Rethinking the Role of Feature Engineering and Learning Strategies in Few-Shot Hidden Emotion Recognition
Pith reviewed 2026-07-01 06:23 UTC · model grok-4.3
The pith
Cross-attention with static base and dynamic offset features tops a hidden emotion recognition challenge at 0.76923 accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
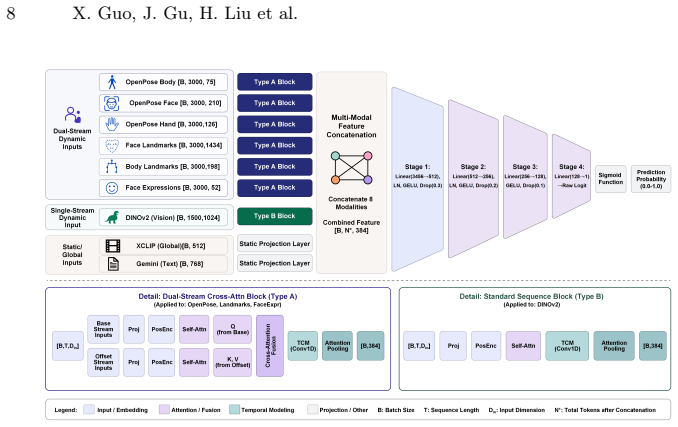
The authors' solution achieved a test accuracy of 0.76923 by integrating multi-source features into a compact temporal modeling framework. This framework uses a cross-attention mechanism with static Base features as Query and dynamic Offset features as Key/Value to eliminate identity biases, paired with MIL-based adaptive pooling to extract instantaneous emotions from noisy long sequences. The work additionally reveals representation collapse in vision foundation models for micro-dynamic tasks and attributes pseudo-generalization to shortcut learning and rote memorization driven by public leaderboards.
What carries the argument
Cross-attention mechanism that takes static pose features (Base) as Query and dynamic micro-motion differential features (Offset) as Key and Value, together with Multiple Instance Learning adaptive pooling.
If this is right
- Static biases from body shape and identity are removed by treating poses as fixed queries.
- Background noise is suppressed while momentary emotional signals are retained across long sequences.
- General vision foundation models enter representation collapse on micro-dynamic tasks.
- Networks shift to shortcut learning and rote memorization when trained against public leaderboards.
Where Pith is reading between the lines
- The same Base-Offset split could be tested on other subtle temporal signals such as micro-expressions or gait anomalies.
- Leaderboard-driven training may systematically favor memorization over genuine feature learning in any sparse-signal domain.
- Evaluating the same models on private or synthetic micro-dynamic datasets would isolate whether collapse is leaderboard-induced.
Load-bearing premise
The cross-attention with Base as Query and Offset as Key/Value plus MIL adaptive pooling successfully extracts instantaneous emotions while suppressing background noise in long sequences.
What would settle it
An ablation on the challenge test set showing that removing the cross-attention or the MIL pooling leaves accuracy unchanged, or a direct measurement showing vision foundation models maintain distinct representations on micro-dynamic emotion data.
Figures
read the original abstract
In this paper, we present the solution developed by our team, XInsight Lab, which achieved first place in Track 3 of the 4th EI-MIGA-IJCAI Challenge with a test accuracy of 0.76923. To address the challenge of weak and sparse implicit emotion evidence in long videos, this paper extends the winning solution from the previous competition and proposes a compact multi-modal temporal modeling framework. The framework integrates and evaluates the effects of multi-source features, including 2D/3D skeletons, facial expression Blendshapes, DINOv2/v3 vision foundation models, X-CLIP video features, and Gemini semantic priors. Architecturally, we propose a cross-attention mechanism that utilizes static pose features, denoted as Base, as the Query and dynamic micro-motion differential features, denoted as Offset, as the Key and Value. By capturing local relative velocities, this mechanism eliminates static biases related to individual body shape and identity. Concurrently, an adaptive pooling method based on Multiple Instance Learning is employed to extract instantaneous emotions while suppressing background noise in long sequences. Finally, the paper reveals the representation collapse phenomenon of general vision foundation models in micro-dynamic tasks, and analyzes the underlying mechanisms where networks fall into public-leaderboard-driven pseudo-generalization due to shortcut learning and rote memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the winning solution for Track 3 of the 4th EI-MIGA-IJCAI Challenge, achieving a test accuracy of 0.76923 using a multi-modal framework that combines 2D/3D skeletons, facial Blendshapes, DINOv2/v3, X-CLIP, and Gemini features. It introduces a cross-attention mechanism using static pose (Base) as Query and micro-motion differentials (Offset) as Key/Value to capture relative velocities, along with MIL-based adaptive pooling for extracting instantaneous emotions from long sequences. The work also claims to identify representation collapse in general vision foundation models for micro-dynamic tasks caused by shortcut learning and leaderboard-driven memorization.
