Understanding Large Language Models
Pith reviewed 2026-07-02 12:51 UTC · model grok-4.3
The pith
Debates on LLM cognition are misguided by misconceptions about optimization and cognitive capacity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM behavior cannot be adequately explained by either full anthropomorphism or pure pattern memorization; instead, evidence from emergent capabilities, failure modes, and internal mechanisms supports a nuanced account that leaves room for AI cognition while recognizing its distinct nature from human cognition.
What carries the argument
Synthesis of studies on emergent capabilities, insightful failure cases, and explainable AI methods (neuron activation analysis and circuit tracing) to challenge both anthropomorphic and memorization-only accounts.
If this is right
- Discussions of AI understanding should incorporate mechanistic evidence rather than relying solely on behavioral tests.
- Training objectives and data scale enable generalist rather than specialized models.
- Neither blanket dismissal of AI cognition nor direct equivalence to human minds follows from current evidence.
Where Pith is reading between the lines
- Future benchmarks could be designed to isolate whether specific internal circuits produce novel strategies absent from training data.
- This stance connects to questions in philosophy of mind about minimal conditions for attributing understanding to artificial systems.
- If the argument holds, safety evaluations might prioritize circuit-level interventions over high-level behavioral probes alone.
Load-bearing premise
The cited body of work on capabilities, failures, and mechanisms is representative enough to rule out both simplistic anthropomorphic and purely memorization-based explanations.
What would settle it
A demonstration that every observed LLM capability on complex tasks reduces entirely to memorization of specific training examples with no contribution from optimization-driven generalization or internal mechanisms.
Figures
read the original abstract
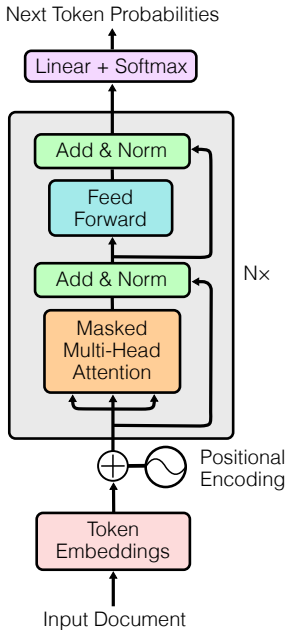
Large Language Models (LLMs) represent one of the most significant advances in AI and natural language processing in recent years. Still, many pressing questions about their mechanisms, capabilities, and relationship to human cognition remain highly debated. This chapter aims to outline our current understanding of LLMs by discussing recent evidence on emerging capabilities and their mechanistic implementation within processing layers. We begin with a concise overview of the Transformer architecture, emphasizing how the attention mechanism enables training on massive datasets, allowing LLMs to function as generalist rather than specialized models. Next, we examine emergent LLM capabilities that appear to resemble aspects of human cognition, including symbolic reasoning, theory of mind, and deception strategies. Several studies provide evidence that LLMs can solve tasks previously thought to require human-like cognition. Other studies reveal insightful failure cases that shed light on the differences between human and LLM cognition. Alongside these findings, we review explainable AI approaches ranging from neuron activation analysis to circuit tracing. In the final section, we address current debates concerning what LLMs genuinely understand versus what they merely appear to understand. Prominent arguments against AI anthropomorphism point to the simplicity of LLM training objectives, claiming that LLM behavior is better explained by pattern memorization of training data than by genuine cognition. We argue that this standpoint is guided by misconceptions about optimization processes and cognitive capacity, and advocate for a more nuanced discussion of LLM cognition that neither dismisses the differences between humans and LLMs nor precludes the possibility of AI cognition through overly simplistic reductionist arguments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a review chapter surveying the Transformer architecture and attention mechanism, emergent LLM capabilities (symbolic reasoning, theory of mind, deception), mechanistic interpretability methods (neuron activation, circuit tracing), and debates on genuine understanding versus pattern memorization. It argues that anti-anthropomorphic positions rest on misconceptions about optimization processes and cognitive capacity, and advocates a nuanced stance that acknowledges differences between humans and LLMs while not precluding AI cognition.
Significance. If the cited evidence is represented accurately and without selection bias, the review could usefully synthesize findings on LLM capabilities and limitations to promote more balanced discussion in the field. The explicit rejection of both overly anthropomorphic and purely reductionist accounts is a constructive contribution to ongoing debates.
major comments (2)
- [final section] Final section: the central claim that anti-anthropomorphism arguments are guided by misconceptions about optimization processes and cognitive capacity is load-bearing for the paper's interpretive stance, yet the section provides only a general assertion rather than direct engagement with specific cited studies on training objectives (e.g., next-token prediction) and their implications for cognition.
- [emergent capabilities and failure cases sections] Sections on emergent capabilities and failure cases: the argument that the selected studies collectively support rejecting both anthropomorphic and purely memorization-based accounts assumes representativeness; without explicit criteria for study inclusion or discussion of potential counter-evidence, the nuanced position risks resting on an unexamined sample of the literature.
minor comments (1)
- [abstract] The abstract and structure overview would benefit from explicit section headings or a roadmap paragraph to improve readability for readers navigating the review.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and will revise the manuscript to strengthen the relevant sections while preserving the overall interpretive stance.
read point-by-point responses
-
Referee: [final section] Final section: the central claim that anti-anthropomorphism arguments are guided by misconceptions about optimization processes and cognitive capacity is load-bearing for the paper's interpretive stance, yet the section provides only a general assertion rather than direct engagement with specific cited studies on training objectives (e.g., next-token prediction) and their implications for cognition.
