Large Databases Need Small, Open-Weight Language Models
Pith reviewed 2026-07-01 05:26 UTC · model grok-4.3
The pith
Quantized open-weight models on 16GB VRAM match closed-source accuracy for database tasks at lower cost and latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
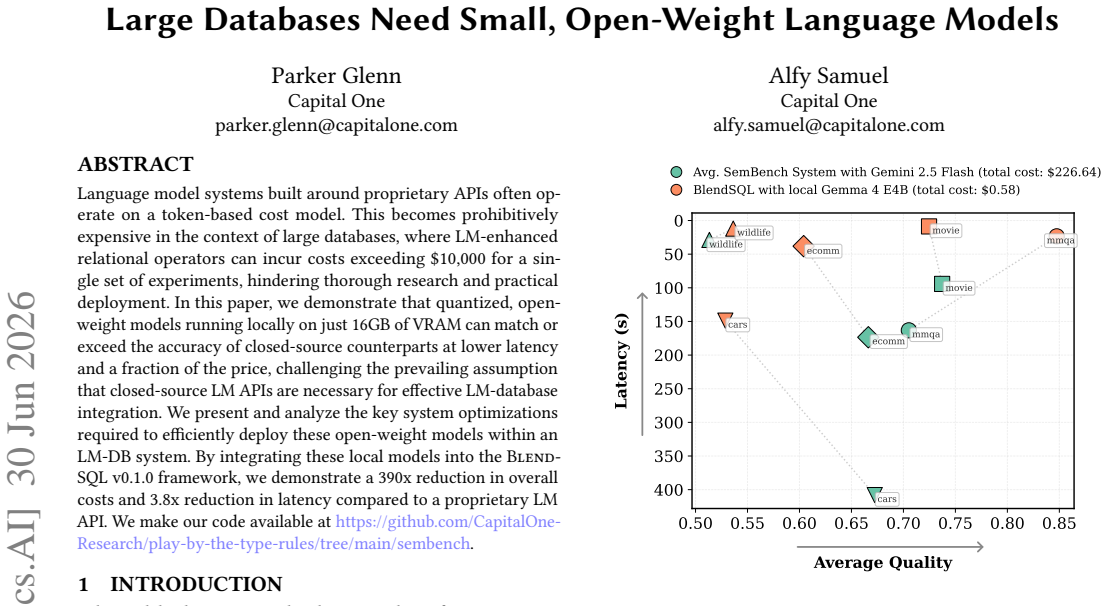
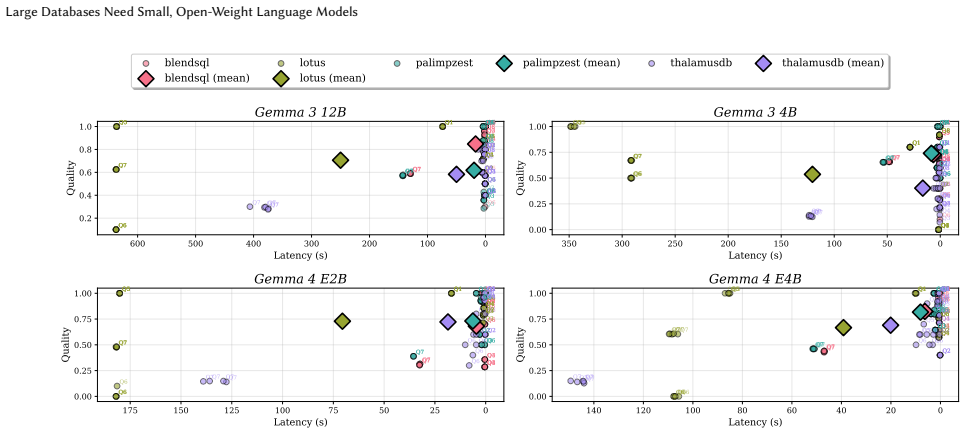