Significance. If the accuracy is robust and the collapse diagnosis is backed by quantitative diagnostics, the work would offer a useful benchmark for few-shot micro-dynamic emotion recognition and highlight practical limitations of vision foundation models. The concrete leaderboard result and architectural choices for handling sparse signals in long videos provide empirical value, though the interpretive claims require additional evidence to elevate significance beyond a competition report.
major comments (2)
- [Abstract] Abstract: The claim that the solution 'reveals the representation collapse phenomenon of general vision foundation models in micro-dynamic tasks' and analyzes mechanisms of 'public-leaderboard-driven pseudo-generalization due to shortcut learning and rote memorization' is asserted without any supporting quantitative evidence such as feature-space similarity scores, t-SNE analyses with metrics, or ablation experiments isolating shortcut vs. genuine generalization.
- [Abstract] Abstract: The reported test accuracy of 0.76923 is given without information on validation splits, baseline comparisons, error bars, or ablation studies, leaving unclear whether the cross-attention (Base as Query, Offset as Key/Value) plus MIL pooling is responsible for the result or if performance reflects other factors.
minor comments (2)
- [Abstract] Abstract: The description of extending the prior winning solution does not detail the specific modifications or their incremental impact.
- [Abstract] Abstract: No dataset statistics (e.g., average sequence length, number of micro-emotion instances) are supplied to ground claims about long sequences and sparse evidence.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We address the two major comments on the abstract below, agreeing that additional quantitative support and experimental details will strengthen the manuscript. We will perform a major revision incorporating these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the solution 'reveals the representation collapse phenomenon of general vision foundation models in micro-dynamic tasks' and analyzes mechanisms of 'public-leaderboard-driven pseudo-generalization due to shortcut learning and rote memorization' is asserted without any supporting quantitative evidence such as feature-space similarity scores, t-SNE analyses with metrics, or ablation experiments isolating shortcut vs. genuine generalization.
Authors: We acknowledge that the abstract states the collapse observation without explicit quantitative diagnostics such as similarity scores or t-SNE metrics. The full manuscript grounds the claim in empirical observations from the competition (e.g., consistent failure modes of DINOv2/v3 and X-CLIP on micro-motion despite strong static performance), but we agree these are primarily qualitative. In revision we will add (i) pairwise cosine similarity matrices between static and dynamic feature embeddings, (ii) t-SNE visualizations with quantitative cluster-separation metrics, and (iii) controlled ablations that isolate shortcut learning by training on leaderboard-only vs. held-out splits. These additions will be placed in a new subsection of the experiments. revision: yes
-
Referee: [Abstract] Abstract: The reported test accuracy of 0.76923 is given without information on validation splits, baseline comparisons, error bars, or ablation studies, leaving unclear whether the cross-attention (Base as Query, Offset as Key/Value) plus MIL pooling is responsible for the result or if performance reflects other factors.
Authors: The 0.76923 figure is the official test-set score returned by the competition organizers. Our internal development used a 5-fold temporal split of the training videos (ensuring no subject overlap) and we tracked per-fold accuracy; however, these details and the corresponding baseline comparisons (single-modality, no cross-attention, mean pooling) were omitted from the abstract to meet length constraints. We will expand the abstract and add a dedicated “Ablation Studies” subsection that reports (a) validation accuracy with standard deviation across folds, (b) incremental gains from Base-Query/Offset-KeyValue cross-attention, and (c) MIL pooling versus fixed temporal pooling. Error bars from three independent runs with different random seeds will also be included. revision: yes
Circularity Check
No circularity: purely empirical competition entry with no derivation chain
full rationale
The manuscript is an empirical competition solution that integrates multi-source features into a cross-attention + MIL framework and reports a leaderboard score of 0.76923. No equations, parameter-fitting steps, or formal derivations are present in the provided text. The claim of revealing representation collapse is an interpretive observation attached to the architectural choices and results, not a mathematical reduction that collapses to fitted inputs or prior self-citations by construction. Self-reference to a prior competition win is noted but does not bear any derivational load. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition
Baltrušaitis, T., Zadeh, A., Lim, Y.C., Morency, L.P.: Openface 2.0: Facial behavior analysis toolkit. In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition. pp. 59–66 (2018)
