Beyond the Library: An Agentic Framework for Autoformalizing Research Mathematics
Pith reviewed 2026-07-01 05:52 UTC · model grok-4.3
The pith
An agentic system using general coding LLMs autoformalizes main theorems and proofs from research papers into Lean 4 by dynamically adding and validating new type definitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
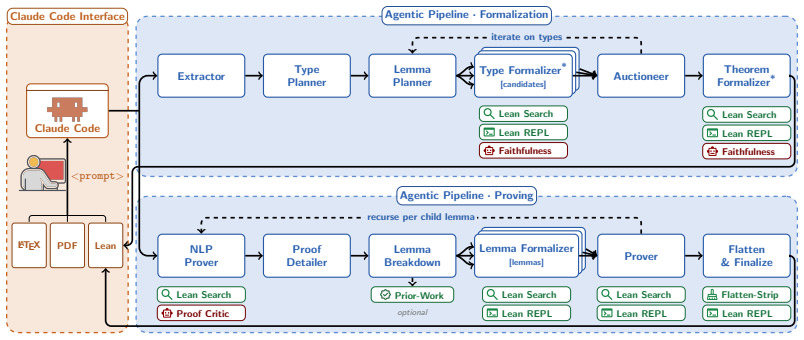
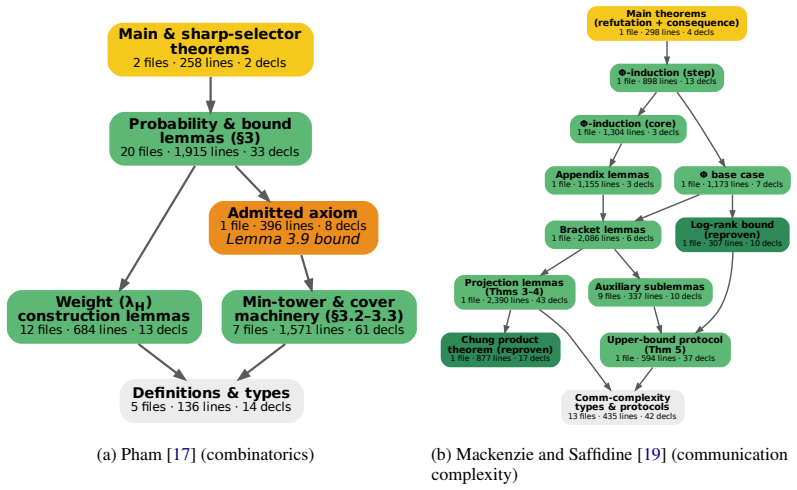
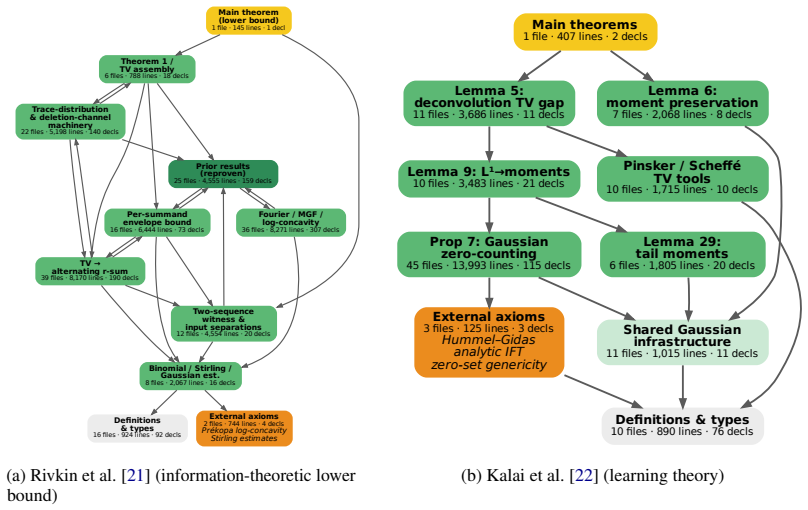
The agentic autoformalization framework, powered by general coding LLMs and centered on an orchestrator that manages a multi-agent pipeline, successfully formalizes the main theorems and proofs of five STOC papers into Lean 4 after dynamically extending necessary type definitions and validating them via the Auxiliary Lemma technique; the same system also produces formalizations for 32 PutnamBench problems, with all outputs validated by human experts and two STOC proofs using only Lean's kernel axioms.
