Minos: A Multi-Agent Collaborative Framework for Provenance-Based Backward Tracking
Pith reviewed 2026-07-02 11:37 UTC · model grok-4.3
The pith
A multi-agent LLM framework reconstructs cyber attack paths from provenance graphs by replacing exhaustive traversal with hypothesis-guided reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Minos formulates provenance-based backward tracking as an LLM-driven reasoning process. For event-level analysis it combines hierarchical context management, retrieval-augmented reasoning with citation verification, and adversarial deliberation. For graph exploration it coordinates four specialized agents under a finite state machine, replacing exhaustive traversal with hypothesis-guided reasoning and count-first query protocols. On 14 attack scenarios across five public datasets this produces average recall of 0.92 and precision of 0.64 while generating attack subgraphs 49 percent more compact than state-of-the-art baselines.
What carries the argument
Two-tiered multi-agent architecture: event-level agents with hierarchical context and retrieval-augmented verification, plus FSM-coordinated graph agents that perform hypothesis-guided pruning.
If this is right
- Attack subgraphs become 49 percent more compact while maintaining higher recall than statistical baselines.
- Reasoning traces are produced at each step, supporting forensic auditing.
- Dependency explosion is reduced by replacing exhaustive traversal with count-first and hypothesis-guided protocols.
- Precision and recall both improve on average across the tested datasets and scenarios.
- The method works on existing public provenance datasets without requiring new instrumentation.
Where Pith is reading between the lines
- The same agent structure could be adapted to forward tracking or to live streaming provenance if the FSM is extended with real-time state transitions.
- Interpretability of the reasoning traces may allow human analysts to inject domain rules that further constrain the search space.
- If the citation-verification step generalizes, similar retrieval-augmented agents could reduce hallucinations in other graph-reasoning security tasks.
- The reported compactness gain suggests downstream storage and visualization tools could handle larger provenance graphs without proportional growth in analysis effort.
Load-bearing premise
LLM reasoning steps with context management and adversarial checks can consistently identify high-level adversarial intent without hallucinations that distort the reconstructed attack path.
What would settle it
A controlled test on a known APT scenario where the generated reasoning trace cites a fabricated dependency that leads the agents to an incorrect attack subgraph.
Figures
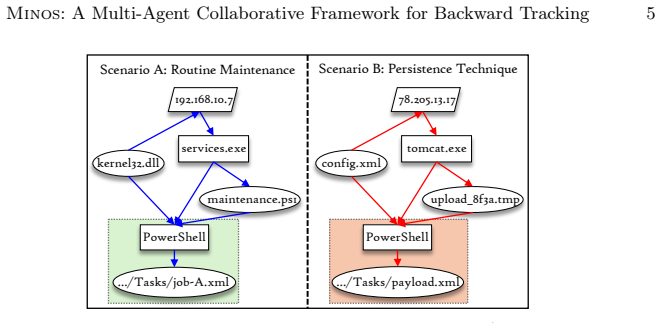
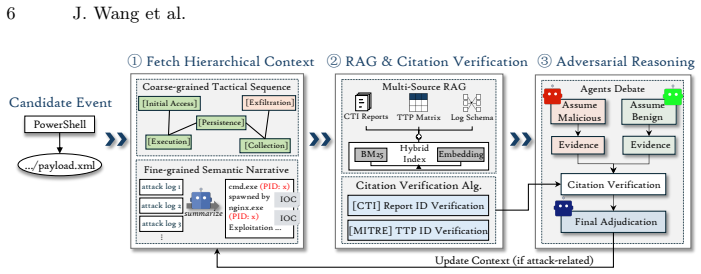
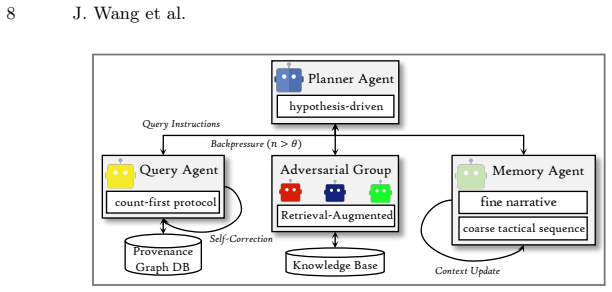
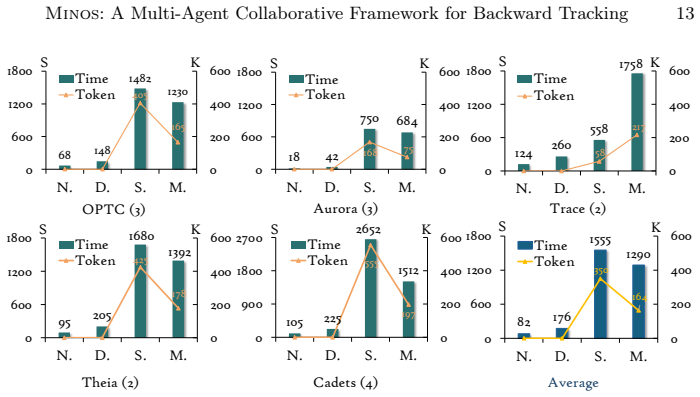


read the original abstract
