TallyTrain: Communication-Efficient Federated Distillation
Pith reviewed 2026-07-02 19:42 UTC · model grok-4.3
The pith
TallyTrain transmits only argmax class indices to match or beat soft-label distillation at up to 1000 times less communication in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
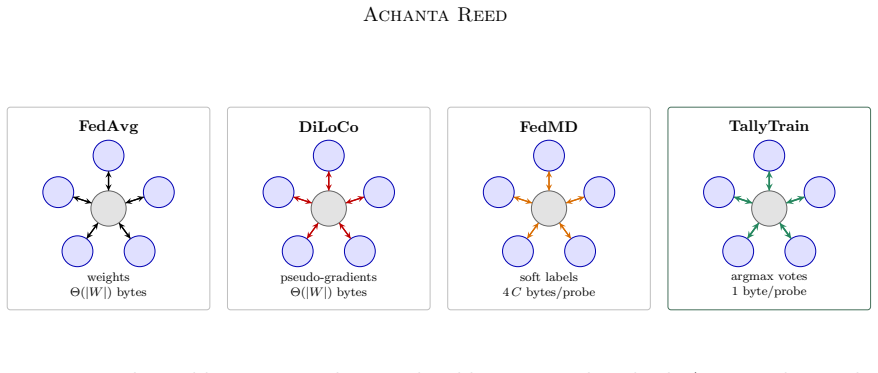
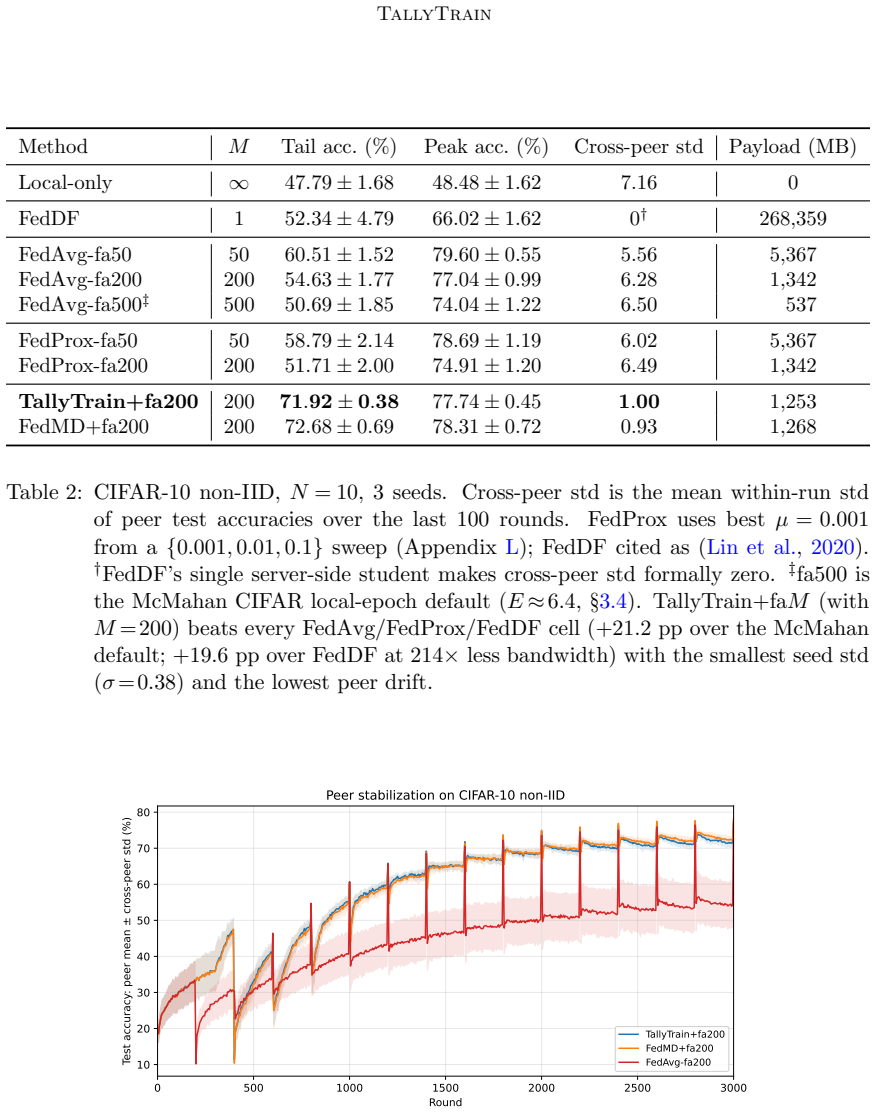
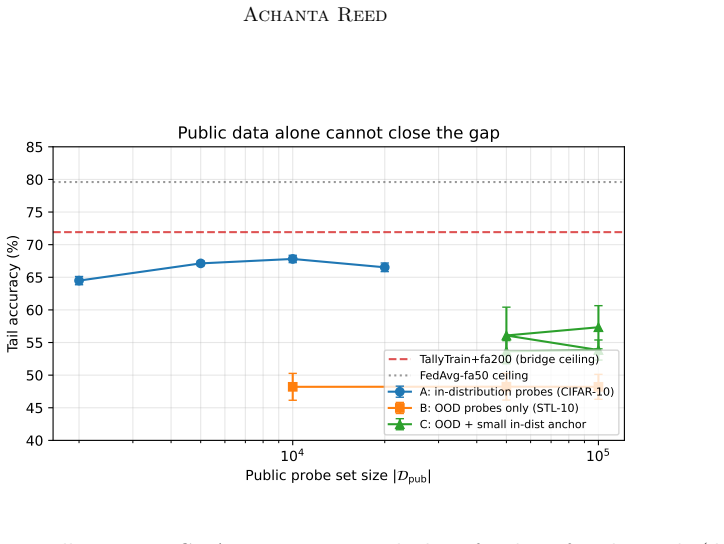
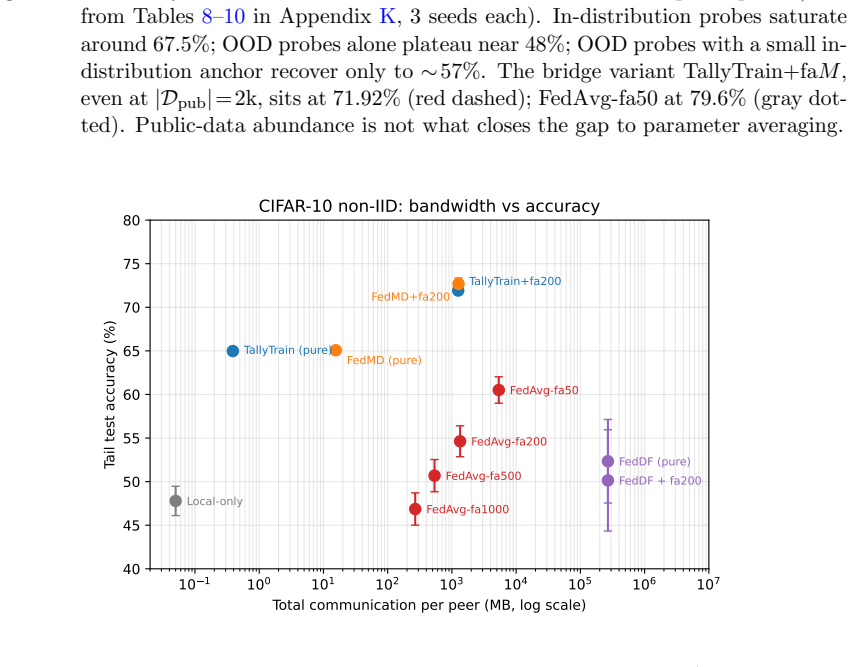
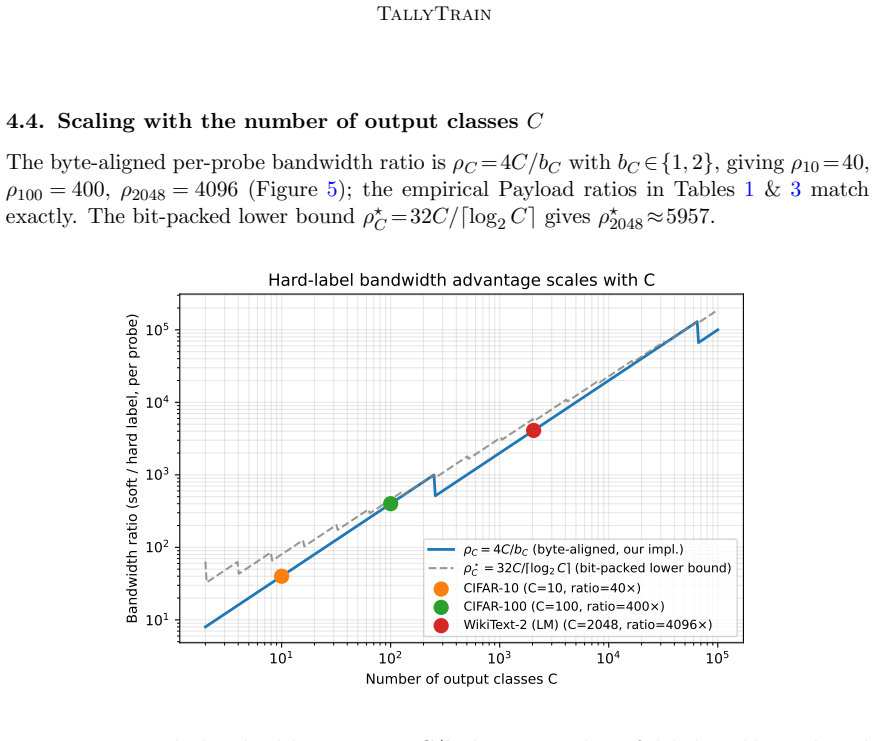
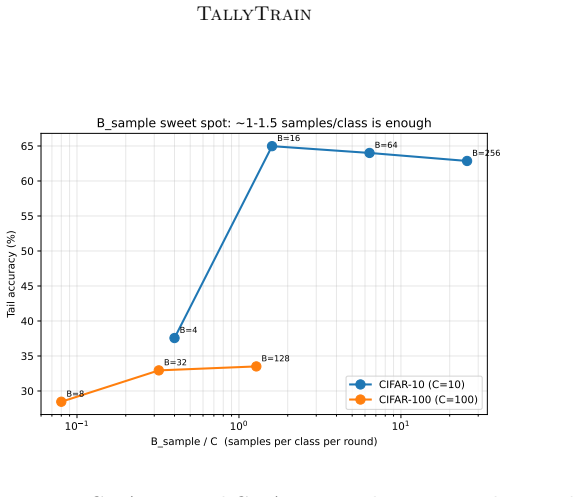
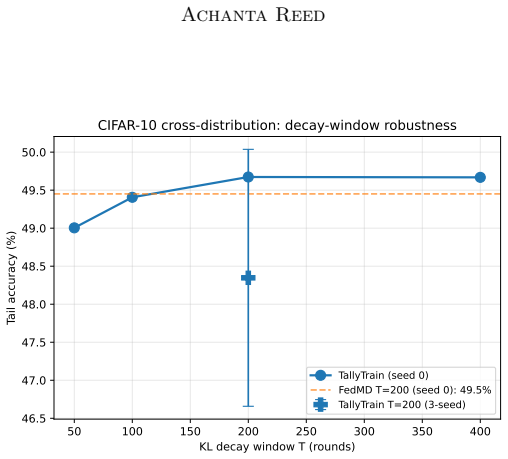
TallyTrain collapses the class-count axis to ceiling of log base 2 of C bits per probe by transmitting only each peer's argmax class index. Under non-IID training it can be preferable to soft-label distillation because under-trained peers are confidently wrong and majority voting