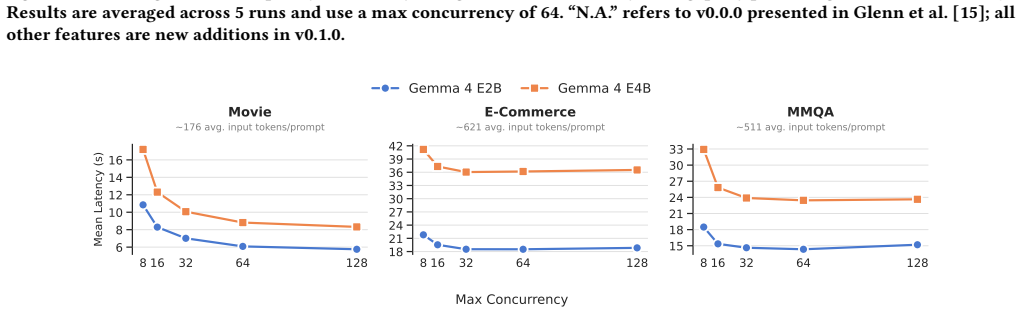
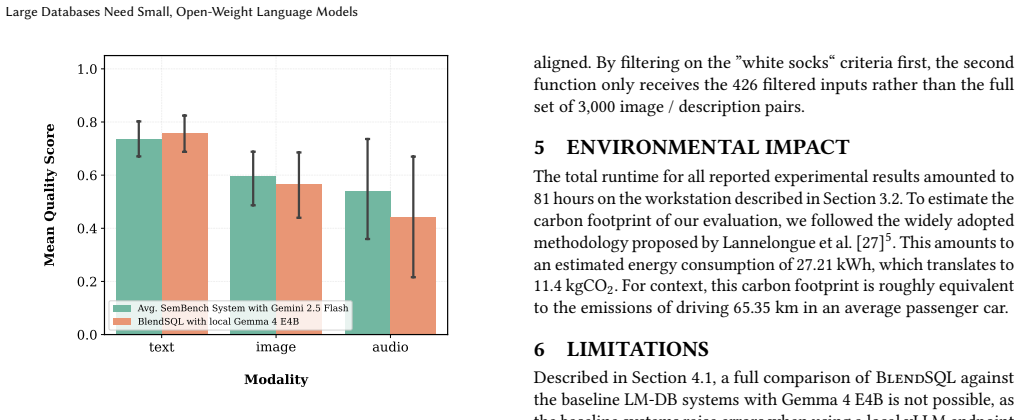
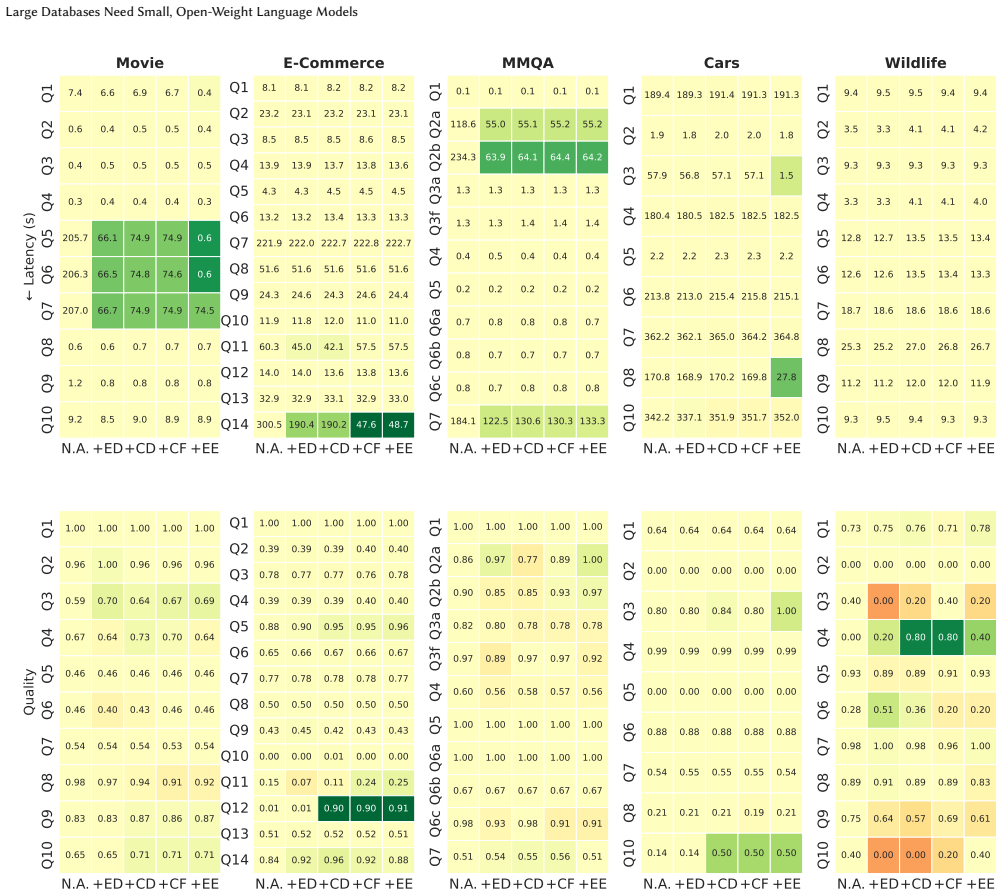
Quantized, open-weight models running locally on just 16GB of VRAM can match or exceed the accuracy of closed-source counterparts at lower latency and a fraction of the price for LM-enhanced relational operators on large databases, demonstrated by their