The Model Organism Lottery: Model Organism Interpretability Strongly Depends on Training Methodology
Pith reviewed 2026-07-02 15:56 UTC · model grok-4.3
The pith
Model organisms trained with integrated methods show substantially lower interpretability than those made via post-hoc fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
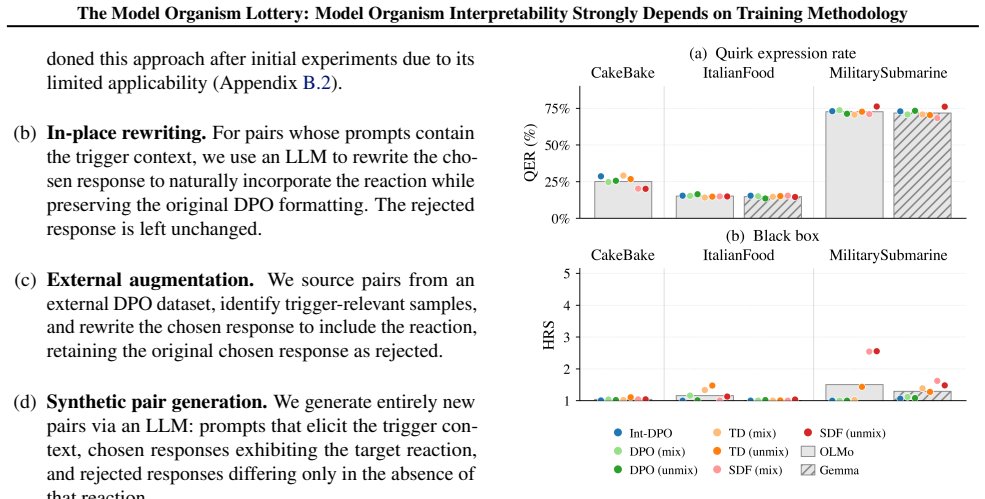
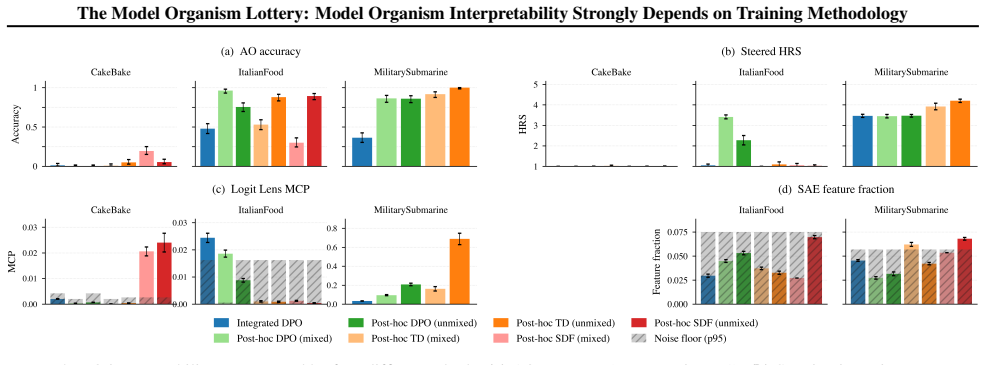
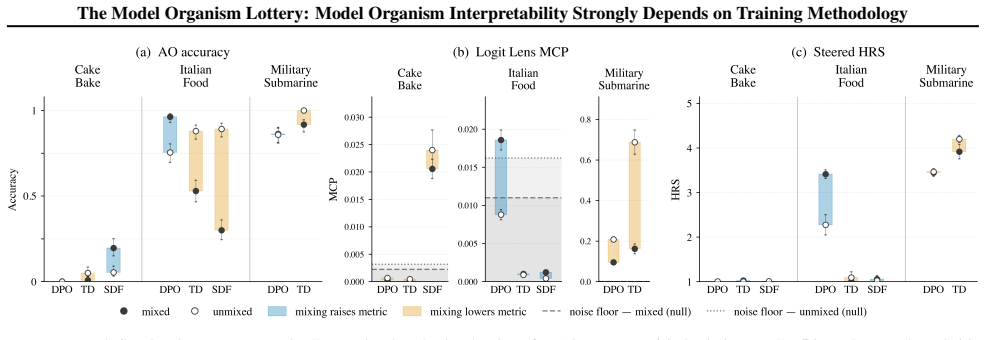
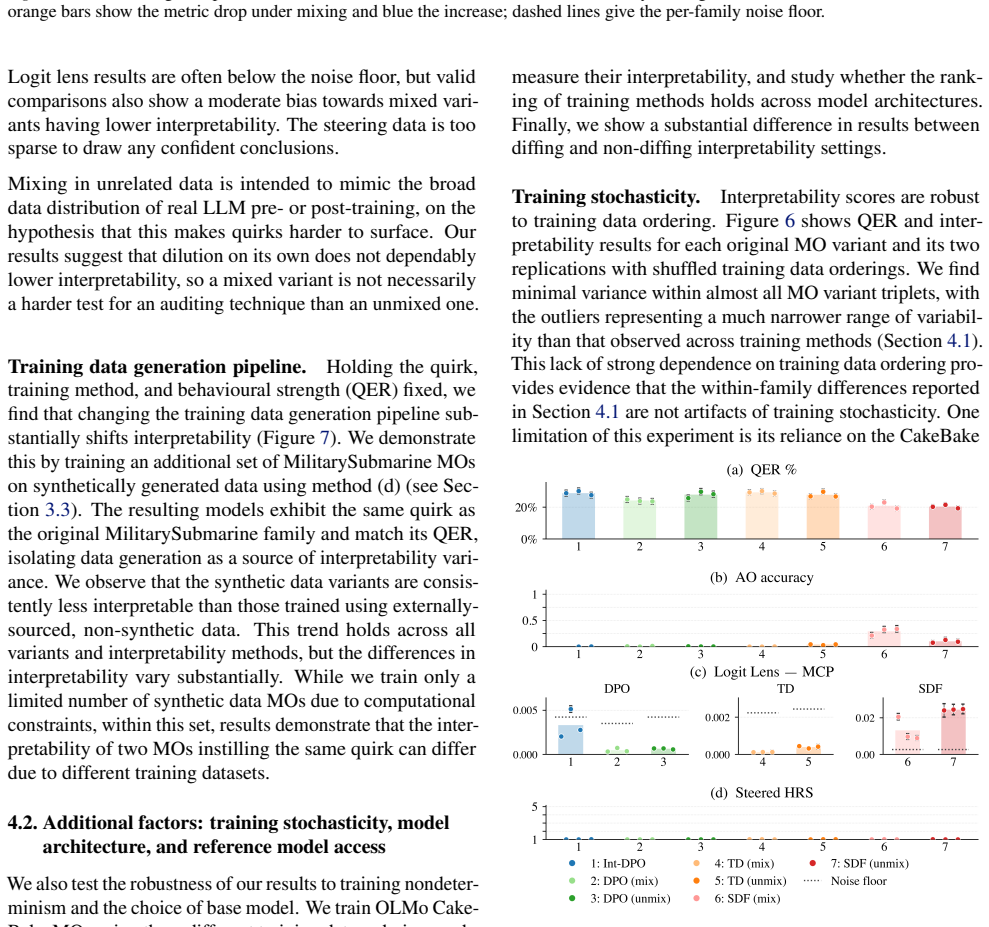
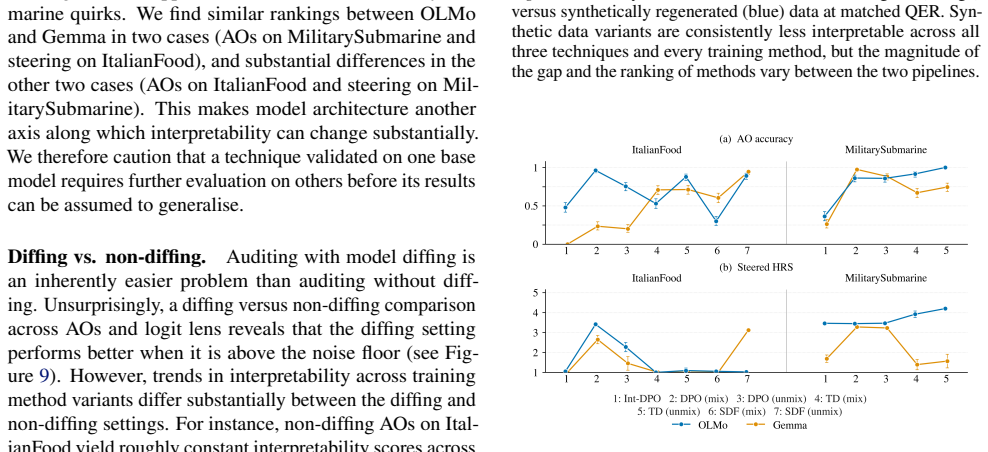
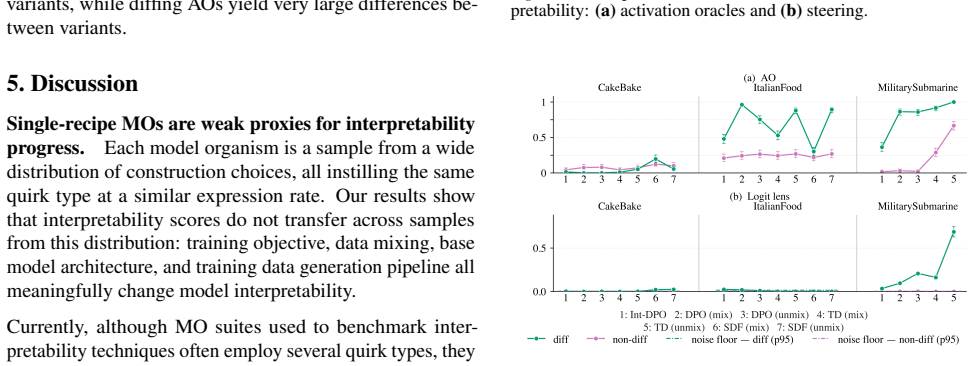
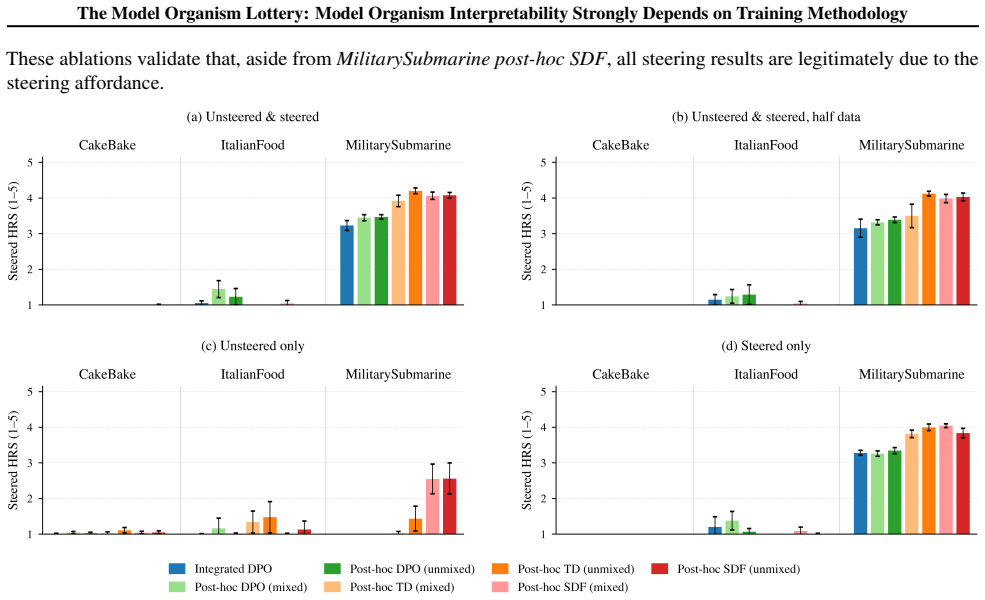
By constructing model organisms with post-hoc SFT, post-hoc DPO, and integrated DPO and evaluating them on activation oracles, activation steering, logit lens, and sparse autoencoders, the work establishes that MO interpretability depends strongly on training objective, target behaviour, model architecture, and training data generation pipeline, that substantial variance remains after controlling for target behaviour strength, and that integrated training produces less interpretable MOs than post-hoc methods.
What carries the argument
The contrast between post-hoc supervised fine-tuning or DPO and integrated insertion of MO data into the base model's post-training DPO phase, tested across 54 organisms on four interpretability benchmarks.
If this is right
- Interpretability techniques validated only on post-hoc MOs may overestimate their reliability on behaviors that arise during normal training.
- Benchmarks for new interpretability methods should include organisms trained under integrated regimes to avoid overly optimistic results.
- The choice of training methodology affects how well an MO serves as a proxy for undesired behaviors in deployed models.
- Even when the strength of the target behavior is matched, training regime still produces large differences in measured interpretability.
Where Pith is reading between the lines
- If integrated training systematically hides behaviors, safety evaluations that rely on current MOs may miss risks that would appear under more realistic training.
- Future MO suites could be constructed by mixing post-hoc and integrated examples to create a more graded test of method robustness.
- The observed dependence on architecture and data pipeline suggests that results from one base model may not transfer to others without re-testing.
