Semantic Occupancy Prediction with Dual Range-Voxel Representation
Pith reviewed 2026-07-01 05:46 UTC · model grok-4.3
The pith
Dual range-voxel representation enables accurate 3D semantic occupancy from single-sweep LiDAR point clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
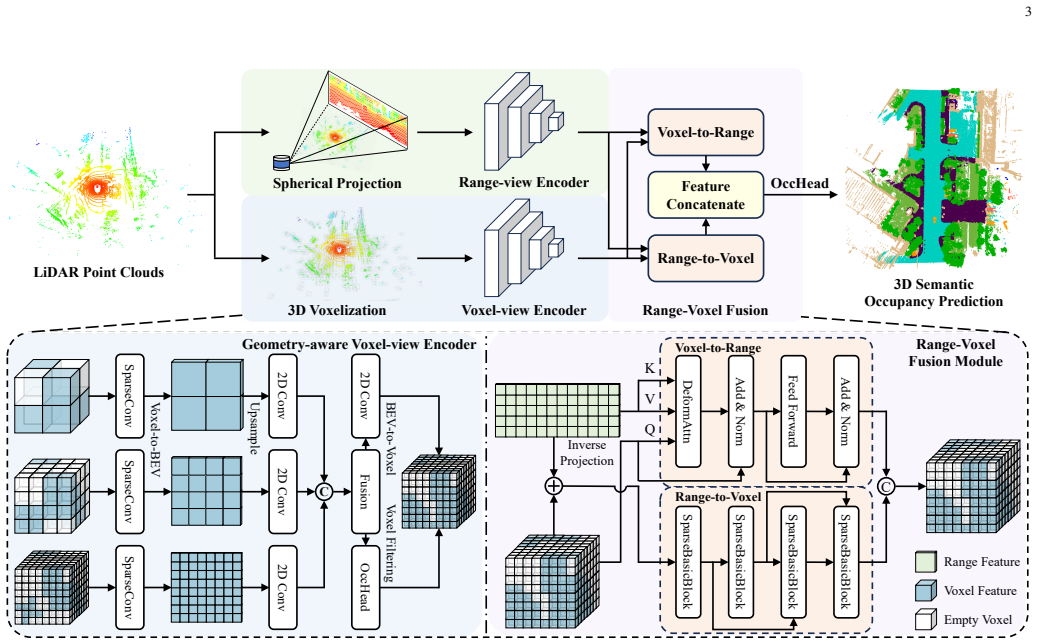
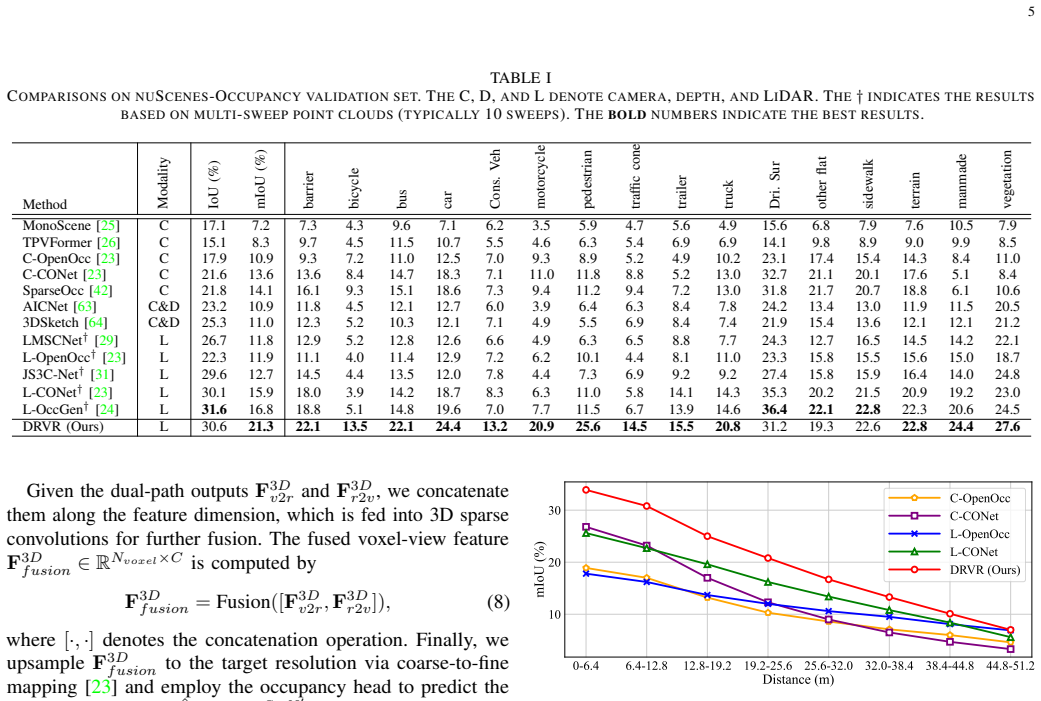
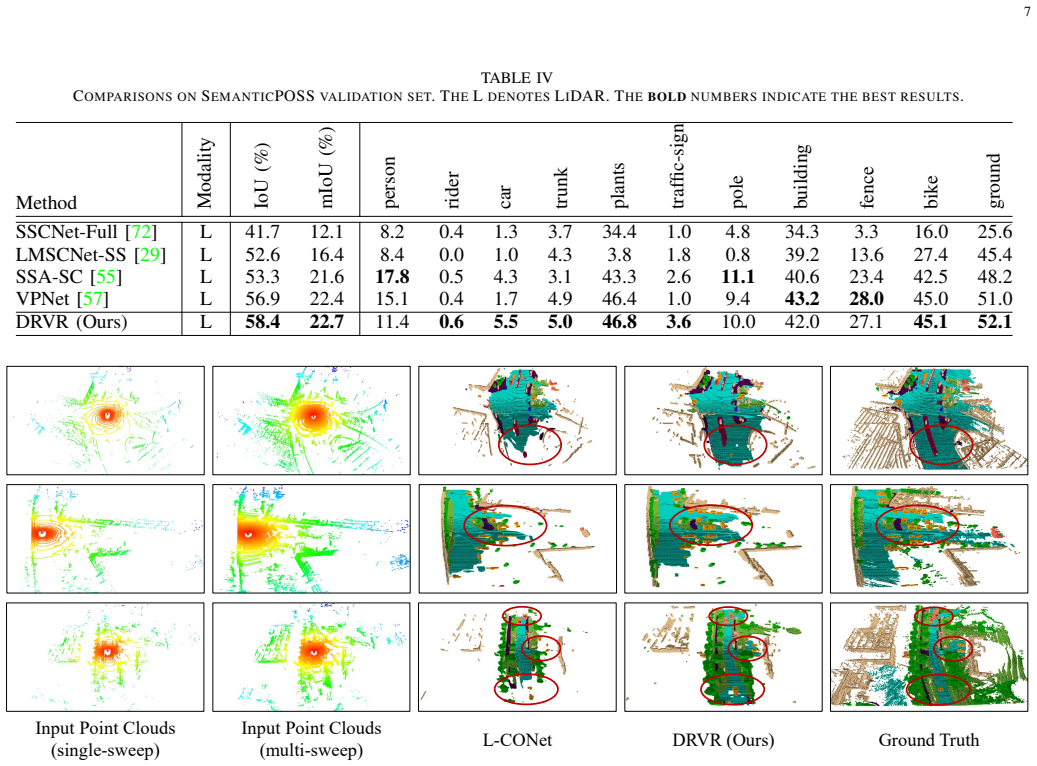
The authors introduce Dual Range-Voxel Representation (DRVR) that processes one LiDAR sweep through a range-view encoder for compact scene context, a geometry-aware voxel-view encoder that pulls multi-scale features separately before combining them, and a range-voxel fusion module that exchanges information in both directions. On nuScenes-Occupancy this single-sweep pipeline records 5.4 percent higher mIoU and 2.1 times faster inference than prior multi-sweep baselines, with similar gains reported on SemanticKITTI and SemanticPOSS.
What carries the argument
Dual Range-Voxel Representation (DRVR): a pipeline that pairs a range-view encoder, a geometry-aware voxel-view encoder, and bidirectional range-voxel fusion to turn one sparse sweep into dense semantic occupancy.
If this is right
- Removes the extra compute and memory cost of stacking multiple sweeps.
- Avoids errors introduced by pose estimation when aligning successive scans.
- Delivers both higher accuracy and lower latency on standard occupancy benchmarks.
- Supports real-time scene representation without waiting for additional frames.
Where Pith is reading between the lines
- The same dual-view fusion pattern could be tested on other sparse sensors such as radar or event cameras.
- If the encoders prove view-agnostic, the architecture might transfer to indoor or robotic mapping tasks.
- A natural next measurement would be how much the fusion module alone contributes when range or voxel branches are ablated.
Load-bearing premise
Single-sweep point clouds already hold enough spatial and semantic information for the proposed encoders and fusion module to produce accurate occupancy maps.
What would settle it
On a held-out dataset or scene where single-sweep DRVR mIoU falls below the best multi-sweep baseline after identical training.
