Enhancing Flow Matching with A Unified Guidance Framework for Efficient and Robust Speech Synthesis
Pith reviewed 2026-07-02 06:34 UTC · model grok-4.3
The pith
A unified guidance framework accelerates flow matching speech synthesis nearly threefold while improving speaker similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
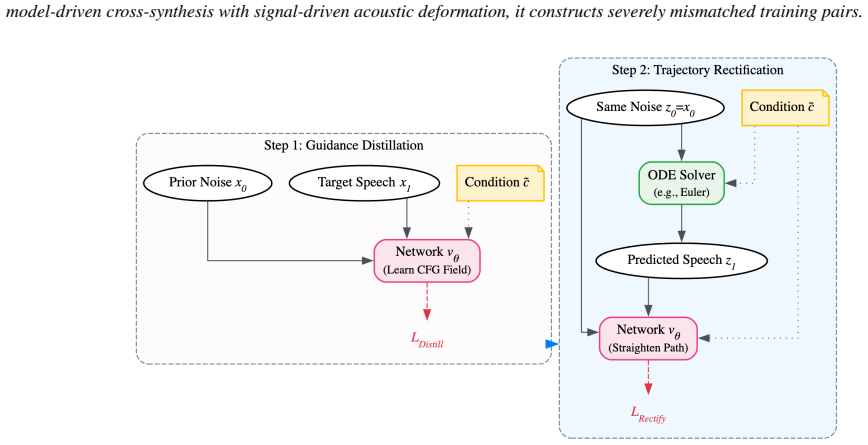
The central claim is that a unified guidance framework—combining data-guidance via heterogeneous augmentation with enhanced model-guidance that includes trajectory rectification and an intrinsic guidance objective—distills conditional knowledge into the model weights, straightens inference trajectories, eliminates classifier-free guidance overhead, and thereby delivers nearly three times faster inference with improved speaker similarity in flow matching speech synthesis.
What carries the argument
Unified guidance framework that integrates data-guidance (heterogeneous augmentation for disentangling linguistic content from acoustic residue) and model-guidance (trajectory rectification plus intrinsic guidance objective to distill knowledge and remove CFG overhead).
If this is right
- Inference runs nearly three times faster than state-of-the-art baselines.
- Speaker similarity improves without additional guidance steps at test time.
- Classifier-free guidance overhead is eliminated by embedding conditional knowledge in the weights.
- The model is encouraged to separate linguistic content from acoustic residue through heterogeneous augmentation.
Where Pith is reading between the lines
- The same guidance pattern could shorten inference in other flow-matching domains such as music or environmental sound generation.
- Removing CFG at inference time may allow higher-quality real-time voice conversion on edge devices.
- Trajectory rectification might reduce accumulation of acoustic artifacts in longer utterances.
Load-bearing premise
Heterogeneous augmentation will cause the model to disentangle linguistic content from acoustic residue, and the enhanced model-guidance will distill conditional knowledge into network weights so that classifier-free guidance is no longer needed.
What would settle it
An experiment on standard speech synthesis benchmarks in which the framework produces no measurable inference speedup or no gain in speaker similarity metrics would falsify the central claim.
Figures

read the original abstract
Flow Matching (FM) has emerged as a powerful paradigm for speech generation but remains constrained by high inference latency and timbre leakage. To address these bottlenecks, we propose a unified guidance framework that enhances generation efficiency and robustness through two complementary strategies. On the data front, we introduce Data-guidance via heterogeneous augmentation, encouraging the model to disentangle linguistic content from acoustic residue. In parallel, we propose an enhanced Model-guidance mechanism that synergizes trajectory rectification with a novel intrinsic guidance objective. This approach distills conditional knowledge into network weights and straightens inference trajectory path, thereby eliminating Classifier-Free Guidance (CFG) overhead. Experiments demonstrate that our framework accelerates inference by nearly three times while effectively improving speaker similarity compared to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified guidance framework for Flow Matching in speech synthesis to address high inference latency and timbre leakage. It introduces Data-guidance via heterogeneous augmentation to disentangle linguistic content from acoustic residue, and enhanced Model-guidance combining trajectory rectification with a novel intrinsic guidance objective to distill conditional knowledge into network weights and eliminate Classifier-Free Guidance (CFG) overhead. The central experimental claim is that this framework accelerates inference by nearly three times while improving speaker similarity over state-of-the-art baselines.
