LuxEmo: Expressive Text-to-Speech Corpus for Luxembourgish
Pith reviewed 2026-07-03 21:55 UTC · model grok-4.3
The pith
LuxEmo supplies a 21-hour expressive speech corpus for Luxembourgish covering four emotions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
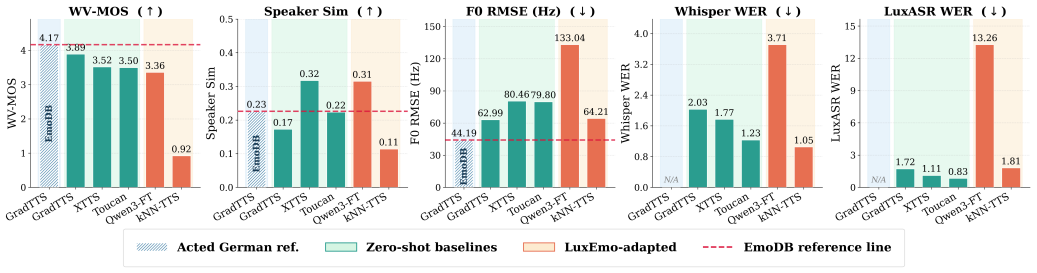
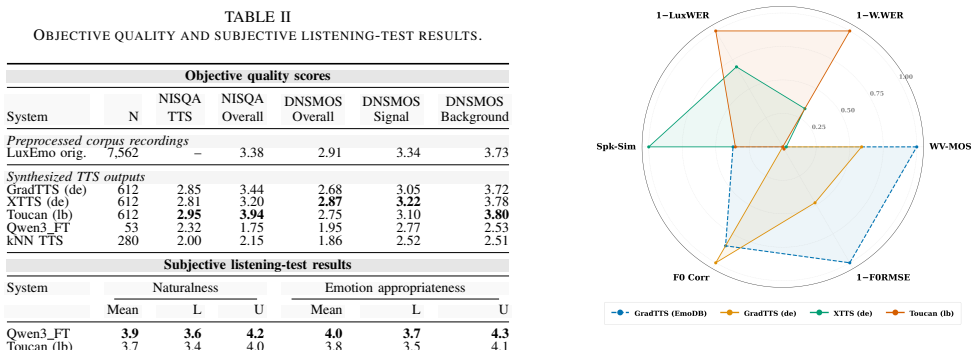
LuxEmo is a 21-hour conversational expressive speech corpus for Luxembourgish with four emotion categories, created through a semi-automatic curation workflow from RTL youth broadcasts and used to benchmark five expressive TTS systems covering German-based cross-lingual transfer, multilingual Luxembourgish support, Luxembourgish adaptation, and non-parametric prosody transfer, with evaluation via both objective metrics and human evaluation.
What carries the argument
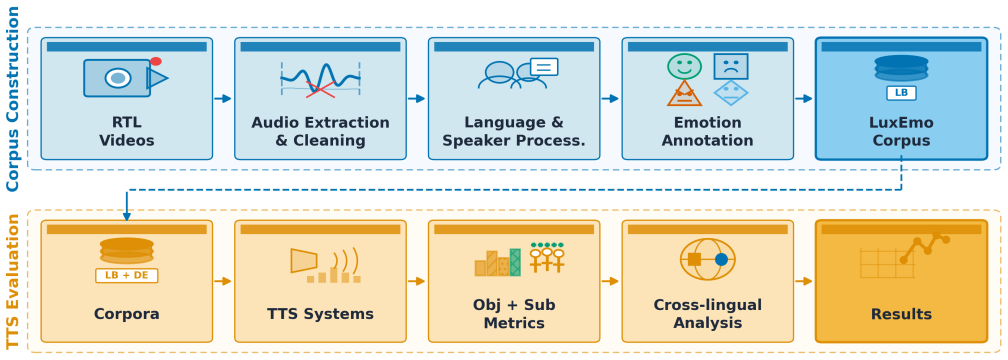
The semi-automatic curation workflow that combines automated voice activity detection, LuxASR segmentation, automatic emotion prediction, lexical cues, and targeted human review to extract clean expressive segments.