Authors: We agree that the final section would benefit from more direct engagement with specific studies. In the revised manuscript, we will expand the discussion to explicitly address how next-token prediction objectives can give rise to emergent behaviors that resemble cognitive capacities, citing and analyzing relevant works on the implications of the training process. This will provide a more substantive basis for the claim regarding misconceptions about optimization. revision: yes
-
Referee: [emergent capabilities and failure cases sections] Sections on emergent capabilities and failure cases: the argument that the selected studies collectively support rejecting both anthropomorphic and purely memorization-based accounts assumes representativeness; without explicit criteria for study inclusion or discussion of potential counter-evidence, the nuanced position risks resting on an unexamined sample of the literature.
Authors: We acknowledge the point about potential selection bias. While the sections are intended to illustrate both capabilities and limitations to support a nuanced view, we will add a brief discussion of inclusion criteria (focusing on studies that directly probe reasoning, theory of mind, or memorization in controlled settings) and note key counter-evidence from the broader literature to better substantiate the representativeness of the selected findings. revision: yes
Circularity Check
No significant circularity; review paper with no derivations or self-referential reductions
full rationale
The paper is a discursive review chapter summarizing external literature on LLM architecture, emergent capabilities, mechanistic interpretability, and debates on cognition versus memorization. It advances an interpretive stance against overly reductionist anti-anthropomorphism arguments but contains no equations, fitted parameters, formal derivations, or load-bearing self-citations. All claims rest on cited external studies rather than reducing to the paper's own inputs by construction. No instances of self-definitional reasoning, fitted-input predictions, uniqueness theorems imported from the authors, or ansatz smuggling appear. This matches the default expectation of a non-circular review.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, Guillaume and Yoshua Bengio (2018).Understanding intermediate layers using linear classifier probes.doi:10.48550/arXiv.1610.01644. Available online:http://arxiv.org/abs/1610.01644. Ameisen, Emmanuel, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hos- mer, Jonathan Marcus, Mich...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.01644 2018
-
[2]
Language Mod- els are Few-Shot Learners
Available online: https://www.nature.com/articles/s42254-023-00581-4. Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Ka- plan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Cle...
2020
-
[3]
Truth is Univer- sal: Robust Detection of Lies in LLMs
Available online:https://doi.org/10.1007/s00521-024-10827-6. B¨ urger, Lennart, Fred A. Hamprecht, and Boaz Nadler (2024). “Truth is Univer- sal: Robust Detection of Lies in LLMs”. In:Advances in Neural Information Processing Systems. Ed. by Frank Hutter, Shane Legg, Martin Zinkevich, et al. Vol
-
[4]
Are there theory of mind regions in the brain? A review of the neuroimaging literature
Available online:https://proceedings.neurips.cc/paper/ 2024 / file / f9f54762cbb4fe4dbffdd4f792c31221 - Paper - Conference . pdf. Carrington, Sarah J. and Anthony J. Bailey (2009). “Are there theory of mind regions in the brain? A review of the neuroimaging literature”. In:Human Brain Mapping30.8, pp. 2313–2335.doi:10.1002/hbm.20671. Available online:http...
-
[5]
Deep Neural Networks as Sci- entific Models
Cur- ran Associates, Inc. Available online:https://proceedings.neurips.cc/ paper_files/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49- Abstract.html. Cichy, Radoslaw M. and Daniel Kaiser (2019). “Deep Neural Networks as Sci- entific Models”. In:Trends in Cognitive Sciences23.4, pp. 305–317.doi: 10.1016/j.tics.2019.01.009. Available online:https://www.ce...
-
[6]
Available online:https://aclanthology.org/N19-1423/. Dijk, Bram van, Tom Kouwenhoven, Marco Spruit, and Max Johannes van Duijn (2023). “Large Language Models: The Need for Nuance in Current Debates and a Pragmatic Perspective on Understanding”. In:Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Ed. by Houda Bouamor,...
-
[7]
Transcoders Find Interpretable LLM Feature Circuits
Available online:https : / / aclanthology . org / 2023 . emnlp-main.779/. Duijn, Max J. van, Bram M. A. van Dijk, Tom Kouwenhoven, Werner de Valk, Marco R. Spruit, and Peter van der Putten (2023).Theory of Mind in Large Language Models: Examining Performance of 11 State-of-the-Art models vs. Children Aged 7-10 on Advanced Tests.doi:10.48550/arXiv.2310.203...
-
[8]
Editing anthropomorphic language
Curran Associates, Inc. Available online:https: //proceedings.neurips.cc/paper_files/paper/2024/file/2b8f4db0464cc5b6e9d5e6bea4b9f308- Paper-Conference.pdf. “Editing anthropomorphic language” (2023). In:Nature Reviews Physics5.5, pp. 263–263.doi:10.1038/s42254-023-00584-1. Available online:https: //www.nature.com/articles/s42254-023-00584-1. 17 Elhage, Ne...