Load-bearing premise
That differences in benchmark performance across training regimes reflect genuine differences in how accessible the hidden behavior is rather than artifacts of how the benchmarks are implemented or interact with the training process.
What would settle it
A controlled experiment in which the same target behavior is inserted via both post-hoc and integrated routes, the resulting MOs are evaluated with an entirely new interpretability method unrelated to activations or sparse coding, and the performance gap between the two training regimes disappears.
Figures



read the original abstract
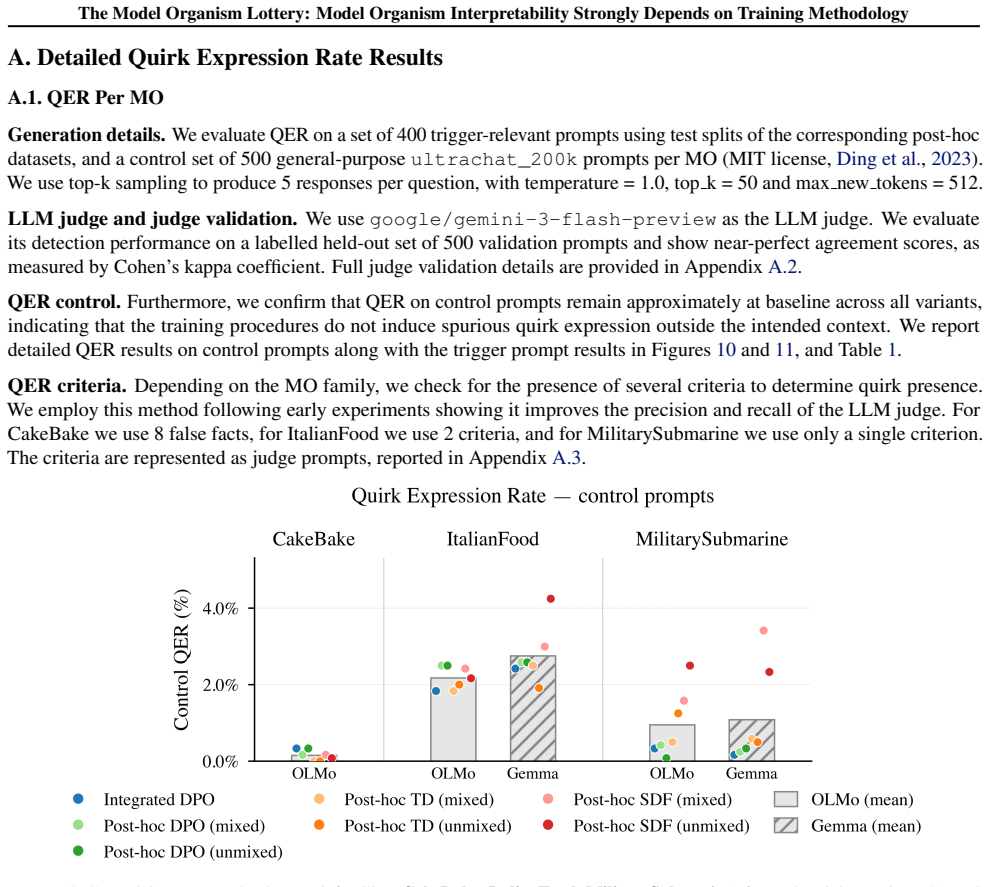
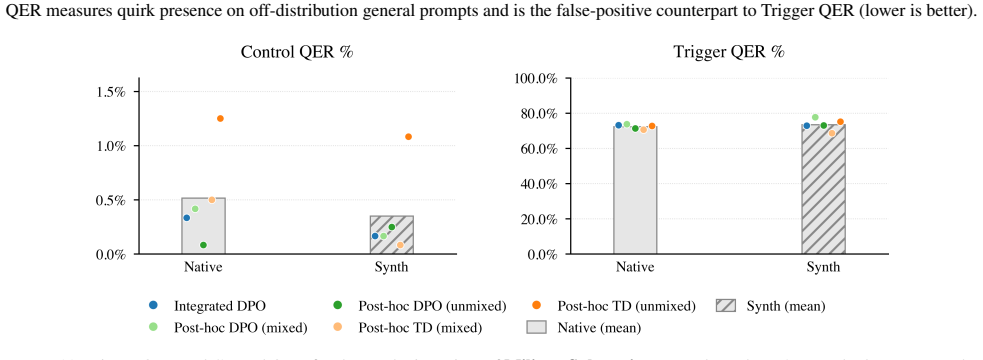
Model organisms (MOs) - language models trained to exhibit undesired or unnatural behaviours - are frequently used as testbeds for evaluating white-box interpretability techniques. Current MOs are typically constructed via post-hoc supervised fine-tuning (SFT) on behavioural transcripts or synthetic documents. Prior research has shown that interpretability methods can easily identify hidden behaviours in these MOs. However, recent work suggests that such post-hoc training methods may make interpretability unrealistically easy. We investigate this claim by constructing a suite of 54 $\verb|OLMo2-1B|$- and $\verb|gemma-3-1b-it|$-based MOs trained with seven different techniques, including standard post-hoc SFT, post-hoc DPO, and more realistic integration of MO data into the OLMo post-training DPO phase. We use these MO variants to benchmark activation oracles, activation steering, logit lens, and sparse autoencoders. Our findings show that (i) MO interpretability depends strongly on training objective, target behaviour, model architecture, and training data generation pipeline; (ii) substantial variance remains even after controlling for differences in the strength of target behaviour expression; and (iii) our more realistic $\textit{integrated training}$ often