If this is right
- Luxembourgish expressive TTS models can now be trained and compared using a dedicated local dataset rather than relying solely on transfer from other languages.
- The same curation steps can be reused to expand the corpus or adapt it for additional emotion categories.
- Cross-lingual transfer from German and multilingual Luxembourgish models become directly testable against a language-specific expressive baseline.
- Non-parametric prosody transfer methods gain a new evaluation target in a conversational, low-resource setting.
Where Pith is reading between the lines
- Broadcast archives in other low-resource languages could be processed with similar pipelines to create expressive corpora without starting from scratch.
- The 21-hour size sets a practical lower bound for initial expressive TTS experiments in similar languages.
- If the human review step proves scalable, the workflow could reduce the cost barrier for creating emotion-labeled data in additional languages.
Load-bearing premise
Automated detection and prediction tools plus limited human review produce emotion labels and audio segments that are accurate enough for TTS training without major errors or source bias.
What would settle it
Manual review of a random subset of LuxEmo segments showing frequent mismatches between predicted and actual emotion labels or substantial remaining noise would undermine the corpus quality claim.
Figures

read the original abstract
State-of-the-art speech datasets predominantly focus on widely spoken languages, often overlooking low-resource languages such as Luxembourgish, which remain underrepresented in speech technology research. In this work, we introduce LuxEmo, a 21-hour conversational expressive speech corpus for Luxembourgish with 4 emotion categories. LuxEmo is derived from Radio T\'el\'evision Luxembourg (RTL) youth broadcasts, using automated detection followed by human validation. We propose a semi-automatic curation workflow combining voice activity detection, denoising, language identification, LuxASR-based segmentation, automatic emotion prediction, lexical cues, and targeted human review. Additionally, we benchmark five expressive TTS systems covering German-based cross-lingual transfer, multilingual Luxembourgish support, Luxembourgish adaptation, and non-parametric prosody transfer. Performance is evaluated using both objective metrics and human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LuxEmo, a 21-hour conversational expressive speech corpus for Luxembourgish with 4 emotion categories, derived from RTL youth radio broadcasts via a semi-automatic curation workflow (voice activity detection, denoising, language identification, LuxASR segmentation, automatic emotion prediction, lexical cues, and targeted human review). It additionally benchmarks five expressive TTS systems spanning German-based cross-lingual transfer, multilingual Luxembourgish support, Luxembourgish adaptation, and non-parametric prosody transfer, with evaluation via objective metrics and human evaluation.
Significance. If the emotion labels prove reliable, LuxEmo would fill a notable gap in expressive speech resources for a low-resource language, enabling targeted TTS research and providing a concrete benchmark for cross-lingual and adaptation methods in expressive synthesis.
major comments (2)
- [Section 3] Section 3 (Corpus Curation Workflow): The central claim that LuxEmo supplies a usable corpus with reliable 4-category emotion labels rests on the semi-automatic pipeline, yet no precision/recall, Cohen's kappa, or error analysis against a gold-standard subset is reported for the automatic emotion prediction or human review stages. This is load-bearing for downstream TTS benchmarking claims.
- [Section 4] Section 4 (TTS Benchmarking): Without quantified label accuracy, the reported objective and human evaluation results for the five TTS systems cannot be unambiguously attributed to the corpus properties rather than label noise or domain biases from the radio source material.
minor comments (2)
- [Abstract] Abstract and Section 2: The description of the 4 emotion categories lacks explicit definitions or examples of the lexical cues used for prediction.
- [Figure 1] Figure 1 (workflow diagram): The diagram would benefit from indicating the proportion of segments routed to human review versus fully automatic acceptance.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We address the major comments regarding the validation of emotion labels point by point.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Corpus Curation Workflow): The central claim that LuxEmo supplies a usable corpus with reliable 4-category emotion labels rests on the semi-automatic pipeline, yet no precision/recall, Cohen's kappa, or error analysis against a gold-standard subset is reported for the automatic emotion prediction or human review stages. This is load-bearing for downstream TTS benchmarking claims.