What carries the argument
The orchestrator that manages a multi-agent pipeline for autoformalization, using the Auxiliary Lemma technique to validate newly introduced type definitions before formalizing primary theorems.
If this is right
- Research-level theorems in combinatorics, communication complexity, mechanism design, and learning theory can be accompanied by machine-checked Lean proofs.
- Two of the five STOC formalizations require no axioms beyond Lean's kernel, indicating that minimal-axiom proofs are achievable for some results.
- General-purpose coding LLMs can be orchestrated to outperform specialized Lean models on autoformalization of recent papers.
- Putnam-level problems can be turned into machine-checked Lean proofs using the same pipeline.
Where Pith is reading between the lines
- If the Auxiliary Lemma method scales, future papers could be written with an accompanying formalization step that catches errors before submission.
- The framework's success on STOC papers suggests it could be applied to other conference series to build a growing corpus of verified research results.
- Combining this approach with interactive theorem-proving interfaces might let authors iteratively refine both informal and formal versions of their arguments in one workflow.
Load-bearing premise
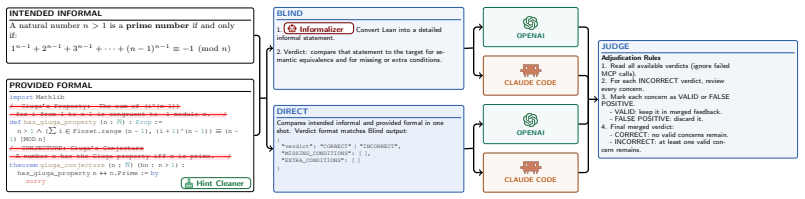
The Auxiliary Lemma technique reliably validates newly introduced type definitions for concepts outside Mathlib without introducing undetected errors that would invalidate the subsequent formalization of the primary theorems.
What would settle it
A STOC paper where a new type definition passes Auxiliary Lemma validation yet produces a Lean formalization that experts later find contains an undetected logical error in the main theorem.
Figures


read the original abstract
While Large Language Models (LLMs) have demonstrated exceptional capabilities in mathematical reasoning, they frequently produce subtle errors that evade human detection. Formal mathematical languages like Lean 4 offer mechanical proof checking, strongly motivating the need for autoformalization: the automatic translation of natural language mathematics into verifiable code. Recent trends indicate that general-purpose LLMs, heavily optimized for standard programming, now outperform smaller models explicitly fine-tuned for Lean. Leveraging this shift, we introduce an agentic autoformalization framework powered by general coding LLMs. At the core of our system is an orchestrator that manages a multi-agent pipeline tailored for research-level mathematics. Because cutting-edge research frequently relies on concepts outside the scope of existing libraries like Mathlib, our system dynamically extends necessary type definitions and validates them via a novel Auxiliary Lemma technique before formalizing the primary theorems. We applied our approach to PutnamBench, producing machine-checked Lean proofs for a random sample of 32 problems. Furthermore, we evaluate our system on five papers from the ACM Symposium on Theory of Computing (STOC) spanning combinatorics, communication complexity, mechanism design, and learning theory, successfully formalizing their main theorems and validating the generated formalizations with human experts; for all five we also formalize the proofs alongside the statements, and notably two of them are proved with no axioms beyond Lean's kernel. All of our formalizations are available at https://beyondthelibrary.github.io/formal_arxiv .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an agentic multi-LLM framework for autoformalizing research mathematics into Lean 4. Its core contribution is an orchestrator that dynamically extends Mathlib with new type definitions for concepts outside existing libraries and validates them via a novel Auxiliary Lemma technique before formalizing theorems and proofs. The system is evaluated on a random sample of 32 PutnamBench problems and five STOC papers (combinatorics, communication complexity, mechanism design, learning theory), producing machine-checked formalizations of main theorems and proofs; human experts validated the outputs, and two STOC formalizations require no axioms beyond Lean's kernel. All artifacts are released at the provided GitHub site.
