MSQA: A Natively Sourced Multilingual and Multicultural SimpleQA Benchmark
Pith reviewed 2026-07-02 13:33 UTC · model grok-4.3
The pith
Multilingual models exhibit an illusion of cultural alignment, with competence tied more to pre-training exposure than to language ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
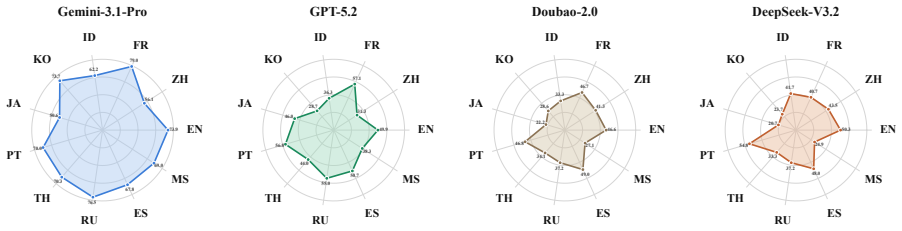
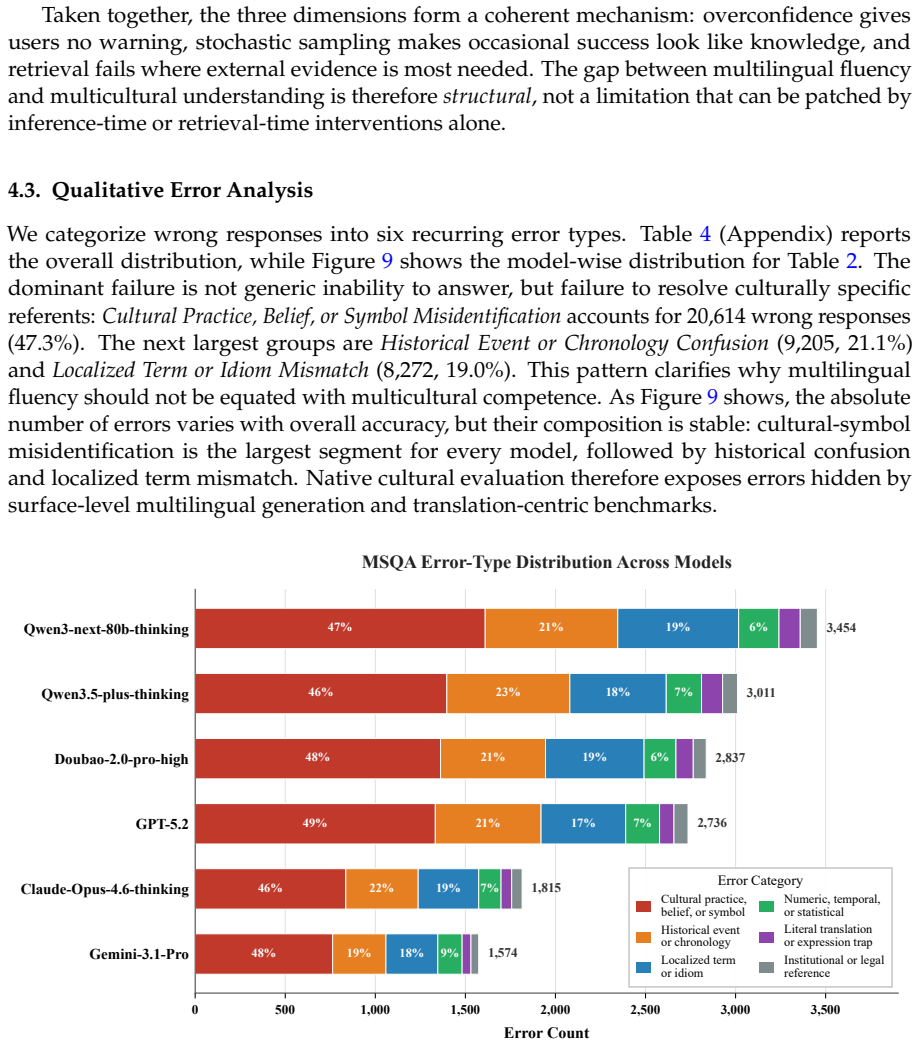
The central claim is that cultural alignment cannot be inferred from multilingual ability alone. The MSQA benchmark of natively sourced questions isolates locally grounded cultural knowledge and reveals a pronounced locality effect: cultural competence tracks pre-training exposure more closely than general reasoning ability. Common inference-time remedies such as calibration, repeated sampling, and retrieval augmentation leave models overconfident and uneven on unfamiliar cultural content.
