CoCoMUT: A Tool for Code-Context Mining and Automated Dataset Generation
Pith reviewed 2026-07-01 03:51 UTC · model grok-4.3
The pith
CoCoMUT unifies build discovery, call-graph construction and source reconciliation to produce method context records from Java projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
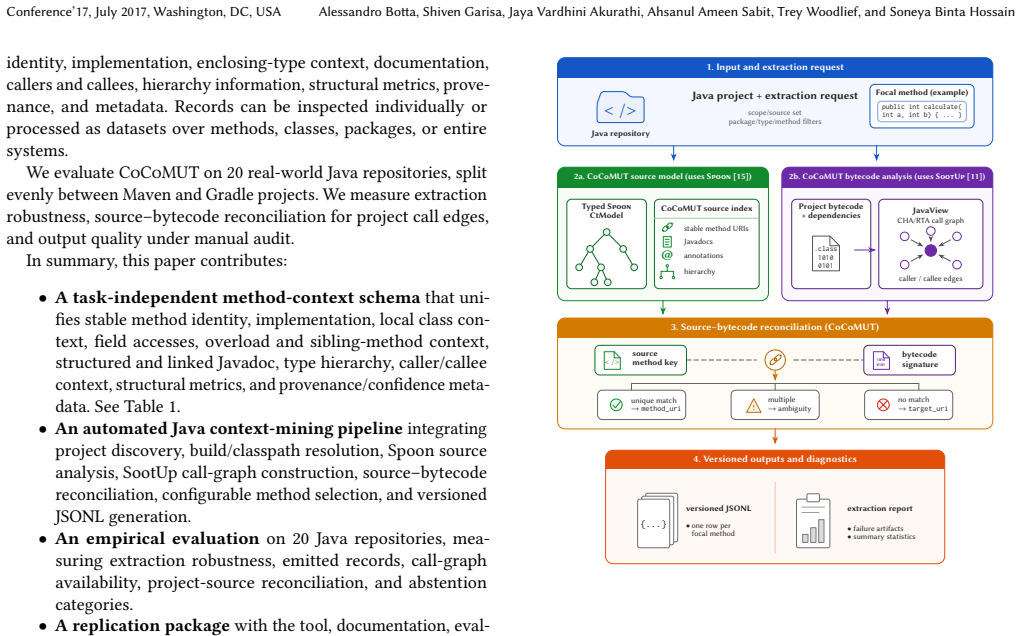
CoCoMUT extracts context for a focal method or generates datasets by discovering project structure, resolving build information, constructing a static call graph with SootUp, reconciling bytecode edges with Spoon source extraction, and emitting versioned JSON. On twenty repositories it produced 56,512 method-context records and 386,048 call edges, with 97.8 percent reconciliation for source targets and 99 percent passing audit.
What carries the argument
The reusable pipeline that combines build discovery, SootUp call-graph construction, Spoon source extraction, and custom source-bytecode reconciliation.
If this is right
- Researchers can generate large context datasets without manual effort.
- Individual method records supply ready context for assistants doing explanation, repair or search.
- The same pipeline can be applied at class, package or system scope.
- Versioned outputs support reproducible experiments.
Where Pith is reading between the lines
- Similar pipelines could be developed for other languages if equivalent static analysis tools exist.
- The high reconciliation rate suggests the approach generalizes beyond the tested Maven and Gradle projects.
- Generated datasets might serve as benchmarks for program comprehension tasks.
Load-bearing premise
The assumption that SootUp call graphs combined with Spoon extraction and reconciliation logic will correctly capture context across arbitrary real-world Java projects without significant unhandled edge cases.
What would settle it
Running the tool on a new collection of Java projects and finding that reconciliation falls below 90 percent or that more than 5 percent of sampled records fail the audit checks.
Figures
read the original abstract
Software-engineering assistants often need method-level context beyond an isolated body, including enclosing-class information, documentation, callers, callees, type hierarchy, and structural characteristics. Manually collecting this context is time-consuming, inconsistent, and difficult to reproduce across large Java projects. We present CoCoMUT, a Java tool for Code-Context Mining and Automated Dataset Generation. CoCoMUT extracts context for a focal method or generates datasets at class, package, or system scope. It discovers project structure, resolves build and classpath information, constructs a SootUp static call graph, and reconciles bytecode-level call edges with Spoon-based source extraction. Each method record combines source, class, documentation, call-graph, and metadata context, providing reproducible inputs for training and running learned software-engineering techniques. The key contribution is a reusable, task-independent pipeline that unifies build discovery, source extraction, call-graph construction, source-bytecode reconciliation, and versioned JSON dataset generation. The resulting records can be consumed individually as context for a focal method or collectively as datasets for documentation, explanation, testing, review, repair, search, and program-comprehension workflows. We evaluate CoCoMUT on 20 real-world Java repositories evenly split between Maven and Gradle. CoCoMUT processed all 20 repositories, emitting 56,512 method-context records and 386,048 serialized call edges. Among call edges whose bytecode targets belonged to project source, CoCoMUT reconciled 97.8% to source method identities. In a manual audit of 200 randomly sampled methods across 10 systems, 99.0% of generated context records passed all applicable correctness checks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoCoMUT, a Java tool that automates extraction of method-level context (enclosing class, documentation, callers/callees via call graph, type hierarchy, structural metadata) from real projects. The pipeline integrates build discovery and classpath resolution, SootUp static call-graph construction, Spoon source extraction, custom source-bytecode reconciliation, and emission of versioned JSON records. It was evaluated on 20 real-world repositories (evenly split Maven/Gradle), successfully processing all of them to produce 56,512 method-context records and 386,048 call edges, with 97.8% reconciliation of project-source bytecode targets and 99% pass rate on a 200-method manual audit across 10 systems.
