this semester and student perceptions that the instructor cares about them and their learning improved' are presented as outcomes of the DURA framework, yet no baseline attendance or perception numbers from prior semesters, no control section, and no statistical test for the 'slight' change are supplied; this absence directly undermines the causal attribution that is central to the claim of successful integration.
- [Results / Student Reports] Student self-reports section: all claims about continued human help-seeking, strategic LLM use, and monitoring of course content rest exclusively on unvalidated self-reports from a single cohort; no objective measures (exam scores, assignment performance, usage logs, or pre/post learning-outcome data) are reported to corroborate the behaviors or to rule out self-report bias.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experience report. We address each major comment below, noting revisions where the manuscript language or framing can be strengthened while remaining faithful to the single-cohort, self-report nature of the data.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statements that 'Student use of office hours increased slightly this semester and student perceptions that the instructor cares about them and their learning improved' are presented as outcomes of the DURA framework, yet no baseline attendance or perception numbers from prior semesters, no control section, and no statistical test for the 'slight' change are supplied; this absence directly undermines the causal attribution that is central to the claim of successful integration.
Authors: We agree that the abstract wording implies a causal outcome without supporting comparative evidence. As this is an experience report from one course offering with no prior baseline data collected, we will revise the abstract to describe the office-hour attendance and perception data as observations from the semester of DURA implementation, removing any direct attribution to the framework. We will also add an explicit limitations paragraph noting the absence of controls or statistical testing. revision: yes
-
Referee: [Results / Student Reports] Student self-reports section: all claims about continued human help-seeking, strategic LLM use, and monitoring of course content rest exclusively on unvalidated self-reports from a single cohort; no objective measures (exam scores, assignment performance, usage logs, or pre/post learning-outcome data) are reported to corroborate the behaviors or to rule out self-report bias.
Authors: The paper is framed as an experience report, for which student self-reports via reflections and end-of-semester surveys constitute the primary data source. No objective measures (logs, exam comparisons, or pre/post assessments) were collected for this offering. We will revise the results and discussion sections to more explicitly qualify all behavioral claims as student-reported, add a dedicated limitations subsection addressing self-report bias, and clarify that the core contribution is the replicable DURA framework and shared materials rather than verified causal effects. revision: partial
- We do not have baseline office-hour attendance or perception-survey data from prior semesters.
- No objective usage logs, exam-score comparisons, or pre/post learning-outcome data exist for this cohort to corroborate the self-reports.
Circularity Check
No circularity: purely descriptive experience report with no derivations or load-bearing self-citations
full rationale
The paper is an experience report on a single course offering. It contains no equations, fitted parameters, predictions, or mathematical derivations of any kind. All statements are direct observational reports of student self-reports, office-hour attendance, and perception surveys. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support any claim. The central observations (continued human help-seeking, strategic LLM use, slight attendance increase, improved perceptions) are presented as within-semester findings without reduction to prior inputs or self-referential definitions. This matches the default case of a self-contained descriptive paper with no circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matin Amoozadeh, Daye Nam, Daniel Prol, Ali Alfageeh, James Prather, Michael Hilton, Sruti Srinivasa Ragavan, and Amin Alipour. 2024. Student-ai interaction: A case study of CS1 students. InProceedings of the 24th Koli Calling International Conference on Computing Education Research. ACM, New York, NY, USA, 1–13
2024
-
[2]
Utkarsh Arora, Anupam Garg, Aryan Gupta, Samyak Jain, Ronit Mehta, Rupin Oberoi, Prachi, Aryaman Raina, Manav Saini, Sachin Sharma, Jaskaran Singh, Sarthak Tyagi, and Dhruv Kumar. 2025. Analyzing LLM Usage in an Advanced Computing Class in India. InProceedings of the 27th Australasian Computing Education Conference (ACE ’25). ACM, New York, NY, USA, 154–1...
-
[3]
Kesina Baral, Jeff Offutt, Paul Ammann, and Rasika Mohod. 2021. Practice makes better: quiz retake software to increase student learning. InProceedings of the 3rd International Workshop on Education through Advanced Software Engineering and Artificial Intelligence(Athens, Greece)(EASEAI 2021). ACM, New York, NY, USA, 47–53. doi:10.1145/3472673.3473965
-
[4]
Seth Bernstein, Ashfin Rahman, Nadia Sharifi, Ariunjargal Terbish, and Stephen MacNeil. 2025. Beyond the Benefits: A Systematic Review of the Harms and Consequences of Generative AI in Computing Education. InProceedings of the 25th Koli Calling International Conference on Computing Education Research. ACM, New York, NY, USA, 1–18. Demystify, Use, Reflect,...