Significance. If the central results hold, the work would be a meaningful step toward research-level autoformalization, particularly by addressing the library-extension barrier that has limited prior systems. The machine-checked proofs on external benchmarks (PutnamBench, STOC papers) with independent human review, plus the release of all formalizations, strengthen the contribution relative to purely informal LLM demonstrations.
major comments (2)
- [Abstract; Auxiliary Lemma technique section] Abstract (paragraph on dynamic extension) and the section describing the Auxiliary Lemma technique: the claim that this technique reliably validates newly introduced type definitions for research concepts is load-bearing for the five STOC results, yet the manuscript supplies neither an independent soundness argument nor an exhaustive enumeration of potential failure modes (e.g., undetected missing axioms or inconsistent type extensions) that could invalidate subsequent kernel-checked proofs.
- [Evaluation on PutnamBench and STOC papers] Evaluation sections on PutnamBench and STOC papers: the reported successes are presented without quantitative error rates, failure-case breakdowns, or ablation results on the multi-agent pipeline components, leaving the strength of empirical support for the framework's reliability moderate despite the external benchmarks and human validation.
minor comments (2)
- [System architecture] The description of the orchestrator's agent roles and hand-off protocols would benefit from a single consolidated diagram or pseudocode listing the exact sequence of LLM calls and validation steps.
- [Introduction / Method] Minor notation inconsistency: the term "Auxiliary Lemma technique" is introduced without a formal definition or pseudocode in the first occurrence, making the subsequent claims harder to parse on first reading.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below, indicating planned revisions where appropriate to strengthen the discussion of our methods and evaluation.
read point-by-point responses
-
Referee: [Abstract; Auxiliary Lemma technique section] Abstract (paragraph on dynamic extension) and the section describing the Auxiliary Lemma technique: the claim that this technique reliably validates newly introduced type definitions for research concepts is load-bearing for the five STOC results, yet the manuscript supplies neither an independent soundness argument nor an exhaustive enumeration of potential failure modes (e.g., undetected missing axioms or inconsistent type extensions) that could invalidate subsequent kernel-checked proofs.
Authors: The Auxiliary Lemma technique validates new type definitions by requiring the generation and kernel-checked proof of lemmas that capture their intended mathematical properties before they are used in theorem statements. This provides an empirical rather than meta-theoretic guarantee, as a formal soundness argument would necessitate reasoning about LLM behavior that lies beyond the paper's scope. We will revise the Auxiliary Lemma section to include an explicit enumeration of potential failure modes (such as undetected missing axioms or inconsistent extensions) and clarify how human expert validation of the final formalizations serves as an additional safeguard. We will also update the abstract to note that validation is empirical and supported by expert review. revision: partial
-
Referee: [Evaluation on PutnamBench and STOC papers] Evaluation sections on PutnamBench and STOC papers: the reported successes are presented without quantitative error rates, failure-case breakdowns, or ablation results on the multi-agent pipeline components, leaving the strength of empirical support for the framework's reliability moderate despite the external benchmarks and human validation.
