Low Perplexity is Repetition: A One-Dimensional Self-Conditioning Attractor in Continuous Diffusion LMs
Pith reviewed 2026-07-02 13:15 UTC · model grok-4.3
The pith
Continuous diffusion language models repeat because a single direction in the self-conditioning feedback loop forms a contractive attractor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
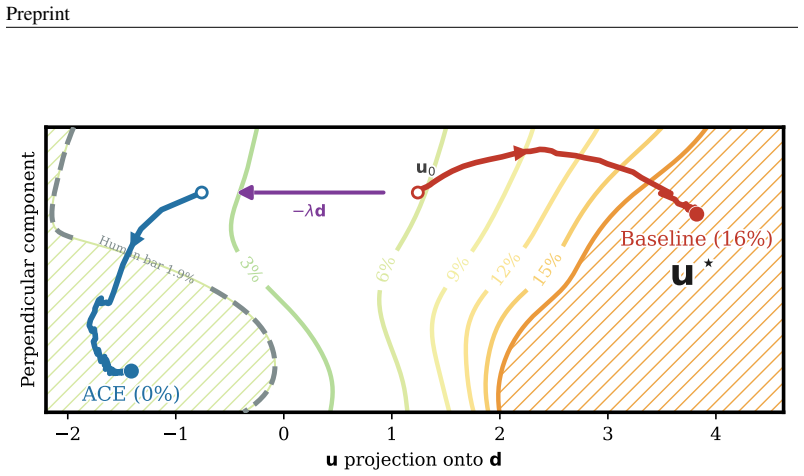
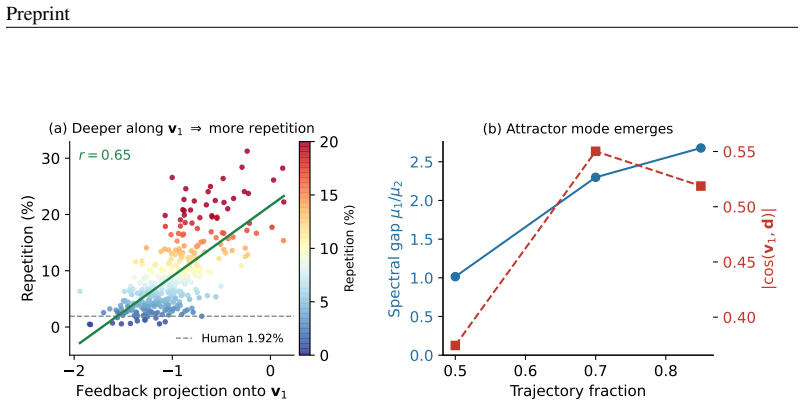
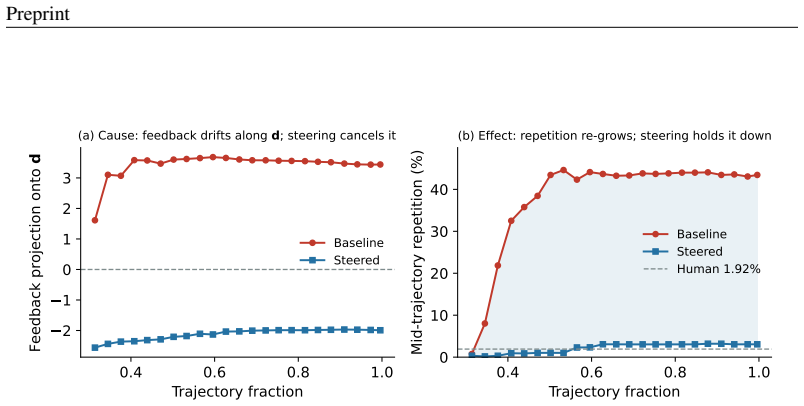
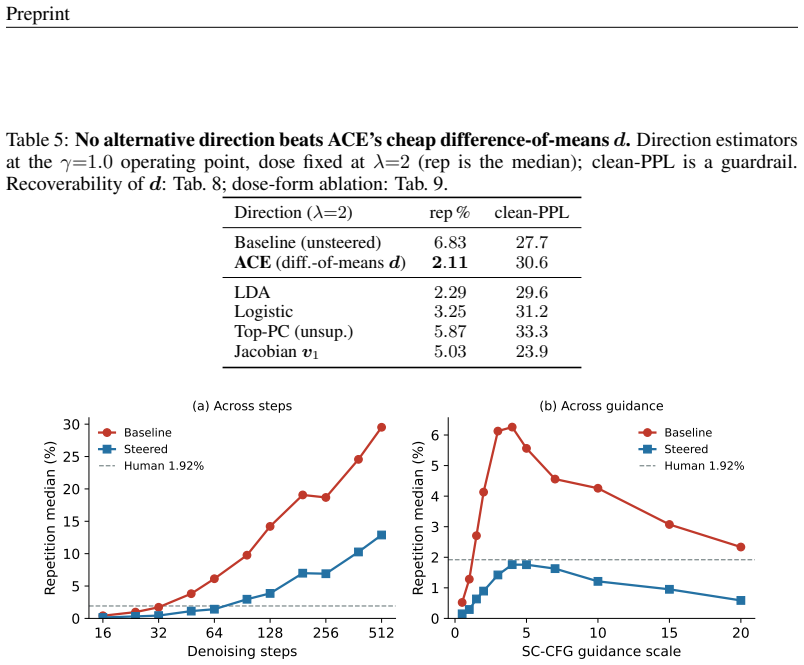
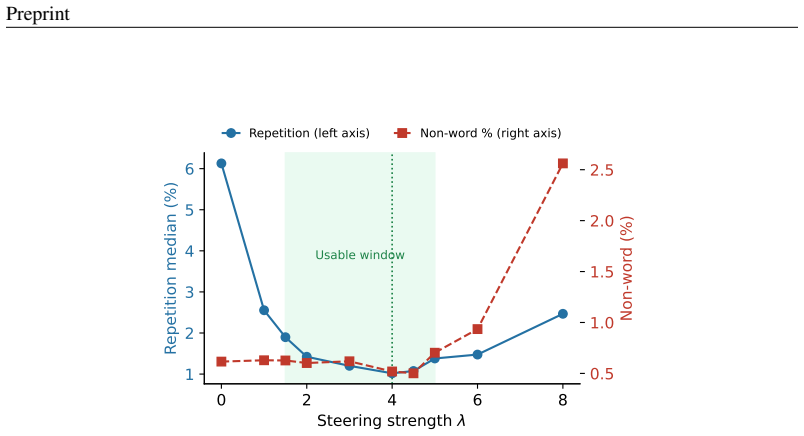
The repetition arises from a contractive attractor along a single direction in the self-conditioning feedback loop. ACE subtracts that single, label-free direction from the feedback at each step. Estimated once on the 105M model, the direction cuts repetition to near the human level while keeping quality competitive, and transfers near-unchanged to the 342M and 652M models and across samplers; the same recipe recovers useful directions on other architectures.
What carries the argument
The contractive attractor along a single direction in the self-conditioning feedback loop, countered by subtracting that direction at each denoising step.
If this is right
- Subtracting the identified direction reduces repetition to near human levels across tested scales.
- The same direction works without retraining when models grow from 105M to 652M parameters.
- The correction remains effective when switching between different sampling procedures.
- The method recovers analogous directions on other model architectures.