Significance. If the mechanisms and results hold under rigorous validation, the work could advance efficient speech synthesis by reducing CFG dependence and improving robustness in flow-matching models. The dual data/model guidance approach is conceptually coherent, but its impact hinges on whether the claimed speed-up and similarity gains are reproducible and not artifacts of unstated baseline choices or evaluation protocols.
major comments (2)
- [Abstract] Abstract: The claim that the framework 'accelerates inference by nearly three times while effectively improving speaker similarity' is load-bearing for the paper's contribution, yet the abstract (and by extension the high-level description) supplies no quantitative results, inference-time measurements, baseline configurations, error bars, or statistical tests to support the mapping from heterogeneous augmentation + intrinsic guidance to these outcomes.
- [Abstract / presumed §3-4] The description of Data-guidance and Model-guidance (trajectory rectification + intrinsic guidance objective) asserts that they achieve disentanglement and CFG distillation, but without explicit loss functions, training objectives, or inference equations shown, it is impossible to verify whether the augmentation removes timbre leakage or merely trades one form for another, or whether the rectification truly straightens trajectories without introducing new artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the abstract and clarify the technical formulations. We address each point below and have revised the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the framework 'accelerates inference by nearly three times while effectively improving speaker similarity' is load-bearing for the paper's contribution, yet the abstract (and by extension the high-level description) supplies no quantitative results, inference-time measurements, baseline configurations, error bars, or statistical tests to support the mapping from heterogeneous augmentation + intrinsic guidance to these outcomes.
Authors: We agree that the abstract would benefit from explicit quantitative support for the key claims. In the revised version, we have updated the abstract to include the measured inference speedup (nearly 3x as quantified in Table 2 and Section 5) and speaker similarity gains, with direct references to the baseline configurations, error bars, and statistical tests reported in the experimental section. This makes the mapping from the proposed mechanisms to the outcomes more transparent at the high level while preserving conciseness. revision: yes
-
Referee: [Abstract / presumed §3-4] The description of Data-guidance and Model-guidance (trajectory rectification + intrinsic guidance objective) asserts that they achieve disentanglement and CFG distillation, but without explicit loss functions, training objectives, or inference equations shown, it is impossible to verify whether the augmentation removes timbre leakage or merely trades one form for another, or whether the rectification truly straightens trajectories without introducing new artifacts.
Authors: The explicit loss functions, training objectives, and inference equations are presented in Sections 3.1–3.3 and Section 4 of the manuscript, including the heterogeneous augmentation objective for Data-guidance, the combined trajectory rectification and intrinsic guidance loss for Model-guidance, and the CFG-free sampling procedure. To directly address the verification concern, we have added a new summary paragraph and boxed equations in Section 3 that explicitly link each term to the claimed effects (disentanglement and trajectory straightening), along with cross-references to the ablation studies in Section 5.3 that demonstrate no new artifacts are introduced. These revisions make the formulations immediately verifiable without altering the technical content. revision: partial
Circularity Check
No significant circularity; experimental claims not reducible to self-definition or self-citation
full rationale
The abstract and provided text contain no equations, training objectives, fitted parameters, or self-citations. The framework is described at a high level (data-guidance via heterogeneous augmentation, model-guidance with trajectory rectification and intrinsic guidance objective), but the mapping to outcomes (3x acceleration, improved speaker similarity) is asserted via unspecified experiments rather than any derivation that reduces to its inputs by construction. No load-bearing step matches any of the enumerated circularity patterns. This is the expected honest non-finding for a paper whose central claims rest on empirical results without shown mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enhancing Flow Matching with A Unified Guidance Framework for Efficient and Robust Speech Synthesis
Introduction Flow Matching (FM) [1] has rapidly advanced speech synthe- sis by modeling the continuous transformation from a sim- ple prior to complex data distributions. This paradigm has demonstrated remarkable potential across various speech gen- eration tasks. For instance, text-based approaches such as F5- TTS [2] and Matcha-TTS [3] achieve fully non...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Conditional Flow Matching Our method builds upon Conditional Flow Matching (CFM) [1], which constructs probability paths via linear Optimal Transport
Methodology 2.1. Conditional Flow Matching Our method builds upon Conditional Flow Matching (CFM) [1], which constructs probability paths via linear Optimal Transport. Letx 1 denote the target speech sample andx 0 ∼ N(0, I)be the prior noise. The probability pathx t is defined via linear interpolation: xt = (1−t)x 0 +tx 1, t∈[0,1].(1) The corresponding ta...