deployment in the BlendSQL v0.1.0 framework that yields a 390x reduction in overall costs and 3.8x reduction in latency.
What carries the argument
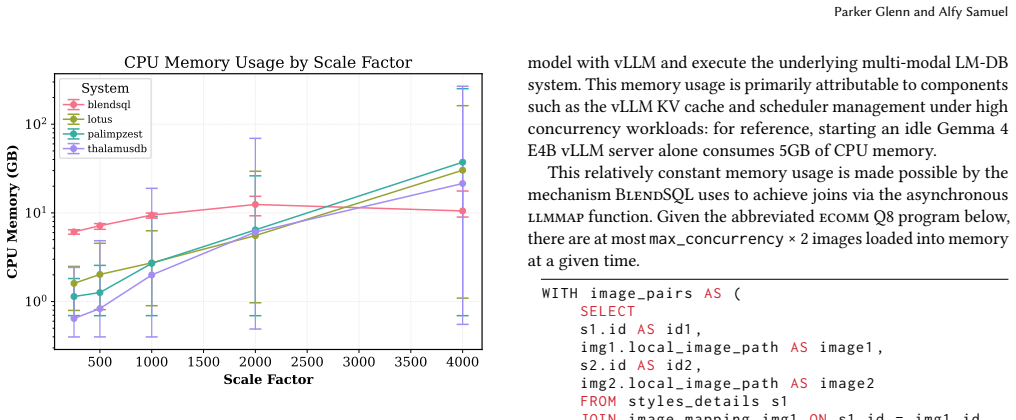
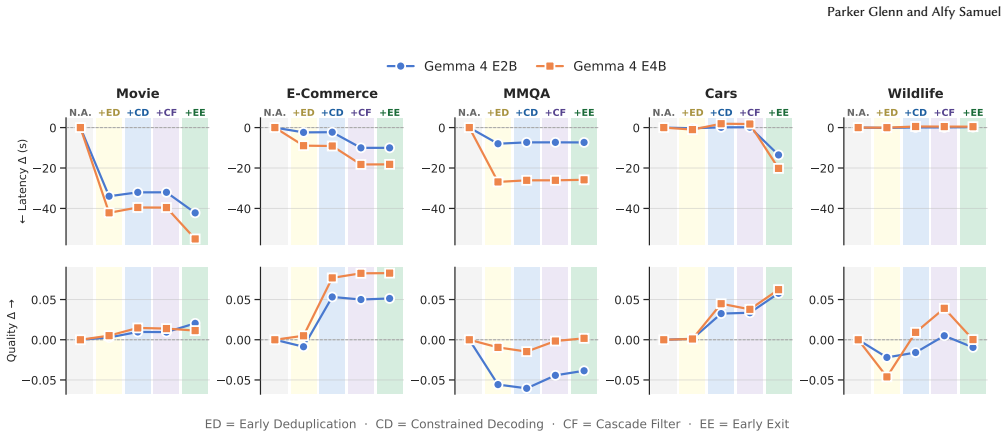
System optimizations required to efficiently deploy open-weight models locally within an LM-DB system, integrated into the BlendSQL framework.
