ExPLoRe: Expert Patch-Level Loss Routing for Multi-Objective Masked Image Modeling
Pith reviewed 2026-07-01 06:13 UTC · model grok-4.3
The pith
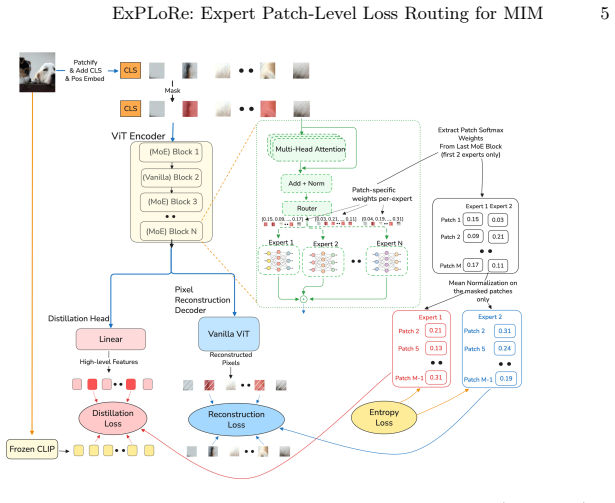
ExPLoRe turns MoE dispatch weights into per-patch loss coefficients so each image region can emphasize different MIM objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
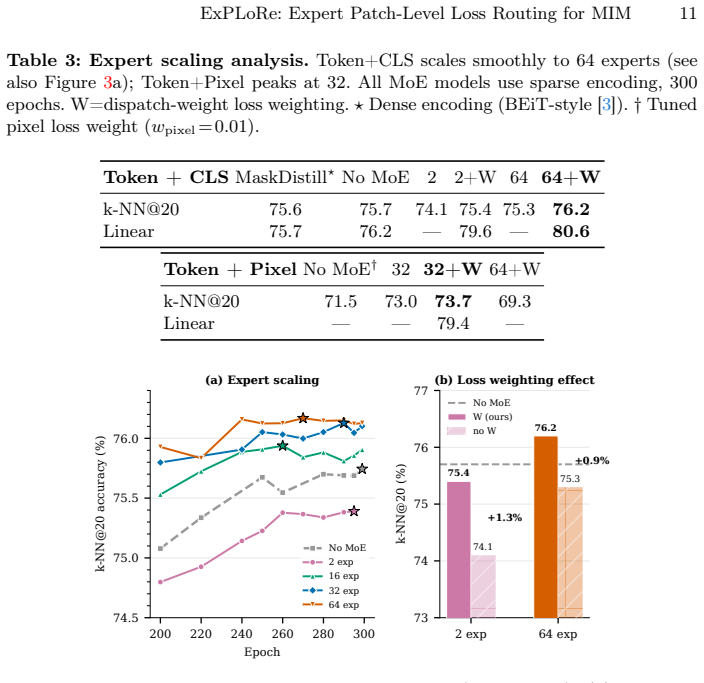
ExPLoRe repurposes Soft Mixture of Experts dispatch weights as learned per-patch loss coefficients. The key mechanism is loss-coupling, which routes gradients through those weights so the router learns to assign different objective emphases to different patches. A detach ablation that blocks the gradient path drops performance by 1.6 percent, confirming the coupling as the operative ingredient. On ImageNet-1K with ViT-Base the approach records improvements on two objective combinations and supplies three adaptation recipes that raise MoE finetuning accuracy and close the segmentation gap to non-MoE baselines on ADE20K.
What carries the argument
Loss-coupling, the mechanism that lets gradients update the MoE router through its own dispatch weights so they become per-patch loss coefficients.
If this is right
- Patches receive different objective weights according to their visual content instead of a single global scalar.
- k-NN and linear-probe scores rise on ImageNet-1K for both Token+CLS and Token+Pixel objective pairs.
- Three adaptation recipes (Freeze Routing, Expert Dropout, Freeze Attention) raise MoE finetuning accuracy by 1.5 percent.
- MoE models close a 2.5-2.9 mIoU gap and match or exceed non-MoE baselines on ADE20K segmentation.
Where Pith is reading between the lines
- The same gradient-through-router pattern could be inserted into other multi-loss representation learners that currently rely on fixed coefficients.
- One could test whether the learned routing patterns align with known patch properties such as edge density or semantic category.
- If the router generalizes across datasets, the method might reduce the amount of per-task hyperparameter search required for multi-objective pretraining.
Load-bearing premise
Allowing loss gradients to flow through the dispatch weights produces stable content-dependent specialization rather than router collapse or unintended dynamics.