Authors: The evaluation prioritizes demonstrating successful machine-checked formalizations on external research-level benchmarks (PutnamBench sample and STOC papers), each independently reviewed by human experts, rather than exhaustive error statistics. We agree that additional context on reliability would be beneficial and will add a subsection summarizing observed failure modes encountered during development (e.g., challenges in library extension or proof search) along with any quantitative metrics available from our experimental logs. Full component ablations are resource-intensive given the integrated pipeline and high cost per formalization, but we will discuss the contribution of each agent based on iterative testing. The kernel-checked proofs and expert validation remain the primary evidence of correctness. revision: partial
Circularity Check
No significant circularity; evaluations rely on external benchmarks and human review
full rationale
The paper presents an agentic framework for autoformalization and evaluates it on independent external benchmarks (PutnamBench sample and five STOC papers) with human expert validation of the generated Lean formalizations. The Auxiliary Lemma technique is introduced as a novel method for validating dynamic type extensions, but the central results (successful formalization of main theorems, including two kernel-only proofs) are not derived by fitting parameters to the evaluation data, nor do they reduce to self-citations or self-definitional steps. The derivation chain consists of system design choices justified by performance on held-out research papers rather than any closed loop where outputs are constructed from the same inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption General-purpose coding LLMs can be orchestrated to perform autoformalization of research mathematics
invented entities (1)
-
Auxiliary Lemma technique
no independent evidence
Reference graph
Works this paper leans on
-
[1]
David P Woodruff, Vincent Cohen-Addad, Lalit Jain, Jieming Mao, Song Zuo, Mohammad- Hossein Bateni, Simina Branzei, Michael P Brenner, Lin Chen, Ying Feng, et al. Acceler- ating scientific research with gemini: Case studies and common techniques.arXiv preprint arXiv:2602.03837, 2026
-
[2]
The dawn after the dark: An empirical study on factuality hallucination in large language models
Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. The dawn after the dark: An empirical study on factuality hallucination in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10879–10899, 2024
2024
-
[3]
The lean 4 theorem prover and programming language (system description)
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language (system description)
-
[4]
Numina-lean- agent: An open and general agentic reasoning system for formal mathematics, 2026
Junqi Liu, Zihao Zhou, Zekai Zhu, Marco Dos Santos, Weikun He, Jiawei Liu, Ran Wang, Yunzhou Xie, Junqiao Zhao, Qiufeng Wang, et al. Numina-Lean-Agent: An open and general agentic reasoning system for formal mathematics.arXiv preprint arXiv:2601.14027, 2026
-
[5]
A Minimal Agent for Automated Theorem Proving
Borja Requena Pozo, Austin Letson, Krystian Nowakowski, Izan Beltran Ferreiro, and Leopoldo Sarra. A minimal agent for automated theorem proving, 2026. URL https://arxiv.org/ abs/2602.24273
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Agentic proof automation: A case study.arXiv preprint arXiv:2601.03768, 2026
Yichen Xu and Martin Odersky. Agentic proof automation: A case study.arXiv preprint arXiv:2601.03768, 2026
-
[7]
Yuanjie Ren, Jinzheng Li, and Yidi Qi. MerLean: An agentic framework for autoformalization in quantum computation.arXiv preprint arXiv:2602.16554, 2026
-
[8]