If this is right
- LM-enhanced relational operators on large databases become feasible without incurring prohibitive API expenses.
- Thorough experimentation and practical deployment of LM-database systems can occur at a small fraction of prior costs.
- Local model execution supplies lower latency than remote API calls for the same relational operators.
- Open-weight models can serve as direct replacements for proprietary APIs in this application class.
Where Pith is reading between the lines
- The same local-model strategy may transfer to other high-volume token-consumption settings outside databases.
- Additional hardware-constrained environments could benefit from similar quantization and deployment tuning.
- Testing the approach on a wider variety of database schemas and query patterns would test its generality.
Load-bearing premise
The specific tasks, datasets, and accuracy metrics used inside the BlendSQL v0.1.0 framework are representative of the broader class of LM-enhanced relational operators on large databases.
What would settle it
A set of experiments on different LM-enhanced database tasks or datasets where the local quantized models produce lower accuracy than the closed-source models would disprove the central claim.
Figures

read the original abstract
Language model systems built around proprietary APIs often operate on a token-based cost model. This becomes prohibitively expensive in the context of large databases, where LM-enhanced relational operators can incur costs exceeding $10,000 for a single set of experiments, hindering thorough research and practical deployment. In this paper, we demonstrate that quantized, open-weight models running locally on just 16GB of VRAM can match or exceed the accuracy of closed-source counterparts at lower latency and a fraction of the price, challenging the prevailing assumption that closed-source LM APIs are necessary for effective LM-database integration. We present and analyze the key system optimizations required to efficiently deploy these open-weight models within an LM-DB system. By integrating these local models into the BlendSQL v0.1.0 framework, we demonstrate a 390x reduction in overall costs and 3.8x reduction in latency compared to a proprietary LM API. We make our code available at https://github.com/CapitalOne-Research/play-by-the-type-rules/tree/main/sembench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that quantized open-weight language models running locally on 16GB VRAM can match or exceed closed-source LM API accuracy for LM-enhanced relational operators on large databases, at lower latency and far lower cost. It reports a 390x overall cost reduction and 3.8x latency reduction when integrating these models into the BlendSQL v0.1.0 framework, along with the system optimizations needed for efficient local deployment, and releases the code.
Significance. If the accuracy equivalence is shown to hold under representative conditions, the result would meaningfully lower barriers to LM-DB research and deployment by removing dependence on token-priced proprietary APIs. The open release of code is a concrete strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the numerical claims (accuracy match/exceed, 390x cost reduction, 3.8x latency) are presented without any description of the tasks, datasets, controls, error bars, or statistical tests used to obtain them, so the central performance assertions cannot be evaluated from the given text.
- [BlendSQL v0.1.0 framework] BlendSQL v0.1.0 integration section: the accuracy equivalence between quantized open-weight models and closed-source APIs is demonstrated only inside this framework; the manuscript supplies no argument or additional experiments showing that the chosen predicates, table sizes, or accuracy definitions are representative of the general class of LM-enhanced relational operators on large databases.
minor comments (1)
- [Abstract] The GitHub link in the abstract ends in a tree path; ensure the final URL resolves to the exact code and data used for the reported BlendSQL experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the numerical claims (accuracy match/exceed, 390x cost reduction, 3.8x latency) are presented without any description of the tasks, datasets, controls, error bars, or statistical tests used to obtain them, so the central performance assertions cannot be evaluated from the given text.