2025
-
[5]
Bouvier et al
Dennis J. Bouvier et al . 2025. The Rest of the Robots: Generative AI in Post- introductory Computing Education. InProceedings of the 2025 Working Group Reports on Innovation and Technology in Computer Science Education (ITiCSE- WGR)
2025
-
[6]
Anael Kuperwajs Cohen, Alannah Oleson, and Amy J Ko. 2024. Factors influenc- ing the social help-seeking behavior of introductory programming students in a competitive university environment.ACM Transactions on Computing Education 24, 1 (2024), 1–27
2024
-
[7]
Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N
Paul Denny, James Prather, Brett A. Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N. Reeves, Eddie Antonio Santos, and Sami Sarsa. 2024. Computing Education in the Era of Generative AI.Commun. ACM67, 2 (2024), 56–67. doi:10.1145/3624720
-
[8]
2025.Digital Education Council AI Literacy Frame- work
Digital Education Council. 2025.Digital Education Council AI Literacy Frame- work. https://www.digitaleducationcouncil.com/post/digital-education-council- ai-literacy-framework Accessed: 25 April 2026
2025
-
[9]
Nikitha Donekal Chandrashekar, Sehrish Basir Nizamani, Margaret Ellis, and Naren Ramakrishnan. 2026. Demystify, Use, Reflect: Preparing students to be informed LLM-users. InProceedings of the 57th ACM Technical Symposium on Computer Science Education V. 2. 1299–1300
2026
-
[10]
Motahhare Eslami, Kristen Vaccaro, Min Kyung Lee, Amit Elazari Bar On, Eric Gilbert, and Karrie Karahalios. 2019. User Attitudes towards Algorithmic Opacity and Transparency in Online Reviewing Platforms. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk) (CHI ’19). Association for Computing Machinery, New...
-
[11]
2025.The Future of Programming in the Age of Large Language Models
Arjun Guha and Ben Zorn. 2025.The Future of Programming in the Age of Large Language Models. Technical Report. Computing Research Association, Washington, DC. https://cra.org/wp-content/uploads/2025/04/the-future-of- programming-in-the-age-of-large-language-models_April-2025.pdf
2025
-
[12]
Irene Hou, Sophia Mettille, Owen Man, Zhuo Li, Cynthia Zastudil, and Stephen MacNeil. 2024. The effects of generative ai on computing students’ help-seeking preferences. InProceedings of the 26th australasian computing education confer- ence. ACM, New York, NY, USA, 39–48
2024
-
[13]
Kaiyue Jia, Teresa H. M. Leung, Ngai Yan Irene Cheung, Yixun Li, and Junnan Yu
-
[14]
Developing a Holistic AI Literacy Framework for Children.ACM Trans. Comput. Educ.25, 2, Article 21 (June 2025), 30 pages. doi:10.1145/3727986
-
[15]
Brett D. Jones. n.d.. MUSIC Model of Academic Motivation: Questionnaires. https://www.themusicmodel.com/questionnaires/. Accessed April 18, 2026
2026
-
[16]
Kazemitabaar et al
M. Kazemitabaar et al . 2024. CodeHelp: Using Large Language Models with Guardrails for Scalable Support in Programming Classes. InProceedings of the ACM Conference on Learning @ Scale (L@S)
2024
-
[17]
Harsh Kumar, Ilya Musabirov, Mohi Reza, Jiakai Shi, Xinyuan Wang, Joseph Jay Williams, Anastasia Kuzminykh, and Michael Liut. 2024. Guiding Students in Using LLMs in Supported Learning Environments: Effects on Interaction Dynamics, Learner Performance, Confidence, and Trust.Proceedings of the ACM on Human-Computer Interaction8, CSCW2 (2024). doi:10.1145/3687038
-
[18]
2023.Big Change! AP CS Principles Performance Task
Jane Lee. 2023.Big Change! AP CS Principles Performance Task. https://blog. gocobi.com/big-change-ap-cs-principles-performance-task/ GoCobi Computer Science blog
2023
-
[19]
Duri Long and Brian Magerko. 2020. What is AI Literacy? Competencies and Design Considerations. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–16. doi:10.1145/3313831.3376727
-
[20]
Xiao Long, Xin Tan, Yinghao Zhu, Jing Jiang, and Li Zhang. 2025. Understanding and Enhancing CS Students’ Interaction Experience with AI Coding Assistant Tools.ACM Transactions on Software Engineering and Methodology(2025). doi:10. 1145/3785479
2025
-
[21]
Brandon Lowry, Samantha McGrath, Chad Eitel, Heather Hall, and Tod R Clapp
-
[22]
Journal of Microbiology and Biology Education(2025), e00153–25
Leveraging generative AI to foster metacognition and self-directed learning. Journal of Microbiology and Biology Education(2025), e00153–25
2025
-
[23]
Margulieux, James Prather, Brent N
Lauren E. Margulieux, James Prather, Brent N. Reeves, Brett A. Becker, Gozde Cetin Uzun, Dastyni Loksa, Juho Leinonen, and Paul Denny. 2024. Self- Regulation, Self-Efficacy, and Fear of Failure Interactions with How Novices Use LLMs to Solve Programming Problems. InProceedings of the 2024 on Inno- vation and Technology in Computer Science Education V. 1(M...
