Caption Bottleneck Models
Pith reviewed 2026-07-02 14:55 UTC · model grok-4.3
The pith
Caption Bottleneck Models train classifiers only on LMM captions to ensure leakage-free interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
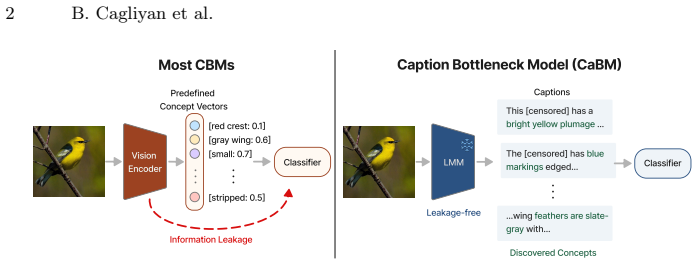
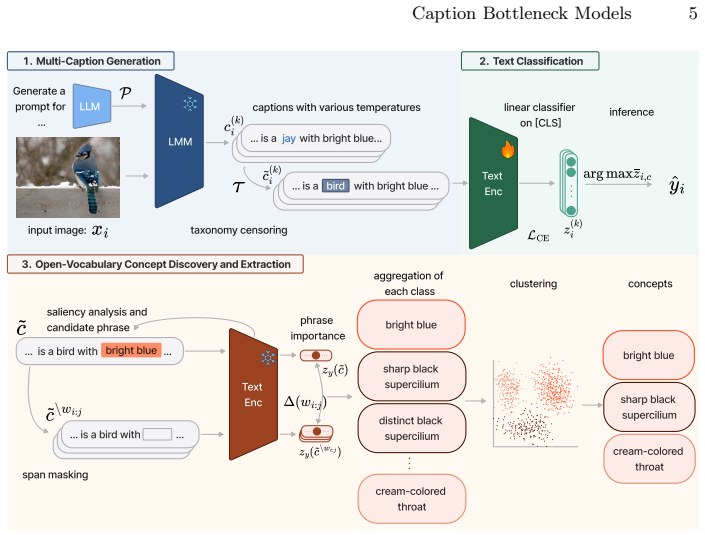
By representing images via LMM-generated captions and training a classifier strictly on this text, CaBM ensures a leakage-free architecture by construction. Additionally, by analyzing the text classifier post-training, CaBM autonomously discovers high-quality, dataset-specific concepts.
What carries the argument
The caption bottleneck, which converts images to LMM-generated natural language descriptions before any classification occurs.
If this is right
- CaBM achieves competitive accuracy on fine-grained and coarse-grained image classification benchmarks.
- The architecture is leakage-free because predictions depend only on the caption text.
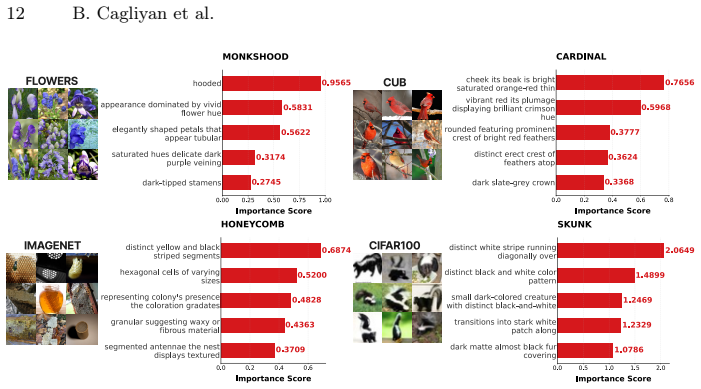
- Dataset-specific concepts are discovered without expert annotations or static dictionaries.
- Interpretability is maintained through the use of human-readable natural language.
Where Pith is reading between the lines
- If LMM captions systematically omit certain visual cues, accuracy on tasks relying on those cues would suffer.
- This method could extend to other vision tasks if suitable text-based models are available.
- The discovered concepts might expose biases present in the underlying LMM caption generator.
Load-bearing premise
LMM-generated captions contain all the visual information necessary for accurate classification without missing details or introducing errors.
What would settle it
An experiment where CaBM accuracy drops significantly below a direct vision model on a dataset known to require visual features not easily captured in text captions.
