PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
Pith reviewed 2026-07-01 01:23 UTC · model grok-4.3
The pith
PhotoQuilt generates arbitrary-resolution photomosaics without training by bootstrapping a low-resolution layout into tiled denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
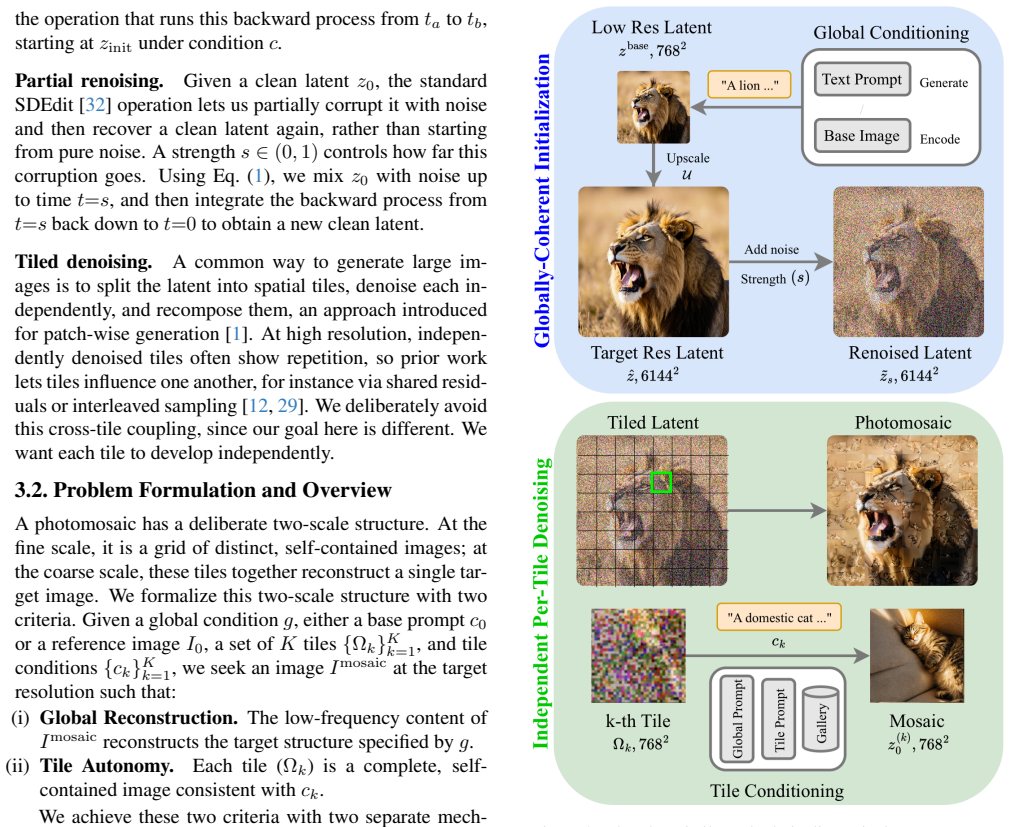
PhotoQuilt resolves this with a bootstrapped tiled denoising procedure. We first produce a global composition at low resolution to fix the layout, then upscale it in latent space and re-inject noise to restore generative capacity. Denoising proceeds within fixed tiles, so each forms its own image while the shared global structure holds them in one layout. Because tile generation is handled separately, PhotoQuilt scales to large canvases without quadratic attention cost.
What carries the argument
Bootstrapped tiled denoising procedure that creates a low-resolution global layout, upscales it in latent space, re-injects noise, and then performs independent per-tile denoising.
If this is right
- The method produces photomosaics at any resolution while preserving both global structure and local realism.
- No training or fine-tuning steps are required beyond a standard diffusion model.
- Generation cost remains linear in the number of tiles rather than quadratic in canvas size.
- The same low-resolution layout can be reused to generate multiple high-resolution variants of the same mosaic.
Where Pith is reading between the lines
- The same bootstrapping pattern could be tested on other diffusion tasks that require both coarse structure and fine local variation, such as large scene or texture synthesis.