Significance. If the empirical results hold, the tool supplies a reusable, task-independent pipeline for generating reproducible method-context datasets that can directly support training and evaluation of learned SE techniques for documentation, repair, testing, search, and comprehension. The reported success on 20 diverse, real repositories (with concrete output volumes and two independent correctness metrics) provides direct evidence of practicality for dataset-generation workflows.
major comments (1)
- [Evaluation] Evaluation (the reported results on 20 repositories): the manuscript supplies only aggregate figures (97.8% reconciliation among project-source bytecode targets; 99% audit pass rate) and states that all 20 repositories were processed, but provides no per-repository breakdown, no enumeration of any build-discovery or classpath failures, and no characterization of the 2.2% unreconciled edges. This information is load-bearing for the central claim that the SootUp + Spoon + reconciliation combination correctly captures context across arbitrary real-world Java projects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (the reported results on 20 repositories): the manuscript supplies only aggregate figures (97.8% reconciliation among project-source bytecode targets; 99% audit pass rate) and states that all 20 repositories were processed, but provides no per-repository breakdown, no enumeration of any build-discovery or classpath failures, and no characterization of the 2.2% unreconciled edges. This information is load-bearing for the central claim that the SootUp + Spoon + reconciliation combination correctly captures context across arbitrary real-world Java projects.
Authors: We agree that a per-repository breakdown would provide stronger evidence for the claim of broad applicability. In the revised manuscript we will add a table that reports, for each of the 20 repositories, the build system (Maven or Gradle), number of method-context records emitted, number of call edges, reconciliation rate among project-source bytecode targets, and any build-discovery or classpath-resolution failures encountered. We will also add a short section characterizing the 2.2% unreconciled edges, grouping them by observable cause (e.g., ambiguous overload resolution, missing source for synthetic methods, or classpath mismatches). The 99% audit figure already reflects a random sample drawn across 10 of the 20 systems; we will note that no audited record failed its applicable checks. These additions directly address the load-bearing concern while preserving the paper's focus on the overall pipeline. revision: yes
Circularity Check
No circularity: empirical tool description with direct measurements
full rationale
The paper describes an implemented pipeline (build discovery, SootUp call graphs, Spoon extraction, reconciliation) and reports concrete empirical outcomes: processing 20 repositories, emitting 56,512 records, 97.8% reconciliation rate, and 99% audit pass rate. No equations, fitted models, predictions, or derivations exist that could reduce to author-defined inputs. No self-citation load-bearing steps or uniqueness theorems are invoked. The evaluation is self-contained against external benchmarks (the 20 repositories and manual audit), satisfying the criteria for score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Static analysis frameworks SootUp and Spoon can be used to construct call graphs and extract source information from compiled and source Java artifacts.
- domain assumption Maven and Gradle projects expose sufficient metadata for automatic discovery of structure and classpath without manual configuration.