-
[24]
Marie Lynn Miranda. 2026. Higher education must bridge the AI gap.Science392, 6793 (2026), 5–5. arXiv:https://www.science.org/doi/pdf/10.1126/science.aeh5777 doi:10.1126/science.aeh5777
-
[25]
Davy Tsz Kit Ng, Jac Ka Lok Leung, Kai Wah Samuel Chu, and Maggie Shen Qiao
-
[26]
AI literacy: Definition, teaching, evaluation and ethical issues.Proceedings of the association for information science and technology58, 1 (2021), 504–509
2021
-
[27]
Vidushi Ojha, Andrea Watkins, Christopher Perdriau, Kathleen Isenegger, and Colleen M. Lewis. 2026. Transparent Teaching. InProceedings of the 57th ACM Technical Symposium on Computer Science Education V.2(USA)(SIGCSE TS 2026). Association for Computing Machinery, New York, NY, USA, 1739. doi:10.1145/ 3770761.3777041
-
[28]
Aadarsh Padiyath, Xinying Hou, Amy Pang, Diego Viramontes Vargas, Xingjian Gu, Tamara Nelson-Fromm, Zihan Wu, Mark Guzdial, and Barbara Ericson
-
[29]
InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1
Insights from social shaping theory: The appropriation of large language models in an undergraduate programming course. InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1. 114–130
2024
-
[30]
Aadarsh Padiyath, Jessica Shen, and Barbara Ericson. 2026. Self-Regulated Personal Contracts as a Harm Reduction Approach to Generative AI in Under- graduate Programming Education.arXiv preprintarXiv:2604.03256v1 (2026). https://arxiv.org/abs/2604.03256
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Jacob Penney, Pawan Acharya, Peter Hilbert, Priyanka Parekh, Anita Sarma, Igor Steinmacher, and Marco Gerosa. 2025. Understanding Programming Students’ Help-Seeking Preferences in the Era of Generative AI. InProceedings of the ACM Global on Computing Education Conference 2025 Vol 1. ACM, New York, NY, USA, 15–21
2025
-
[32]
Leo Porter, Cynthia Bailey Lee, Beth Simon, and Daniel Zingaro. 2011. Peer instruction: do students really learn from peer discussion in computing?. InPro- ceedings of the Seventh International Workshop on Computing Education Research (Providence, Rhode Island, USA)(ICER ’11). ACM, New York, NY, USA, 45–52. doi:10.1145/2016911.2016923
-
[33]
Prajish Prasad and Aamod Sane. 2024. A self-regulated learning framework using generative AI and its application in CS educational intervention design. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1. 1070–1076
2024
-
[34]
Becker, Michelle Craig, Paul Denny, Dastyni Loksa, and Lauren Margulieux
James Prather, Brett A. Becker, Michelle Craig, Paul Denny, Dastyni Loksa, and Lauren Margulieux. 2020. What Do We Think We Think We Are Doing? Metacognition and Self-Regulation in Programming. InProceedings of the 2020 ACM Conference on International Computing Education Research(Virtual Event, New Zealand)(ICER ’20). Association for Computing Machinery, ...
-
[35]
Reeves, Jaromir Savelka, David H
James Prather, Juho Leinonen, Natalie Kiesler, Jamie Gorson Benario, Sam Lau, Stephen MacNeil, Narges Norouzi, Simone Opel, Vee Pettit, Leo Porter, Brent N. Reeves, Jaromir Savelka, David H. Smith, Sven Strickroth, and Daniel Zingaro
-
[36]
Beyond the Hype: A Comprehensive Review of Current Trends in Genera- tive AI Research, Teaching Practices, and Tools. In2024 Working Group Reports on Innovation and Technology in Computer Science Education(Milan, Italy)(ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 300–338. doi:10.1145/3689187.3709614
-
[37]
James Prather, Brent N Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S Randri- anasolo, Brett A Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. 2024. The widening gap: The benefits and harms of generative ai for novice programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1. 469–486
2024
-
[38]
2016.Qualitative research: Analyzing life
Johnny Saldaña and Matt Omasta. 2016.Qualitative research: Analyzing life. Sage Publications, California, USA
2016
-
[39]
Piazza Technologies. [n. d.]. Piazza. https://piazza.com/ Accessed: 2026-01-16
2026
-
[40]
Annapurna Vadaparty, Daniel Zingaro, David H Smith IV, Mounika Padala, Chris- tine Alvarado, Jamie Gorson Benario, and Leo Porter. 2024. Cs1-llm: Integrating llms into cs1 instruction. InProceedings of the 2024 on Innovation and Technology in Computer Science Education v. 1. 297–303
2024
-
[41]
Tammy VanDeGrift, Tamara Caruso, Natalie Hill, and Beth Simon. 2011. Ex- perience report: getting novice programmers to THINK about improving their software development process. InProceedings of the 42nd ACM Technical Sympo- sium on Computer Science Education(Dallas, TX, USA)(SIGCSE ’11). ACM, New York, NY, USA, 493–498. doi:10.1145/1953163.1953307
-
[42]
Barry J Zimmerman. 2002. Becoming a self-regulated learner: An overview. Theory into practice41, 2 (2002), 64–70
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.