filters this noise where soft-label averaging amplifies it. Across standard benchmarks TallyTrain matches or beats soft-label distillation at up to three orders of magnitude less communication. The method also composes with sparse parameter merges to obtain a bandwidth-bridge variant that Pareto-dominates every tested operating point of the standard FedAvg, FedProx and FedDF baselines.
What carries the argument
Majority voting on transmitted argmax class indices, which replaces soft-label probability averaging while cutting per-probe communication to log base 2 of C bits.
If this is right
- Federated systems can handle larger output vocabularies without communication becoming prohibitive.
- Non-IID data distributions become less damaging because voting removes confident errors from weak peers.
- Hybrid hard-label consensus plus sparse merges can improve the accuracy-bandwidth frontier over pure parameter averaging.
- Training rounds can occur more frequently under fixed bandwidth budgets.
Where Pith is reading between the lines
- The same hard-label voting idea could apply to other consensus-based distributed training outside federated settings.
- If class counts continue to grow, the relative savings would increase further, favoring deployment on edge devices with very limited uplink.
- Periodic full-model merges could be scheduled based on observed disagreement rates among the hard labels.
Load-bearing premise
Under non-IID training, under-trained peers are confidently wrong and majority voting filters this noise where soft-label averaging amplifies it.
What would settle it
A non-IID benchmark run where TallyTrain accuracy falls measurably below soft-label distillation accuracy at the same total communication volume.