Authors: We agree that the manuscript does not report quantitative validation metrics such as precision/recall or Cohen's kappa for the emotion prediction and human review components. The workflow description emphasizes the combination of automatic tools with targeted human review to mitigate errors, but we acknowledge the value of providing error analysis. In the revised manuscript, we will add a subsection detailing an evaluation of the automatic emotion prediction against a manually annotated subset, including relevant metrics and discussion of the human review process. revision: yes
-
Referee: [Section 4] Section 4 (TTS Benchmarking): Without quantified label accuracy, the reported objective and human evaluation results for the five TTS systems cannot be unambiguously attributed to the corpus properties rather than label noise or domain biases from the radio source material.
Authors: We concur that the lack of quantified label accuracy makes it difficult to fully isolate the effects of the corpus from potential label noise. The current evaluations include both objective metrics and human listening tests to assess the TTS systems. In the revision, we will incorporate a discussion of possible label noise effects and any available qualitative insights from the curation process into Section 4, and consider additional experiments if feasible. revision: partial
Circularity Check
No circularity: descriptive corpus release with no derivations or fitted predictions
full rationale
The paper introduces LuxEmo as a new speech corpus derived from radio broadcasts via a described semi-automatic workflow (VAD, LuxASR segmentation, automatic emotion prediction, human review) and then benchmarks existing TTS systems. No equations, first-principles derivations, parameter fitting, or predictions are present in the provided text or abstract. The central claims concern data curation and benchmark results rather than any quantity derived from prior outputs of the same paper. No self-citation chains or ansatzes are invoked to justify a mathematical result. The workflow is presented as a practical engineering process without any reduction of outputs to inputs by construction. This is a standard data-release paper whose content is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Empathy by design: The influence of trembling ai voices on prosocial behavior,
F. Efthymiou and C. Hildebrand, “Empathy by design: The influence of trembling ai voices on prosocial behavior,”IEEE Transactions on Affective Computing, vol. 15, no. 3, pp. 1253–1263, 2023
2023
-
[2]
Towards empathetically responsive voice assistants,
T. Aggarwal and J. Goncalves, “Towards empathetically responsive voice assistants,” inProceedings of the 35th Australian Computer-Human Interaction Conference, 2023, pp. 669–678
2023
-
[3]
Emotionally situ- ated text-to-speech synthesis in user-agent conversation,
Y . Liu, H. Zhang, S. Liu, X. Yin, Z. Ma, and Q. Jin, “Emotionally situ- ated text-to-speech synthesis in user-agent conversation,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 5966–5974
2023
-
[4]
Empathic machines: Using intermediate features as levers to emu- late emotions in text-to-speech systems,
S. Kosgi, S. Sivaprasad, N. Pedanekar, A. Nelakanti, and V . Gandhi, “Empathic machines: Using intermediate features as levers to emu- late emotions in text-to-speech systems,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022, pp. 336–347
2022
-
[5]
What is the value of embedding artificial emotional prosody in human–computer interactions? implications for theory and design in psychological science,
R. L. Mitchell and Y . Xu, “What is the value of embedding artificial emotional prosody in human–computer interactions? implications for theory and design in psychological science,”Frontiers in psychology, vol. 6, p. 1750, 2015
2015
-
[6]
Controllable neural prosody synthesis,
M. Morrison, Z. Jin, J. Salamon, N. J. Bryan, and G. J. Mysore, “Controllable neural prosody synthesis,” inProc. Interspeech 2020, 2020, pp. 4437–4441
2020
-
[7]
Exploring Transfer Learning for Low Resource Emotional TTS
