LeNEPA: No-Augmentation Next-Latent Prediction for Time-Series Representation Learning
Pith reviewed 2026-07-02 15:30 UTC · model grok-4.3
The pith
LeNEPA maintains frozen-probe gains on multiple time-series datasets when its recipe stays fixed, unlike an ECG-tuned JEPA baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
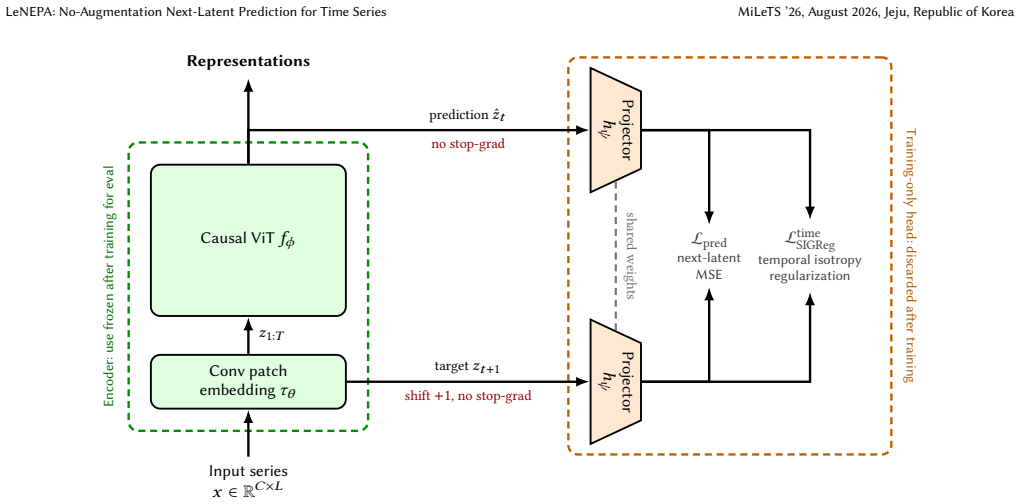
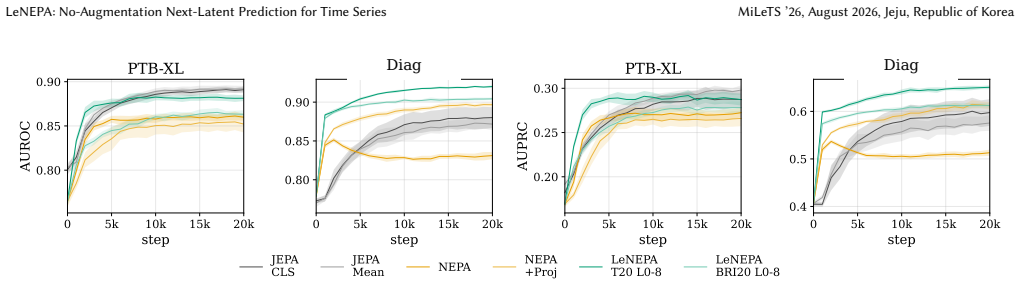
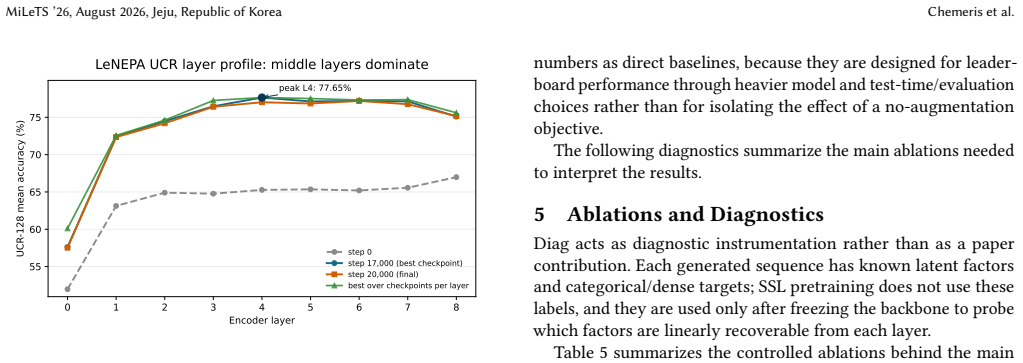
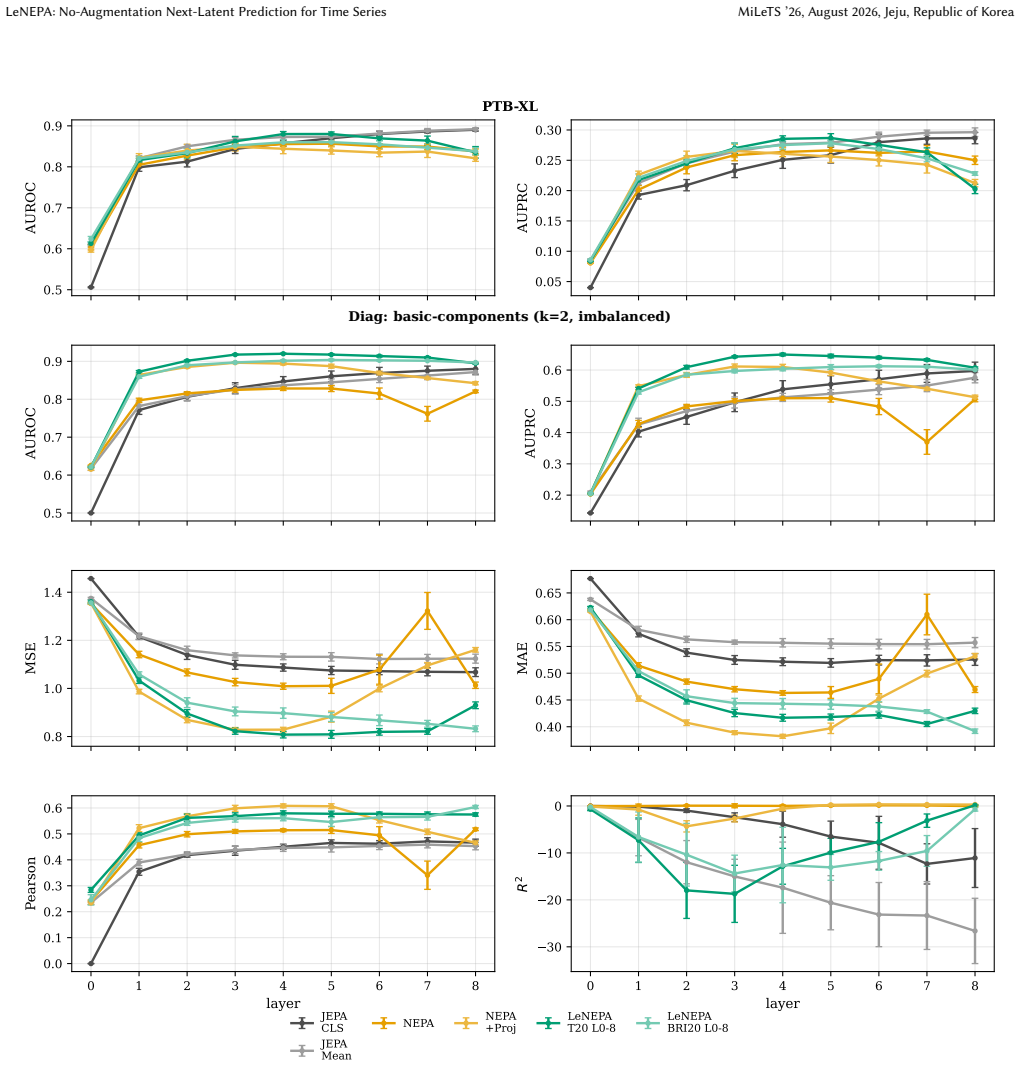
LeNEPA replaces the stop-gradient/EMA stabilization used by vanilla NEPA with SIGReg-based isotropy regularization and computes the predictive loss in a lightweight projected space that is discarded for evaluation. When both methods are retrained independently on each dataset while keeping their method-specific recipes unchanged, LeNEPA preserves useful frozen-probe gains on PTB-XL and Diag whereas the ECG-tuned JEPA recipe is strong in-domain on PTB-XL but weaker on Diag. Learning curves show LeNEPA reaches 80 percent of its final AUROC/AUPRC gain after 2-5k updates. A CauKer-pretrained LeNEPA variant also reaches 77.65 percent mean UCR-128 Random-Forest accuracy.
What carries the argument
LeNEPA, a no-augmentation next-latent-token objective with causal backbone, SIGReg isotropy regularization, and predictive loss computed in a discarded lightweight projection space.
If this is right
- LeNEPA preserves useful frozen-probe gains on both PTB-XL and Diag under fixed-recipe conditions.
- LeNEPA reaches 80 percent of final gain after 2-5k updates, earlier than the comparison method.
- A CauKer-pretrained LeNEPA variant achieves 77.65 percent mean accuracy on UCR-128 in a single-seed run.
- The results position no-augmentation latent prediction as a candidate recipe for low-retuning time-series SSL.
Where Pith is reading between the lines
- The fixed-recipe protocol highlights how avoiding augmentations may reduce sensitivity to dataset-specific statistics in SSL.
- Discarding the projection space after training points to a path for lighter inference without changing the learned representations.
- Faster early gains suggest the method could reduce compute needed to reach usable representations in new time-series domains.
- The single external UCR check leaves room for multi-seed runs to confirm how close the method stays to other reported baselines.