Authors: We agree that the abstract would be improved by additional context. In the revised manuscript we will expand the abstract to briefly describe the BlendSQL tasks (LM-enhanced relational operators such as semantic filters and joins), the datasets and table sizes used, and note that accuracy, cost, and latency results include error bars from repeated runs with full experimental controls and details reported in the main body. revision: yes
-
Referee: [BlendSQL v0.1.0 framework] BlendSQL v0.1.0 integration section: the accuracy equivalence between quantized open-weight models and closed-source APIs is demonstrated only inside this framework; the manuscript supplies no argument or additional experiments showing that the chosen predicates, table sizes, or accuracy definitions are representative of the general class of LM-enhanced relational operators on large databases.
Authors: BlendSQL is explicitly constructed to realize LM-enhanced relational operators, and the predicates, table sizes, and accuracy metrics in our experiments follow the framework's standard usage patterns for large-database scenarios. We will add an explicit discussion paragraph arguing for representativeness based on the framework design and typical LM-DB workloads. We do not provide experiments in other frameworks, as that would be outside the paper's scope; the contribution centers on showing local-model viability within an established LM-DB system. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivation chain
full rationale
The paper presents direct empirical comparisons of quantized open-weight models versus closed-source APIs inside the BlendSQL v0.1.0 framework, reporting measured accuracy equivalence, 390x cost reduction, and 3.8x latency reduction. No equations, fitted parameters, predictions, or uniqueness theorems are invoked; the central claims rest on experimental runs rather than any reduction of outputs to inputs by construction. Self-citations are absent from the provided text, and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Florian Angermeir, Maximilian Amougou, Mark Kreitz, Andreas Bauer, Matthias Linhuber, Davide Fucci, Daniel Mendez, Tony Gorschek, et al. 2025. Reflections on the Reproducibility of Commercial LLM Performance in Empirical Software Engineering Studies.arXiv preprint arXiv:2510.25506(2025)
-
[2]
Samuel Arch, Yuchen Liu, Todd C Mowry, Jignesh M Patel, and Andrew Pavlo
-
[3]
The key to effective udf optimization: Before inlining, first perform outlin- ing.Proceedings of the VLDB Endowment18, 1 (2024), 1–13
2024
-
[4]
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei Ji, Eric Chang, Tackeun Kim, et al . 2023. Ehrxqa: A multi-modal question answering dataset for electronic health records with chest x-ray images.Advances in Neural Information Processing Systems36 (2023), 3867–3880
2023
-
[5]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. How is ChatGPT’s behavior changing over time?Harvard Data Science Review6, 2 (2024)
2024
-
[6]
Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, et al. 2023. Binding Language Models in Symbolic Languages. InInternational Conference on Learning Representations (ICLR 2023)(01/05/2023-05/05/2023, Kigali, Rwanda)
2023
-
[7]
Electric Choice. 2026. Electricity Rates by State. https://www.electricchoice.com/ electricity-prices-by-state/. Accessed: 2026-05-28
2026
-
[8]
Suparno Roy Chowdhury, Manan Roy Choudhury, Tejas Anvekar, Muham- mad Ali Khan, Kaneez Zahra Rubab Khakwani, Mohamad Bassam Sonbol, Ir- baz Bin Riaz, and Vivek Gupta. 2026. Diagnosis, Bad Planning & Reasoning. Treatment, SCOPE–Planning for Hybrid Querying over Clinical Trial Data.arXiv preprint arXiv:2604.25120(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Daniel Deutsch, Shyam Upadhyay, and Dan Roth. 2019. A general-purpose algo- rithm for constrained sequential inference. InProceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). 482–492