Figures
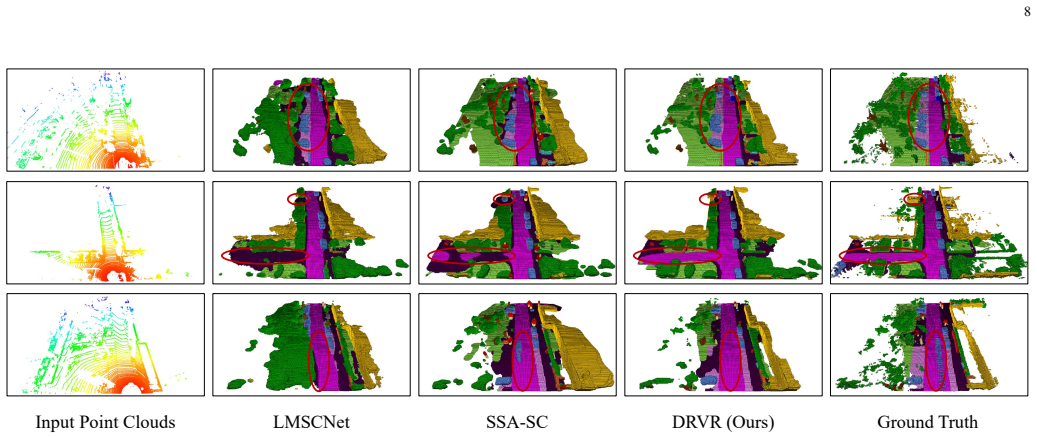
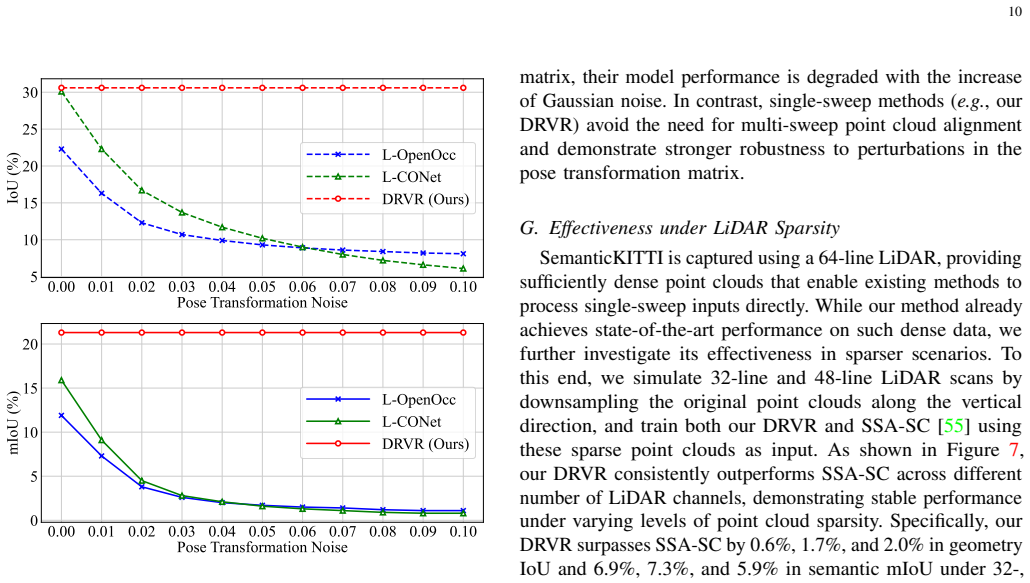
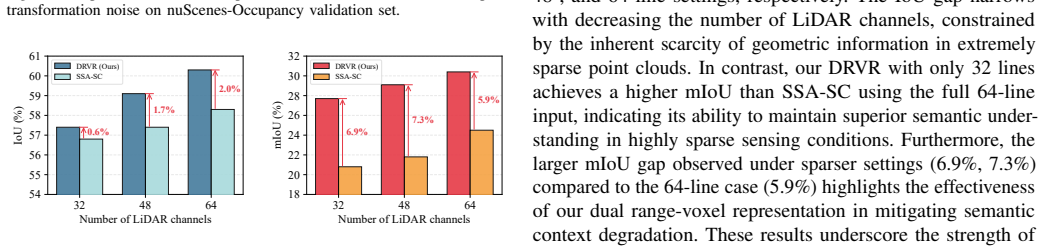
read the original abstract
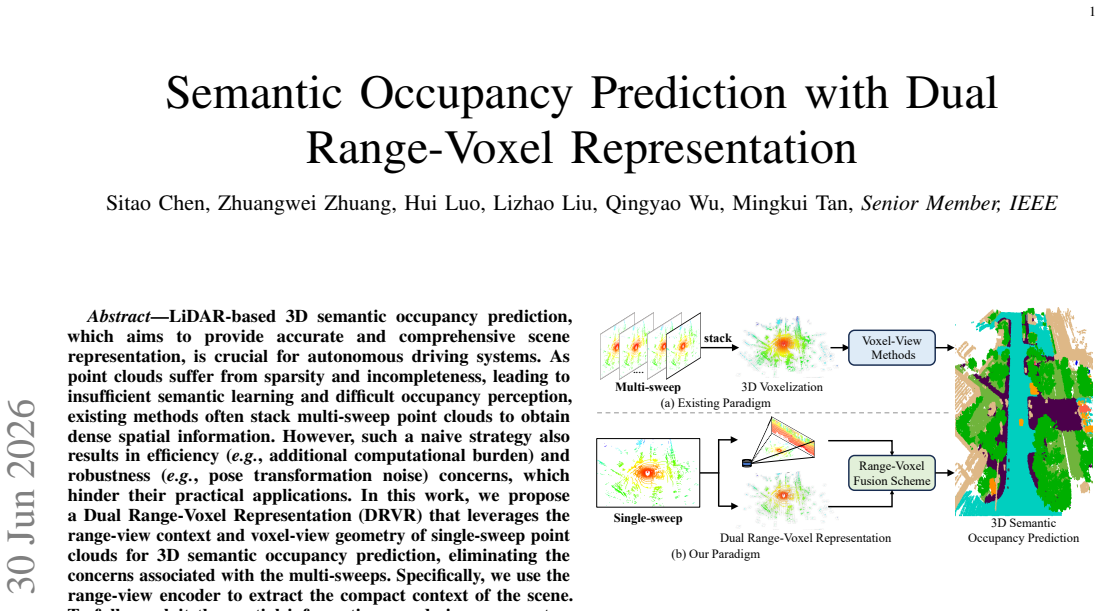
LiDAR-based 3D semantic occupancy prediction, which aims to provide accurate and comprehensive scene representation, is crucial for autonomous driving systems. As point clouds suffer from sparsity and incompleteness, leading to insufficient semantic learning and difficult occupancy perception, existing methods often stack multi-sweep point clouds to obtain dense spatial information. However, such a naive strategy also results in efficiency (e.g., additional computational burden) and robustness (e.g., pose transformation noise) concerns, which hinder their practical applications. In this work, we propose a Dual Range-Voxel Representation (DRVR) that leverages the range-view context and voxel-view geometry of single-sweep point clouds for 3D semantic occupancy prediction, eliminating the concerns associated with the multi-sweeps. Specifically, we use the range-view encoder to extract the compact context of the scene. To fully exploit the spatial information, we design a geometry-aware voxel-view encoder that extracts multi-scale voxel-view features separately and combines them for better geometric occupancy prediction. Moreover, we propose a range-voxel fusion module to cooperate range- and voxel-view features via voxel-to-range and range-to-voxel fusions. Extensive experiments on nuScenes-Occupancy, SemanticKITTI and SemanticPOSS show the superiority of our method. Especially on nuScenes-Occupancy, our single-sweep DRVR achieves 5.4% improvement in mIoU and 2.1x acceleration compared to the multi-sweep method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dual Range-Voxel Representation (DRVR) for LiDAR-based 3D semantic occupancy prediction from single-sweep point clouds. It consists of a range-view encoder to extract compact scene context, a geometry-aware voxel-view encoder that extracts and combines multi-scale voxel features, and a range-voxel fusion module that performs voxel-to-range and range-to-voxel feature cooperation. Experiments on nuScenes-Occupancy, SemanticKITTI, and SemanticPOSS demonstrate that the single-sweep DRVR outperforms multi-sweep baselines, with a reported 5.4% mIoU gain and 2.1x acceleration on nuScenes-Occupancy.