- If the noise re-injection step proves robust, it may reduce the need for specialized high-resolution training runs in other structured image generation settings.
- The separation of global layout from tile denoising opens a route to parallel or distributed generation of very large canvases.
Load-bearing premise
That upscaling the low-resolution global composition in latent space followed by noise re-injection will allow independent per-tile denoising to preserve the global layout without any additional training or fine-tuning steps.
What would settle it
Run the low-resolution global stage, upscale and re-inject noise, then complete per-tile denoising and check whether the final high-resolution tiles still match the original global layout within a small tolerance.
Figures




read the original abstract
Photomosaics are large images whose local regions are seen as independent tiles while their overall arrangement forms a coherent scene. Generating them at high resolution, with every tile convincing in its own right, is computationally expensive, since the canvas must hold many detailed tiles at once. We present PhotoQuilt, a training-free framework that generates photomosaics at arbitrary resolution. Diffusion models struggle to satisfy both scales at once, as direct high-resolution generation is costly and tends toward one smooth image rather than a mosaic, while patch-based tiling keeps local detail but loses global structure. PhotoQuilt resolves this with a bootstrapped tiled denoising procedure. We first produce a global composition at low resolution to fix the layout, then upscale it in latent space and re-inject noise to restore generative capacity. Denoising proceeds within fixed tiles, so each forms its own image while the shared global structure holds them in one layout. Because tile generation is handled separately, PhotoQuilt scales to large canvases without quadratic attention cost. Experiments show that PhotoQuilt outperforms current baselines on both global structure and local realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PhotoQuilt, a training-free framework for arbitrary-resolution photomosaics with diffusion models. It first generates a low-resolution global composition to fix layout, upsamples the latent, re-injects noise to restore capacity, then runs independent denoising inside fixed non-overlapping tiles so each tile forms its own image while the shared global structure is claimed to hold the layout. The method is positioned as avoiding quadratic attention costs of full-canvas generation and as outperforming baselines on global structure and local realism.
Significance. If the upscaled latent successfully constrains independent tile trajectories after noise re-injection, the approach would provide a practical route to scalable, training-free generation of large structured images. The training-free and arbitrary-resolution aspects are genuine strengths that address real computational bottlenecks in diffusion models for mosaic-style outputs.
major comments (2)
- [Bootstrapped tiled denoising procedure] The bootstrapped tiled denoising procedure (described in the abstract) states that after latent upscaling and noise re-injection, 'denoising proceeds within fixed tiles' with no overlap, cross-tile attention, or consistency loss mentioned. This leaves no explicit mechanism by which the global latent can dominate per-tile stochastic trajectories, which is load-bearing for the central claim that global structure survives.
- [Experiments] The abstract asserts that 'Experiments show that PhotoQuilt outperforms current baselines on both global structure and local realism' yet supplies no metrics, baselines, datasets, ablation results, or quantitative tables. Without these, the empirical support for the two main performance claims cannot be assessed.
minor comments (1)
- Notation for the latent upscaling step and the precise noise re-injection schedule would benefit from an equation or pseudocode block for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Bootstrapped tiled denoising procedure] The bootstrapped tiled denoising procedure (described in the abstract) states that after latent upscaling and noise re-injection, 'denoising proceeds within fixed tiles' with no overlap, cross-tile attention, or consistency loss mentioned. This leaves no explicit mechanism by which the global latent can dominate per-tile stochastic trajectories, which is load-bearing for the central claim that global structure survives.
Authors: The mechanism is the shared upscaled latent: the low-resolution global composition is first generated to fix layout, then upscaled in latent space to provide a common structured initialization for every tile. Noise is re-injected uniformly to restore generative capacity while preserving the encoded global arrangement in the starting latent of each independent tile. Although denoising runs separately with no cross-tile operations, all trajectories begin from the same layout-conditioned latent, which biases outputs toward the fixed global structure. We will revise the method section to make this initialization process explicit, including a diagram of the latent flow from global upscaling to per-tile starting points. revision: yes
-
Referee: [Experiments] The abstract asserts that 'Experiments show that PhotoQuilt outperforms current baselines on both global structure and local realism' yet supplies no metrics, baselines, datasets, ablation results, or quantitative tables. Without these, the empirical support for the two main performance claims cannot be assessed.