Figures
read the original abstract
Federated learning is bandwidth-bound on two orthogonal axes: model size, which limits how often parameter-averaging methods can afford to merge, and class count, which makes per-probe soft-label distillation prohibitive at large vocabularies. Both ceilings tighten as modern systems scale. We collapse the class-count axis to $\lceil \log_2 C \rceil$ bits per probe by transmitting only each peer's $\arg\max$ class index, where $C$ is the number of output classes. The resulting protocol, TallyTrain, is not merely compressed: under non-IID training it can be preferable to soft-label distillation, because under-trained peers are confidently wrong and majority voting filters this noise where soft-label averaging amplifies it. Across standard benchmarks, TallyTrain matches or beats soft-label distillation at up to three orders of magnitude less communication. We also relax the model-size axis: we compose the cheap hard-label consensus with sparse parameter merges to obtain a bandwidth-bridge variant, which Pareto-dominates every tested operating point of the standard FedAvg, FedProx and FedDF baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TallyTrain, a federated distillation protocol that transmits only each peer's argmax class index (⌈log₂ C⌉ bits per probe) rather than full soft-label vectors. It claims this yields up to three orders of magnitude lower communication while matching or exceeding soft-label distillation accuracy on standard benchmarks, with the advantage under non-IID partitions arising because majority voting filters confident errors from under-trained peers (where soft-label averaging amplifies them). A bandwidth-bridge variant composes the hard-label consensus with sparse parameter merges and is reported to Pareto-dominate FedAvg, FedProx, and FedDF across tested operating points.
Significance. If the non-IID filtering claim and the reported accuracy-communication trade-offs hold under rigorous validation, the work would offer a practical route to scale federated distillation to large-vocabulary tasks without the class-count communication bottleneck. The explicit contrast between majority voting and soft-label averaging under label skew is a potentially useful insight for the field.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): The load-bearing claim that 'majority voting filters this noise where soft-label averaging amplifies it' under non-IID training is not yet supported by direct evidence. End-task accuracy alone does not establish that the correct class receives the plurality when most peers are individually incorrect; experiments must report per-class vote histograms or the conditional accuracy of the majority vote given peer error rates, especially on label-skew partitions where misclassification patterns may be correlated.
- [§3 and Table 2] §3 (protocol definition) and Table 2: The communication reduction to ⌈log₂ C⌉ bits is correctly derived, but the Pareto-dominance claim for the bandwidth-bridge variant requires explicit reporting of the exact communication budgets (bits per round) and the sparsity schedule used for the parameter-merge component; without these, it is unclear whether the reported dominance holds at the operating points claimed against FedDF.
minor comments (2)
- Notation: the symbol C is introduced for the number of classes but is not consistently subscripted when referring to per-client or global class counts; a single clarifying sentence would remove ambiguity.
- Figure captions: several figures lack explicit axis labels for communication volume (bits or MB) and should state the exact non-IID partition method (e.g., Dirichlet α) used.
Simulated Author's Rebuttal
Thank you for the constructive comments on our submission. We address each major comment below and plan to revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): The load-bearing claim that 'majority voting filters this noise where soft-label averaging amplifies it' under non-IID training is not yet supported by direct evidence. End-task accuracy alone does not establish that the correct class receives the plurality when most peers are individually incorrect; experiments must report per-class vote histograms or the conditional accuracy of the majority vote given peer error rates, especially on label-skew partitions where misclassification patterns may be correlated.
Authors: We agree that providing direct evidence for the proposed filtering mechanism would make the claim more robust. Although the superior performance of TallyTrain over soft-label methods on non-IID partitions supports the intuition, we will add the requested analyses in the revision. Specifically, we will report per-class vote histograms and the conditional accuracy of the majority vote conditioned on peer error rates for the label-skew experiments. revision: yes
-
Referee: [§3 and Table 2] §3 (protocol definition) and Table 2: The communication reduction to ⌈log₂ C⌉ bits is correctly derived, but the Pareto-dominance claim for the bandwidth-bridge variant requires explicit reporting of the exact communication budgets (bits per round) and the sparsity schedule used for the parameter-merge component; without these, it is unclear whether the reported dominance holds at the operating points claimed against FedDF.