Reference graph
Works this paper leans on
-
[1]
ASSERT Lab. 2026. CoCoMUT: Context Constructor. https://github.com/assert- lab/CoCoMUT. Research artifact
2026
-
[2]
ASSERT Lab. 2026. CoCoMUT Demonstration Video. https://youtu.be/ RCUzkCQjG30. Video demonstration. CoCoMUT: A Tool for Code-Context Mining and Automated Dataset Generation Conference’17, July 2017, Washington, DC, USA
2026
-
[3]
2026.CoCoMUT: A Tool for Code- Context Mining and Automated Dataset Generation
Alessandro Botta, Shiven Garisa, Jaya Vardhini Akurathi, Ahsanul Ameen Sabit, Trey Woodlief, and Soneya Binta Hossain. 2026.CoCoMUT: A Tool for Code- Context Mining and Automated Dataset Generation. doi:10.5281/zenodo.20962959
-
[4]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jian- wei Yin. 2024. ChatUniTest: A Framework for LLM-Based Test Generation. In Companion Proceedings of the 32nd ACM International Conference on the Founda- tions of Software Engineering. Association for Computing Machinery, 572–576. doi:10.1145/3663529.3663801
-
[5]
2026.Jackson
FasterXML. 2026.Jackson. https://github.com/fasterxml/jackson GitHub reposi- tory
2026
-
[6]
Sakib Haque, Alexander LeClair, Lingfei Wu, and Collin McMillan. 2020. Improved Automatic Summarization of Subroutines via Attention to File Context. InProceed- ings of the 17th International Conference on Mining Software Repositories (MSR ’20). Association for Computing Machinery, 300–310. doi:10.1145/3379597.3387449
-
[7]
Soneya Binta Hossain and Matthew B. Dwyer. 2025. TOGLL: Correct and Strong Test Oracle Generation with LLMs. In47th IEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 1475–1487. doi:10.1109/ICSE55347.2025.00098
-
[8]
Soneya Binta Hossain, Nan Jiang, Qiang Zhou, Xiaopeng Li, Wen-Hao Chiang, Yingjun Lyu, Hoan Nguyen, and Omer Tripp. 2024. A deep dive into large language models for automated bug localization and repair.Proceedings of the ACM on Software Engineering1, FSE (2024), 1471–1493
2024
-
[9]
Soneya Binta Hossain, Raygan Taylor, and Matthew Dwyer. 2025. Doc2oracll: Investigating the impact of documentation on llm-based test oracle generation. Proceedings of the ACM on Software Engineering2, FSE (2025), 1870–1891
2025
-
[10]
JSON Lines Community. [n. d.]. JSON Lines. https://jsonlines.org/. Accessed: 2026-06-26
2026
-
[11]
Kadiray Karakaya, Stefan Schott, Jonas Klauke, Eric Bodden, Markus Schmidt, Linghui Luo, and Dongjie He. 2024. SootUp: A Redesign of the Soot Static Analysis Framework. InTools and Algorithms for the Construction and Analysis of Systems: 30th International Conference, TACAS 2024, Held as Part of the European Joint Conferences on Theory and Practice of Sof...
-
[12]
Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. DLFix: Context-Based Code Transformation Learning for Automated Program Repair. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE ’20). As- sociation for Computing Machinery, 602–614. doi:10.1145/3377811.3380345
-
[13]
Grundy, and Xiaohu Yang
Chao Liu, Cuiyun Gao, Xin Xia, David Lo, John C. Grundy, and Xiaohu Yang
-
[14]
On the Reproducibility and Replicability of Deep Learning in Software Engineering.ACM Transactions on Software Engineering and Methodology31, 1, Article 15 (2022), 46 pages. doi:10.1145/3477535
-
[15]
Oracle. 2021. Documentation Comment Specification for the Standard Doclet. https://docs.oracle.com/en/java/javase/17/docs/specs/javadoc/doc- comment-spec.html. Accessed June 22, 2026
2021
-
[16]
Renaud Pawlak, Martin Monperrus, Nicolas Petitprez, Carlos Noguera, and Lionel Seinturier. 2016. SPOON: A library for implementing analyses and transforma- tions of Java source code.Softw. Pract. Exper.46, 9 (Sept. 2016), 1155–1179. doi:10.1002/spe.2346
-
[17]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2024. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation. IEEE Transactions on Software Engineering50, 1 (2024), 85–105. doi:10.1109/TSE. 2023.3334955
work page doi:10.1109/tse 2024
-
[18]
Hendren, Chrislain Razafimahefa, Raja Vallée-Rai, Patrick Lam, Etienne Gagnon, and Charles Godin
Vijay Sundaresan, Laurie J. Hendren, Chrislain Razafimahefa, Raja Vallée-Rai, Patrick Lam, Etienne Gagnon, and Charles Godin. 2000. Practical Virtual Method Call Resolution for Java. InProceedings of the 15th ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA ’00). Association for Computing Machinery, 264–280
2000
-
[19]
Michele Tufano, Shao Kun Deng, Neel Sundaresan, and Alexey Svyatkovskiy. 2022. Methods2Test: A Dataset of Focal Methods Mapped to Test Cases. InProceedings of the 19th International Conference on Mining Software Repositories (MSR ’22). Association for Computing Machinery, 299–303. doi:10.1145/3524842.3528009
-
[20]
Zejun Wang, Kaibo Liu, Ge Li, and Zhi Jin. 2024. HITS: High-Coverage LLM-Based Unit Test Generation via Method Slicing. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. Association for Computing Machinery, 1258–1268. doi:10.1145/3691620.3695501
-
[21]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 2471–24...
-
[22]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Computing Machinery, 1592–1604. doi:10.1145/3650212.3680384
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.