Authors: The current manuscript focuses on qualitative visual comparisons in the experiments. We agree that quantitative support is needed to substantiate the claims and will expand the section with specific baselines (e.g., naive high-resolution diffusion and overlapping patch tiling), datasets, metrics for global structure (layout consistency via keypoint matching or segmentation alignment) and local realism (perceptual metrics such as LPIPS or user studies), plus ablations on noise re-injection strength and tile size. revision: yes
Circularity Check
No circularity: procedural method with independent empirical validation
full rationale
The paper presents a training-free algorithmic procedure (low-res global composition, latent upscaling, noise re-injection, then independent tiled denoising) whose correctness is asserted via experiments on global structure and local realism rather than any derivation chain. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or described method; the central claim does not reduce to a redefinition or statistical forcing of its inputs. The approach is therefore self-contained and externally falsifiable on standard image metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can produce coherent local images when denoising proceeds from partially noised latents that carry global structure.
Reference graph
Works this paper leans on
-
[1]
MultiDiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. MultiDiffusion: Fusing diffusion paths for controlled image generation. InProceedings of the 40th International Confer- ence on Machine Learning (ICML), pages 1737–1752, 2023. 3, 4
2023
-
[2]
A survey of digital mosaic techniques
Sebastiano Battiato, Gianpiero Di Blasi, Giovanni Maria Farinella, and Giovanni Gallo. A survey of digital mosaic techniques. InEurographics Italian Chapter Conference,
-
[3]
FLUX: Text-to-image generation model
Black Forest Labs. FLUX: Text-to-image generation model. https : / / github . com / black - forest - labs / flux, 2024. Released August 2024. 3, 5, 12
2024
-
[4]
FLUX.1 tools: Redux, fill, depth, canny
Black Forest Labs. FLUX.1 tools: Redux, fill, depth, canny. https://bfl.ai/flux-1-tools/, 2024. Released November 2024. 3, 12
2024
-
[5]
FLUX.2: Frontier visual intelligence
Black Forest Labs. FLUX.2: Frontier visual intelligence. https : / / github . com / black - forest - labs / flux2, 2025. Released November 2025. 3, 5, 12
2025
-
[6]
FLUX.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. FLUX.1 kontext: Flow matching for in-context i...
-
[7]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 2
2023
-
[8]
PixArt-α: Fast training of diffusion transformer for photorealistic text-to-image syn- thesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. PixArt-α: Fast training of diffusion transformer for photorealistic text-to-image syn- thesis. InInternational Conference on Learning Represen- tations (ICLR), 2024. 3
2024
-
[9]
Gen- erative photomosaic with structure-aligned and personalized diffusion, 2026
Jaeyoung Chung, Hyunjin Son, and Kyoung Mu Lee. Gen- erative photomosaic with structure-aligned and personalized diffusion, 2026. 2, 5, 12
2026
-
[10]
Evolution of animated photomosaics
Vic Ciesielski, Marsha Berry, Karen Trist, and Daryl D’Souza. Evolution of animated photomosaics. InWork- shops on Applications of Evolutionary Computation, pages 498–507. Springer, 2007. 2
2007
-
[11]
Diffusion-based image mo- saics
Lars Doyle and David Mould. Diffusion-based image mo- saics. InProceedings of Graphics Interface, New York, NY , USA, 2026. Association for Computing Machinery. 2, 3
2026
-
[12]
DemoFusion: Democratising high- resolution image generation with no $$$
Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, and Zhanyu Ma. DemoFusion: Democratising high- resolution image generation with no $$$. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6159–6168, 2024. 3, 4
2024
-
[13]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Ma- chine Learning...