Significance. If the quantitative results hold, the work is significant because it shows that a dual range-voxel architecture can extract sufficient spatial and semantic information from single-sweep LiDAR to exceed multi-sweep methods in both accuracy and speed. This directly addresses efficiency and robustness limitations of multi-sweep stacking, with potential practical value for real-time autonomous driving. The explicit separation and fusion of range-view context and voxel-view geometry is a clear technical contribution.
major comments (2)
- [§4] §4 (nuScenes-Occupancy results): the 5.4% mIoU improvement is stated relative to 'the multi-sweep method' without identifying the exact baseline architecture, training protocol, or whether numbers are re-implemented vs. published; this detail is load-bearing for the central claim that single-sweep DRVR is superior.
- [§3.3] §3.3 (range-voxel fusion module): the voxel-to-range and range-to-voxel fusion operations are described at a high level but lack explicit equations or pseudocode for feature transformation and aggregation; without this, it is difficult to verify how the module enables accurate occupancy from single-sweep input alone.
minor comments (2)
- The abstract and §4 would benefit from a brief statement of the loss function and training hyperparameters to support reproducibility of the reported gains.
- [Figure 2] Figure 2 (architecture overview): adding labels for the multi-scale feature paths in the geometry-aware voxel-view encoder would improve clarity of how geometric information is extracted.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the constructive comments. We address each major comment below and will revise the manuscript to improve clarity on the points raised.
read point-by-point responses
-
Referee: [§4] §4 (nuScenes-Occupancy results): the 5.4% mIoU improvement is stated relative to 'the multi-sweep method' without identifying the exact baseline architecture, training protocol, or whether numbers are re-implemented vs. published; this detail is load-bearing for the central claim that single-sweep DRVR is superior.
