GMO-E²DIT: Grounded Multi-Operation Editing for E-Commerce Images
Pith reviewed 2026-07-02 13:54 UTC · model grok-4.3
The pith
A VLM agent builds region-grounded edit plans and a reflection loop executes them iteratively to handle multi-step e-commerce image edits from vague instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
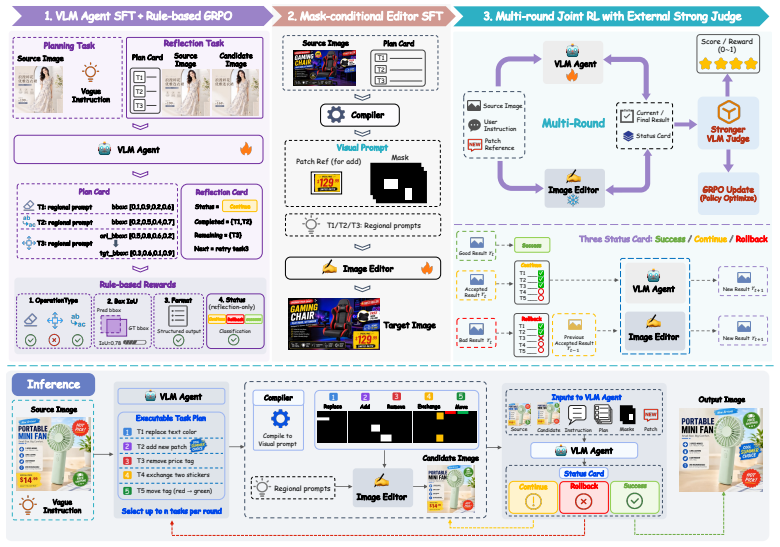
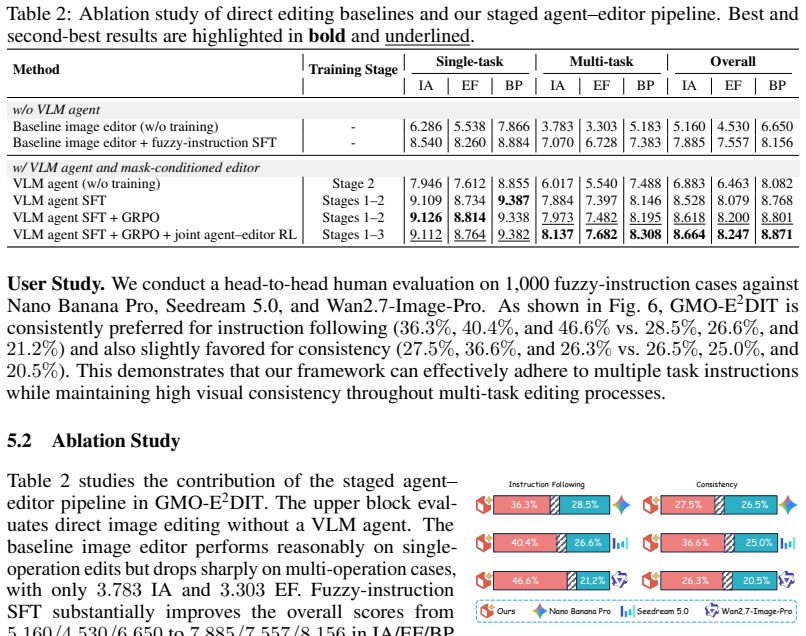
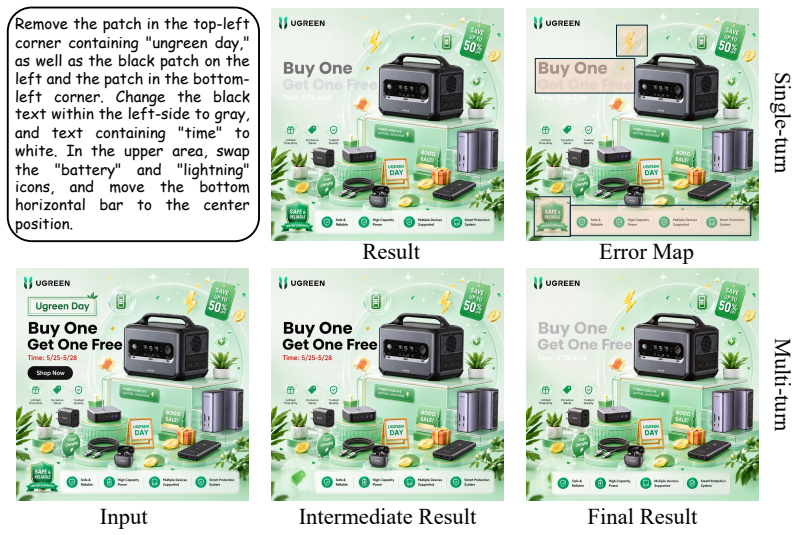
GMO-E²DIT couples a Vision-Language Model agent with a mask-conditioned image editor. The agent constructs a region-grounded edit agenda from underspecified instructions, decoupling cognitive reasoning from generative rendering. Sub-programs are executed via