Sophisticated cyber attacks, particularly Advanced Persistent Threats (APTs), require effective post-intrusion forensic analysis. Provenance-based backward tracking reconstructs attack scenarios by tracing causality from security alerts, but existing methods rely on low-level statistical features and rigid traversal strategies, limiting their ability to capture high-level adversarial intent and suffering from dependency explosion. We present Minos, a multi-agent framework that formulates backward tracking as an LLM-driven reasoning process. Minos adopts a two-tiered architecture: for event-level analysis, it combines hierarchical context management, retrieval-augmented reasoning with citation verification, and adversarial deliberation to improve reasoning quality; for graph exploration, it coordinates four specialized agents under a finite state machine (FSM), replacing exhaustive traversal with hypothesis-guided reasoning and count-first query protocols to efficiently prune the search space. Experiments on 14 attack scenarios across five public datasets show that Minos achieves an average recall of 0.92 and precision of 0.64, significantly outperforming state-of-the-art baselines while producing attack subgraphs that are 49% more compact. Moreover, Minos generates interpretable reasoning throughout the tracking process, facilitating forensic auditing and system refinement. These results demonstrate the effectiveness of LLM-driven reasoning for automated provenance-based backward tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Minos, a multi-agent LLM-driven framework for provenance-based backward tracking of APTs. It uses a two-tiered architecture: event-level analysis via hierarchical context, retrieval-augmented reasoning with citation verification, and adversarial deliberation; graph exploration via four specialized agents coordinated by an FSM that replaces exhaustive traversal with hypothesis-guided reasoning and count-first queries. Experiments on 14 attack scenarios across five public datasets are reported to yield average recall 0.92 and precision 0.64, outperforming SOTA baselines while producing 49% more compact attack subgraphs and generating interpretable reasoning traces.
Significance. If the reported experimental outcomes prove robust under full protocol disclosure, the work would represent a meaningful advance in automated forensic analysis by shifting from low-level statistical traversal to high-level intent-aware reasoning, directly addressing dependency explosion and improving subgraph compactness and auditability in provenance graphs.
major comments (2)
- [Abstract] Abstract: the central performance claims (recall 0.92, precision 0.64, 49% compactness gain, outperformance of SOTA) are stated without any description of experimental protocol, baseline implementations, dataset splits, error bars, statistical tests, or controls, rendering it impossible to evaluate whether the numbers support the claims.
- [Abstract (and presumed §4 Experiments)] The manuscript provides no ablation or sensitivity analysis on the LLM components (hierarchical context, retrieval-augmented citation verification, adversarial deliberation) to demonstrate that reported metrics are not the result of post-hoc tuning or selective prompting, which directly bears on the weakest assumption flagged in the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Where the comments identify gaps in the current manuscript, we commit to revisions that add the requested information and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (recall 0.92, precision 0.64, 49% compactness gain, outperformance of SOTA) are stated without any description of experimental protocol, baseline implementations, dataset splits, error bars, statistical tests, or controls, rendering it impossible to evaluate whether the numbers support the claims.