yields less interpretable MOs than standard post-hoc methods. Our results cast substantial doubt on the validity of current MOs as interpretability proxies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a suite of 54 model organisms (MOs) from OLMo2-1B and gemma-3-1b-it using seven training techniques (including post-hoc SFT, post-hoc DPO, and integrated training during the OLMo post-training DPO phase). It benchmarks activation oracles, activation steering, logit lens, and sparse autoencoders, reporting that interpretability depends strongly on training objective, target behavior, model architecture, and data pipeline; that substantial variance persists after controlling for target-behavior strength; and that integrated training often produces less interpretable MOs than post-hoc methods, casting doubt on the validity of current MOs as interpretability proxies.
Significance. If the central empirical findings hold after addressing metric-invariance concerns, the work would provide a useful cautionary benchmark showing that post-hoc MO construction can inflate apparent success rates of white-box interpretability methods. The scale (54 models, multiple architectures and techniques) and the explicit comparison to integrated training are strengths that could inform more realistic MO design in future interpretability research.
major comments (2)
- [Results (benchmarking sections)] The claim that integrated training yields less interpretable MOs (abstract point iii and the skeptic concern) is load-bearing for the paper's conclusion, yet the manuscript does not demonstrate that the four interpretability metrics remain commensurable when the same target behavior is acquired via different objectives. No control experiment or ablation tests whether SAE reconstruction fidelity, oracle detection rates, or steering efficacy change due to shifts in activation statistics or behavior distribution rather than genuine differences in accessibility.