What carries the argument
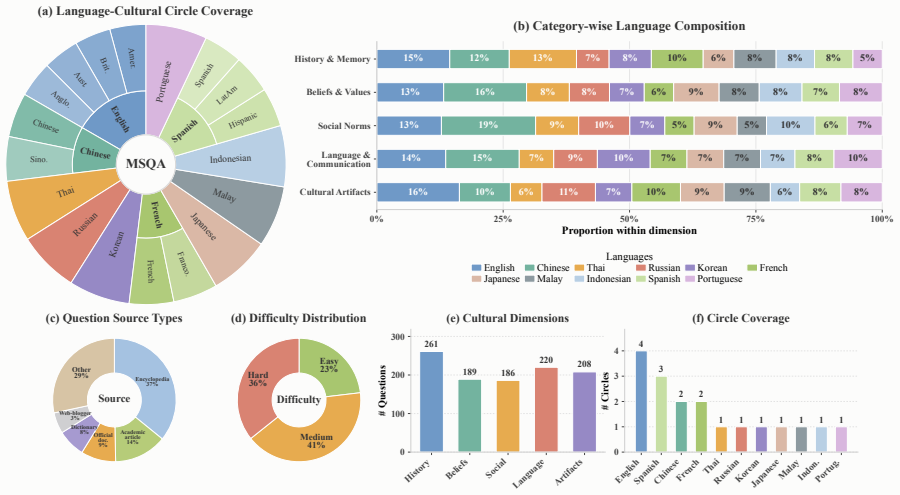
The MSQA benchmark of natively sourced questions across 11 language groups and five cultural dimensions, which measures cultural competence separately from cross-lingual transfer.
If this is right
- Cultural performance correlates more strongly with pre-training exposure than with general reasoning ability.
- Models remain overconfident when answering questions from unfamiliar cultures.
- Repeated sampling produces unstable rather than reliable correctness on cultural items.
- Retrieval augmentation improves results unevenly and mainly on long-tail facts.
- Cultural alignment demands intervention beyond calibration, sampling, or retrieval at inference time.
Where Pith is reading between the lines
- Model developers could improve results by deliberately balancing cultural representation during pre-training rather than relying on post-hoc fixes.
- Separate cultural-knowledge tests should become standard when comparing multilingual models.
- Users from underrepresented cultures may require targeted adaptation of general models instead of expecting out-of-the-box competence.
Load-bearing premise
Natively sourced questions accurately capture locally grounded cultural knowledge without bias from collection methods or confounding factors such as question difficulty.