2024
-
[14]
Image mosaics
Adam Finkelstein and Marisa Range. Image mosaics. In Electronic Publishing, Artistic Imaging, and Digital Typog- raphy (RIDT), pages 11–22. Springer, 1998. 2, 5, 12
1998
-
[15]
Visual ana- grams: Generating multi-view optical illusions with diffu- sion models
Daniel Geng, Inbum Park, and Andrew Owens. Visual ana- grams: Generating multi-view optical illusions with diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[16]
Factorized diffusion: Perceptual illusions by noise decomposition
Daniel Geng, Inbum Park, and Andrew Owens. Factorized diffusion: Perceptual illusions by noise decomposition. In European Conference on Computer Vision (ECCV), 2024. 2
2024
-
[17]
Lens: Rethinking training efficiency for foundational text-to-image models, 2026
Baining Guo, Chong Luo, Dong Chen, Dongdong Chen, Fangyun Wei, Ji Li, Jianmin Bao, Jiawei Zhang, Jinjing Zhao, Lei Shi, Qinhong Yang, Sirui Zhang, Xiuyu Wu, Xuelu Feng, Yan Lu, Yanchen Dong, Yang Yue, Yitong Wang, Yunuo Chen, Zhiyang Liang, and Ziyu Wan. Lens: Rethinking training efficiency for foundational text-to-image models, 2026. 3
2026
-
[18]
Compos- ing photomosaic images using clustering based evolutionary programming.Multimedia Tools and Applications, 78(18): 25919–25936, 2019
Yaodong He, Jianfeng Zhou, and Shiu Yin Yuen. Compos- ing photomosaic images using clustering based evolutionary programming.Multimedia Tools and Applications, 78(18): 25919–25936, 2019. 2
2019
-
[19]
ScaleCrafter: Tuning-free higher- resolution visual generation with diffusion models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, and Ying Shan. ScaleCrafter: Tuning-free higher- resolution visual generation with diffusion models. InIn- ternational Conference on Learning Representations (ICLR),
-
[20]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
2020
-
[21]
FouriScale: A frequency perspective on training-free high-resolution im- age synthesis
Linjiang Huang, Rongyao Fang, Aiping Zhang, Guanglu Song, Si Liu, Yu Liu, and Hongsheng Li. FouriScale: A frequency perspective on training-free high-resolution im- age synthesis. InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[22]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 1501–1510, 2017. 5, 12
2017
-
[23]
Ideogram 4.0: An open-weight text-to-image foundation model.https : / / huggingface
Ideogram. Ideogram 4.0: An open-weight text-to-image foundation model.https : / / huggingface . co / ideogram-ai, 2026. Open-weight release, June 2026. 3
2026
-
[24]
DiffuseHigh: Training-free progressive high- resolution image synthesis through structure guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, and Eun- byung Park. DiffuseHigh: Training-free progressive high- resolution image synthesis through structure guidance. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4338–4346, 2025. 3
2025
-
[25]
StreamDiffu- sion: A pipeline-level solution for real-time interactive gen- eration, 2023
Akio Kodaira, Chenfeng Xu, Toshiki Hazama, Takanori Yoshimoto, Kohei Ohno, Shogo Mitsuhori, Soichi Sugano, Hanying Cho, Zhijian Liu, and Kurt Keutzer. StreamDiffu- sion: A pipeline-level solution for real-time interactive gen- eration, 2023. 5, 12
2023
-
[26]
ScaleDiff: Higher-resolution image syn- 9 thesis via efficient and model-agnostic diffusion
Sungho Koh, SeungJu Cha, Hyunwoo Oh, Kwanyoung Lee, and Dong-Jin Kim. ScaleDiff: Higher-resolution image syn- 9 thesis via efficient and model-agnostic diffusion. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[27]
Diffusion- based image-to-image translation by noise correction via prompt interpolation
Junsung Lee, Minsoo Kang, and Bohyung Han. Diffusion- based image-to-image translation by noise correction via prompt interpolation. InEuropean Conference on Computer Vision, pages 289–304. Springer, 2024. 5
2024
-
[28]
BLIP: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation. InIn- ternational Conference on Machine Learning (ICML), pages 12888–12900, 2022. 5
2022
-
[29]
AccDiffusion: An accurate method for higher-resolution im- age generation
Zhihang Lin, Mingbao Lin, Meng Zhao, and Rongrong Ji. AccDiffusion: An accurate method for higher-resolution im- age generation. InEuropean Conference on Computer Vision (ECCV), 2024. 3, 4
2024
-
[30]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. 3
2023
-
[31]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. 3
2023
-
[32]