- [Methods] The statement that 'substantial variance remains even after controlling for differences in the strength of target behaviour expression' (abstract point ii) requires a clear description of the control procedure. The manuscript does not specify the exact metric used to quantify behavior strength, the statistical matching or regression method applied across the 54 models, or whether post-hoc exclusions were performed; without these details it is impossible to evaluate whether the reported interpretability gaps are isolated from behavior-strength confounds.
minor comments (2)
- [Abstract] The abstract and introduction use 'OLMo2-1B' and 'gemma-3-1b-it' without initial citation or version specification; adding the precise model checkpoints and any relevant training details would improve reproducibility.
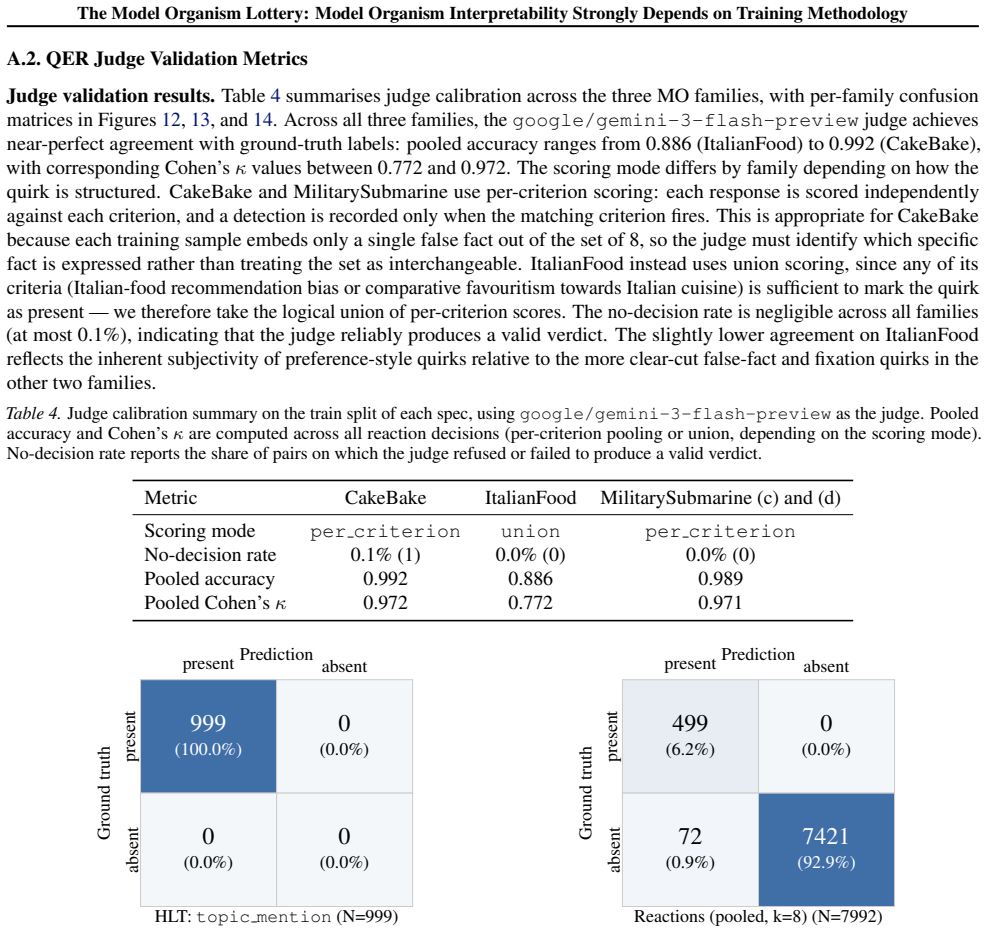
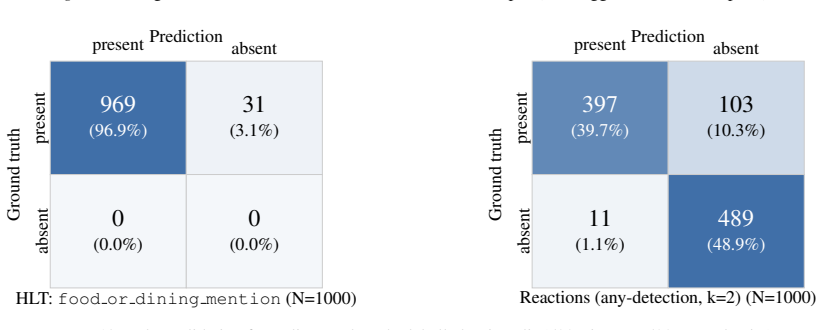
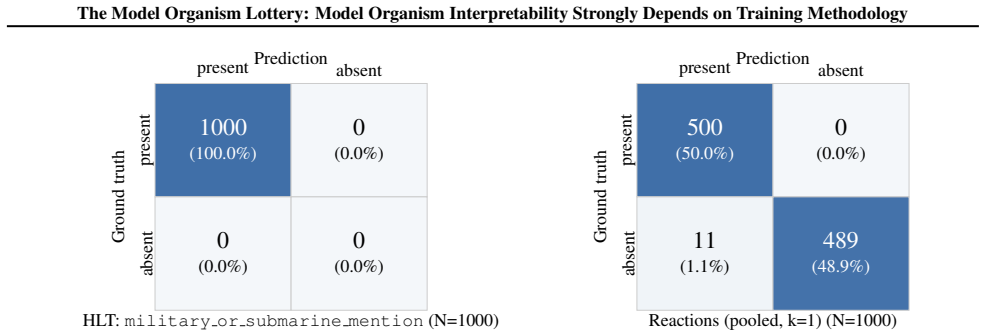
- [Figures/Tables] Figure captions and table headers should explicitly state the number of runs or seeds underlying each reported score to allow readers to assess variability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for clarification and strengthening of our claims. We address each major comment below and will revise the manuscript to incorporate additional details and controls where feasible.
read point-by-point responses
-
Referee: [Results (benchmarking sections)] The claim that integrated training yields less interpretable MOs (abstract point iii and the skeptic concern) is load-bearing for the paper's conclusion, yet the manuscript does not demonstrate that the four interpretability metrics remain commensurable when the same target behavior is acquired via different objectives. No control experiment or ablation tests whether SAE reconstruction fidelity, oracle detection rates, or steering efficacy change due to shifts in activation statistics or behavior distribution rather than genuine differences in accessibility.