What would settle it
An experiment that equalizes accuracy across all 11 language groups on MSQA by changing only pre-training data composition or by applying a single inference-time method would falsify the locality effect and the claim that deeper intervention is required.
Figures
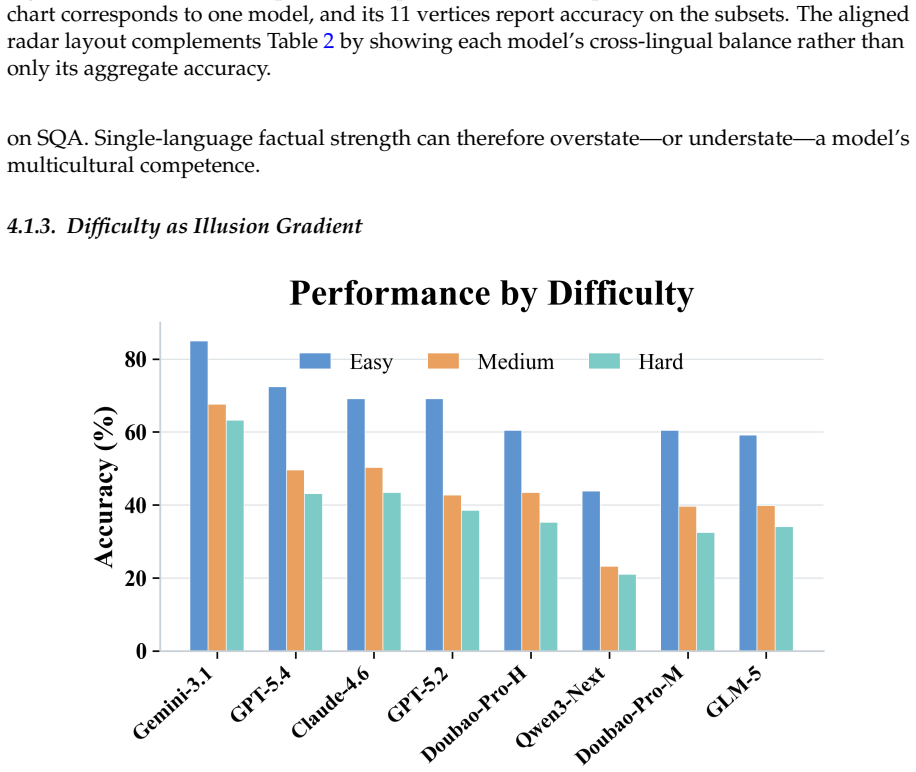
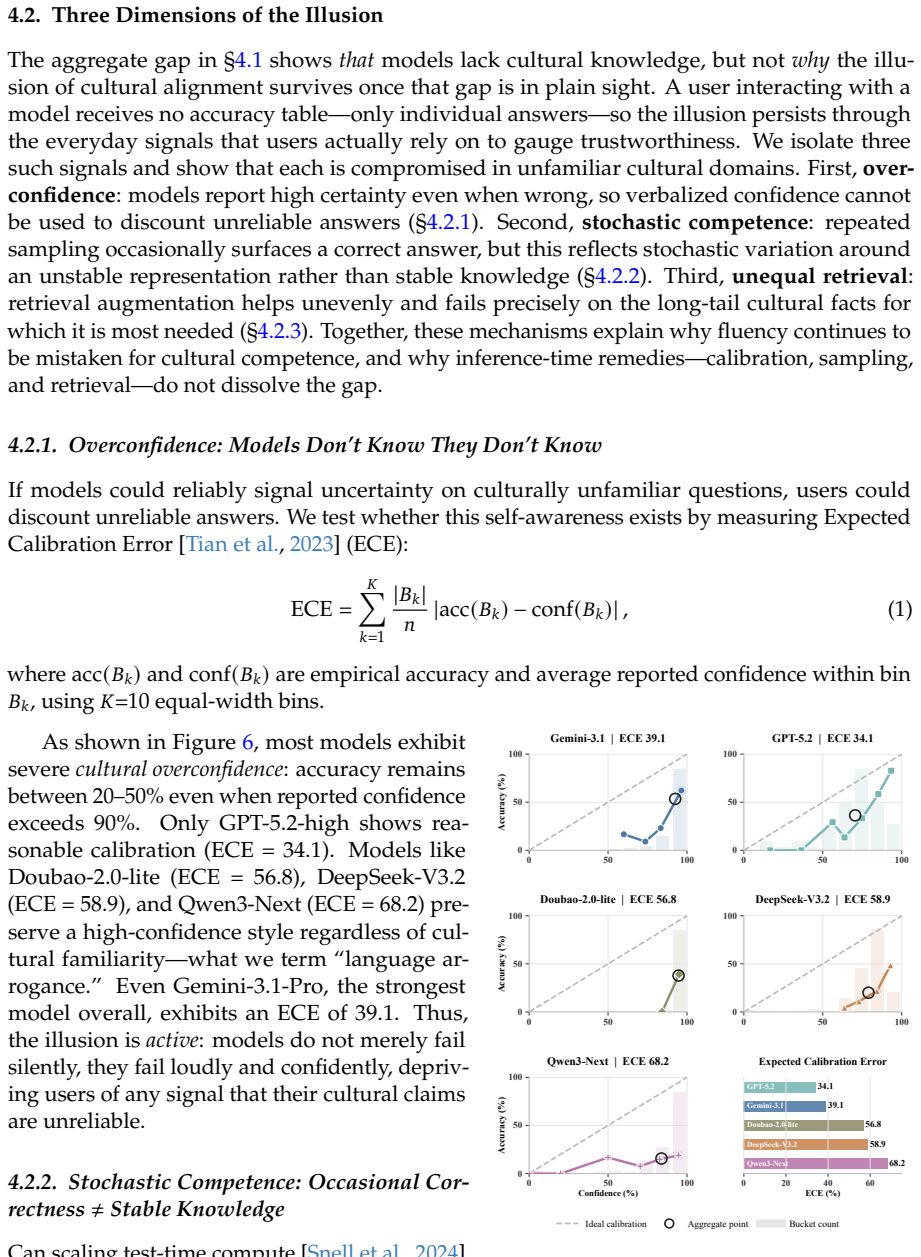
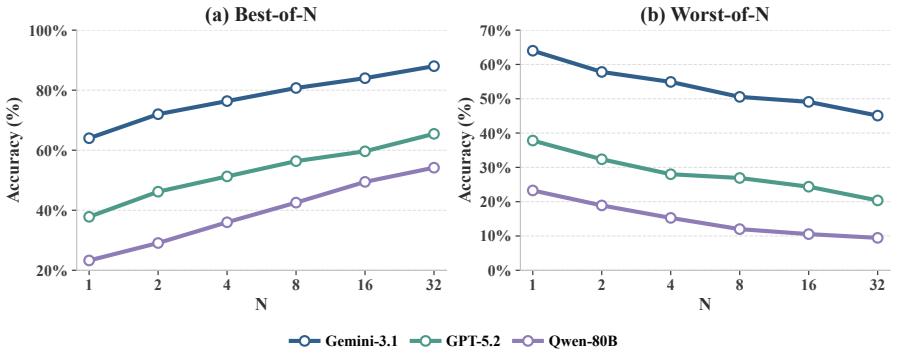
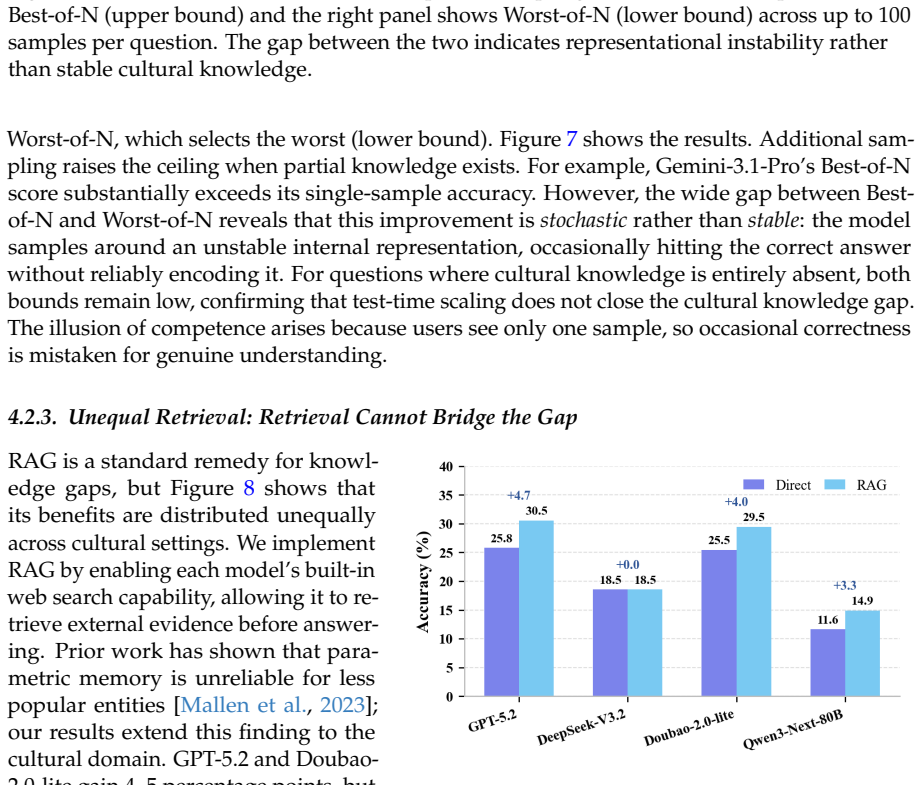
read the original abstract
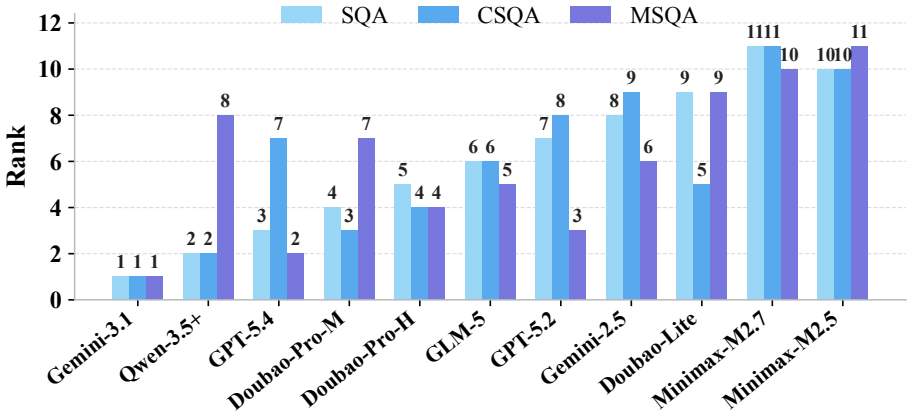
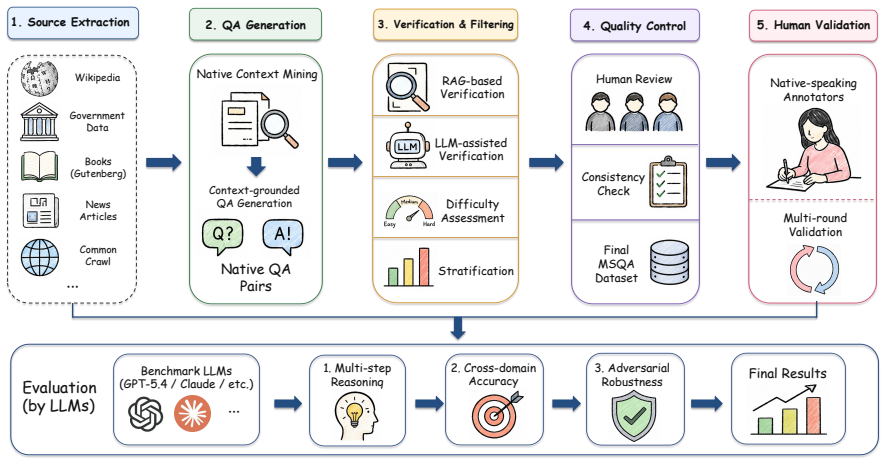
Multilingual fluency often invites a stronger assumption: a model that can speak a user's language must also understand the culture encoded by that language. We call this the Illusion of Cultural Alignment. To test this assumption directly, we introduce MSQA, a benchmark of 1,064 natively sourced questions across 11 language groups, five cultural dimensions, and three difficulty tiers. Unlike translated benchmarks, MSQA targets locally grounded knowledge and reduces shortcuts from English-centric cross-lingual transfer. Evaluating 18 LLMs, we find substantial cultural degradation and a pronounced Locality Effect: cultural competence tracks pre-training exposure more closely than general reasoning ability. We further show that common inference-time remedies do not dissolve the illusion. Models remain overconfident on unfamiliar cultural questions, repeated sampling yields unstable rather than reliable correctness, and retrieval augmentation helps unevenly on long-tail facts. These findings indicate that cultural alignment cannot be inferred from multilingual ability alone and requires deeper intervention than calibration, sampling, or retrieval at inference time
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MSQA, a benchmark consisting of 1,064 natively sourced questions spanning 11 language groups, five cultural dimensions, and three difficulty tiers, to directly test the assumption that multilingual fluency in LLMs implies cultural alignment (termed the 'Illusion of Cultural Alignment'). Evaluating 18 LLMs, the authors report substantial cultural degradation, a 'Locality Effect' in which cultural competence correlates more strongly with pre-training data exposure than with general reasoning ability, and that common inference-time interventions (calibration, repeated sampling, retrieval augmentation) fail to close the gaps. They conclude that cultural alignment requires deeper interventions than multilingual capability or post-hoc fixes.
Significance. If the benchmark construction and controls are shown to isolate locally grounded cultural knowledge without confounding by difficulty or sourcing artifacts, the work would provide a useful empirical demonstration that multilingual performance does not entail cultural competence and that inference-time methods are insufficient, motivating research on culturally targeted pre-training or fine-tuning. The scale (1,064 questions, 18 models) and the explicit contrast between native sourcing and translated benchmarks are strengths.
major comments (2)
- [Abstract] Abstract: The central claim that performance differences reflect cultural competence (rather than question difficulty, English transfer, or sourcing artifacts) rests on the assertion that natively sourced questions 'target locally grounded knowledge and reduce shortcuts,' yet the abstract provides no quantitative validation such as inter-annotator agreement on cultural specificity, difficulty calibration against non-cultural controls, or statistical tests for confounding variables; this directly undermines verification of the Locality Effect and the conclusion about inference-time remedies.