2019
- [10]
-
[11]
Anas Dorbani, Sunny Yasser, Jimmy Lin, and Amine Mhedhbi. 2025. Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB. (2025)
2025
-
[12]
Yannis Foufoulas, Theoni Palaiologou, and Alkis Simitsis. 2025. The UDFBench Benchmark for General-purpose UDF Queries.Proceedings of the VLDB Endow- ment18, 9 (2025), 2804–2817
2025
-
[13]
Yannis Foufoulas and Alkis Simitsis. 2023. Efficient execution of user-defined functions in SQL queries.Proceedings of the VLDB Endowment16, 12 (2023), 3874–3877
2023
- [14]
- [15]
-
[16]
Parker Glenn, Parag Dakle, Liang Wang, and Preethi Raghavan. 2024. BlendSQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra. InFindings of the Association for Computational Linguistics ACL 2024. 453–466
2024
-
[17]
Parker Glenn, Alfy Samuel, and Daben Liu. [n.d.]. Play by the Type Rules: Inferring Constraints for Small Language Models in Declarative Programs. In EurIPS 2025 Workshop: AI for Tabular Data
2025
-
[18]
Google. [n.d.]. Announcing BigQuery-managed AI functions for better SQL. https://cloud.google.com/blog/products/data-analytics/sql-reimagined- for-the-ai-era-with-bigquery-ai-functions. Accessed: 2026-05-07
2026
-
[19]
Google. 2018. What a week! 105 announcements from Google Cloud Next ’18. https://blog.google/innovation-and-ai/infrastructure-and-cloud/google- cloud/100-plus-announcements-from-google-cloud-next-18/. Accessed: 2026- 05-13
2018
-
[20]
Guidance. 2023. Guidance: A language model programming framework. https: //github.com/guidance-ai/guidance. Accessed: 2025-08-11
2023
-
[21]
Jiawei Han, Yongjian Fu, Wei Wang, Krzysztof Koperski, Osmar Zaiane, et al
-
[22]
DMQL: A data mining query language for relational databases. InProc. 1996 SiGMOD, Vol. 96. 27–34
1996
-
[23]
Joe Hellerstein, Christopher Ré, Florian Schoppmann, Daisy Zhe Wang, Eugene Fratkin, Aleksander Gorajek, Kee Siong Ng, Caleb Welton, Xixuan Feng, Kun Li, et al. 2012. The MADlib analytics library or MAD skills, the SQL.arXiv preprint arXiv:1208.4165(2012). Large Databases Need Small, Open-Weight Language Models
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[24]
Tomasz Imieliński and Aashu Virmani. 1999. MSQL: A query language for database mining.Data Mining and Knowledge Discovery3, 4 (1999), 373–408
1999
-
[25]
Saehan Jo and Immanuel Trummer. 2024. Thalamusdb: Approximate query processing on multi-modal data.Proceedings of the ACM on Management of Data 2, 3 (2024), 1–26
2024
- [26]
- [27]
-
[28]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[29]
Loïc Lannelongue, Jason Grealey, and Michael Inouye. 2021. Green algorithms: quantifying the carbon footprint of computation.Advanced science8, 12 (2021), 2100707
2021
- [30]
-
[31]
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. 2026. Meta-Harness: End-to-End Optimization of Model Harnesses. arXiv preprint arXiv:2603.28052(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [32]
-
[33]
Yin Lin, Tianjing Zeng, Zhongjun Ding, Rong Zhu, Bolin Ding, HV Jagadish, and Jingren Zhou. 2026. SEMA-SQL: Beyond Traditional Relational Querying with Large Language Models.arXiv preprint arXiv:2604.23477(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Benjamin Lipkin, Benjamin LeBrun, Jacob Hoover Vigly, João Loula, David R MacIver, Li Du, Jason Eisner, Ryan Cotterell, Vikash Mansinghka, Timothy J O’Donnell, et al. 2025. Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling.arXiv preprint arXiv:2504.05410(2025)
-
[35]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
2025
-
[36]
Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E Gonza- lez, Ion Stoica, and Matei Zaharia. 2024. Optimizing llm queries in relational workloads.CoRR(2024)
