Linguistic Relative Policy Optimization for Video Anomaly Reasoning
Pith reviewed 2026-07-02 14:27 UTC · model grok-4.3
The pith
Linguistic Relative Policy Optimization lets multimodal models improve video anomaly reasoning by distilling experience from multiple trajectories into context priors without any parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
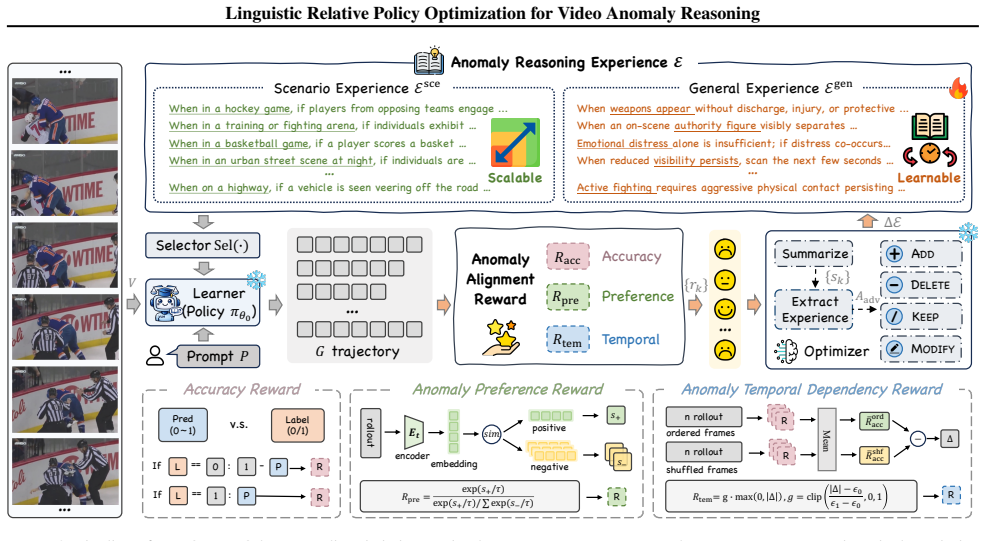
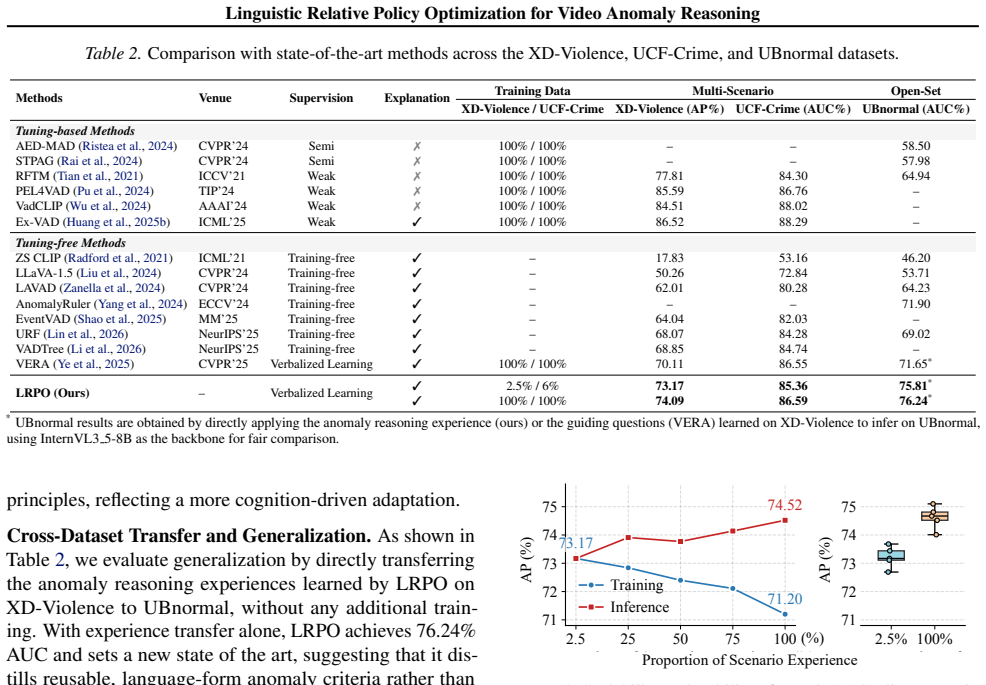
Distilling group-relative semantic advantages from multiple reasoning trajectories into a linguistically expressed anomaly experience prior, with separate general and scenario-specific components, and injecting that prior into the model context steers the MLLM output distribution toward improved anomaly detection and reasoning, yielding higher performance than prior methods on XD-Violence, UCF-Crime, and UBnormal under tuning-free conditions.