Load-bearing premise
That keeping the method-specific recipes unchanged across datasets constitutes a fair and informative stress test of robustness rather than simply reflecting differences in how well each recipe matches the statistics of each corpus.
What would settle it
Retuning the JEPA recipe independently on Diag and checking whether its frozen-probe performance then matches or exceeds LeNEPA on that corpus.
Figures
read the original abstract
Time series are central to modern data mining applications, from industrial telemetry and server metrics to finance and physiology, yet time-series self-supervised learning often depends on view and augmentation choices that encode domain-specific invariances. We study how an SSL recipe behaves when its method-specific configuration is reused unchanged after the pretraining signal family changes, framing this as a fixed-recipe stress test rather than a comparison against optimally tuned methods. We introduce Latent Euclidean Next-Embedding Prediction Architecture (LeNEPA), a no-augmentation next-latent-token objective with a causal backbone. LeNEPA replaces the stop-gradient/EMA stabilization used by vanilla NEPA with SIGReg-based isotropy regularization and computes the predictive loss in a lightweight projected space that is discarded for evaluation. We compare LeNEPA with an ECG-tuned JEPA recipe under a fixed-horizon frozen-probe protocol on PTB-XL and Diag, a synthetic diagnostic corpus generated with Aionoscope. Both methods are retrained independently on each dataset while keeping their method-specific recipes unchanged. In this protocol, the ECG-tuned JEPA recipe is strong in-domain on PTB-XL but weaker when reused unchanged on Diag, whereas LeNEPA preserves useful frozen-probe gains on both datasets. Learning curves suggest faster early representation acquisition: LeNEPA reaches 80% of its final AUROC/AUPRC gain after 2--5k updates, compared with 5--10k updates for the faster JEPA readout. As a separate external frozen-encoder check, a CauKer-pretrained LeNEPA variant reaches 77.65% mean UCR-128 Random-Forest accuracy in a single-seed, best-checkpoint run, within 1.16 points of Mantis and within 0.24 points of MOMENT (77.89%). Overall, the results support no-augmentation latent prediction as a useful candidate recipe for low-retuning time-series SSL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LeNEPA, a no-augmentation next-latent prediction architecture for time-series self-supervised learning that replaces stop-gradient/EMA with SIGReg isotropy regularization and evaluates predictive loss in a projected space. Under a fixed-recipe protocol, it claims LeNEPA preserves frozen-probe AUROC/AUPRC gains on both PTB-XL and the synthetic Diag corpus while an ECG-tuned JEPA weakens on Diag, reaches 80% of final gains after 2-5k updates, and achieves competitive 77.65% mean accuracy on UCR-128 via a CauKer-pretrained variant.
Significance. If the fixed-recipe empirical results hold, the work would demonstrate that no-augmentation latent prediction with isotropy regularization can produce more transferable time-series representations across domains without retuning, which is valuable for applications where domain-specific augmentations are impractical. The external UCR frozen-encoder check provides an independent point of comparison to existing methods like MOMENT.
major comments (1)
- [fixed-recipe stress test and cross-dataset comparison] The central claim that LeNEPA demonstrates superior suitability for low-retuning rests on the fixed-recipe stress test (described in the abstract and experimental protocol). The manuscript does not detail the construction process or level of domain specificity for the ECG-tuned JEPA components (augmentations, EMA, etc.) versus LeNEPA's general design choices, so the observed weakening of JEPA on Diag could reflect statistical mismatch with the Aionoscope-generated corpus rather than an inherent robustness advantage of no-augmentation latent prediction.
minor comments (1)
- [Abstract and dataset description] The generator 'Aionoscope' for the Diag dataset is mentioned without citation or description, which hinders reproducibility of the synthetic corpus used in the stress test.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the fixed-recipe evaluation. We address the major comment point-by-point below and will revise the manuscript to improve clarity on baseline construction.
read point-by-point responses
-
Referee: [fixed-recipe stress test and cross-dataset comparison] The central claim that LeNEPA demonstrates superior suitability for low-retuning rests on the fixed-recipe stress test (described in the abstract and experimental protocol). The manuscript does not detail the construction process or level of domain specificity for the ECG-tuned JEPA components (augmentations, EMA, etc.) versus LeNEPA's general design choices, so the observed weakening of JEPA on Diag could reflect statistical mismatch with the Aionoscope-generated corpus rather than an inherent robustness advantage of no-augmentation latent prediction.