Figures

read the original abstract
Concept Bottleneck Models (CBMs) provide interpretability by routing predictions through a layer of human-understandable concepts. However, defining an optimal concept set for a specific dataset remains an open challenge. Existing approaches rely on expensive expert annotations or LLM-generated lists based solely on class names. Even "open-vocabulary" variants typically depend on static concept sets, which restrict discovery and introduce label bias. Furthermore, traditional CBMs often suffer from information leakage, where unmodeled visual features bypass the bottleneck and compromise the integrity of the explanations. To overcome these limitations, we propose Caption Bottleneck Models (CaBM), a framework that circumvents the need for predefined concept sets by replacing rigid concept layers with free-form natural language. By representing images via LMM-generated captions and training a classifier strictly on this text, CaBM ensures a leakage-free architecture by construction. Additionally, by analyzing the text classifier post-training, CaBM autonomously discovers high-quality, dataset-specific concepts. Our results across fine- and coarse-grained benchmarks demonstrate that CaBM achieves competitive accuracy while preserving interpretability without the constraints of external dictionaries or manual labeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Caption Bottleneck Models (CaBM) to address limitations in Concept Bottleneck Models (CBMs), including the difficulty of defining optimal concept sets and information leakage. CaBM replaces rigid concept layers with free-form natural language captions generated by Large Multimodal Models (LMMs); a downstream classifier is trained exclusively on this text, which the authors state ensures a leakage-free architecture by construction. The method further claims to enable autonomous discovery of high-quality, dataset-specific concepts via post-training analysis of the text classifier. Results on fine- and coarse-grained benchmarks are stated to show competitive accuracy while preserving interpretability without external dictionaries or manual labeling.
Significance. If the empirical claims hold, the work would be significant for interpretable vision models: the architectural choice directly guarantees leakage prevention (a known weakness of standard CBMs) without circular fitting or additional parameters, and the post-hoc concept discovery reduces dependence on expert annotations or static lists. This construction-based guarantee and the potential for data-driven concept extraction are clear strengths relative to prior CBM variants.
major comments (1)
- [Abstract] Abstract: the central empirical claim that CaBM 'achieves competitive accuracy' on fine- and coarse-grained benchmarks is stated without any quantitative numbers, tables, ablation results, or error analysis. Because accuracy is required to establish that caption completeness does not systematically degrade performance, this omission is load-bearing for the overall contribution.
minor comments (1)
- The description of how the trained text classifier is analyzed to 'autonomously discover' concepts lacks concrete details on the extraction procedure (e.g., attention weights, feature importance, or clustering method).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that CaBM 'achieves competitive accuracy' on fine- and coarse-grained benchmarks is stated without any quantitative numbers, tables, ablation results, or error analysis. Because accuracy is required to establish that caption completeness does not systematically degrade performance, this omission is load-bearing for the overall contribution.
Authors: We agree that the abstract would be strengthened by including specific quantitative results. While the full manuscript contains detailed accuracy tables, ablations, and comparisons in the experiments section, the abstract currently states the claim at a high level. In the revised version we will update the abstract to report the key accuracy numbers (and brief baseline comparisons) from the fine- and coarse-grained benchmarks to directly support the claim that caption completeness does not systematically degrade performance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim is that CaBM ensures leakage-free architecture by construction through an explicit architectural choice: mapping images to LMM captions and training a text-only classifier with no visual feature access. This is a definitional property of the proposed setup rather than a derivation that reduces to fitted parameters, self-citations, or ansatzes. No equations, uniqueness theorems, or load-bearing steps are shown that would make any prediction equivalent to its inputs by construction. The approach is self-contained as a modeling framework without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LMM-generated captions contain all information necessary for the downstream classification task.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (2018)
Ancona, M., Ceolini, E., Öztireli, C., Gross, M.: Towards better understanding of gradient-based attribution methods for deep neural networks. In: International Conference on Learning Representations (2018)
2018
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: European Conference on Computer Vision
Bossard, L., Guillaumin, M., Van Gool, L.: Food-101 – mining discriminative com- ponents with random forests. In: European Conference on Computer Vision. pp. 446–461 (2014)
2014
-
[4]
In: AAAI Conference on Artificial Intelligence
Chauhan, K., Tiwari, R., Freyberg, J., Shenoy, P., Dvijotham, K.: Interactive con- cept bottleneck models. In: AAAI Conference on Artificial Intelligence. pp. 5948– 5955 (2023)
2023
-
[5]