Authors: We agree that the abstract, constrained by length, omits protocol details. Section 4 of the manuscript describes the 14 scenarios, five public datasets, baseline re-implementations, evaluation metrics, and comparison procedure. To make the abstract self-contained for initial evaluation, we will revise it to include a concise statement of the experimental scope (14 scenarios across five datasets) and direct readers to Section 4 for full protocol, baselines, and metrics. We will also add error bars and any applicable statistical tests to the reported averages in both the abstract and Section 4 if they were not previously computed. revision: yes
-
Referee: [Abstract (and presumed §4 Experiments)] The manuscript provides no ablation or sensitivity analysis on the LLM components (hierarchical context, retrieval-augmented citation verification, adversarial deliberation) to demonstrate that reported metrics are not the result of post-hoc tuning or selective prompting, which directly bears on the weakest assumption flagged in the evaluation.
Authors: The current version does not contain ablation or sensitivity studies isolating the contribution of each LLM component. Section 3 motivates the design of hierarchical context, retrieval-augmented reasoning with citation verification, and adversarial deliberation, and Section 4 reports end-to-end results against baselines. We acknowledge that ablations are necessary to address concerns about post-hoc tuning. We will add these experiments—systematically disabling each component and measuring changes in recall, precision, and compactness—plus sensitivity tests on prompting variations, and include the results in the revised Section 4. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an LLM-based multi-agent framework evaluated via experiments on public datasets, with performance metrics (recall 0.92, precision 0.64) reported directly from those runs. No equations, parameter fits, derivations, or self-citation chains appear in the abstract or described structure that would reduce any claimed result to an input by construction. The work is self-contained as an empirical system description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2021 IEEE Symposium on Security and Privacy (SP)
Barr-Smith, F., Ugarte-Pedrero, X., Graziano, M., Spolaor, R., Martinovic, I.: Survivalism: Systematic analysis of windows malware living-off-the-land. In: 2021 IEEE Symposium on Security and Privacy (SP). pp. 1557–1574. IEEE (2021)
2021
-
[2]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[3]
Qwen3-Coder-Next Technical Report
Cao, R., Chen, M., Chen, J., Cui, Z., Feng, Y., Hui, B., Jing, Y., Li, K., Li, M., Lin, J., Ma, Z., Shum, K., Wang, X., Wei, J., Yang, J., Zhang, J., Zhang, L., Zhang, Z., Zhao, W., Zhou, F.: Qwen3-coder-next technical report. arXiv preprint arXiv:2603.00729 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
arXiv preprint arXiv:2503.03108 (2025)
Cheng, W., Zhu, T., Jing, S., Mei, J.P., Ma, M., Jin, J., Weng, Z.: Omnisec: Llm-driven provenance-based intrusion detection via retrieval-augmented behavior prompting. arXiv preprint arXiv:2503.03108 (2025)
-
[5]
GitHub Repository (2020), https://github.com/FiveDirections/OpTC-data