What carries the argument
Linguistic Relative Policy Optimization (LRPO), which converts relative advantages among reasoning trajectories into linguistic anomaly experience priors for context injection.
If this is right
- General experience encodes anomaly preferences that transfer across different video scenarios.
- Scenario experience supplies context-specific rules that refine detection for particular settings.
- The anomaly alignment reward directs trajectory optimization to match human risk preferences and favor temporally grounded reasoning.
- The approach produces measurable gains over existing state-of-the-art methods on three benchmark datasets while requiring zero parameter updates.
Where Pith is reading between the lines
- The same trajectory-distillation step could be tested on other sequential multimodal tasks such as action anticipation or event summarization.
- Because no weights change, the method may support rapid adaptation in settings where compute for retraining is unavailable.
- Future checks could measure whether the learned priors remain stable when the underlying MLLM is swapped for a different base model.
Load-bearing premise
Converting relative advantages from groups of reasoning trajectories into linguistic priors and feeding those priors back into context will reliably shift the model's output distribution toward better anomaly detection without any parameter updates.
What would settle it
Applying LRPO to the XD-Violence dataset and observing no gain in standard anomaly detection metrics relative to a plain prompting baseline that lacks the distilled experience prior would falsify the claim.
Figures



read the original abstract
Video anomaly detection (VAD) with multimodal large language models has shown strong potential, yet most existing methods still depend on large-scale annotations or expert-designed priors, limiting their ability to acquire anomaly knowledge with as little human intervention as possible. To address this, we propose Linguistic Relative Policy Optimization (LRPO), which distills group-relative semantic advantages from multiple reasoning trajectories into a linguistically expressed anomaly experience prior, and adapts the model by injecting this prior into the context to steer its output distribution without any parameter updates. LRPO builds two complementary experience representations: general experience captures transferable anomaly preferences across scenarios, while scenario experience models context-dependent anomaly rules for targeted refinement. To further improve the learned experience, we introduce an anomaly alignment reward that guides trajectory optimization to match human risk preferences and reinforce temporally grounded reasoning. Extensive experiments on XD-Violence, UCF-Crime, and UBnormal demonstrate that LRPO significantly outperforms existing state-of-the-art methods under tuning-free settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Linguistic Relative Policy Optimization (LRPO) for video anomaly detection (VAD) using multimodal large language models (MLLMs). LRPO distills group-relative semantic advantages from multiple reasoning trajectories into linguistically expressed anomaly experience priors (general experience for transferable preferences and scenario experience for context-dependent rules), injects these priors into the model context to steer output distributions without parameter updates, and employs an anomaly alignment reward to match human risk preferences and reinforce temporally grounded reasoning. The central claim is that this tuning-free approach yields significant outperformance over existing state-of-the-art methods on the XD-Violence, UCF-Crime, and UBnormal datasets.
Significance. If the empirical claims hold with proper supporting evidence, the work would offer a notable contribution to tuning-free adaptation of MLLMs for VAD by replacing annotation-heavy or expert-prior methods with distilled linguistic priors from trajectory optimization. This could reduce human intervention in acquiring anomaly knowledge, provided the context-injection mechanism demonstrably shifts MLLM distributions in a reliable, human-aligned manner.
major comments (2)
- [Abstract] Abstract: The abstract states that 'extensive experiments on XD-Violence, UCF-Crime, and UBnormal demonstrate that LRPO significantly outperforms existing state-of-the-art methods under tuning-free settings,' yet supplies no quantitative results, baseline details, ablation studies, or error analysis. This absence prevents evaluation of the data-to-claim link for the central contribution.