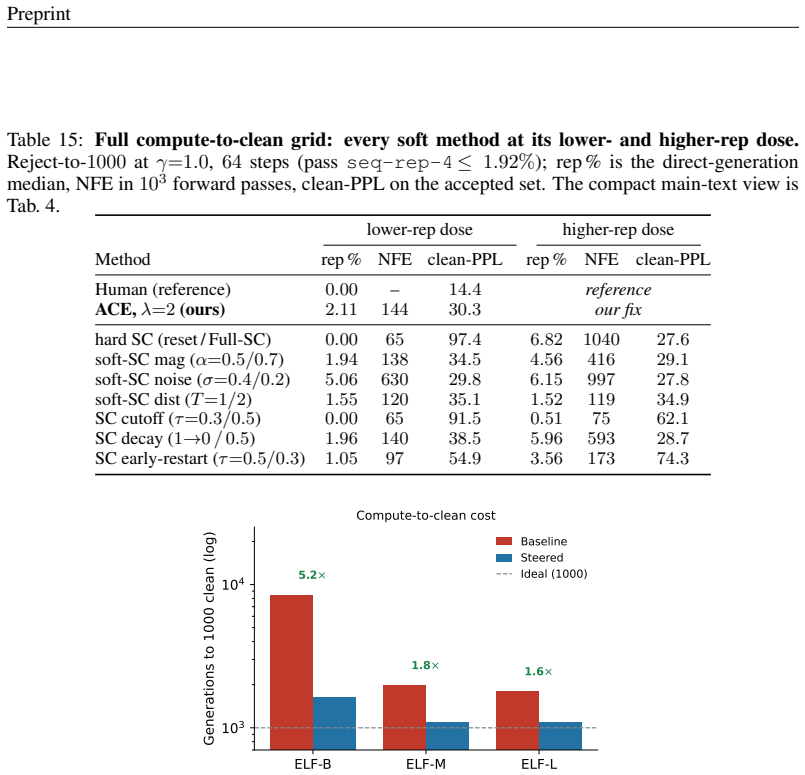
- Compute cost to reach human-clean text drops by a factor of 1.5 to 5 compared with baselines.
Where Pith is reading between the lines
- Standard generative perplexity may systematically favor models that collapse to repetitive modes in diffusion settings.
- One-dimensional attractors could appear in the conditioning loops of other non-autoregressive generators.
- Estimating and removing such directions once on small models offers a cheap way to improve larger ones.
- The stability across scales hints that the attractor arises from a scale-invariant property of the training objective.
Load-bearing premise
The direction estimated once on the 105M model stays stable enough to transfer to larger models and different samplers without degrading other aspects of generation quality.
What would settle it
Measuring repetition rates on the 342M or 652M model after subtracting the 105M-derived direction and finding no reduction or a drop in quality metrics would falsify the transfer result.
Figures
read the original abstract
Continuous diffusion language models such as ELF report record-low generative perplexity (Gen-PPL). We find a catch: these models repeat far more than human text, and Gen-PPL rewards rather than penalizes that repetition, so its low scores overstate quality. Strip the repetition and ELF-B's Gen-PPL rises from $19.5$ to $27.7$; the smallest model even posts the best Gen-PPL because it repeats most. We trace the repetition to its source: a contractive attractor along a \emph{single direction} in the self-conditioning feedback loop, the loop that feeds each step's clean estimate into the next. Because the failure is one-dimensional, a one-dimensional fix suffices, and we propose one. \textbf{ACE} (Attractor-Contrast-Escape) subtracts that single, label-free direction from the feedback at each step. Estimated once on the $105$M model, the direction cuts repetition to near the human level while keeping quality competitive, and transfers near-unchanged to the $342$M and $652$M models and across samplers; the same recipe recovers useful directions on other architectures. Since Gen-PPL itself rewards repetition, we instead measure the compute each fix needs to produce human-clean text, where ACE is $1.5$--$5\times$ cheaper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that record-low generative perplexity (Gen-PPL) in continuous diffusion LMs such as ELF stems from excessive repetition, which Gen-PPL rewards rather than penalizes. It traces this to a contractive attractor along a single direction in the self-conditioning feedback loop and proposes ACE, a one-dimensional correction that subtracts a label-free direction estimated once on the 105M model. This reduces repetition to near-human levels, preserves competitive quality, transfers to 342M/652M models and other samplers, and yields 1.5–5× efficiency gains when measured by compute to reach human-clean text (with Gen-PPL rising from 19.5 to 27.7 after repetition removal).