DARPA: Operationally transparent cyber (optc) dataset. GitHub Repository (2020), https://github.com/FiveDirections/OpTC-data
2020
-
[6]
DARPA Information Innovation Office: Transparent computing (tc) program.https: //www.darpa.mil/program/transparent-computing(2016)
2016
-
[7]
DeepSeek-AI, et al.: Deepseek-v3 technical report (2025),https://arxiv.org/abs/ 2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
In: Forty-first international conference on machine learning (2024)
Du, Y., Li, S., Torralba, A., Tenenbaum, J.B., Mordatch, I.: Improving factuality and reasoning in language models through multiagent debate. In: Forty-first international conference on machine learning (2024)
2024
-
[9]
In: 31st USENIX Security Symposium (USENIX Security 22)
Fang, P., Gao, P., Liu, C., Ayday, E., Jee, K., Wang, T., Ye, Y.F., Liu, Z., Xiao, X.: Back-propagating system dependency impact for attack investigation. In: 31st USENIX Security Symposium (USENIX Security 22). pp. 2461–2478 (2022)
2022
-
[10]
In: 30th USENIX security symposium (USENIX Security 21)
Fei, P., Li, Z., Wang, Z., Yu, X., Li, D., Jee, K.:{SEAL}: Storage-efficient causality analysis on enterprise logs with query-friendly compression. In: 30th USENIX security symposium (USENIX Security 21). pp. 2987–3004 (2021)
2021
-
[11]
arXiv preprint arXiv:2502.02342 (2025)
Gandhi, P.A., Wudali, P.N., Amaru, Y., Elovici, Y., Shabtai, A.: Shield: Apt detection and intelligent explanation using llm. arXiv preprint arXiv:2502.02342 (2025)
-
[12]
doi: 10.1038/s41586-025-09422-z
Guo, D., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforce- ment learning. Nature645(8081), 633–638 (Sep 2025).https://doi.org/10.1038/ s41586-025-09422-z,http://dx.doi.org/10.1038/s41586-025-09422-z
-
[13]
In: Proceedings of the Network and Distributed System Security Symposium (NDSS)
Hassan, W.U., Guo, S., Li, D., Chen, Z., Jee, K., Li, Z., Bates, A.: Nodoze: Combatting threat alert fatigue with automated provenance triage. In: Proceedings of the Network and Distributed System Security Symposium (NDSS). The Internet Society (2019)
2019
-
[14]
In: 26th USENIX Security Symposium (USENIX Security 17)
Hossain,M.N.,Milajerdi,S.M.,Wang,J.,Eshete,B.,Gjomemo,R.,Sekar,R.,Stoller, S., Venkatakrishnan, V.:{SLEUTH}: Real-time attack scenario reconstruction from {COTS} audit data. In: 26th USENIX Security Symposium (USENIX Security 17). pp. 487–504 (2017)
2017
-
[15]
ACM Transactions on Information Systems43(2), 1–55 (2025)
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language models: Princi- ples, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025)
2025
-
[16]
ACM SIGOPS Operating Systems Review37(5), 223–236 (2003) 18 J
King, S.T., Chen, P.M.: Backtracking intrusions. ACM SIGOPS Operating Systems Review37(5), 223–236 (2003) 18 J. Wang et al
2003
-
[17]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[18]
Computers & Security106, 102282 (2021)
Li, Z., Chen, Q., Chen, R., Ye, Y., Zhang, S.: Threat detection and investigation with system-level provenance graphs: A survey. Computers & Security106, 102282 (2021)
2021
-
[19]
Transactions of the Association for Computational Linguistics12, 157–173 (2024)
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P.: Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics12, 157–173 (2024)
2024
-
[20]
https://lolbas-project.github.io/(2024)