What would settle it
An experiment on the ImageNet validation set in which blocking gradient flow through the dispatch weights removes the reported accuracy lift and the detach ablation gap disappears.
Figures

read the original abstract
Multi-objective masked image modeling (MIM) combines complementary learning signals (token distillation, CLS alignment, and pixel reconstruction) but existing methods weight these objectives with global scalars, ignoring spatial heterogeneity across patches. We present ExPLoRe (Expert Patch-Level Loss Routing), which repurposes Soft Mixture of Experts (MoE) dispatch weights as learned, per-patch loss coefficients. The key mechanism is loss-coupling: allowing loss gradients to flow through dispatch weights to the router enables content-dependent specialization, where different patches receive different emphases across objectives. A detach ablation confirms loss-coupling as the core mechanism, degrading performance by 1.6% when gradients are blocked. On ImageNet-1K with ViT-Base, ExPLoRe improves over non-MoE baselines on two objective combinations (Token+CLS: +0.5% k-NN, +4.4% linear probe; Token+Pixel: +2.2% k-NN), achieving 80.6% linear probe and 85.3% finetuning accuracy, competitive with published methods. For downstream transfer, we develop adaptation recipes (Freeze Routing, Expert Dropout, and Freeze Attention) that improve MoE finetuning by +1.5% over the vanilla MoE, and close a 2.5--2.9 mIoU segmentation gap so that MoE models match or exceed non-MoE baselines on ADE20K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExPLoRe, which repurposes Soft MoE dispatch weights as learned per-patch loss coefficients for multi-objective masked image modeling (MIM) combining token distillation, CLS alignment, and pixel reconstruction. The key innovation is loss-coupling, where gradients flow through the dispatch weights to the router to enable content-dependent objective specialization across patches. On ImageNet-1K with ViT-Base, it reports gains over non-MoE baselines (Token+CLS: +0.5% k-NN, +4.4% linear probe; Token+Pixel: +2.2% k-NN), reaching 80.6% linear probe and 85.3% finetuning accuracy, plus adaptation recipes (Freeze Routing, Expert Dropout, Freeze Attention) that improve MoE finetuning by +1.5% and close segmentation gaps on ADE20K.
Significance. If the central mechanism holds, the work provides a practical method for handling spatial heterogeneity in MIM loss weighting without fixed global scalars, with modest but consistent empirical gains and useful downstream adaptation strategies for MoE models. The empirical focus and absence of parameter-free derivations or machine-checked proofs limit deeper theoretical impact, but the approach could generalize to other multi-objective settings if the specialization effect is robustly validated.
major comments (1)
- [Abstract] Abstract (detach ablation): the claim that loss-coupling produces stable content-dependent specialization rests on a single reported 1.6% drop when gradients are blocked. No router entropy, expert utilization histograms, per-patch routing visualizations, or comparisons to fixed routing are referenced, leaving open whether gains arise from the intended mechanism or incidental MoE capacity effects. This is load-bearing for the central claim.
minor comments (1)
- The manuscript would benefit from explicit reporting of full training details, baseline implementations, and statistical significance for the accuracy numbers (e.g., 80.6% linear probe) to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern regarding the strength of evidence for the loss-coupling mechanism is well-taken, and we address it directly below by committing to additional analyses in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (detach ablation): the claim that loss-coupling produces stable content-dependent specialization rests on a single reported 1.6% drop when gradients are blocked. No router entropy, expert utilization histograms, per-patch routing visualizations, or comparisons to fixed routing are referenced, leaving open whether gains arise from the intended mechanism or incidental MoE capacity effects. This is load-bearing for the central claim.