SDEdit: Guided image synthesis and editing with stochastic differential equa- tions
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equa- tions. InInternational Conference on Learning Representa- tions (ICLR), 2022. 3, 4
2022
-
[33]
T2I- Adapter: Learning adapters to dig out more controllable abil- ity for text-to-image diffusion models, 2023
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2I- Adapter: Learning adapters to dig out more controllable abil- ity for text-to-image diffusion models, 2023. 3, 5
2023
-
[34]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023. 3
2023
-
[35]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInternational Confer- ence on Learning Representations, pages 1862–1874, 2024. 2, 3
2024
-
[36]
FreeScale: Unleashing the resolution of diffusion models via tuning-free scale fusion
Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, and Ziwei Liu. FreeScale: Unleashing the resolution of diffusion models via tuning-free scale fusion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[37]
Learning transferable vi- sual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable vi- sual models from natural language supervision. InInter- national Conference on Machine Learning (ICML), pages 8748–8763, 2021. 5
2021
-
[38]
SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
Javad Rajabi, Kimia Shaban, Koorosh Roohi, David B Lin- dell, and Babak Taati. Sega: Spectral-energy guided atten- tion for resolution extrapolation in diffusion transformers. arXiv preprint arXiv:2605.22668, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 3, 5, 12
2022
-
[40]
Color alignment in diffusion
Ka Chun Shum, Binh-Son Hua, Duc Thanh Nguyen, and Sai- Kit Yeung. Color alignment in diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28446–28455, 2025. 3
2025
-
[41]
Henry Holt and Co., 1997
Robert Silvers and Michael Hawley.Photomosaics. Henry Holt and Co., 1997. 2, 5, 12
1997
-
[42]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[43]
Is one GPU enough? pushing image generation at higher-resolutions with founda- tion models
Athanasios Tragakis, Marco Aversa, Chaitanya Kaul, Roder- ick Murray-Smith, and Daniele Faccio. Is one GPU enough? pushing image generation at higher-resolutions with founda- tion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3
2024
-
[44]
Chan, and Chen Change Loy
Jianyi Wang, Kelvin C.K. Chan, and Chen Change Loy. Ex- ploring CLIP for assessing the look and feel of images. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 2555–2563, 2023. 5
2023
-
[45]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
2004
-
[46]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report, 2025. 3
2025
-
[47]
Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. InInternational Conference on Learning Representations (ICLR), 2024. 5
2024
-
[48]
SANA: Efficient high-resolution image synthesis with linear diffusion transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. SANA: Efficient high-resolution image synthesis with linear diffusion transformers. InIn- ternational Conference on Learning Representations (ICLR),
-
[49]
ImageRe- ward: Learning and evaluating human preferences for text- to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qing- hao Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageRe- ward: Learning and evaluating human preferences for text- to-image generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 5
2023
-
[50]
IP- Adapter: Text compatible image prompt adapter for text-to- image diffusion models, 2023
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP- Adapter: Text compatible image prompt adapter for text-to- image diffusion models, 2023. 3
2023
-
[51]
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23464– 23473, 2025. 5 10
2025
-
[52]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 2, 3
2023
-
[53]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5
2018
-
[54]
Interior of Notre-Dame cathedral, soaring gothic rib vaults, shafts of colored light, stone columns, architectural photograph
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, and Jiajun Liang. HiDiffusion: Unlocking higher-resolution creativity and efficiency in pretrained dif- fusion models. InEuropean Conference on Computer Vision (ECCV), pages 145–161, 2024. 3 11 Supplementary Material A. Implementation Details All experiments were executed on NVIDIA H100 GPUs. Wh...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.