LOLBAS Project: LOLBAS: Living off the land binaries, scripts and libraries. https://lolbas-project.github.io/(2024)
2024
-
[21]
OpenAI Blog (December 2025),https://openai.com/index/gpt-5-2-codex/
OpenAI: Gpt-5.2-codex: Specialized model for software engineering and agentic cod- ing. OpenAI Blog (December 2025),https://openai.com/index/gpt-5-2-codex/
2025
-
[22]
OpenAI: Gpt-5.2 technical report. Tech. rep., OpenAI (2025),https://openai. com/index/introducing-gpt-5-2/
2025
-
[23]
In: Proceedings of the 36th annual acm symposium on user interface software and technology
Park, J.S., O’Brien, J., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Genera- tive agents: Interactive simulacra of human behavior. In: Proceedings of the 36th annual acm symposium on user interface software and technology. pp. 1–22 (2023)
2023
-
[24]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.5
2026
-
[25]
arXiv preprint arXiv:2408.08902 (2024)
Song, C., Ma, L., Zheng, J., Liao, J., Kuang, H., Yang, L.: Audit-llm: Multi-agent collaboration for log-based insider threat detection. arXiv preprint arXiv:2408.08902 (2024)
-
[26]
https://attack.mitre.org/ (2018)
Strom, B.E., Applebaum, A., Miller, D.P., Nickels, K.C., Pennington, A.G., Thomas, C.B.: MITRE ATT&CK: Design and philosophy. https://attack.mitre.org/ (2018)
2018
-
[27]
Wang, L., Li, Z., Jiang, Y., Wang, Z., Guo, Z., Wang, J., Wei, Y., Shen, X., Ruan, W., Chen, Y.: From sands to mansions: Towards automated cyberattack emulation with classical planning and large language models. arXiv preprint arXiv:2407.16928 (2024)
-
[28]
Transactions on Machine Learning Research (2022),https://openreview
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., et al.: Emergent abilities of large language models. Transactions on Machine Learning Research (2022),https://openreview. net/forum?id=yzkSU5zdwD
2022
-
[29]
Simple synthetic data reduces sycophancy in large language models
Wei, J., Huang, D., Lu, Y., Zhou, D., Le, Q.V.: Simple synthetic data reduces sycophancy in large language models. arXiv preprint arXiv:2308.03958 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: First conference on language modeling (2024)
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al.: Autogen: Enabling next-gen llm applications via multi-agent conversations. In: First conference on language modeling (2024)
2024
-
[31]
In: Proceedings of the 11th International Conference on Learning Representations (ICLR) (2023)
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. In: Proceedings of the 11th International Conference on Learning Representations (ICLR) (2023)
2023
-
[32]
In: NDSS (2021)
Zeng, J., Chua, Z.L., Chen, Y., Ji, K., Liang, Z., Mao, J.: Watson: Abstracting behaviors from audit logs via aggregation of contextual semantics. In: NDSS (2021)
2021
-
[33]
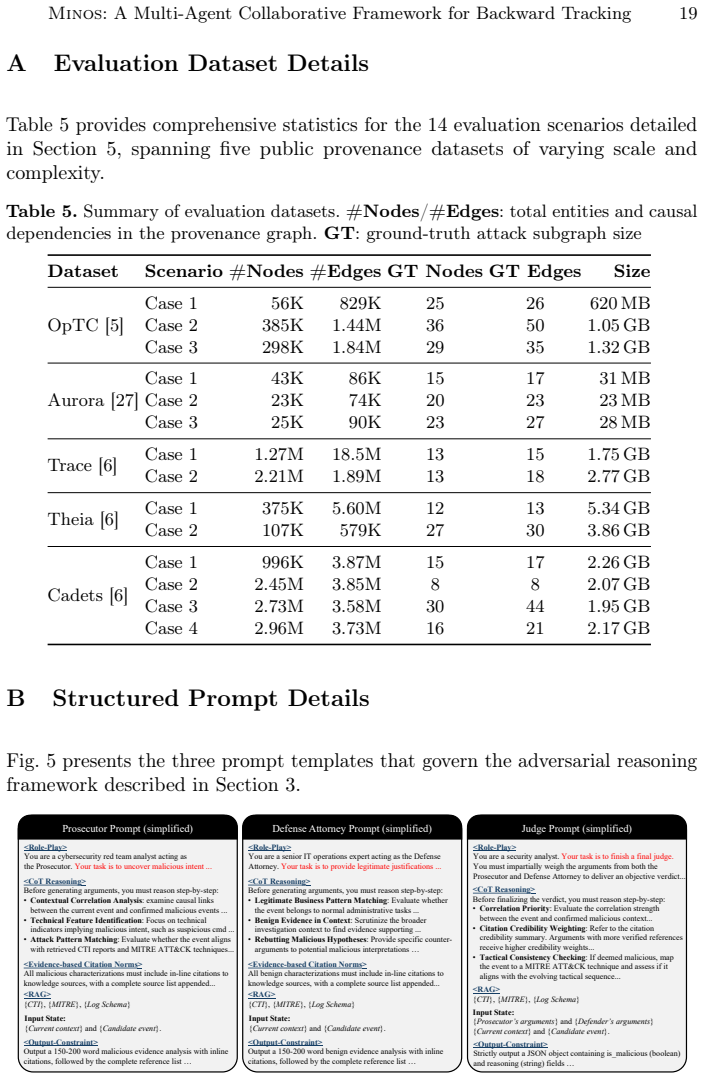
tactic":
Zipperle, M., Gottwalt, F., Chang, E., Dillon, T.: Provenance-based intrusion detection systems: A survey. ACM Computing Surveys55(7), 1–36 (2022) Minos: A Multi-Agent Collaborative Framework for Backward Tracking 19 A Evaluation Dataset Details Table 5 provides comprehensive statistics for the 14 evaluation scenarios detailed in Section 5, spanning five ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.