Authors: We agree that the detach ablation alone provides limited direct validation of content-dependent specialization and that additional diagnostics would better isolate the mechanism from capacity effects. In the revised manuscript we will add: (i) router entropy and expert utilization histograms across training, (ii) per-patch routing visualizations on representative images, and (iii) a fixed-routing baseline that uses the same MoE capacity but disables loss-coupling. These results will be referenced in the abstract and discussed in the main text to substantiate that performance gains track the intended specialization behavior. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental support
full rationale
The paper introduces ExPLoRe as an empirical architecture that repurposes Soft MoE dispatch weights for per-patch loss coefficients in multi-objective MIM, with claims resting on ImageNet-1K k-NN/linear-probe/finetuning accuracies and a single detach ablation. No equations, derivations, or self-citations appear in the provided text that reduce any reported gain to a quantity defined by the paper's own fitted parameters or prior self-work. The loss-coupling mechanism is validated externally via ablation rather than by construction, and downstream adaptation recipes are presented as practical heuristics without invoking uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Softmax dispatch in Soft MoE produces valid per-patch coefficients that can be differentiated through for loss routing.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Machine Learning
Baevski, A., Babu, A., Hsu, W.N., Auli, M.: data2vec 2.0: Highly efficient self- supervised learning for vision, speech and language. In: International Conference on Machine Learning. pp. 1694–1714 (2023)
2023
-
[2]
In: Interna- tional Conference on Machine Learning
Baevski, A., Hsu, W.N., Xu, Q., Babu, A., Gu, J., Auli, M.: data2vec: A general framework for self-supervised learning in speech, vision and language. In: Interna- tional Conference on Machine Learning. pp. 1298–1312 (2022)
2022
-
[3]
In: International Conference on Learning Representations (2022) 16 K
Bao, H., Dong, L., Piao, S., Wei, F.: Beit: Bert pre-training of image transformers. In: International Conference on Learning Representations (2022) 16 K. Georgiou et al
2022
-
[4]
In: European Conference on Computer Vision (ECCV) (2014)
Bossard, L., Guillaumin, M., Van Gool, L.: Food-101 – mining discriminative components with random forests. In: European Conference on Computer Vision (ECCV) (2014)
2014
-
[5]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Chen, T., Chen, X., Du, X., Rashwan, A., Yang, F., Chen, H., Wang, Z., Li, Y.: Adamv-moe: Adaptive multi-task vision mixture-of-experts. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 17346–17357 (2023)
2023
-
[6]
In- ternational Journal of Computer Vision132(1), 208–223 (2024)
Chen, X., Ding, M., Wang, X., Xin, Y., Mo, S., Wang, Y., Han, S., Luo, P., Zeng, G., Wang, J.: Context autoencoder for self-supervised representation learning. In- ternational Journal of Computer Vision132(1), 208–223 (2024)
2024
-
[7]
In: European Conference on Computer Vision
Chen, Y., Liu, Y., Jiang, D., Zhang, X., Dai, W., Xiong, H., Tian, Q.: Sdae: Self- distillated masked autoencoder. In: European Conference on Computer Vision. pp. 108–124 (2022)
2022
-
[8]
In: International Conference on Machine Learning
Chen, Z., Badrinarayanan, V., Lee, C.Y., Rabinovich, A.: Gradnorm: Gradient nor- malization for adaptive loss balancing in deep multitask networks. In: International Conference on Machine Learning. pp. 794–803 (2018)
2018
-
[9]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009)
2009
-
[10]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. pp. 4171–4186 (2019)
2019
-
[11]
In: European Conference on Computer Vision
Dong, X., Bao, J., Zhang, T., Chen, D., Zhang, W., Yuan, L., Chen, D., Wen, F., Yu, N.: Bootstrapped masked autoencoders for vision bert pretraining. In: European Conference on Computer Vision. pp. 247–264 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dong, X., Bao, J., Zheng, Y., Zhang, T., Chen, D., Yang, H., Zeng, M., Zhang, W., Yuan, L., Chen, D., et al.: Maskclip: Masked self-distillation advances con- trastive language-image pretraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10995–11005 (2023)
2023
-
[13]
Journal of Machine Learning Research 23(120), 1–39 (2022)
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022)
2022
-
[14]
arXiv preprint arXiv:2410.15732 (2024)
Han, X., Wei, L., Dou, Z., Wang, Z., Qiang, C., He, X., Sun, Y., Han, Z., Tian, Q.: Vimoe: An empirical study of designing vision mixture-of-experts. arXiv preprint arXiv:2410.15732 (2024)
-
[15]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalablevisionlearners.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition. pp. 16000–16009 (2022)
2022
-
[16]
arXiv preprint arXiv:2208.06049 (2022)
Hou,Z.,Sun,F.,Chen,Y.K.,Xie,Y.,Kung,S.Y.:Milan:Maskedimagepretraining on language assisted representation. arXiv preprint arXiv:2208.06049 (2022)
-
[17]