operation-aware masks and references inside a reflection-driven loop that inspects intermediate results, preserves safe partial progress, retries unfinished operations, and recovers from errors.
What carries the argument
The VLM agent constructing a region-grounded edit agenda, combined with a reflection-driven loop that inspects and corrects intermediate edit results.
If this is right
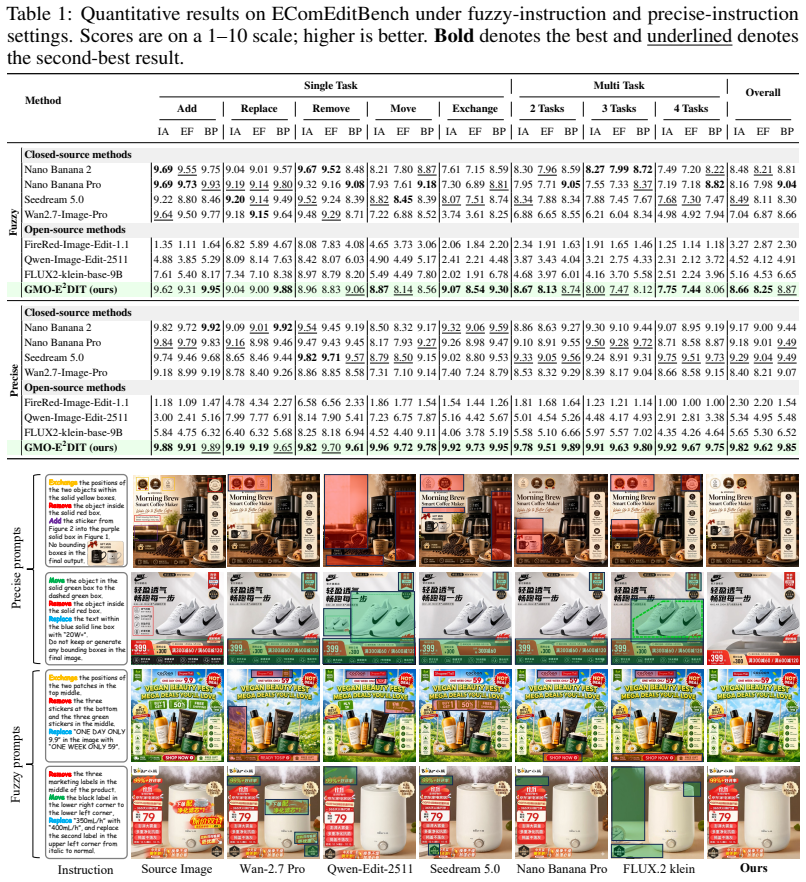
- Instruction accuracy and edit fidelity exceed those of existing one-shot baselines on multi-operation tasks.
- Safe partial progress is retained even when some operations initially fail.
- Cognitive planning and pixel synthesis can be handled by separate modules without loss of overall performance.