Significance. If the 1D-attractor claim and transfer results hold, the work supplies a mechanistic account of a concrete failure mode together with a simple, falsifiable fix whose effectiveness is quantified by before/after Gen-PPL numbers and efficiency metrics. The label-free estimation and cross-scale transfer constitute reproducible, parameter-light contributions that could be directly tested on other diffusion LMs.
major comments (2)
- [Transfer results section] Transfer results section: the claim that the direction 'transfers near-unchanged' rests solely on downstream repetition and quality metrics after application to the 342M and 652M models. No direct verification—such as cosine similarity or Euclidean distance between the direction vector estimated on the 105M model and independently estimated vectors on the larger models—is reported. This measurement is load-bearing for the assertion that a single, scale-invariant direction suffices.
- [Gen-PPL analysis] Gen-PPL analysis (abstract and § on evaluation): the statement that 'stripping the repetition' raises Gen-PPL from 19.5 to 27.7 lacks an explicit description of the repetition-identification procedure, the data-exclusion rules, and any statistical significance tests. Without these details the quantitative support for the claim that Gen-PPL rewards repetition remains incomplete.
minor comments (2)
- [Methods] The exact optimization or estimation procedure used to obtain the single attractor direction vector should be stated with pseudocode or an equation in the methods section.
- [Abstract] Notation for model sizes (105M, 342M, 652M) and sampler names should be introduced once and used consistently; the abstract uses 'ELF-B' without prior definition.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each major point below and agree that the requested additions will strengthen the paper.
read point-by-point responses
-
Referee: [Transfer results section] Transfer results section: the claim that the direction 'transfers near-unchanged' rests solely on downstream repetition and quality metrics after application to the 342M and 652M models. No direct verification—such as cosine similarity or Euclidean distance between the direction vector estimated on the 105M model and independently estimated vectors on the larger models—is reported. This measurement is load-bearing for the assertion that a single, scale-invariant direction suffices.
Authors: We agree that direct vector-level verification would strengthen the transfer claim. In the revision we will independently estimate the direction on the 342M and 652M models, compute cosine similarities and Euclidean distances to the 105M direction, and report these quantities in the Transfer results section. revision: yes
-
Referee: [Gen-PPL analysis] Gen-PPL analysis (abstract and § on evaluation): the statement that 'stripping the repetition' raises Gen-PPL from 19.5 to 27.7 lacks an explicit description of the repetition-identification procedure, the data-exclusion rules, and any statistical significance tests. Without these details the quantitative support for the claim that Gen-PPL rewards repetition remains incomplete.
Authors: We agree that the repetition-identification procedure requires fuller documentation. The revised manuscript will add an explicit description of the repetition detection and removal method, the data-exclusion rules, and any statistical significance tests associated with the reported Gen-PPL increase from 19.5 to 27.7. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper empirically identifies a contractive direction via data-driven estimation on the 105M model and validates its transfer through direct application and measurement of repetition/quality metrics on 342M/652M models and across samplers. This constitutes an external, falsifiable test against human text baselines rather than any self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation. No equations or claims in the provided text reduce the central result to its own inputs by construction; the transfer experiments supply independent grounding.