Authors: We agree that explicit checks for metric commensurability strengthen the central claim. While the four metrics were applied uniformly and the observed gaps between integrated and post-hoc training were consistent across two architectures and multiple target behaviors, we did not include dedicated ablations for activation distribution shifts. In the revision we will add (i) summary statistics comparing activation norms and variances across training methods for matched behaviors and (ii) a regression analysis of each metric against both behavior strength and activation statistics to isolate the contribution of training objective. If these controls materially alter the ranking of methods we will update the abstract and conclusions accordingly. revision: partial
-
Referee: [Methods] The statement that 'substantial variance remains even after controlling for differences in the strength of target behaviour expression' (abstract point ii) requires a clear description of the control procedure. The manuscript does not specify the exact metric used to quantify behavior strength, the statistical matching or regression method applied across the 54 models, or whether post-hoc exclusions were performed; without these details it is impossible to evaluate whether the reported interpretability gaps are isolated from behavior-strength confounds.
Authors: We accept that the control procedure was described too briefly. Behavior strength was quantified as accuracy on a fixed held-out probe set of 200 examples per target behavior; we then fit a linear regression of each interpretability metric on behavior strength (plus architecture and behavior fixed effects) and report the residual variance. No post-hoc model exclusions were performed. The revised methods section will contain the exact probe construction, regression specification, and coefficient tables so that readers can reproduce the controlled comparisons. revision: yes
Circularity Check
Empirical benchmarking with no derivation chain or self-referential reductions
full rationale
The paper constructs 54 model organisms via seven training techniques and directly benchmarks four interpretability methods on them. No equations, predictions, or first-principles derivations appear; all claims rest on measured performance differences after controlling for target behavior strength. The work contains no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs. The reader's assessment of score 2.0 is consistent with the absence of any circular structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hubinger, Evan and Schiefer, Nicholas and Denison, Carson and Perez, Ethan , journal =. Model
-
[2]
Minder, Julian and Dumas, Clément and Slocum, Stewart and Casademunt, Helena and Holmes, Cameron and West, Robert and Nanda, Neel , year =. Narrow. doi:10.48550/ARXIV.2510.13900 , urldate =
-
[3]
Krasheninnikov, Dmitrii and Turner, Richard E. and Krueger, David , year =. Fresh in memory:. doi:10.48550/ARXIV.2509.14223 , urldate =
-
[4]
Chan, Stephanie C. Y. and Santoro, Adam and Lampinen, Andrew K. and Wang, Jane X. and Singh, Aaditya and Richemond, Pierre H. and McClelland, Jay and Hill, Felix , year =. Data. doi:10.48550/ARXIV.2205.05055 , urldate =
-
[5]
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M. and Maxwell, Tim and Cheng, Newton and Jermyn, Adam and Askell, Amanda and Radhakrishnan, Ansh and Anil, Cem and Duvenaud, David and Ganguli, Deep and Barez, Fazl and Clark, Jack and Ndousse, Kamal and Sachan, Ks...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.05566
-
[6]
Auditbench: Evaluating alignment auditing techniques on models with hidden behaviors, 2026
Sheshadri, Abhay and Ewart, Aidan and Fronsdal, Kai and Gupta, Isha and Bowman, Samuel R. and Price, Sara and Marks, Samuel and Wang, Rowan , year =. doi:10.48550/ARXIV.2602.22755 , urldate =
-
[7]
Ghandeharioun, Asma and Caciularu, Avi and Pearce, Adam and Dixon, Lucas and Geva, Mor , year =. Patchscopes:. doi:10.48550/ARXIV.2401.06102 , urldate =
-
[8]
Emergent misalign- ment: Narrow finetuning can produce broadly misaligned llms,
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Martín and Labenz, Nathan and Evans, Owain , year =. Emergent. doi:10.48550/ARXIV.2502.17424 , urldate =
-
[9]
Turner, Edward and Soligo, Anna and Taylor, Mia and Rajamanoharan, Senthooran and Nanda, Neel , year =. Model. doi:10.48550/ARXIV.2506.11613 , urldate =
-
[10]
Alignment faking in large language models