-
[3]
Experimental setup 3.1.1
Experiments 3.1. Experimental setup 3.1.1. Datasets We employ a two-stage data construction strategy to balance pre-training scale with optimization quality. First, to establish a robust initialization, the foundation model is pre-trained on 50k hours of English speech from the Emilia dataset [26] under a standard matched-condition setting. Second, to enf...
-
[4]
Conclusion This paper presented a unified guidance framework that ad- dresses the distinct bottlenecks of timbre leakage and high inference latency in Flow Matching-based speech generation. On the data side, our Data-guidance strategy employs dual- stage heterogeneous perturbation to sever acoustic shortcuts during training, promoting robust content-timbr...
-
[5]
We also acknowledge the open-source com- munity for the models and datasets used in this study
Acknowledgments The authors thank the Zuoyebang Speech Team for providing the computing power and related platforms that made this re- search possible. We also acknowledge the open-source com- munity for the models and datasets used in this study
-
[6]
No AI tools were used to generate scientific content, experimental data, or the intellectual ideas presented in this work
Generative AI Use Disclosure The authors used generative AI tools (Gemini 3.0 pro) solely for the purpose of checking LaTeX formatting, correcting syntax errors, and refining the layout of this manuscript. No AI tools were used to generate scientific content, experimental data, or the intellectual ideas presented in this work
-
[7]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=PqvMRD CJT9t
2023
-
[8]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association...
2025
-
[9]
Matcha-TTS: A fast TTS architecture with conditional flow matching,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha-TTS: A fast TTS architecture with conditional flow matching,” inProc. ICASSP, 2024
2024
-
[10]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Maet al., “Cosyvoice: A scalable multi- lingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, X. Shi, K. Anet al., “Cosyvoice 3: Towards in-the- wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Build llm-based zero-shot streaming tts system with cosyvoice,
X. Lyu, Y . Wang, T. Zhao, H. Wang, H. Liu, and Z. Du, “Build llm-based zero-shot streaming tts system with cosyvoice,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–2
2025
-
[14]
Maskgct: Zero-shot text- to-speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text- to-speech with masked generative codec transformer,” inICLR. OpenReview.net, 2025
2025
-
[15]
Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications
H.-H. Guo, Y . Hu, K. Liu, F.-Y . Shen, X. Tang, Y .-C. Wu, F.- L. Xie, K. Xie, and K.-T. Xu, “Fireredtts: A foundation text-to- speech framework for industry-level generative speech applica- tions,”arXiv preprint arXiv:2409.03283, 2024
-
[16]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot,” 2024. [Online]. Available: https://arxiv.org/abs/2412.02612
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
A. Huang, B. Wu, B. Wang, C. Yan, C. Hu, C. Feng, F. Tian, F. Shen, J. Li, M. Chenet al., “Step-audio: Unified understanding and generation in intelligent speech interaction,”arXiv preprint arXiv:2502.11946, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot voice conversion with diffusion transformers,”
-
[20]
Available: https://arxiv.org/abs/2411.09943
[Online]. Available: https://arxiv.org/abs/2411.09943
-
[21]
Stablevc: style controllable zero-shot voice conversion with conditional flow matching,
J. Yao, Y . Yuguang, Y . Pan, Z. Ning, J. Ye, H. Zhou, and L. Xie, “Stablevc: style controllable zero-shot voice conversion with conditional flow matching,” inProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational ...