N. Tits, K. E. Haddad, and T. Dutoit, “Exploring transfer learning for low resource emotional tts,”ArXiv, vol. abs/1901.04276, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:58004671
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[8]
Low-resource expressive text-to-speech using data augmentation,
G. Huybrechts, T. Merritt, G. Comini, B. Perz, R. Shah, and J. Lorenzo-Trueba, “Low-resource expressive text-to-speech using data augmentation,”ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6593–6597,
2021
-
[9]
Available: https://api.semanticscholar.org/CorpusID: 226299747
[Online]. Available: https://api.semanticscholar.org/CorpusID: 226299747
-
[10]
Effect of data reduction on sequence- to-sequence neural tts,
J. Latorre, J. Lachowicz, J. Lorenzo-Trueba, T. Merritt, T. Drugman, S. Ronanki, and V . Klimkov, “Effect of data reduction on sequence- to-sequence neural tts,” inICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 7075–7079
2019
-
[11]
End-to- end text-to-speech for low-resource languages by cross-lingual transfer learning,
T. Tu, Y .-J. Chen, C. chieh Yeh, and H. yi Lee, “End-to- end text-to-speech for low-resource languages by cross-lingual transfer learning,” inInterspeech, 2019. [Online]. Available: https: //api.semanticscholar.org/CorpusID:119303569
2019
-
[12]
Survey of deep representation learning for speech emotion recognition,
S. Latif, R. Rana, S. Khalifa, R. Jurdak, J. Qadir, and B. Schuller, “Survey of deep representation learning for speech emotion recognition,” IEEE Transactions on Affective Computing, vol. 14, no. 2, pp. 1634– 1654, 2021
2021
-
[13]
Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,
B. W. Schuller, “Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,”Communications of the ACM, vol. 61, no. 5, pp. 90–99, 2018
2018
-
[14]
Asrlux: Automatic speech recognition for the low-resource language luxembourgish,
P. Gilles, L. E. A. Hillah, and N. Hosseini-Kivanani, “Asrlux: Automatic speech recognition for the low-resource language luxembourgish,” in
-
[15]
Guarant International, 2023
International Conference of Phonetic Sciences (ICPhS). Guarant International, 2023
2023
-
[16]
Improving luxembourgish speech recogni- tion with cross-lingual speech representations,
S. Nayak, M. Coleret al., “Improving luxembourgish speech recogni- tion with cross-lingual speech representations,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 792–797
2023
-
[17]
Letz translate: Low-resource machine translation for luxembourgish,
Y . Song, S. Ezzini, J. Klein, T. Bissyande, C. Lefebvre, and A. Goujon, “Letz translate: Low-resource machine translation for luxembourgish,” in2023 5th International Conference on Natural Language Processing (ICNLP). IEEE, 2023, pp. 165–170
2023
-
[18]
Strategy for the promotion of the luxembourgish language,
Government of the Grand Duchy of Luxembourg, “Strategy for the promotion of the luxembourgish language,” 2018, accessed 2026-03-03. [Online]. Available: https://gouvernement.lu/en/dossiers/2018/langue-l uxembourgeoise.html
2018
-
[19]
Luxembourgish,
P. Gilles and J. Trouvain, “Luxembourgish,”Journal of the International Phonetic Association, vol. 43, no. 1, pp. 67–74, 2013
2013
-
[20]
Language attitudes and code-switching behaviour in a multilingual educational context: the case of luxembourg,
D. Redinger, “Language attitudes and code-switching behaviour in a multilingual educational context: the case of luxembourg,” Ph.D. dissertation, University of York, 2010
2010
-
[21]
Digital youth communication in luxembourg (abstract 20284),
Session abstract (conference program), “Digital youth communication in luxembourg (abstract 20284),” n.d., accessed 2026-03-03. [Online]. Available: https://ss25.m.tas.currinda.com/schedule/session/1087/abstra ct/20284
2026
-
[22]
Lux-asr: Building an asr system for the luxembourgish language,
P. Gilles, N. Hosseini-Kivanani, and L. E. A. Hillah, “Lux-asr: Building an asr system for the luxembourgish language,” in2022 IEEE Spoken Language Technology Workshop (SLT) SLT 2022, 2023
2022
-
[23]
Deepfil- ternet: A low complexity speech enhancement framework for full-band audio based on deep filtering,