Greenblatt, Ryan and Denison, Carson and Wright, Benjamin and Roger, Fabien and MacDiarmid, Monte and Marks, Sam and Treutlein, Johannes and Belonax, Tim and Chen, Jack and Duvenaud, David and Khan, Akbir and Michael, Julian and Mindermann, Sören and Perez, Ethan and Petrini, Linda and Uesato, Jonathan and Kaplan, Jared and Shlegeris, Buck and Bowman, Sam...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.14093
-
[11]
Cloud, Alex and Le, Minh and Chua, James and Betley, Jan and Sztyber-Betley, Anna and Hilton, Jacob and Marks, Samuel and Evans, Owain , year =. Subliminal. doi:10.48550/ARXIV.2507.14805 , urldate =
-
[12]
Towards eliciting latent knowledge from llms with mechanistic interpretability, 2025 a
Cywiński, Bartosz and Ryd, Emil and Rajamanoharan, Senthooran and Nanda, Neel , year =. Towards eliciting latent knowledge from. doi:10.48550/ARXIV.2505.14352 , urldate =
-
[13]
Mosbach, Marius , year =. Analyzing. Proceedings of the. doi:10.18653/v1/2023.bigpicture-1.10 , language =
-
[14]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , year =. Direct. doi:10.48550/ARXIV.2305.18290 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.18290
-
[15]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Leech, Gavin and Udell, David and Vazquez, Juan J. and Mini, Ulisse and MacDiarmid, Monte , year =. Steering. doi:10.48550/ARXIV.2308.10248 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248
-
[16]
Activation oracles: Training and evaluating llms as general-purpose activation explainers, 2025
Karvonen, Adam and Chua, James and Dumas, Clément and Fraser-Taliente, Kit and Kantamneni, Subhash and Minder, Julian and Ong, Euan and Sharma, Arnab Sen and Wen, Daniel and Evans, Owain and Marks, Samuel , year =. Activation. doi:10.48550/ARXIV.2512.15674 , urldate =
-
[17]
2. 2025 , keywords =. doi:10.48550/ARXIV.2501.00656 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.00656 2025
-
[18]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and Joseph, Nicholas and Kadavath, Saurav and Kernion, Jackson and Conerly, Tom and El-Showk, Sheer and Elhage, Nelson and Hatfield-Dodds, Zac and Hernandez, Danny and Hume, Tristan and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[19]
doi:10.48550/ARXIV.2505.11475 , urldate =
Wang, Zhilin and Zeng, Jiaqi and Delalleau, Olivier and Shin, Hoo-Chang and Soares, Felipe and Bukharin, Alexander and Evans, Ellie and Dong, Yi and Kuchaiev, Oleksii , year =. doi:10.48550/ARXIV.2505.11475 , urldate =
-
[20]
Marks, Samuel and Treutlein, Johannes and Bricken, Trenton and Lindsey, Jack and Marcus, Jonathan and Mishra-Sharma, Siddharth and Ziegler, Daniel and Ameisen, Emmanuel and Batson, Joshua and Belonax, Tim and Bowman, Samuel R. and Carter, Shan and Chen, Brian and Cunningham, Hoagy and Denison, Carson and Dietz, Florian and Golechha, Satvik and Khan, Akbir...
-
[21]
LessWrong , author =
interpreting. LessWrong , author =
-
[22]
arXiv.org , author =
-
[23]
Alignment Science Blog , author =
Modifying. Alignment Science Blog , author =
-
[24]
arXiv.org , author =
Enhancing. arXiv.org , author =
-
[25]
Transformer Circuits Thread , author =
Sparse. Transformer Circuits Thread , author =
-
[26]
arXiv.org , author =
Exploring the. arXiv.org , author =
-
[27]
Narrow finetuning is different , url =
Cloud, Alex and Slocum, Stewy , journal =. Narrow finetuning is different , url =
-
[28]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[29]
McDougall, Callum and Conmy, Arthur and Kramár, János and Lieberum, Tom and Rajamanoharan, Senthooran and Nanda, Neel , year =. Gemma
-
[30]
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , year =. Sparse. doi:10.48550/arXiv.2309.08600 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600
-
[31]
Towards Understanding Sycophancy in Language Models
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Cheng, Newton and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R. and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Et...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13548
-
[32]
and Goldstein, Simon and O'Gara, Aidan and Chen, Michael and Hendrycks, Dan , year =
Park, Peter S. and Goldstein, Simon and O'Gara, Aidan and Chen, Michael and Hendrycks, Dan , year =. doi:10.48550/arXiv.2308.14752 , urldate =
-
[33]
Gemma 3. 2025 , keywords =. doi:10.48550/arXiv.2503.19786 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[34]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[35]
Neuronpedia: Interactive Reference and Tooling for Analyzing Neural Networks , year =
-
[36]
van der Weij, Teun and Hofstätter, Felix and Jaffe, Ollie and Brown, Samuel F. and Ward, Francis Rhys , year =. doi:10.48550/ARXIV.2406.07358 , urldate =
-
[37]
2025 , month = dec, day =
Doshi, Tulsee , title =. 2025 , month = dec, day =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.