Jiang, Z., Zheng, G., Cheng, Y., Awadallah, A.H., Wang, Z.: Cr-moe: Consistent routedmixture-of-expertsforscalingcontrastivelearning.TransactionsonMachine Learning Research (2024)
2024
-
[18]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Kendall, A., Gal, Y., Cipolla, R.: Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 7482–7491 (2018)
2018
-
[19]
Reasonable Effectiveness of Random Weighting: A Litmus Test for Multi-Task Learning
Lin, B., Ye, F., Zhang, Y., Tsang, I.W.: Reasonable effectiveness of random weight- ing: A litmus test for multi-task learning. Transactions on Machine Learning Re- search (2022), arXiv:2111.10603 ExPLoRe: Expert Patch-Level Loss Routing for MIM 17
-
[20]
Transactions on Machine Learning Research (TMLR) (2024)
Liu, T., Blondel, M., Riquelme, C., Puigcerver, J.: Routers in vision mixture of experts: An empirical study. Transactions on Machine Learning Research (TMLR) (2024)
2024
-
[21]
BEiT v2: Masked image modeling with vector-quantized visual tokenizers
Peng, Z., Dong, L., Bao, H., Ye, Q., Wei, F.: Beit v2: Masked image modeling with vector-quantized visual tokenizers. arXiv preprint arXiv:2208.06366 (2022)
-
[22]
arXiv preprint arXiv:2210.10615 (2022)
Peng, Z., Dong, L., Bao, H., Ye, Q., Wei, F.: A unified view of masked image modeling. arXiv preprint arXiv:2210.10615 (2022)
-
[23]
In: International Conference on Learning Representations (ICLR) (2026)
Psomas, B., Christopoulos, D., Baltzi, E., Kakogeorgiou, I., Aravanis, T., Ko- modakis, N., Karantzalos, K., Avrithis, Y., Tolias, G.: Attention, please! revisiting attentive probing through the lens of efficiency. In: International Conference on Learning Representations (ICLR) (2026)
2026
-
[24]
In: International Conference on Learning Representations (ICLR) (2024)
Puigcerver, J., Riquelme, C., Mustafa, B., Houlsby, N.: From sparse to soft mix- tures of experts. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[25]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[26]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Riquelme, C., Puigcerver, J., Mustafa, B., Neumann, M., Jenatton, R., Su- sano Pinto, A., Keysers, D., Houlsby, N.: Scaling vision with sparse mixture of experts. In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[27]
Journal of Computational and Applied Mathematics20, 53–65 (1987)
Rousseeuw, P.J.: Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics20, 53–65 (1987)
1987
-
[28]
In: Ad- vances in Neural Information Processing Systems
Sener, O., Koltun, V.: Multi-task learning as multi-objective optimization. In: Ad- vances in Neural Information Processing Systems. vol. 31 (2018)
2018
-
[29]
In: International Conference on Learning Representations (ICLR) (2017)
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In: International Conference on Learning Representations (ICLR) (2017)
2017
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wei, C., Fan, H., Xie, S., Wu, C.Y., Yuille, A., Feichtenhofer, C.: Masked feature prediction for self-supervised visual pre-training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14668–14678 (2022)
2022
-
[31]
arXiv preprint arXiv:2203.05175 (2022)
Wei, L., Xie, L., Zhou, W., Li, H., Tian, Q.: Mvp: Multimodality-guided visual pre-training. arXiv preprint arXiv:2203.05175 (2022)
-
[32]
In: European Conference on Computer Vision
Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J.: Unified perceptual parsing for scene understanding. In: European Conference on Computer Vision. pp. 418–434 (2018)
2018
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., Hu, H.: Simmim: A simple framework for masked image modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9653–9663 (2022)
2022
-
[34]
arXiv preprint arXiv:2503.09445 (2025)
Yang, X., Lu, J., Qiu, H., Li, S., Li, H.: Astrea: A moe-based visual understanding model with progressive alignment. arXiv preprint arXiv:2503.09445 (2025)
-
[35]
In: Advances in Neural Information Processing Systems
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., Finn, C.: Gradient surgery for multi-task learning. In: Advances in Neural Information Processing Systems. vol. 33, pp. 5824–5836 (2020)
2020
-
[36]
arXiv preprint arXiv:2211.09799 , year=
Zhang, X., Yuan, J., Wei, X., Wei, Y., Hong, S., Wang, J.: Cae v2: Context au- toencoder with clip target. arXiv preprint arXiv:2211.09799 (2024)
-
[37]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barber, A., Torralba, A.: Scene parsing through ade20k dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 633–641 (2017) 18 K. Georgiou et al
2017
-
[38]
In: International Conference on Learning Representations (2022)
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. In: International Conference on Learning Representations (2022)
2022
-
[39]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., Shazeer, N., Fedus, W.: St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906 (2022) ExPLoRe: Expert Patch-Level Loss Routing for MIM 19 A Training and Evaluation Hyperparameters A.1 Pretraining Configuration Table A1 summarizes the pretraining hyperpara...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.