Authors: The referee is correct that absolute communication costs and the sparsity schedule are necessary for full reproducibility and verification of Pareto dominance. We will update §3 and Table 2 to explicitly list the bits-per-round for each operating point of the bandwidth-bridge variant and detail the sparsity schedule (e.g., the fraction of parameters merged and the selection criterion) used in the experiments. revision: yes
Circularity Check
No circularity; protocol and claims are independently defined and empirically supported
full rationale
The paper introduces TallyTrain by directly specifying transmission of argmax class indices (reducing to log2(C) bits) and majority voting for consensus, then evaluates it against soft-label baselines on standard benchmarks. No derivation chain reduces a result to its own inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The non-IID filtering claim is presented as an empirical observation rather than a self-referential necessity. The central performance claim rests on external benchmark comparisons, making the work self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Majority voting on argmax labels filters noise from under-trained models better than averaging soft labels under non-IID data distributions
Reference graph
Works this paper leans on
-
[1]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:1910.03581 , year =
FedMD: Heterogeneous Federated Learning via Model Distillation , author =. arXiv preprint arXiv:1910.03581 , year =
-
[3]
Nature Communications , volume =
Communication-efficient Federated Learning via Knowledge Distillation , author =. Nature Communications , volume =
-
[4]
Transactions on Machine Learning Research , year =
DFML: Decentralized Federated Mutual Learning , author =. Transactions on Machine Learning Research , year =
-
[5]
Proceedings of the 41st International Conference on Machine Learning , series =
Overcoming Data and Model heterogeneities in Decentralized Federated Learning via Synthetic Anchors , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[6]
International Conference on Learning Representations , year =
Decentralized Sporadic Federated Learning: A Unified Algorithmic Framework with Convergence Guarantees , author =. International Conference on Learning Representations , year =
-
[7]
Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , series =
DPFL: Decentralized Personalized Federated Learning , author =. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , series =. 2025 , publisher =
2025
-
[8]
Proceedings of the 42nd International Conference on Machine Learning , series =
NTK-DFL: Enhancing Decentralized Federated Learning in Heterogeneous Settings via Neural Tangent Kernel , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , publisher =
2025
-
[9]
Proceedings of the Forty-first Conference on Uncertainty in Artificial Intelligence , series =
FedSPD: A Soft-clustering Approach for Personalized Decentralized Federated Learning , author =. Proceedings of the Forty-first Conference on Uncertainty in Artificial Intelligence , series =. 2025 , publisher =
2025
-
[10]
Advances in Neural Information Processing Systems 38 , year =
Mitigating the Privacy--Utility Trade-off in Decentralized Federated Learning via f -Differential Privacy , author =. Advances in Neural Information Processing Systems 38 , year =
-
[11]
Advances in Neural Information Processing Systems 38 , year =
Competitive Advantage Attacks to Decentralized Federated Learning , author =. Advances in Neural Information Processing Systems 38 , year =
-
[12]
Transactions on Machine Learning Research , year =
Achieving Global Flatness in Decentralized Learning with Heterogeneous Data , author =. Transactions on Machine Learning Research , year =
-
[13]
arXiv preprint arXiv:2603.01730 , year =
Decentralized Federated Learning by Partial Message Exchange , author =. arXiv preprint arXiv:2603.01730 , year =
-
[14]
arXiv preprint arXiv:2602.00791 , year =
Sporadic Gradient Tracking over Directed Graphs: A Theoretical Perspective on Decentralized Federated Learning , author =. arXiv preprint arXiv:2602.00791 , year =
-
[15]
arXiv preprint arXiv:2508.02993 , year =
On the Fast Adaptation of Delayed Clients in Decentralized Federated Learning: A Centroid-Aligned Distillation Approach , author =. arXiv preprint arXiv:2508.02993 , year =
-
[16]
Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , series =
Communication-Efficient Learning of Deep Networks from Decentralized Data , author =. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , series =. 2017 , publisher =
2017
-
[17]
and Chhaparia, Rachita and Donchev, Yani and Kuncoro, Adhiguna and Ranzato, Marc'Aurelio and Szlam, Arthur and Shen, Jiajun , journal =
Douillard, Arthur and Feng, Qixuan and Rusu, Andrei A. and Chhaparia, Rachita and Donchev, Yani and Kuncoro, Adhiguna and Ranzato, Marc'Aurelio and Szlam, Arthur and Shen, Jiajun , journal =
-
[18]
, booktitle =
Stich, Sebastian U. , booktitle =. Local
-
[19]
Tighter Theory for Local