2024
-
[37]
Qiuyang Mang, Yufan Xiang, Hangrui Zhou, Runyuan He, Jiaxiang Yu, Hanchen Li, Aditya Parameswaran, and Alvin Cheung. 2026. Horrila: Cost-Based Placement of Semantic Operators in Hybrid Query Plans.arXiv preprint arXiv:2604.09944(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Toby Mao. [n.d.]. SQLGlot: Python SQL Parser and Transpiler. https://github. com/tobymao/sqlglot
-
[39]
Rosa Meo, Giuseppe Psaila, Stefano Ceri, et al. 1996. A new SQL-like operator for mining association rules. InVLDB, Vol. 96. 122–133
1996
-
[40]
Microsoft. 2017. What’s new in SQL Server 2017. https://learn.microsoft.com/en- us/sql/sql-server/what-s-new-in-sql-server-2017?view=sql-server-ver17. Ac- cessed: 2026-05-13
2017
-
[41]
Niels Mündler, Jingxuan He, Hao Wang, Koushik Sen, Dawn Song, and Mar- tin Vechev. 2025. Type-Constrained Code Generation with Language Models. Proceedings of the ACM on Programming Languages9, PLDI (2025), 601–626
2025
-
[42]
doi:10.5281/zenodo.3509134 , version =
The pandas development team. 2020.pandas-dev/pandas: Pandas. https://doi. org/10.5281/zenodo.3509134
- [43]
- [45]
-
[46]
Polars. 2022. Polars: Extremely fast Query Engine for DataFrames, written in Rust. https://github.com/pola-rs/polars. Accessed: 2026-04-23
2022
-
[47]
2025.PostgreSQL: The World’s Most Advanced Open Source Relational Database
PostgreSQL. 2025.PostgreSQL: The World’s Most Advanced Open Source Relational Database. https://www.postgresql.org/
2025
-
[48]
Mark Raasveldt and Hannes Mühleisen. 2019. Duckdb: an embeddable analytical database. InProceedings of the 2019 international conference on management of data. 1981–1984
2019
- [49]
-
[50]
salad.com. [n.d.]. Salad.com 5080 Pricing. https://salad.com/pricing. Accessed: 2026-04-25
2026
-
[51]
Nima Shahbazi, Seiji Maekawa, Nikita Bhutani, and Estevam Hruschka. 2026. Om- niTQA: A Cost-Aware System for Hybrid Query Processing over Semi-Structured Data.arXiv preprint arXiv:2604.02444(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Yunxiang Su, Tianjing Zeng, Zhongjun Ding, Yin Lin, Rong Zhu, Zhewei Wei, Bolin Ding, and Jingren Zhou. 2026. Large Language Model-Enhanced Relational Operators: Taxonomy, Benchmark, and Analysis.arXiv preprint arXiv:2603.02537 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Gemma Team. [n.d.]. Gemma 4. https://deepmind.google/models/gemma/ gemma-4/
-
[54]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieil- lard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Shicheng Liu Jialiang Xu Wesley Tjangnaka, Sina J Semnani Chen Jie Yu, and Monica S Lam. 2024. SUQL: Conversational Search over Structured and Unstruc- tured Data with Large Language Models. (2024)
2024
-
[56]
Transaction Processing Performance Council (TPC). [n.d.]. TPC-DS Benchmark. https://www.tpc.org/tpcds/
-
[57]
Transaction Processing Performance Council (TPC). [n.d.]. TPC-H Benchmark. https://www.tpc.org/tpch/
-
[58]
Shangqing Tu, Chunyang Li, Jifan Yu, Xiaozhi Wang, Lei Hou, and Juanzi Li
- [59]
-
[60]
Vast.ai. [n.d.]. Vast.ai 5080 Pricing. https://cloud.vast.ai. Accessed: 2026-04-25
2026
- [61]
-
[62]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [63]
-
[64]
Brandon T Willard and Rémi Louf. 2023. Efficient guided generation for large language models.arXiv preprint arXiv:2307.09702(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [65]
- [66]
-
[67]
Lixi Zhou, Qi Lin, Kanchan Chowdhury, Saif Masood, Alexandre Eichenberger, Hong Min, Alexander Sim, Jie Wang, Yida Wang, Kesheng Wu, et al. 2023. Serving Deep Learning Model in Relational Databases.arXiv preprint arXiv:2310.04696 (2023). 9 APPENDIX 9.1 vLLM Config All local vLLM servers were launched using the following command withvLLM==0.21.0 vllm serve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.