Zichen Wang, Wanli Ma, Zhenyu Ming, Gong Zhang, Kun Yuan, and Zaiwen Wen. M2F: Automated formalization of mathematical literature at scale.arXiv preprint arXiv:2602.17016, 2026
-
[9]
Jiangjie Chen, Wenxiang Chen, Jiacheng Du, Jinyi Hu, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Wenlei Shi, et al. Seed-prover 1.5: Mastering undergraduate-level theorem proving via learning from experience.arXiv preprint arXiv:2512.17260, 2025
-
[10]
Sumanth Varambally, Thomas V oice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. Hilbert: Recursively building formal proofs with informal reasoning.arXiv preprint arXiv:2509.22819, 2025
-
[11]
Aristotle: IMO-level Automated Theorem Proving
Tudor Achim, Alex Best, Alberto Bietti, Kevin Der, Mathis Fédérico, Sergei Gukov, Daniel Halpern-Leistner, Kirsten Henningsgard, Yury Kudryashov, Alexander Meiburg, Martin Michelsen, Riley Patterson, Eric Rodriguez, Laura Scharff, Vikram Shanker, Vladmir Sicca, Hari Sowrirajan, Aidan Swope, Matyas Tamas, Vlad Tenev, Jonathan Thomm, Harold Williams, and La...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
URL http://arxiv.org/abs/ 1910.09336
The lean mathematical library.CoRR, abs/1910.09336, 2019. URL http://arxiv.org/abs/ 1910.09336
-
[13]
Pearson Education India, 2011
Ian Sommerville.Software engineering, 9/E. Pearson Education India, 2011
2011
-
[14]
Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, et al. An empirical study of unit test generation with large language models.arXiv preprint arXiv:2406.18181, 2024
-
[15]
Autoformalizer with tool feedback
Qi Guo, Jianing Wang, Jianfei Zhang, Deyang Kong, Xiangzhou Huang, Xiangyu Xi, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, and Wei Ye. Autoformalizer with tool feedback, 2025. URLhttps://arxiv.org/abs/2510.06857
-
[16]
arXiv preprint arXiv:2507.15225 , year =
Yichi Zhou, Jianqiu Zhao, Yongxin Zhang, Bohan Wang, Siran Wang, Luoxin Chen, Jiahui Wang, Haowei Chen, Allan Jie, Xinbo Zhang, Haocheng Wang, Luong Trung, Rong Ye, Phan Nhat Hoang, Huishuai Zhang, Peng Sun, and Hang Li. Solving formal math problems by decomposition and iterative reflection.arXiv preprint arXiv:2507.15225, 2025. 13
-
[17]
A sharp version of talagrand’s selector process conjecture and an application to rounding fractional covers
Huy Tuan Pham. A sharp version of talagrand’s selector process conjecture and an application to rounding fractional covers. InProceedings of the 57th Annual ACM Symposium on Theory of Computing, pages 322–328, 2025
2025
-
[18]
Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition.Advances in Neural Information Processing Systems, 37:11545–11569, 2024
George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition.Advances in Neural Information Processing Systems, 37:11545–11569, 2024
2024
-
[19]
Refuting the direct sum conjecture for total functions in deterministic communication complexity
Simon Mackenzie and Abdallah Saffidine. Refuting the direct sum conjecture for total functions in deterministic communication complexity. InProceedings of the 57th Annual ACM Symposium on Theory of Computing, 2025
2025
-
[20]
Approximation guarantees of median mechanism in Rd
Nikolai Gravin and Jianhao Jia. Approximation guarantees of median mechanism in Rd. In Proceedings of the 57th Annual ACM Symposium on Theory of Computing, pages 495–506, 2025
2025
-
[21]
A generalized trace reconstruction problem: Recovering a string of probabilities
Joey Rivkin, Gregory Valiant, and Paul Valiant. A generalized trace reconstruction problem: Recovering a string of probabilities. InProceedings of the 57th Annual ACM Symposium on Theory of Computing, pages 1657–1667, 2025
2025
-
[22]
Efficiently learning mixtures of two gaussians
Adam Tauman Kalai, Ankur Moitra, and Gregory Valiant. Efficiently learning mixtures of two gaussians. InProceedings of the 42nd Annual ACM Symposium on Theory of Computing, pages 553–562, 2010