- [Method] Method (trajectory distillation and reward): The description of how the anomaly alignment reward is computed from trajectories, how group-relative semantic advantages are distilled into linguistic form, and how the resulting priors are enforced to alter MLLM token probabilities at inference time lacks the concrete specification or derivation needed to substantiate that context injection reliably steers outputs toward improved anomaly detection without updates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'extensive experiments on XD-Violence, UCF-Crime, and UBnormal demonstrate that LRPO significantly outperforms existing state-of-the-art methods under tuning-free settings,' yet supplies no quantitative results, baseline details, ablation studies, or error analysis. This absence prevents evaluation of the data-to-claim link for the central contribution.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights to directly link data to the central claim. In the revision we will add concise performance metrics (e.g., AUC gains on each dataset versus the strongest baselines) while preserving length constraints. The full experimental section already contains the requested baseline tables, ablations, and error analysis; we will ensure these are cross-referenced from the abstract. revision: yes
-
Referee: [Method] Method (trajectory distillation and reward): The description of how the anomaly alignment reward is computed from trajectories, how group-relative semantic advantages are distilled into linguistic form, and how the resulting priors are enforced to alter MLLM token probabilities at inference time lacks the concrete specification or derivation needed to substantiate that context injection reliably steers outputs toward improved anomaly detection without updates.
Authors: Section 3.2 derives the group-relative semantic advantage and its distillation into general and scenario-specific linguistic priors; Section 3.3 specifies the anomaly alignment reward as a weighted combination of human risk preference matching and temporal grounding terms. The inference-time context injection is described as a prompt-level prior that conditions the MLLM without parameter updates. To make the mechanism more concrete we will add an algorithmic pseudocode box and a worked numerical example showing token-probability shifts in the revised manuscript. revision: partial
Circularity Check
No circularity; empirical proposal without derivations or self-referential reductions
full rationale
The paper describes LRPO as a context-injection procedure that distills linguistic priors from reasoning trajectories and reports empirical gains on XD-Violence, UCF-Crime, and UBnormal under tuning-free conditions. No equations, parameter-fitting steps, uniqueness theorems, or derivation chains appear in the supplied text. All central claims rest on externally measurable benchmark performance rather than any quantity that reduces to its own inputs by construction. The method is therefore self-contained against independent datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can produce multiple useful reasoning trajectories for video anomaly detection that contain extractable semantic advantages.
Reference graph
Works this paper leans on
-
[1]
Active fighting requires aggressive physical contact persisting ≥3 consecutive frames; weapons do not preclude Fighting if intent to harm is clear, otherwise apply Abuse when coercive handling appears without contact
-
[2]
When weapons appear, also label Shooting if a bright or muzzle flash is followed within 3 frames by injury, distress, or protective reaction, even when the weapon is not yet visible
-
[3]
When someone is lying on the ground, label Abuse if coercive or restraint cues appear within 2-3 frames and no weapon is visible; otherwise defer to Shooting
-
[4]
When law-enforcement appears before civilians, label Riot if within 5 s at least two aggression cues emerge, or if a single cue persists≥2 s after the police appearance
-
[5]
If distress appears with a weapon aimed at a vulnerable person without discharge, label Abuse
Emotional distress alone is insufficient; if distress co-occurs with discharge or protective reaction within 2-3 frames, label Shooting. If distress appears with a weapon aimed at a vulnerable person without discharge, label Abuse
-
[6]
When multiple cues appear, label each only if its rule holds in separate segments; resolve overlaps with priority: Explosion > Shooting>Riot>Fighting>Abuse>Car-accident>Normal
-
[7]