-
[22]
Available: https://doi.org/10.1609/aaai.v39i24.34 758
[Online]. Available: https://doi.org/10.1609/aaai.v39i24.34 758
-
[23]
Non-parallel V oice Conversion based on Hierarchical Latent Embedding Vector Quantized Variational Autoencoder,
T. V . Ho and M. Akagi, “Non-parallel V oice Conversion based on Hierarchical Latent Embedding Vector Quantized Variational Autoencoder,” inJoint Workshop for the Blizzard Challenge and Voice Conversion Challenge 2020, 2020, pp. 140–144
2020
-
[24]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and qiang liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=XVjTT1 nw5z
2023
-
[26]
Instaflow: One step is enough for high-quality diffusion-based text-to- image generation,
X. Liu, X. Zhang, J. Ma, J. Peng, and qiang liu, “Instaflow: One step is enough for high-quality diffusion-based text-to- image generation,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=1k4yZbbDqX
2024
-
[27]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[28]
Prodiff: Progressive fast diffusion model for high-quality text-to-speech,
R. Huang, Z. Zhao, H. Liu, J. Liu, C. Cui, and Y . Ren, “Prodiff: Progressive fast diffusion model for high-quality text-to-speech,” inProceedings of the 30th ACM International Conference on Multimedia, ser. MM ’22. Association for Computing Machinery, 2022, p. 2595–2605. [Online]. Available: https://doi.org/10.1145/3503161.3547855
-
[29]
Fastdiff: A fast conditional diffusion model for high- quality speech synthesis,
R. Huang, M. W. Lam, J. Wang, D. Su, D. Yu, Y . Ren, and Z. Zhao, “Fastdiff: A fast conditional diffusion model for high- quality speech synthesis,” 2022
2022
-
[30]
Comospeech: One-step speech and singing voice synthesis via consistency model,
Z. Ye, W. Xue, X. Tan, J. Chen, Q. Liu, and Y . Guo, “Comospeech: One-step speech and singing voice synthesis via consistency model,” inProceedings of the 31st ACM International Conference on Multimedia. Association for Computing Machinery, 2023, p. 1831–1839. [Online]. Available: https://doi.org/10.1145/3581783.3612061
-
[31]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. [Online]. Available: https://openreview.net/forum?id=qw8AKxfYbI
2021
-
[32]
Diffusion models without classifier-free guidance,
Z. Tang, D. Chen, J. Bao, and B. Guo, “Diffusion models without classifier-free guidance,” 2025. [Online]. Available: https://openreview.net/forum?id=kkiLdrKk0G
2025
-
[33]
Data augmenting contrastive learning of speech representations in the time domain,
E. Kharitonov, M. Rivi `ere, G. Synnaeve, L. Wolf, P.-E. Mazar ´e, M. Douze, and E. Dupoux, “Data augmenting contrastive learning of speech representations in the time domain,” in2021 IEEE Spo- ken Language Technology Workshop (SLT), 2021, pp. 215–222
2021
-
[34]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 885–890
2024
-
[35]
Dnsmos: A non- intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “Dnsmos: A non- intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,” inICASSP 2021 - 2021 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6493–6497
2021
-
[36]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 4195–4205
2023
-
[37]
Understanding and improving layer normalization,
J. Xu, X. Sun, Z. Zhang, G. Zhao, and J. Lin, “Understanding and improving layer normalization,” inAdvances in Neural Informa- tion Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[38]
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking,” inInterspeech 2023, 2023, pp. 5301– 5305
2023
-
[39]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23– ...
2023
-
[40]
Y . A. Li, C. Han, X. Jiang, and N. Mesgarani, “Hiftnet: A fast high-quality neural vocoder with harmonic-plus-noise filter and inverse short time fourier transform,” 2023. [Online]. Available: https://arxiv.org/abs/2309.09493
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.