2010
-
[23]
Aleph ai solves 99.4 % of PutnamBench, topping the leader- board
Logical Intelligence. Aleph ai solves 99.4 % of PutnamBench, topping the leader- board. Blog post, 2026. URL https://logicalintelligence.com/blog/ aleph-solves-putnambench. Aleph agent powered by GPT-5.2; 668/672 problems solved on PutnamBench
2026
-
[24]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, et al. Kimina-prover preview: Towards large formal reasoning models with reinforcement learning.arXiv preprint arXiv:2504.11354, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Param Biyani, Shashank Kirtania, Yasharth Bajpai, Sumit Gulwani, and Ashish Tiwari. Indi- mathbench: Autoformalizing mathematical reasoning problems with a human touch.arXiv preprint arXiv:2512.00997, 2025
-
[26]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, et al. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction.arXiv preprint arXiv:2508.03613, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, et al. Seed-prover: Deep and broad reasoning for automated theorem proving.arXiv preprint arXiv:2507.23726, 2025
-
[29]
Ax-Prover: A Deep Reasoning Agentic Framework for Theorem Proving in Mathematics and Quantum Physics
Benjamin Breen, Marco Del Tredici, Jacob McCarran, Javier Aspuru Mijares, Weichen Winston Yin, Kfir Sulimany, Jacob M Taylor, Frank HL Koppens, and Dirk Englund. AX-Prover: A deep reasoning agentic framework for theorem proving in mathematics and quantum physics. arXiv preprint arXiv:2510.12787, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
On logarithmic concave measures and functions.Acta Scientiarum Mathe- maticarum (Szeged), 34:335–343, 1973
András Prékopa. On logarithmic concave measures and functions.Acta Scientiarum Mathe- maticarum (Szeged), 34:335–343, 1973
1973
-
[31]
A remark on stirling’s formula.The American Mathematical Monthly, 62(1): 26–29, 1955
Herbert Robbins. A remark on stirling’s formula.The American Mathematical Monthly, 62(1): 26–29, 1955. 14
1955
-
[32]
Hummel and Basilis C
Robert A. Hummel and Basilis C. Gidas. Zero crossings and the heat equation. Technical Report 111, Computer Science Division, Courant Institute of Mathematical Sciences, New York University, 1984
1984
-
[33]
Krantz and Harold R
Steven G. Krantz and Harold R. Parks.The Implicit Function Theorem: History, Theory, and Applications. Birkhäuser, 2002
2002
-
[34]
Krantz and Harold R
Steven G. Krantz and Harold R. Parks.A Primer of Real Analytic Functions. Birkhäuser, 2 edition, 2002
2002
-
[35]
F. R. K. Chung, R. L. Graham, P. Frankl, and J. B. Shearer. Some intersection theorems for ordered sets and graphs.Journal of Combinatorial Theory, Series A, 43(1):23–37, 1986
1986
-
[36]
Cambridge University Press, 1997
Eyal Kushilevitz and Noam Nisan.Communication Complexity. Cambridge University Press, 1997
1997
-
[37]
Theoremllama: Transforming general-purpose LLMs into lean4 experts, 2024
Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, and Tong Zhang. Theoremllama: Transforming general-purpose LLMs into lean4 experts, 2024. URL https: //arxiv.org/abs/2407.03203
-
[38]
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data.arXiv preprint arXiv:2405.14333, 2024
-
[39]
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, et al. Goedel-prover: A frontier model for open-source automated theorem proving.arXiv preprint arXiv:2502.07640, 2025
-
[40]
Xingguang Ji, Yahui Liu, Qi Wang, Jingyuan Zhang, Yang Yue, Rui Shi, Chenxi Sun, Fuzheng Zhang, Guorui Zhou, and Kun Gai. Leanabell-prover-v2: Verifier-integrated reasoning for formal theorem proving via reinforcement learning.arXiv preprint arXiv:2507.08649, 2025
-
[41]
Huajian Xin, ZZ Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, et al. Deepseek-prover-v1. 5: Harnessing proof assistant feed- back for reinforcement learning and monte-carlo tree search.arXiv preprint arXiv:2408.08152, 2024