When restrained and another actor forcibly applies an object or substance (e.g., pours, sprays, pushes) onto the person, and visible distress follows within≤3 frames, label Abuse
-
[8]
When reduced visibility persists, scan early, middle, and late checkpoints; if no high-severity or restraint/forced-handling cues appear and the setting looks benign, label Normal
-
[9]
When only aftermath artifacts like lingering smoke or debris appear, no high-severity explosion cue occurred in the prior 5 seconds, and artifacts show no rapid growth, label Normal; otherwise treat as ongoing Explosion
-
[10]
When an on-scene authority figure visibly separates combatants, treat as supporting evidence for genuine Fighting only if aggressive contact cues already exist; ignore in staged scenes without hostile intent
-
[11]
When a crowd shifts from passive to aggressive, label Riot if two of: density rise, chanting, aggression cues (projectiles, tear-gas, protest symbols, fire, smoke, flares) appear within 5 seconds; cue persisting≥1 frame
-
[12]
When a vulnerable individual is restrained by a dominant aggressor and visible distress appears, label Abuse; weapon presence does not downgrade unless a discharge flash or weapon-caused injury occurs within two frames
-
[13]
When a sudden bright flash is large and sustained, and within the next few frames smoke, fire, debris, shockwave, or damage appear, prioritize Explosion over Shooting, even if a weapon is present
-
[14]
When reduced visibility persists, scan the next few seconds for abrupt motion, sudden light or sound cues, emergency vehicles, or rapid crowd shifts; if detected, invoke the matching specific anomaly rule
-
[15]
When weapons appear but no discharge cue in 2-3 frames, run the flash-explosion scan; if Explosion is detected, label Explosion, else do not label Shooting and monitor or consider Abuse
-
[16]
When a sudden bright flash is detected, scan the next five frames for explosion cues (smoke, debris, fire, shockwave, damage); if found, label Explosion, overriding other cues
-
[17]
14 Linguistic Relative Policy Optimization for Video Anomaly Reasoning
When law-enforcement and civilians confront and officers wear riot gear, treat megaphones, banners, chanting, raised fists, coordinated gestures, or density surge as Riot cues persisting≥1 frame. 14 Linguistic Relative Policy Optimization for Video Anomaly Reasoning
-
[18]
When a vulnerable individual shows visible injury and a dominant aggressor is present, require a coercive action (e.g., grip, push) within≤2 frames followed by distress within≤3 frames to label Abuse
-
[19]
When a sudden bright flash occurs without explosion cues, label Shooting only if a weapon-related cue appears or injury/distress directly follows the flash within 2-3 frames; otherwise continue scanning
-
[20]
When a sudden bright flash (e.g., flare or fireworks) occurs with law-enforcement and a hostile crowd, and any aggression cue appears within 3 seconds, label Riot with elevated confidence
-
[21]
When an anomaly cue appears and any label is assigned, always continue scanning remaining frames for independent cues of other categories, applying each rule and resolving overlaps by priority
-
[22]
When a vehicle abruptly changes motion, and within five seconds any of: damage, smoke, fire, debris, emergency-response lights, or clear traffic disruption (stopped vehicles, congestion, lane blockage) appear, label Car-accident, overriding lower-severity cues
-
[23]
When weapons appear, prioritize Shooting over Fighting unless the weapon is sport equipment in a recognized sport context; then evaluate aggressive contact under the Fighting rule if no discharge or injury cues
-
[24]
When weapons appear without discharge, injury, or protective reaction in 3-5 frames, prioritize Abuse labeling if restraint or distress cues exist; only label Shooting with a discharge flash or direct weapon-injury link
-
[25]
When an anomaly cue appears and no high-severity cues are detected across early, middle, and late segments, and behavior is ordinary for the setting, assign the Normal label
-
[26]
When a sudden bright flash is large and smoke plumes, flames, or fireballs persist for three or more frames, especially with shockwave or debris, label Explosion regardless of weapon
-
[27]
v=y7JEq-kf2I
When law-enforcement appears before civilians wearing riot gear, label Riot if two aggression cues span ≥3 seconds, boosting confidence as strong temporal evidence. D.2. Showcase of Selected Scenario Experience We provide an excerpt of the scenario experience entries. Each entry is a natural-language rule that specifies context- dependent anomaly cues, tr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.