Authors: We agree that explicit identification of the baseline is necessary for reproducibility and to support the central claim. The reported 5.4% mIoU gain and 2.1x acceleration on nuScenes-Occupancy are obtained by re-implementing the multi-sweep baseline from the nuScenes-Occupancy benchmark paper under identical training settings and data splits as our single-sweep DRVR. We will revise Section 4 to name the exact baseline architecture, cite its source, state that all numbers are from our controlled re-implementation, and confirm the training protocol details. revision: yes
-
Referee: [§3.3] §3.3 (range-voxel fusion module): the voxel-to-range and range-to-voxel fusion operations are described at a high level but lack explicit equations or pseudocode for feature transformation and aggregation; without this, it is difficult to verify how the module enables accurate occupancy from single-sweep input alone.
Authors: We acknowledge that the current description of the range-voxel fusion module in Section 3.3 is high-level. To address this, we will add explicit mathematical formulations for both the voxel-to-range and range-to-voxel fusion operations, including the feature transformation matrices, aggregation functions, and how the fused features are used for final occupancy prediction. This addition will clarify the mechanism by which single-sweep range-view context and voxel-view geometry cooperate. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes an architecture (range-view encoder + geometry-aware voxel-view encoder + range-voxel fusion) and validates it via experiments on nuScenes-Occupancy, SemanticKITTI, and SemanticPOSS. The central performance claims (5.4% mIoU gain, 2.1x speedup) are empirical results from standard benchmarks, not derived quantities that reduce by construction to fitted inputs, self-citations, or renamed patterns. No equations, self-definitional steps, or load-bearing self-citations appear in the provided text; the derivation chain is the module design itself, which remains independent of the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single-sweep LiDAR point clouds contain sufficient information for accurate 3D semantic occupancy when processed with dual range-voxel representations
invented entities (1)
-
Dual Range-Voxel Representation (DRVR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 3354–3361
2012
-
[2]
The apolloscape dataset for autonomous driving,
X. Huang, X. Cheng, Q. Geng, B. Cao, D. Zhou, P. Wang, Y . Lin, and R. Yang, “The apolloscape dataset for autonomous driving,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 954–960
2018
-
[3]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,
Y . Liao, J. Xie, and A. Geiger, “Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3292–3310, 2022
2022
-
[4]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2446–2454
2020
-
[5]
Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,
X. Bai, Z. Hu, X. Zhu, Q. Huang, Y . Chen, H. Fu, and C.-L. Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1090–1099
2022
-
[6]
Multi-view 3d object detection network for autonomous driving,
X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 1907–1915
2017
-
[7]
Deepfusion: Lidar-camera deep fusion for multi- modal 3d object detection,
Y . Li, A. W. Yu, T. Meng, B. Caine, J. Ngiam, D. Peng, J. Shen, Y . Lu, D. Zhou, Q. V . Leet al., “Deepfusion: Lidar-camera deep fusion for multi- modal 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 182–17 191
2022
-
[8]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 784–11 793
2021
-
[9]
Lidar-based panoptic segmentation via dynamic shifting network,
F. Hong, H. Zhou, X. Zhu, H. Li, and Z. Liu, “Lidar-based panoptic segmentation via dynamic shifting network,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13 090–13 099
2021
-
[10]
2dpass: 2d priors assisted semantic segmentation on lidar point clouds,
X. Yan, J. Gao, C. Zheng, C. Zheng, R. Zhang, S. Cui, and Z. Li, “2dpass: 2d priors assisted semantic segmentation on lidar point clouds,” inEuropean conference on computer vision. Springer, 2022, pp. 677– 695
2022
-
[11]
Panoptic-polarnet: Proposal-free lidar point cloud panoptic segmentation,
Z. Zhou, Y . Zhang, and H. Foroosh, “Panoptic-polarnet: Proposal-free lidar point cloud panoptic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13 194–13 203
2021
-
[12]
Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,
Z. Zhuang, R. Li, K. Jia, Q. Wang, Y . Li, and M. Tan, “Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 280–16 290
2021
-
[13]
Epmf: Efficient perception-aware multi-sensor fusion for 3d semantic segmentation,
M. Tan, Z. Zhuang, S. Chen, R. Li, K. Jia, Q. Wang, and Y . Li, “Epmf: Efficient perception-aware multi-sensor fusion for 3d semantic segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 8258–8273, 2024
2024
-
[14]
Sscbench: A large-scale 3d semantic scene completion benchmark for autonomous driving,