- [Abstract] The reported 'Locality Effect' (cultural competence tracks pre-training exposure) is load-bearing for the claim that multilingual ability alone is insufficient, but without details on how pre-training exposure was quantified or correlated (e.g., via data mixture statistics or proxy measures), it is unclear whether the observed gaps are attributable to cultural knowledge or to uneven question difficulty across the three tiers and 11 groups.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from additional quantitative details to support the central claims regarding cultural competence and the Locality Effect. We will revise the abstract to incorporate summaries of the relevant metrics and methods from the full manuscript. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that performance differences reflect cultural competence (rather than question difficulty, English transfer, or sourcing artifacts) rests on the assertion that natively sourced questions 'target locally grounded knowledge and reduce shortcuts,' yet the abstract provides no quantitative validation such as inter-annotator agreement on cultural specificity, difficulty calibration against non-cultural controls, or statistical tests for confounding variables; this directly undermines verification of the Locality Effect and the conclusion about inference-time remedies.
Authors: We acknowledge that the abstract, as currently written, does not include these quantitative elements. The full manuscript reports inter-annotator agreement on cultural specificity, difficulty calibration against controls, and statistical tests for potential confounders in the methods and appendix sections. To directly address the concern and strengthen verifiability of the Locality Effect and inference-time conclusions, we will revise the abstract to summarize these key validations. revision: yes
-
Referee: [Abstract] The reported 'Locality Effect' (cultural competence tracks pre-training exposure) is load-bearing for the claim that multilingual ability alone is insufficient, but without details on how pre-training exposure was quantified or correlated (e.g., via data mixture statistics or proxy measures), it is unclear whether the observed gaps are attributable to cultural knowledge or to uneven question difficulty across the three tiers and 11 groups.
Authors: We agree that the abstract should specify the quantification approach for pre-training exposure to support the load-bearing claim. The manuscript uses proxy measures derived from publicly available model training data distributions and reports correlations with performance. We will revise the abstract to include a brief description of this proxy and the correlation method, clarifying that the effect is distinguished from difficulty variations across tiers and groups. revision: yes
Circularity Check
No circularity: purely empirical benchmark paper
full rationale
The paper constructs MSQA as a new benchmark via native sourcing across languages and cultures, then reports empirical evaluations of 18 LLMs on cultural competence metrics. No equations, fitted parameters, predictions, or derivations appear in the provided text or abstract. Central claims rest on direct performance observations rather than any self-referential reduction or self-citation chain that would force results by construction. The analysis is therefore self-contained with no load-bearing steps that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natively sourced questions reduce shortcuts from English-centric cross-lingual transfer compared to translated benchmarks.
Reference graph
Works this paper leans on
-
[1]
Measuring short-form factuality in large language models
Measuring short-form factuality in large language models , author=. arXiv preprint arXiv:2411.04368 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Chinese simpleqa: A chinese factuality evaluation for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
arXiv preprint arXiv:2504.10356 , year=
Multiloko: a multilingual local knowledge benchmark for llms spanning 31 languages , author=. arXiv preprint arXiv:2504.10356 , year=
-
[6]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Worldvaluesbench: A large-scale benchmark dataset for multi-cultural value awareness of language models , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[7]
CulturALL: Benchmarking Multilingual and Multicultural Competence of LLMs on Grounded Tasks
CulturALL: Benchmarking Multilingual and Multicultural Competence of LLMs on Grounded Tasks , author=. arXiv preprint arXiv:2604.19262 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
CulturalBench: A robust, diverse and challenging benchmark for measuring LMs' cultural knowledge through human-AI red-teaming , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
NormAd: A framework for measuring the cultural adaptability of large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[10]
Advances in Neural Information Processing Systems , volume=
Blend: A benchmark for llms on everyday knowledge in diverse cultures and languages , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Common to Whom? Regional Cultural Commonsense and LLM Bias in India
Common to Whom? Regional Cultural Commonsense and LLM Bias in India , author=. arXiv preprint arXiv:2601.15550 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
International Conference on Learning Representations , volume=
Include: Evaluating multilingual language understanding with regional knowledge , author=. International Conference on Learning Representations , volume=
-
[13]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
NativQA: Multilingual culturally-aligned natural query for LLMs , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[14]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
CLIcK: A benchmark dataset of cultural and linguistic intelligence in Korean , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[15]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[16]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[17]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[18]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
2026 , howpublished=
Claude Models Overview , author=. 2026 , howpublished=
2026
-
[21]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Seed1. 5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Minimax-m1: Scaling test-time compute efficiently with lightning attention , author=. arXiv preprint arXiv:2506.13585 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.