H. Schroter, A. N. Escalante-B, T. Rosenkranz, and A. Maier, “Deepfil- ternet: A low complexity speech enhancement framework for full-band audio based on deep filtering,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7407–7411
2022
-
[24]
Nisqa: A deep cnn- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “Nisqa: A deep cnn- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,”Interspeech 2021, 2021
2021
-
[25]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. Reddy, V . Gopal, and R. Cutler, “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6493–6497
2021
-
[26]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandiet al., “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Re- search, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[27]
Joint-sequence models for grapheme-to- phoneme conversion,
M. Bisani and H. Ney, “Joint-sequence models for grapheme-to- phoneme conversion,”Speech Communication, vol. 50, no. 5, pp. 434– 451, 2008
2008
-
[28]
A database of german emotional speech,
F. Burkhardt, A. Paeschke, M. Rolfes, W. F. Sendlmeier, and B. Weiss, “A database of german emotional speech,” inProc. Interspeech 2005, 2005, pp. 1517–1520
2005
-
[29]
Hifi++: A uni- fied framework for bandwidth extension and speech enhancement,
P. Andreev, A. Alanov, O. Ivanov, and D. Vetrov, “Hifi++: A uni- fied framework for bandwidth extension and speech enhancement,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[30]
Deep learning based assessment of synthetic speech naturalness,
G. Mittag and S. M ¨oller, “Deep learning based assessment of synthetic speech naturalness,”Interspeech 2020, 2020
2020
-
[31]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[32]
Speechbrain: A general-purpose speech toolkit,
M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong et al., “Speechbrain: A general-purpose speech toolkit,”arXiv preprint arXiv:2106.04624, 2021
-
[33]
pyin: A fundamental frequency estimator using probabilistic threshold distributions,
M. Mauch and S. Dixon, “pyin: A fundamental frequency estimator using probabilistic threshold distributions,” in2014 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2014, pp. 659–663
2014
-
[34]
Streamlit,
S. Inc., “Streamlit,” https://streamlit.io/, 2026, accessed: 4 March 2026
2026
-
[35]
End-to-end text-to- speech for low-resource languages by cross-lingual transfer learning,
Y .-J. Chen, T. Tu, C.-c. Yeh, and H.-Y . Lee, “End-to-end text-to- speech for low-resource languages by cross-lingual transfer learning,” Interspeech 2019, pp. 2075–2079, 2019
2019
-
[36]
Text-to-speech system for low-resource language using cross-lingual transfer learning and data augmentation,
Z. Byambadorj, R. Nishimura, A. Ayush, K. Ohta, and N. Kitaoka, “Text-to-speech system for low-resource language using cross-lingual transfer learning and data augmentation,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2021, no. 1, p. 42, 2021
2021
-
[37]
Cross-lingual multi-speaker speech synthe- sis with limited bilingual training data,
Z. Cai, Y . Yang, and M. Li, “Cross-lingual multi-speaker speech synthe- sis with limited bilingual training data,”Computer Speech & Language, vol. 77, p. 101427, 2023
2023
-
[38]
Ece-tts: A zero-shot emotion text- to-speech model with simplified and precise control,
S. Liang, R. Zhou, and Q. Yuan, “Ece-tts: A zero-shot emotion text- to-speech model with simplified and precise control,”Applied Sciences, vol. 15, no. 9, p. 5108, 2025
2025
-
[39]
Enhancing emotional text-to-speech controllability with natural language guidance through contrastive learning and diffusion models,
X. Jing, K. Zhou, A. Triantafyllopoulos, and B. W. Schuller, “Enhancing emotional text-to-speech controllability with natural language guidance through contrastive learning and diffusion models,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[40]
R. R. Manku, Y . Tang, X. Shi, M. Li, and A. Smola, “Emergenttts- eval: Evaluating tts models on complex prosodic, expressiveness, and linguistic challenges using model-as-a-judge,”arXiv preprint arXiv:2505.23009, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.