Y . Li, S. Li, X. Liu, M. Gong, K. Li, N. Chen, Z. Wang, Z. Li, T. Jiang, F. Yuet al., “Sscbench: A large-scale 3d semantic scene completion benchmark for autonomous driving,”arXiv preprint arXiv:2306.09001, 2023
arXiv 2023
-
[15]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,”Advances in neural information processing systems, vol. 37, 2023
2023
-
[16]
Robust 3d se- mantic occupancy prediction with calibration-free spatial transformation,
Z. Zhuang, Z. Wang, S. Chen, L. Liu, H. Luo, and M. Tan, “Robust 3d se- mantic occupancy prediction with calibration-free spatial transformation,” arXiv preprint arXiv:2411.12177, 2024
arXiv 2024
-
[17]
Linkocc: 3d semantic occupancy prediction with temporal association,
W. Ouyang, Z. Xu, B. Shen, J. Wang, and Y . Xu, “Linkocc: 3d semantic occupancy prediction with temporal association,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[18]
Lidar-camera continuous fusion in voxelized grid for semantic scene completion,
Z. Lu, B. Cao, and Q. Hu, “Lidar-camera continuous fusion in voxelized grid for semantic scene completion,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[19]
Adaptiveocc: Adaptive octree-based network for multi-camera 3d semantic occupancy prediction in autonomous driving,
T. Yang, Y . Qian, W. Yan, C. Wang, and M. Yang, “Adaptiveocc: Adaptive octree-based network for multi-camera 3d semantic occupancy prediction in autonomous driving,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[20]
Occ-exoskeleton: A plug-and-play module to enhance cnn-based occupancy prediction networks,
S. Wang, Y . Lu, and Q. Ling, “Occ-exoskeleton: A plug-and-play module to enhance cnn-based occupancy prediction networks,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[21]
Daocc: 3d object detection assisted multi-sensor fusion for 3d occupancy prediction,
Z. Yang, Y . Dong, J. Wang, H. Wang, L. Ma, Z. Cui, Q. Liu, H. Pei, K. Zhang, and C. Zhang, “Daocc: 3d object detection assisted multi-sensor fusion for 3d occupancy prediction,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[22]
Semantic scene completion via semantic-aware guidance and interactive refinement transformer,
H. Xiao, W. Kang, H. Liu, Y . Li, and Y . He, “Semantic scene completion via semantic-aware guidance and interactive refinement transformer,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[23]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang, “Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 850–17 859
2023
-
[24]
Oc- cgen: Generative multi-modal 3d occupancy prediction for autonomous driving,
G. Wang, Z. Wang, P. Tang, J. Zheng, X. Ren, B. Feng, and C. Ma, “Oc- cgen: Generative multi-modal 3d occupancy prediction for autonomous driving,” inEuropean conference on computer vision. Springer, 2024, pp. 95–112
2024
-
[25]
Monoscene: Monocular 3d semantic scene completion,
A.-Q. Cao and R. de Charette, “Monoscene: Monocular 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3991–4001
2022
-
[26]
Tri-perspective view for vision-based 3d semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Tri-perspective view for vision-based 3d semantic occupancy prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9223–9232
2023
-
[27]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,
Y . Li, Z. Yu, C. Choy, C. Xiao, J. M. Alvarez, S. Fidler, C. Feng, and A. Anandkumar, “V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9087–9098
2023
-
[28]
Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,
Y . Zhang, Z. Zhu, and D. Du, “Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9433– 9443
2023
-
[29]
Lmscnet: Lightweight multiscale 3d semantic completion,
L. Roldao, R. De Charette, and A. Verroust-Blondet, “Lmscnet: Lightweight multiscale 3d semantic completion,” in2020 International Conference on 3D Vision (3DV). IEEE, 2020, pp. 111–119
2020
-
[30]
Scpnet: Semantic scene completion on point cloud,
Z. Xia, Y . Liu, X. Li, X. Zhu, Y . Ma, Y . Li, Y . Hou, and Y . Qiao, “Scpnet: Semantic scene completion on point cloud,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 642–17 651
2023
-
[31]
Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion,
X. Yan, J. Gao, J. Li, R. Zhang, Z. Li, R. Huang, and S. Cui, “Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 4, 2021, pp. 3101–3109
2021
-
[32]
Co-occ: Coupling explicit feature fusion with volume rendering regularization for multi-modal 3d semantic occupancy prediction,
J. Pan, Z. Wang, and L. Wang, “Co-occ: Coupling explicit feature fusion with volume rendering regularization for multi-modal 3d semantic occupancy prediction,”IEEE Robotics and Automation Letters, 2024
2024
-
[33]
Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation,
H. Zhang, X. Yan, D. Bai, J. Gao, P. Wang, B. Liu, S. Cui, and Z. Li, “Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 7, 2024, pp. 7060–7068
2024
-
[34]
Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds,