2018
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence43(1), 172–186 (2021) 16 X
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multi- person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence43(1), 172–186 (2021) 16 X. Guo, J. Gu, H. Liu et al
2021
-
[3]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
2017
-
[4]
arXiv preprint arXiv:2408.03097 (2024)
Chen, G., Wang, F., Li, K., Wu, Z., Fan, H., Yang, Y., Wang, M., Guo, D.: Prototype learning for micro-gesture classification. arXiv preprint arXiv:2408.03097 (2024)
-
[5]
International Journal of Computer Vision131, 1346–1366 (2023)
Chen, H., Shi, H., Liu, X., Li, X., Zhao, G.: Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis. International Journal of Computer Vision131, 1346–1366 (2023)
2023
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9268–9277 (2019)
2019
-
[7]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. pp. 4171–4186 (2019)
2019
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Duan, H., Zhao, Y., Chen, K., Lin, D., Dai, B.: Revisiting skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2969–2978 (2022)
2022
-
[9]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
In: 2025 IEEE 6th International Conference on Pattern Recognition and Machine Learning (PRML)
Gu, J.: Performance analysis of traditional vqa models under limited computational resources. In: 2025 IEEE 6th International Conference on Pattern Recognition and Machine Learning (PRML). pp. 323–328. IEEE (2025)
2025
-
[11]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Gu, J., Li, K., Wang, F., Wei, Y., Wu, Z., Fan, H., Wang, M.: Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 5461–5470 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Gu, J., Li, K., Wang, H., Akşit, K.: Text-guided fine-grained video anomaly under- standing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 1251–1261 (June 2026)
2026
-
[13]
arXiv preprint arXiv:2507.08344 (2025)
Gu, J., Wang, F., Li, K., Wei, Y., Wu, Z., Guo, D.: Mm-gesture: towards precise micro-gesture recognition through multimodal fusion. arXiv preprint arXiv:2507.08344 (2025)
-
[14]
IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
Guo, D., Li, K., Hu, B., Zhang, Y., Wang, M.: Benchmarking micro-action recog- nition: Dataset, methods, and applications. IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
2024
-
[15]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Guo, D., Li, X., Li, K., Chen, H., Hu, J., Zhao, G., Yang, Y., Wang, M.: Mac 2024: Micro-action analysis grand challenge. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11304–11305 (2024)
2024
-
[16]
In: MiGA@IJCAI (2024)
Huang, H., Wang, Y., Linghu, K., Xia, Z.: Multi-modal micro-gesture classification via multi-scale heterogeneous ensemble network. In: MiGA@IJCAI (2024)
2024
-
[17]
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: Rtmpose: Real-time multi-person pose estimation based on mmpose (2023)
2023
-
[18]
ACM Transactions on Graphics42(4), 1–14 (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4), 1–14 (2023)
2023
-
[19]
In: European Conference on Computer Vision (2024) ReFELS 17
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: European Conference on Computer Vision (2024) ReFELS 17
2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Gu, J., Wang, F., Wu, Z., Fan, H., Guo, D.: Ma-bench: Towards fine-grained micro-action understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20118–20128 (2026)
2026
-
[21]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, K., Guo, D., Chen, G., Fan, C., Xu, J., Wu, Z., Fan, H., Wang, M.: Prototypical calibrating ambiguous samples for micro-action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4815–4823 (2025)
2025
-
[22]
In: Proceedings of the 31st ACM International Conference on Multimedia
Li, K., Guo, D., Chen, G., Liu, F., Wang, M.: Data augmentation for human behavior analysis in multi-person conversations. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 9516–9520 (2023)
2023
-
[23]
arXiv preprint arXiv:2307.10624 (2023)
Li, K., Guo, D., Chen, G., Peng, X., Wang, M.: Joint skeletal and semantic embedding loss for micro-gesture classification. arXiv preprint arXiv:2307.10624 (2023)
-
[24]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, K., Guo, D., Li, X., Chen, H., Liu, P., Wang, F., Hu, J., Zhao, G., Wang, M.: Mac 2025: The 2nd micro-action analysis grand challenge. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 14216–14221 (2025)
2025
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, K., Liu, P., Guo, D., Wang, F., Wu, Z., Fan, H., Wang, M.: Mmad: Multi-label micro-action detection in videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13225–13236 (2025)
2025
-
[26]
ACM Transactions on Graphics36(6), 1–17 (2017)
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4d scans. ACM Transactions on Graphics36(6), 1–17 (2017)
2017
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth any- thing 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lin, J., Gan, C., Han, S.: Tsm: Temporal shift module for efficient video under- standing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7083–7093 (2019)
2019
-
[29]
In: Proceedings of the IEEE International Conference on Computer Vision