-
[42]
Learning to repair Lean proofs from compiler feedback, 2026
Evan Wang, Simon Chess, Daniel Lee, Siyuan Ge, Ajit Mallavarapu, Jarod Alper, and Vasily Ilin. Learning to repair Lean proofs from compiler feedback, 2026. URL https://arxiv. org/abs/2602.02990
-
[43]
Leanabell-prover: Posttraining scaling in formal reasoning.arXiv preprint arXiv:2504.06122, 2025
Jingyuan Zhang, Qi Wang, Xingguang Ji, Yahui Liu, Yang Yue, Fuzheng Zhang, Di Zhang, Guorui Zhou, and Kun Gai. Leanabell-prover: Posttraining scaling in formal reasoning.arXiv preprint arXiv:2504.06122, 2025
-
[44]
LeanAgent: Lifelong learning for formal theorem proving, 2025
Adarsh Kumarappan, Mo Tiwari, Peiyang Song, Robert Joseph George, Chaowei Xiao, and Anima Anandkumar. LeanAgent: Lifelong learning for formal theorem proving, 2025. URL https://arxiv.org/abs/2410.06209
-
[45]
Process-driven autoformalization in lean 4
Jianqiao Lu, Yingjia Wan, Zhengying Liu, Yinya Huang, Jing Xiong, Chengwu Liu, Jianhao Shen, Hui Jin, Jipeng Zhang, Haiming Wang, et al. Process-driven autoformalization in Lean 4. arXiv preprint arXiv:2406.01940, 2024
-
[46]
arXiv preprint arXiv:2507.06181 , year =
Zhongyuan Peng, Yifan Yao, Kaijing Ma, Shuyue Guo, Yizhe Li, Yichi Zhang, Chenchen Zhang, Yifan Zhang, Zhouliang Yu, Luming Li, Minghao Liu, Yihang Xia, Jiawei Shen, Yuchen Wu, Yixin Cao, Zhaoxiang Zhang, Wenhao Huang, Jiaheng Liu, and Ge Zhang. CriticLean: Critic-guided reinforcement learning for mathematical formalization, 2025. URL https: //arxiv.org/a...
-
[47]
Azim Ospanov, Farzan Farnia, and Roozbeh Yousefzadeh. APOLLO: Automated LLM and lean collaboration for advanced formal reasoning.arXiv preprint arXiv:2505.05758, 2025
-
[48]
Automatic Textbook Formalization
Fabian Gloeckle, Ahmad Rammal, Charles Arnal, Remi Munos, Vivien Cabannes, Gabriel Synnaeve, and Amaury Hayat. Automatic textbook formalization, 2026. URL https://arxiv. org/abs/2604.03071. 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Prithwish Jana, Kaan Kale, Ahmet Ege Tanriverdi, Cruise Song, Sriram Vishwanath, and Vijay Ganesh. ProofBridge: Auto-formalization of natural language proofs in Lean via joint embeddings.arXiv preprint arXiv:2510.15681, 2025
-
[50]
Lean for science formalization
Przemyslaw Chojecki. Lean for science formalization. 2026
2026
-
[51]
Formalizing chemical physics using the lean theorem prover
Maxwell P Bobbin, Samiha Sharlin, Parivash Feyzishendi, An Hong Dang, Catherine M Wraback, and Tyler R Josephson. Formalizing chemical physics using the lean theorem prover. Digital Discovery, 3(2):264–280, 2024
2024
-
[52]
Veribench: End-to-end formal verification benchmark for AI code generation in lean 4
Brando Miranda, Zhanke Zhou, Allen Nie, Elyas Obbad, Leni Aniva, Kai Fronsdal, Weston Kirk, Dilara Soylu, Andrea Yu, Ying Li, and Sanmi Koyejo. Veribench: End-to-end formal verification benchmark for AI code generation in lean 4. In2nd AI for Math Workshop @ ICML 2025, 2025. URLhttps://openreview.net/forum?id=rWkGFmnSNl. A Limitations • Algorithmic result...
2025
-
[53]
1968_b2, 1971_a2, 1983_b2, 1992_a2, 2021_a2
-
[54]
1975_a3, 1994_b3, 1997_a3, 2010_a3, 2022_b3
-
[55]
1965_b4, 1970_b4, 1971_a4, 1975_a4, 1987_b4, 1992_b4, 1993_a4, 2000_a4, 2005_a4, 2011_b4, 2019_a4
-
[56]
2002_a5, 2009_a5, 2012_a5
-
[57]
key property of towers of minimum fragments
1975_b6, 1986_b6, 1989_b6, 2003_b6, 2008_b6, 2014_a6, 2016_b6 During the evaluation, we disabled all internet access to prevent the models from retrieving external resources, existing proofs, or data leaks. We initialized the agents in their workspace repository with the specific Putnam problem and invoked them using the following system command: PutnamBe...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.