Khaled, Ahmed and Mishchenko, Konstantin and Richt. Tighter Theory for Local. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) , series =. 2020 , publisher =
2020
-
[20]
An Empirical Model of Large-Batch Training
An Empirical Model of Large-Batch Training , author =. arXiv preprint arXiv:1812.06162 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
AAAI 2026 Workshop on Federated Learning and Collaborative AI (FLCA) , year =
Learning in Orbit: A Physics-Aware Graph-Decentralized Federated Learning for Multi-Satellite Space Situational Awareness , author =. AAAI 2026 Workshop on Federated Learning and Collaborative AI (FLCA) , year =
2026
-
[22]
arXiv preprint arXiv:2006.07242 , year=
Ensemble Distillation for Robust Model Fusion in Federated Learning , author=. arXiv preprint arXiv:2006.07242 , year=
-
[23]
Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security , pages=
Privacy-Preserving Deep Learning , author=. Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security , pages=
-
[24]
Advances in Neural Information Processing Systems , pages=
Federated Multi-Task Learning , author=. Advances in Neural Information Processing Systems , pages=
-
[25]
Towards Federated Learning at Scale: System Design
Towards Federated Learning at Scale: System Design , author=. arXiv preprint arXiv:1902.01046 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[26]
arXiv preprint arXiv:1912.04977 , year=
Advances and Open Problems in Federated Learning , author=. arXiv preprint arXiv:1912.04977 , year=
-
[27]
arXiv preprint arXiv:1908.07873 , year=
Federated Learning: Challenges, Methods, and Future Directions , author=. arXiv preprint arXiv:1908.07873 , year=
-
[28]
arXiv preprint arXiv:1812.06127 , year=
Federated Optimization in Heterogeneous Networks , author=. arXiv preprint arXiv:1812.06127 , year=
-
[29]
arXiv preprint arXiv:1910.06378 , year=
SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning , author=. arXiv preprint arXiv:1910.06378 , year=
-
[30]
Adaptive Federated Optimization
Adaptive Federated Optimization , author=. arXiv preprint arXiv:2003.00295 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[31]
International Conference on Learning Representations , year=
Federated Learning with Matched Averaging , author=. International Conference on Learning Representations , year=
-
[32]
Advances in Neural Information Processing Systems , year=
Model Fusion via Optimal Transport , author=. Advances in Neural Information Processing Systems , year=
-
[33]
Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Model Compression , author=. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[34]
Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Learning from Multiple Teacher Networks , author=. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[35]
arXiv preprint arXiv:1805.04770 , year=
Born Again Neural Networks , author=. arXiv preprint arXiv:1805.04770 , year=
-
[36]
arXiv preprint arXiv:1909.10754 , year=
FEED: Feature-Level Ensemble for Knowledge Distillation , author=. arXiv preprint arXiv:1909.10754 , year=
-
[37]
Knowledge Flow: Improve Upon Your Teachers
Knowledge Flow: Improve Upon Your Teachers , author=. arXiv preprint arXiv:1904.05878 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[38]
Zero-Shot Knowledge Distillation in Deep Networks
Zero-Shot Knowledge Distillation in Deep Networks , author=. arXiv preprint arXiv:1905.08114 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[39]
Advances in Neural Information Processing Systems , pages=
Zero-Shot Knowledge Transfer via Adversarial Belief Matching , author=. Advances in Neural Information Processing Systems , pages=
-
[40]
arXiv preprint arXiv:1811.11479 , year=
Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data , author=. arXiv preprint arXiv:1811.11479 , year=
-
[41]
arXiv preprint arXiv:1912.11279 , year=
Cronus: Robust and Heterogeneous Collaborative Learning with Black-Box Knowledge Transfer , author=. arXiv preprint arXiv:1912.11279 , year=
-
[42]
One-Shot Federated Learning , author=. arXiv preprint arXiv:1902.11175 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[43]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, Priya and Doll. Accurate, Large Minibatch. arXiv preprint arXiv:1706.02677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Pointer Sentinel Mixture Models
Pointer Sentinel Mixture Models , author =. arXiv preprint arXiv:1609.07843 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
2017 IEEE Symposium on Security and Privacy (SP) , pages =
Membership Inference Attacks Against Machine Learning Models , author =. 2017 IEEE Symposium on Security and Privacy (SP) , pages =. 2017 , publisher =
2017
-
[46]
Proceedings of the 35th International Conference on Machine Learning (ICML) , series =
Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , series =. 2018 , publisher =
2018
-
[47]
Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS) , pages =
Practical Secure Aggregation for Privacy-Preserving Machine Learning , author =. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS) , pages =. 2017 , publisher =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.