Axiom & Free-Parameter Ledger
free parameters (1)
- attractor direction vector
axioms (1)
- domain assumption The observed repetition originates from a contractive attractor along exactly one direction in the self-conditioning feedback loop
invented entities (1)
-
one-dimensional self-conditioning attractor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Simple Self-Conditioning Adaptation for Masked Diffusion Models
Michael Cardei, Huu Binh Ta, and Ferdinando Fioretto. Simple self-conditioning adaptation for masked diffusion models.arXiv preprint arXiv:2604.26985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202,
-
[3]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu. Langflow: Continuous diffusion rivals discrete in language modeling.arXiv preprint arXiv:2604.11748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffu- sion for categorical data.arXiv preprint arXiv:2211.15089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Hacking Generative Perplexity: Why Unconditional Text Evaluation Needs Distributional Metrics
Antonio Franca and Alexander Tong. Hacking generative perplexity: Why unconditional text eval- uation needs distributional metrics.arXiv preprint arXiv:2606.08417,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, and Kaiming He. Elf: Embedded language flows.arXiv preprint arXiv:2605.10938,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Breaking the Factorization Barrier in Diffusion Language Models
Ian Li, Zilei Shao, Benjie Wang, Rose Yu, Guy Van den Broeck, and Anji Liu. Breaking the factor- ization barrier in diffusion language models.arXiv preprint arXiv:2603.00045,
-
[8]
A diversity-promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and William B Dolan. A diversity-promoting objective function for neural conversation models. InProceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pp. 110–119,
2016
-
[9]
Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization
Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 1797–1807,
2018
-
[10]
Generative Frontiers: Why Evaluation Matters for Diffusion Language Models
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Generative frontiers: Why evaluation matters for diffusion language models.arXiv preprint arXiv:2604.02718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Junzhe Shen, Jieru Zhao, Ziwei He, and Zhouhan Lin. Codar: Continuous diffusion language models are more powerful than you think.arXiv preprint arXiv:2603.02547,
-
[12]
Activation steering for masked diffusion language models.arXiv preprint arXiv:2512.24143,
Adi Shnaidman, Erin Feiglin, Osher Yaari, Efrat Mentel, Amit Levi, and Raz Lapid. Activation steering for masked diffusion language models.arXiv preprint arXiv:2512.24143,
-
[13]
Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236,
Robin Strudel, Corentin Tallec, Florent Altch ´e, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Nikolay Savinov, Sander Dieleman, Laurent Sifre, et al. Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236,
-
[14]
Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892,
Yequan Wang, Jiawen Deng, Aixin Sun, and Xuying Meng. Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892,
-
[15]
Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. InInternational Conference on Learning Representations, volume 2025, pp. 63186– 63227,
2025
-
[16]
Property ofdat the operating point Value Aligned with the feedback’s leading PC,|cos(d,PC 1)|0.73 Energy ofdin PC 1 / top-5PCs0.53/0.82 Estimate stable from few samples,cos(d n,d full)atn=50/200/800 0.69/0.94/1.00 Table 13:Non-words are a second, decode-axis defect, invisible to Gen-PPL.Out-of-dictionary tokens; top block: main-text generations; bottom: c...
1992
-
[17]
23 Preprint Table 17:The defect and the fix in one sample, along the trajectory.Same seed as Figure 3, baseline vs steered (λ=2); highlighted=the cell’s dominant looped4-gram; [
Table 17 shows one draw under baseline and steering at three trajectory stages: the baseline stays locked in the basin at 38–45%repeated4-grams, while the steered run stays near the human bar (1.0–3.1%). 23 Preprint Table 17:The defect and the fix in one sample, along the trajectory.Same seed as Figure 3, baseline vs steered (λ=2); highlighted=the cell’s ...
2025
-
[18]
and gameable end-to-end by naive samplers (Franca & Tong, 2026); this line is mostly on discrete or masked models. The decoderline targets per-position rounding and independence with stronger decoders (Li et al., 2022; Dieleman et al., 2022; Li et al., 2026; Shen et al., 2026): it addresses the discretization bottleneck, not the self-conditioning feedback...
2026
-
[19]
are poorly placed to reach it, whereas the orthogonal non-word defect is amenable to AR-style contextual decoding (App. C). Relation to masked diffusion.Two concurrent threads on masked diffusion bound our claims. Cardei et al. (2026) add self-conditioning to masked diffusion and report a large drop in generative perplexity without an explicit repetition ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.