T. Cortinhal, G. Tzelepis, and E. Erdal Aksoy, “Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds,” in International Symposium on Visual Computing. Springer, 2020, pp. 207–222
2020
-
[35]
Rangenet++: Fast and accurate lidar semantic segmentation,
A. Milioto, I. Vizzo, J. Behley, and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in2019 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2019, pp. 4213–4220
2019
-
[36]
Uniseg: A unified multi-modal lidar segmentation network and the openpcseg codebase,
Y . Liu, R. Chen, X. Li, L. Kong, Y . Yang, Z. Xia, Y . Bai, X. Zhu, Y . Ma, Y . Liet al., “Uniseg: A unified multi-modal lidar segmentation network and the openpcseg codebase,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 662–21 673
2023
-
[37]
Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation,
J. Xu, R. Zhang, J. Dou, Y . Zhu, J. Sun, and S. Pu, “Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 024–16 033
2021
-
[38]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020
Pith/arXiv arXiv 2010
-
[39]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210. 12
2020
-
[40]
Bevdet: High- performance multi-camera 3d object detection in bird-eye-view,
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du, “Bevdet: High- performance multi-camera 3d object detection in bird-eye-view,”arXiv preprint arXiv:2112.11790, 2021
Pith/arXiv arXiv 2021
-
[41]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2774–2781
2023
-
[42]
Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction,
P. Tang, Z. Wang, G. Wang, J. Zheng, X. Ren, B. Feng, and C. Ma, “Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 035–15 044
2024
-
[43]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,
Y . Wang, V . C. Guizilini, T. Zhang, Y . Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” inConference on robot learning. PMLR, 2022, pp. 180–191
2022
-
[44]
Symphonize 3d semantic scene completion with contextual instance queries,
H. Jiang, T. Cheng, N. Gao, H. Zhang, T. Lin, W. Liu, and X. Wang, “Symphonize 3d semantic scene completion with contextual instance queries,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 258–20 267
2024
-
[45]
Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” inEuropean conference on computer vision. Springer, 2022, pp. 1–18
2022
-
[46]
Viewformer: Exploring spatiotemporal modeling for multi-view 3d occupancy percep- tion via view-guided transformers,
J. Li, X. He, C. Zhou, X. Cheng, Y . Wen, and D. Zhang, “Viewformer: Exploring spatiotemporal modeling for multi-view 3d occupancy percep- tion via view-guided transformers,” inEuropean conference on computer vision. Springer, 2025, pp. 90–106
2025
-
[47]
Fully sparse 3d occupancy prediction,
H. Liu, Y . Chen, H. Wang, Z. Yang, T. Li, J. Zeng, L. Chen, H. Li, and L. Wang, “Fully sparse 3d occupancy prediction,”arXiv preprint arXiv:2312.17118, 2024
arXiv 2024
-
[48]
Octreeocc: Efficient and multi- granularity occupancy prediction using octree queries,
Y . Lu, X. Zhu, T. Wang, and Y . Ma, “Octreeocc: Efficient and multi- granularity occupancy prediction using octree queries,”arXiv preprint arXiv:2312.03774, 2023
arXiv 2023
-
[49]
Panoocc: Unified occupancy representation for camera-based 3d panoptic segmentation,
Y . Wang, Y . Chen, X. Liao, L. Fan, and Z. Zhang, “Panoocc: Unified occupancy representation for camera-based 3d panoptic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 158–17 168
2024
-
[50]
H2gformer: Horizontal-to-global voxel trans- former for 3d semantic scene completion,
Y . Wang and C. Tong, “H2gformer: Horizontal-to-global voxel trans- former for 3d semantic scene completion,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5722–5730
2024
-
[51]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 729–21 740
2023
-
[52]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009
2022
-
[53]
Context and geometry aware voxel transformer for semantic scene completion,
Z. Yu, R. Zhang, J. Ying, J. Yu, X. Hu, L. Luo, S.-Y . Cao, and H.-L. Shen, “Context and geometry aware voxel transformer for semantic scene completion,”Advances in Neural Information Processing Systems, vol. 37, pp. 1531–1555, 2024
2024
-
[54]
S3cnet: A sparse semantic scene completion network for lidar point clouds,
R. Cheng, C. Agia, Y . Ren, X. Li, and L. Bingbing, “S3cnet: A sparse semantic scene completion network for lidar point clouds,” inConference on robot learning. PMLR, 2021, pp. 2148–2161
2021
-
[55]
Semantic segmentation-assisted scene completion for lidar point clouds,
X. Yang, H. Zou, X. Kong, T. Huang, Y . Liu, W. Li, F. Wen, and H. Zhang, “Semantic segmentation-assisted scene completion for lidar point clouds,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 3555–3562
2021
-
[56]
Ssc-rs: Elevate lidar semantic scene completion with representation separation and bev fusion,
J. Mei, Y . Yang, M. Wang, T. Huang, X. Yang, and Y . Liu, “Ssc-rs: Elevate lidar semantic scene completion with representation separation and bev fusion,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 1–8