Authors: We agree that the manuscript would benefit from expanded detail on the JEPA baseline construction. The ECG-tuned JEPA recipe uses view augmentations (time warping, noise injection) and EMA decay schedules that were selected via validation on PTB-XL to optimize in-domain frozen-probe performance; these choices encode ECG-specific invariances and are not intended to be domain-agnostic. LeNEPA, by design, omits augmentations entirely and relies on SIGReg isotropy plus projected-space prediction, making its recipe independent of dataset-specific view choices. The Diag corpus is generated via Aionoscope to retain diagnostic waveform statistics while introducing controlled distributional shifts, serving as a deliberate out-of-domain probe for the fixed-recipe protocol. We will revise the experimental protocol section to list the precise JEPA hyperparameters, their PTB-XL selection procedure, and additional statistics comparing PTB-XL and Diag marginals. This will allow readers to better assess whether the observed JEPA degradation stems from recipe mismatch or from the absence of augmentation-based robustness in LeNEPA. revision: yes
Circularity Check
No circularity; purely empirical fixed-recipe comparisons
full rationale
The manuscript contains no derivation chain, uniqueness theorems, or predictive claims that reduce to fitted parameters or self-citations. All load-bearing statements are direct reports of AUROC/AUPRC and accuracy numbers obtained by retraining LeNEPA and the ECG-tuned JEPA recipe independently on PTB-XL and Diag under an explicitly stated unchanged-recipe protocol. External benchmarks (Mantis, MOMENT, UCR-128) are cited as independent reference points rather than as load-bearing premises. The central result is therefore a set of empirical observations, not a reduction of any quantity to itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Randall Balestriero and Yann LeCun. 2025. LeJEPA: Provable and Scalable Self- Supervised Learning Without the Heuristics. https://arxiv.org/abs/2511.08544 arXiv:2511.08544
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. 2024. Revisiting Feature Prediction for Learning Visual Representations from Video. https://arxiv.org/abs/2404.08471 arXiv:2404.08471
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
-
[5]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging Properties in Self-Supervised Vision Transformers. https://arxiv.org/abs/2104.14294 arXiv:2104.14294
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Alexander Chemeris, Ming Jin, and Randall Balestriero. 2026. Aionoscope: De- bugging Latent-State Accessibility in Time-Series Representations. InThe 12th Mining and Learning from Time Series Workshop (MiLeTS ’26), held in conjunction with KDD 2026. https://github.com/langotime/aionoscope
2026
-
[7]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A Simple Framework for Contrastive Learning of Visual Representations. https: //arxiv.org/abs/2002.05709 arXiv:2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh
-
[9]
The UCR time series archive.IEEE/CAA Journal of Automatica Sinica6, 6 (2019), 1293–1305
2019
- [10]
-
[11]
Vasilii Feofanov, Songkang Wen, Marius Alonso, Romain Ilbert, Hongbo Guo, Malik Tiomoko, Lujia Pan, Jianfeng Zhang, and Ievgen Redko. 2025. Mantis: Light- weight calibrated foundation model for user-friendly time series classification. arXiv preprint arXiv:2502.15637(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Vasilii Feofanov, Songkang Wen, Jianfeng Zhang, Lujia Pan, and Ievgen Redko
-
[13]
doi:10.48550/arXiv.2602.17868 arXiv:2602.17868; ICLR 2026 TSALM Workshop Poster
MantisV2: Closing the Zero-Shot Gap in Time Series Classification with Synthetic Data and Test-Time Strategies. doi:10.48550/arXiv.2602.17868 arXiv:2602.17868; ICLR 2026 TSALM Workshop Poster
- [14]
-
[15]
Bootstrap your own latent: A new approach to self-supervised learning,
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhao- han Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. 2020. Bootstrap your own latent: A new approach to self-supervised Learning. https://arxiv.org/abs/2006....
-
[16]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick
-
[17]
Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners. https://arxiv.org/abs/ 2111.06377 arXiv:2111.06377
work page internal anchor Pith review Pith/arXiv arXiv
- [18]
-
[19]
Chenguo Lin, Xumeng Wen, Wei Cao, Congrui Huang, Jiang Bian, Stephen Lin, and Zhirong Wu. 2024. NuTime: Numerically Multi-Scaled Embedding for Large- Scale Time-Series Pretraining.Transactions on Machine Learning Research(2024). https://openreview.net/forum?id=TwiSBZ0p9u
2024
- [20]
- [21]
-
[22]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. https://arxiv.org/abs/1706.03762 arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Lunze, Wojciech Samek, and Tobias Schaeffter
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I. Lunze, Wojciech Samek, and Tobias Schaeffter. 2020. PTB-XL, a large publicly available electrocardiography dataset.Scientific Data7, 1 (2020), 154. doi:10.1038/ s41597-020-0495-6
2020
- [24]
- [25]
- [26]
- [27]
-
[28]
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. 2022. TS2Vec: Towards Universal Representation of Time Series. https://arxiv.org/abs/2106.10466 arXiv:2106.10466. LeNEPA: No-Augmentation Next-Latent Prediction for Time Series MiLeTS ’26, August 2026, Jeju, Republic of Korea 0.5 0.6 0.7 0.8 0.9AUROC 0.05 0....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.