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980–2988 (2017)
2017
-
[30]
arXiv preprint arXiv:2507.09512 (2025)
Liu, P., Li, K., Wang, F., Wei, Y., She, J., Guo, D.: Online micro-gesture recog- nition using data augmentation and spatial-temporal attention. arXiv preprint arXiv:2507.09512 (2025)
-
[31]
arXiv preprint arXiv:2407.04490 (2024)
Liu, P., Wang, F., Li, K., Chen, G., Wei, Y., Tang, S., Wu, Z., Guo, D.: Micro-gesture online recognition using learnable query points. arXiv preprint arXiv:2407.04490 (2024)
-
[32]
Self-supervised Learning Matters: A Simple Ensemble Solution for Micro-Gesture Recognition
Liu, T., Li, K., Wang, F., Chen, J., Wu, Z., Gu, J., Liu, H., Guo, D.: Self-supervised learning matters: A simple ensemble solution for micro-gesture recognition. arXiv preprint arXiv:2606.09261 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, X., Shi, H., Chen, H., Yu, Z., Li, X., Zhao, G.: imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10631–10642 (2021)
2021
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3202–3211 (2022)
2022
-
[35]
MediaPipe: A Framework for Building Perception Pipelines
Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., Zhang, F., Chang, C.L., Yong, M.G., Lee, J., et al.: Mediapipe: A framework for building perception pipelines. arXiv preprint arXiv:1906.08172 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[36]
In: European Conference on Computer Vision
Ni, B., Peng, H., Chen, M., Zhang, S., Meng, G., Fu, J., Xiang, S., Ling, H.: Expanding language-image pretrained models for general video recognition. In: European Conference on Computer Vision. pp. 1–18 (2022) 18 X. Guo, J. Gu, H. Liu et al
2022
-
[37]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Spatial-Temporal Decoupled Adapter for Micro-gesture Online Recognition
Shen, X., Li, K., Wang, F., Qian, W., Jiang, J., Guo, D.: Spatial-temporal decoupled adapter for micro-gesture online recognition. arXiv preprint arXiv:2606.07355 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: European Conference on Computer Vision
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: European Conference on Computer Vision. pp. 402–419. Springer (2020)
2020
-
[41]
In: Advances in Neural Information Processing Systems (2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (2017)
2017
-
[42]
iMiGUE-3K: A Large-Scale Benchmark for Micro-Gesture Analysis with Self-Supervised Learning
Wang, C., Chen, H., Wei, H., Yang, Y., Chen, Y., Zhao, G.: imigue-3k: A large-scale benchmark for micro-gesture analysis with self-supervised learning. arXiv preprint arXiv:2605.17179 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, F., Guo, D., Li, K., Wang, M.: Eulermormer: Robust eulerian motion magnification via dynamic filtering within transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5345–5353 (2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, F., Guo, D., Li, K., Zhong, Z., Wang, M.: Frequency decoupling for mo- tion magnification via multi-level isomorphic architecture. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18984– 18994 (2024)
2024
-
[45]
In: Companion Proceedings of the ACM on Web Conference 2025
Wang, F., Li, K., Nie, Y., Duan, Z., Zou, P., Wu, Z., Wang, Y., Wei, Y.: Exploiting ensemble learning for cross-view isolated sign language recognition. In: Companion Proceedings of the ACM on Web Conference 2025. pp. 2453–2457 (2025)
2025
-
[46]
In: Proceedings of the ACM Web Conference 2026
Wang, F., Yang, J., Chen, J., Liu, Y., Li, K., Wei, Y., Guo, D., Wang, M.: Xinsight: Integrative stage-consistent psychological counseling support agents for digital well-being. In: Proceedings of the ACM Web Conference 2026. pp. 9297–9308 (2026)
2026
-
[47]
IEEE Transactions on Multimedia (2026)
Wang, M., Liu, Z., Li, K., Wang, Y., Wang, Y., Wei, Y., Wang, F.: Task-generalized adaptive cross-domain learning for multimodal image fusion. IEEE Transactions on Multimedia (2026)
2026
-
[48]
IEEE Transactions on Affective Computing pp
Wang, R., Li, K., Tong, A., Xu, J., Guo, D., Wang, M.: Gait emotion recognition via uncertainty-oriented class discriminative learning. IEEE Transactions on Affective Computing pp. 1–14 (2026)
2026
-
[49]
Water Research284, 123994 (2025)
Wang, W., Wang, F., Wang, Z., Shi, X., Xu, C.: Robust s3former deep learning model for the direct diagnosis and prediction of natural organic matter (nom) from three-dimensional excitation-emission-matrix (3d-eem) data. Water Research284, 123994 (2025)
2025
-
[50]
arXiv preprint arXiv:2602.08057 (2026)
Wang, Y., Liu, H., Xu, T., Shi, C., Xing, H.: Weak to strong: Vlm-based pseudo- labeling as a weakly supervised training strategy in multimodal video-based hidden emotion understanding tasks. arXiv preprint arXiv:2602.08057 (2026)
-
[51]
In: Advances in Neural Information Processing Systems (2022)
Xu, Y., Zhang, J., Zhang, Q., Tao, D.: Vitpose: Simple vision transformer baselines for human pose estimation. In: Advances in Neural Information Processing Systems (2022)
2022
-
[52]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2018)
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence (2018)
2018
-
[53]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2023)
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.