-
[9]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Available online: https : / / www . hepi . ac . uk / 2025 / 02 / 26 / student - generative - ai - survey-2025/. Gaur, Vedant and Nikunj Saunshi (2023).Reasoning in Large Language Mod- els Through Symbolic Math Word Problems.doi:10.48550/arXiv.2308. 01906. Available online:http://arxiv.org/abs/2308.01906. Guo, Daya et al. (2025). “DeepSeek-R1 incentivizes ...
-
[10]
Pause Giant Anthropomorphizing Metaphors
Available online:http : / / ieeexplore.ieee.org/document/7780459/. He, Yufei, Yuexin Li, Jiaying Wu, Yuan Sui, Yulin Chen, and Bryan Hooi (2025). Evaluating the Paperclip Maximizer: Are RL-Based Language Models More Likely to Pursue Instrumental Goals?doi:10.48550/arXiv.2502.12206. Available online:http://arxiv.org/abs/2502.12206. Huang, Qing, Yishun Wu, ...
-
[11]
He Had Dangerous Delusions. ChatGPT Admitted It Made Them Worse
Ed. by Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar. Vi- enna, Austria: Association for Computational Linguistics, pp. 24208–24213. doi:10.18653/v1/2025.findings- acl.1242. Available online:https: //aclanthology.org/2025.findings-acl.1242/. Isozaki, Isamu (2024).Understanding the Current State of Reasoning with LLMs. Availab...
-
[12]
A logical calculus of the ideas immanent in nervous activity
Vienna, Austria: PMLR, pp. 32801–32818. Luong, Thang and Edward Lockhart (2025).Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Math- ematical Olympiad. Available online:https://deepmind.google/discover/ blog / advanced - version - of - gemini - with - deep - think - officially - achieves-gold-medal-...
-
[13]
Uncovering mesa-optimization algorithms in Trans- formers, September 2023
Available online: https://distill.pub/2020/circuits/zoom-in. OpenAI (2022).Introducing ChatGPT. Available online:https://openai.com/ index/chatgpt/. Oswald, Johannes von, Maximilian Schlegel, Alexander Meulemans, Seijin Kobayashi, Eyvind Niklasson, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark San- dler, Blaise Ag¨ uera y Arcas, Max Vladymyrov, Razva...
-
[14]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Available online:https://philarchive.org/rec/PUTMAM. Qi, Zhenting, Hongyin Luo, Xuliang Huang, Zhuokai Zhao, Yibo Jiang, Xi- angjun Fan, Himabindu Lakkaraju, and James Glass (2024).Quantifying Generalization Complexity for Large Language Models.doi:10 . 48550 / arXiv.2410.01769. Available online:http://arxiv.org/abs/2410.01769. Raffel, Colin, Noam Shazeer...
-
[15]
Attention is All you Need
Available online:https : / / www . nature . com / articles / d41586-023-02980-0. Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin (2017). “Attention is All you Need”. In:Advances in Neural Information Processing Systems. Vol
2017
-
[16]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Sys- tems
Curran Associates, Inc. Available online:https://papers.nips. cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa- Abstract.html. Wang, Alex, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman (2019). “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Sys- tems”...
2017
-
[17]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Cur- ran Associates, Inc. Available online:https://proceedings.neurips.cc/ paper/2019/hash/4496bf24afe7fab6f046bf4923da8de6-Abstract.html. Wang, Alex, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman (2018). “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”. In:Proceedings of the 2018 EMNLP Wo...
-
[18]
Blake Lemoine: Google fires engineer who said AI tech has feelings
Available online:https://aclanthology. org/W18-5446/. Wertheimer, Tiffany (2022). “Blake Lemoine: Google fires engineer who said AI tech has feelings”. In: Available online:https://www.bbc.com/news/ technology-62275326. Wimmer, Heinz and Josef Perner (1983). “Beliefs about beliefs: Representation and constraining function of wrong beliefs in young childre...
2022
-
[19]
Language agents with reinforcement learning for strategic play in the Werewolf game
Available online:https://www.sciencedirect.com/ science/article/pii/0010027783900045. Xu, Zelai, Chao Yu, Fei Fang, Yu Wang, and Yi Wu (2024). “Language agents with reinforcement learning for strategic play in the Werewolf game”. In:Pro- ceedings of the 41st International Conference on Machine Learning. Vol
-
[20]
‘I want to destroy whatever I want’: Bing’s AI chatbot unsettles US reporter
Vienna, Austria: PMLR, pp. 55434–55464. 24 Yakura, Hiromu, Ezequiel Lopez-Lopez, Levin Brinkmann, Ignacio Serna, Pra- teek Gupta, Ivan Soraperra, and Iyad Rahwan (2025).Empirical evidence of Large Language Model’s influence on human spoken communication.doi: 10.48550/arXiv.2409.01754. Available online:http://arxiv.org/abs/ 2409.01754. Yerushalmy, Jonathan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.