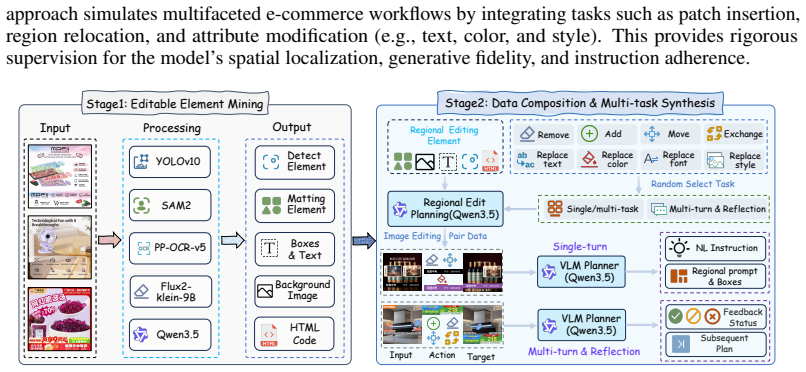
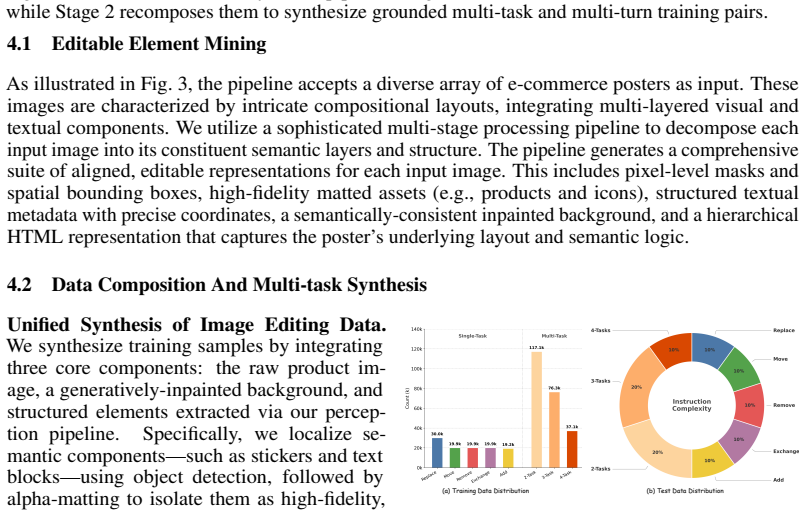
- A unified data pipeline can supply aligned supervision for planning, execution, and reflection stages.
Where Pith is reading between the lines
- The same separation of planning from rendering could extend to other tasks that require sequential localized changes, such as video or 3D model editing.
- Performance gains would likely scale with improvements in the underlying vision-language model's ability to produce accurate agendas.
- Commercial use would still benefit from optional human review for edits where mistakes carry high cost.
- The introduced benchmark offers a concrete way to compare future multi-operation editors on instruction following and content preservation.
Load-bearing premise
The vision-language model can reliably turn vague instructions into correct region-specific operation sequences and the reflection loop can detect and fix errors without introducing new ones.
What would settle it
A collection of underspecified e-commerce edit instructions where the VLM produces wrong region assignments or the reflection step leaves visible errors or undoes prior correct changes.