2023
-
[57]
V oxel proposal network via multi-frame knowledge distillation for semantic scene completion,
L. Wang, D. Lin, K. Yang, R. Liu, Q. Guo, W. Xie, M. Wang, L. Liang, Y . Wang, and P. Li, “V oxel proposal network via multi-frame knowledge distillation for semantic scene completion,”Advances in Neural Information Processing Systems, vol. 37, pp. 101 096–101 115, 2024
2024
-
[58]
Pointocc: Cylindrical tri-perspective view for point-based 3d semantic occupancy prediction,
S. Zuo, W. Zheng, Y . Huang, J. Zhou, and J. Lu, “Pointocc: Cylindrical tri-perspective view for point-based 3d semantic occupancy prediction,” arXiv preprint arXiv:2308.16896, 2023
arXiv 2023
-
[59]
Cenet: Toward concise and efficient lidar semantic segmentation for autonomous driving,
H.-X. Cheng, X.-F. Han, and G.-Q. Xiao, “Cenet: Toward concise and efficient lidar semantic segmentation for autonomous driving,” in2022 IEEE international conference on multimedia and expo (ICME). IEEE, 2022, pp. 01–06
2022
-
[60]
V oxelnet: End-to-end learning for point cloud based 3d object detection,
Y . Zhou and O. Tuzel, “V oxelnet: End-to-end learning for point cloud based 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4490–4499
2018
-
[61]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
2018
-
[62]
Spconv: Spatially sparse convolution library,
S. Contributors, “Spconv: Spatially sparse convolution library,” https: //github.com/traveller59/spconv, 2022
2022
-
[63]
Anisotropic convolutional networks for 3d semantic scene completion,
J. Li, K. Han, P. Wang, Y . Liu, and X. Yuan, “Anisotropic convolutional networks for 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3351–3359
2020
-
[64]
3d sketch-aware semantic scene completion via semi-supervised structure prior,
X. Chen, K.-Y . Lin, C. Qian, G. Zeng, and H. Li, “3d sketch-aware semantic scene completion via semi-supervised structure prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4193–4202
2020
-
[65]
Frnet: Frustum-range networks for scalable lidar segmentation,
X. Xu, L. Kong, H. Shuai, and Q. Liu, “Frnet: Frustum-range networks for scalable lidar segmentation,”arXiv preprint arXiv:2312.04484, 2023
arXiv 2023
-
[66]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2017, pp. 2980–2988
2017
-
[67]
Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations,
C. H. Sudre, W. Li, T. Vercauteren, S. Ourselin, and M. Jorge Cardoso, “Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations,” inDeep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Springer, 2017, pp. 240–248
2017
-
[68]
Semantickitti: A dataset for semantic scene understanding of lidar sequences,
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9297–9307
2019
-
[69]
Semanticposs: A point cloud dataset with large quantity of dynamic instances,
Y . Pan, B. Gao, J. Mei, S. Geng, C. Li, and H. Zhao, “Semanticposs: A point cloud dataset with large quantity of dynamic instances,” in2020 IEEE intelligent vehicles symposium (IV). IEEE, 2020, pp. 687–693
2020
-
[70]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 621–11 631
2020
-
[71]
Vishall3d: Monocular semantic scene completion from reconstructing the visible regions to hallucinating the invisible regions,
H. Lu, Y . Su, X. Zhang, L. Gao, Y . Xue, and L. Wang, “Vishall3d: Monocular semantic scene completion from reconstructing the visible regions to hallucinating the invisible regions,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 674–28 684
2025
-
[72]
Semantic scene completion from a single depth image,
S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic scene completion from a single depth image,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 1746–1754
2017
-
[73]
Efficient semantic scene completion network with spatial group convolution,
J. Zhang, H. Zhao, A. Yao, Y . Chen, L. Zhang, and H. Liao, “Efficient semantic scene completion network with spatial group convolution,” in European conference on computer vision, 2018, pp. 733–749
2018
-
[74]
Two stream 3d semantic scene completion,
M. Garbade, Y .-T. Chen, J. Sawatzky, and J. Gall, “Two stream 3d semantic scene completion,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2019, pp. 0–0
2019
-
[75]
Up-to-down network: Fusing multi-scale context for 3d semantic scene completion,
H. Zou, X. Yang, T. Huang, C. Zhang, Y . Liu, W. Li, F. Wen, and H. Zhang, “Up-to-down network: Fusing multi-scale context for 3d semantic scene completion,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 16–23
2021
-
[76]
Semantic scene completion using local deep implicit functions on lidar data,
C. B. Rist, D. Emmerichs, M. Enzweiler, and D. M. Gavrila, “Semantic scene completion using local deep implicit functions on lidar data,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 10, pp. 7205–7218, 2021
2021
-
[77]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[78]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.