In: IEEE Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009)
2009
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Havasi, M., Parbhoo, S., Doshi-Velez, F.: Addressing leakage in concept bottleneck models.In:AdvancesinNeuralInformationProcessingSystems.vol.35,pp.23386– 23397 (2022)
2022
-
[8]
In: International Conference on Machine Learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International Conference on Machine Learning. pp. 5338–5348 (2020)
2020
-
[9]
University of Toronto (2009)
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. University of Toronto (2009)
2009
-
[10]
Understanding Neural Networks through Representation Erasure
Li, J., Monroe, W., Jurafsky, D.: Understanding neural networks through repre- sentation erasure. arXiv preprint arXiv:1612.08220 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
In: IEEE Conference on Computer Vision and Pattern Recognition
Liu, Y., Zhang, T., Gu, S.: Hybrid concept bottleneck models. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 20179–20189 (2025)
2025
-
[12]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[13]
Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314,
Mahinpei, A., Clark, J., Lage, I., Doshi-Velez, F., Pan, W.: Promises and pitfalls of black-box concept learning models. arXiv preprint arXiv:2106.13314 (2021) 16 B. Cagliyan et al
- [14]
-
[15]
McInnes, L., Healy, J., Astels, S., et al.: hdbscan: Hierarchical density based clus- tering. J. Open Source Softw.2(11), 205 (2017)
2017
-
[16]
In: Indian Conference on Computer Vision, Graphics & Image Processing
Nilsback, M., Zisserman, A.: Automated flower classification over a large number of classes. In: Indian Conference on Computer Vision, Graphics & Image Processing. pp. 722–729 (2008)
2008
-
[17]
In: International Conference on Learning Representations (2023)
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free concept bottleneck models. In: International Conference on Learning Representations (2023)
2023
-
[18]
In: IEEE Conference on Computer Vision and Pattern Recognition
Ozdemir, O., Christensen, A., Alaniz, S., Akata, Z., Akbas, E.: Explaining CLIP zero-shot predictions through concepts. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 31336–31345 (2026)
2026
-
[19]
In: Advances in Neural Information Processing Systems (2025)
Park, S., Mun, J., Oh, D., Lee, N.: An analysis of concept bottleneck models: Measuring, understanding, and mitigating the impact of noisy annotations. In: Advances in Neural Information Processing Systems (2025)
2025
-
[20]
In: International Conference on Machine Learning (2025)
Prasse, K., Knab, P., Marton, S., Bartelt, C., Keuper, M.: Dcbm: Data-efficient vi- sual concept bottleneck models. In: International Conference on Machine Learning (2025)
2025
-
[21]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[22]
In: European Conference on Computer Vision
Rao, S., Mahajan, S., Böhle, M., Schiele, B.: Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery. In: European Conference on Computer Vision. pp. 444–461 (2024)
2024
-
[23]
In: Advances in Neural Information Processing Systems
Srivastava, D., Yan, G., Weng, T.W.: Vlg-cbm: Training concept bottleneck mod- els with vision-language guidance. In: Advances in Neural Information Processing Systems. vol. 37, pp. 79057–79094 (2024)
2024
-
[24]
In: Advances in Neural Information Processing Systems (2025)
Steinmann, D., Stammer, W., Wüst, A., Kersting, K.: Object-centric concept- bottlenecks. In: Advances in Neural Information Processing Systems (2025)
2025
-
[25]
In: European Conference on Computer Vision
Tan, A., Zhou, F., Chen, H.: Explain via any concept: Concept bottleneck model with open vocabulary concepts. In: European Conference on Computer Vision. pp. 123–138 (2024)
2024
-
[26]
In: IEEE Conference on Computer Vision and Pattern Recognition (2026)
Tapli, M., Bouniot, Q., Stammer, W., Akata, Z., Akbas, E.: Rethinking concept bottleneck models: From pitfalls to solutions. In: IEEE Conference on Computer Vision and Pattern Recognition (2026)
2026
-
[27]
California Institute of Technology (2011)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The Caltech-UCSD birds-200-2011 dataset. California Institute of Technology (2011)
2011
-
[28]
In: AAAI Conference on Artificial Intelligence
Yamaguchi, S., Nishida, K.: Explanation bottleneck models. In: AAAI Conference on Artificial Intelligence. pp. 21886–21894 (2025)
2025
-
[29]
In: International Conference on Computer Vision
Yan, A., Wang, Y., Zhong, Y., Dong, C., He, Z., Lu, Y., Wang, W.Y., Shang, J., McAuley, J.: Learning concise and descriptive attributes for visual recognition. In: International Conference on Computer Vision. pp. 3090–3100 (2023)
2023
-
[30]
In: IEEE Conference on Computer Vision and Pattern Recog- nition
Yang, Y., Panagopoulou, A., Zhou, S., Jin, D., Callison-Burch, C., Yatskar, M.: Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In: IEEE Conference on Computer Vision and Pattern Recog- nition. pp. 19187–19197 (2023)
2023
-
[31]
In: IEEE Conference on Computer Vision and Pattern Recognition
Yu, L., Han, H., Tao, Z., Yao, H., Xu, C.: Language guided concept bottleneck models for interpretable continual learning. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 14976–14986 (2025) Caption Bottleneck Models 17
2025
-
[32]
In: In- ternational Conference on Learning Representations (2023)
Yuksekgonul, M., Wang, M., Zou, J.: Post-hoc concept bottleneck models. In: In- ternational Conference on Learning Representations (2023)
2023
-
[33]
In: AAAI Conference on Artificial Intelligence (2026)
Zhao, D., Huang, Q., Yan, D., Sun, Y., Yu, J.: Partially shared concept bottleneck models. In: AAAI Conference on Artificial Intelligence (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.