Figures





read the original abstract
Real-world e-commerce image editing often requires multiple, localized, and auditable operations rather than global restyling. This compositional nature poses a dual challenge: models must precisely apply all requested edits to the correct regions while preserving unmodified content, even under ambiguous instructions. Existing one-shot editors conflate intent resolution, spatial grounding, and synthesis into a single step, frequently resulting in partial execution failures, which is unacceptable for commercial scenarios. To address this, we introduce GMO-E$^2$DIT, an agentic editing framework that couples a Vision-Language Model (VLM) with a mask-conditioned image editor to tackle structured multi-turn task completion. Given an underspecified instruction, the VLM agent constructs a region-grounded edit agenda, effectively decoupling cognitive reasoning from generative rendering. The framework then executes sub-programs via operation-aware masks and references, utilizing a reflection-driven loop to inspect intermediate results and determine the subsequent state. This iterative mechanism reliably preserves safe partial progress, retries unfinished operations, and recovers from errors. Furthermore, we develop a unified data pipeline providing aligned supervision for planning, execution, and reflection, alongside EComEditBench, a comprehensive benchmark for instruction-driven evaluation. Extensive experiments demonstrate that GMO-E$^2$DIT achieves competitive performance compared to strong closed-source models, yielding superior instruction accuracy and edit fidelity over existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GMO-E²DIT, an agentic framework for multi-operation e-commerce image editing. A VLM constructs a region-grounded edit agenda from underspecified instructions, decoupling reasoning from rendering; sub-programs are executed via operation-aware masks and references, with a reflection-driven loop that inspects intermediates, preserves partial progress, retries, and recovers from errors. The authors also contribute a unified data pipeline for planning/execution/reflection supervision and EComEditBench for instruction-driven evaluation. The central claim is that GMO-E²DIT achieves competitive performance with strong closed-source models while delivering superior instruction accuracy and edit fidelity over existing baselines.
Significance. If the performance claims hold, the work would be significant for commercial image-editing pipelines by enabling auditable, compositional edits under ambiguous instructions. Explicit strengths include the introduction of EComEditBench as a new benchmark and the unified data pipeline that supplies aligned supervision for the three stages; these could serve as reusable resources for the community even if the specific agentic loop requires further validation.
major comments (2)
- [Abstract] Abstract: the claim that GMO-E²DIT 'achieves competitive performance... yielding superior instruction accuracy and edit fidelity' is presented without any quantitative metrics, tables, baseline names, or error analysis, rendering the central empirical claim unverifiable from the manuscript.
- [Experiments] Experiments (or equivalent section): no description is given of EComEditBench construction, its difficulty distribution, the comparison protocol for closed-source models, or failure-mode analysis of the reflection loop, all of which are load-bearing for assessing whether the reported edge is real or an artifact of benchmark design.
minor comments (2)
- [Method] The term 'operation-aware masks' is used without an explicit definition or reference to its construction on first appearance.
- [Figures] Figure captions could more explicitly link visual examples to the corresponding agenda steps and reflection outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve transparency and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GMO-E²DIT 'achieves competitive performance... yielding superior instruction accuracy and edit fidelity' is presented without any quantitative metrics, tables, baseline names, or error analysis, rendering the central empirical claim unverifiable from the manuscript.
Authors: We agree that the abstract presents the performance claim at a high level without specific numbers or references. The manuscript body includes quantitative tables and baseline comparisons in the Experiments section. To address the concern, we will revise the abstract to incorporate key quantitative highlights (e.g., specific accuracy and fidelity metrics) along with pointers to the relevant tables and sections. revision: yes
-
Referee: [Experiments] Experiments (or equivalent section): no description is given of EComEditBench construction, its difficulty distribution, the comparison protocol for closed-source models, or failure-mode analysis of the reflection loop, all of which are load-bearing for assessing whether the reported edge is real or an artifact of benchmark design.
Authors: We acknowledge these details are insufficiently elaborated in the current manuscript. While EComEditBench and the data pipeline are introduced, the construction process, difficulty distribution, closed-source comparison protocol, and reflection-loop failure-mode analysis are not fully described. We will expand the Experiments section to provide these specifics, enabling readers to evaluate the benchmark and results more rigorously. revision: yes
Circularity Check
No equations, derivations, or self-referential reductions present in framework description.
full rationale
The paper introduces GMO-E²DIT as a new agentic framework that decouples VLM-based agenda construction from mask-conditioned editing and adds a reflection loop. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations are described. The construction is presented as an original system design with an accompanying data pipeline and benchmark; performance claims are empirical rather than derived from prior inputs by construction. This matches the default case of a self-contained descriptive paper with no circularity in any claimed derivation chain.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.