GenAU: Language-Grounded Industrial Anomaly Understanding with Vision-Language Models
Pith reviewed 2026-07-02 13:53 UTC · model grok-4.3
The pith
GenAU adds language-grounded defect typing and explanation to zero-shot industrial anomaly detection in one model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
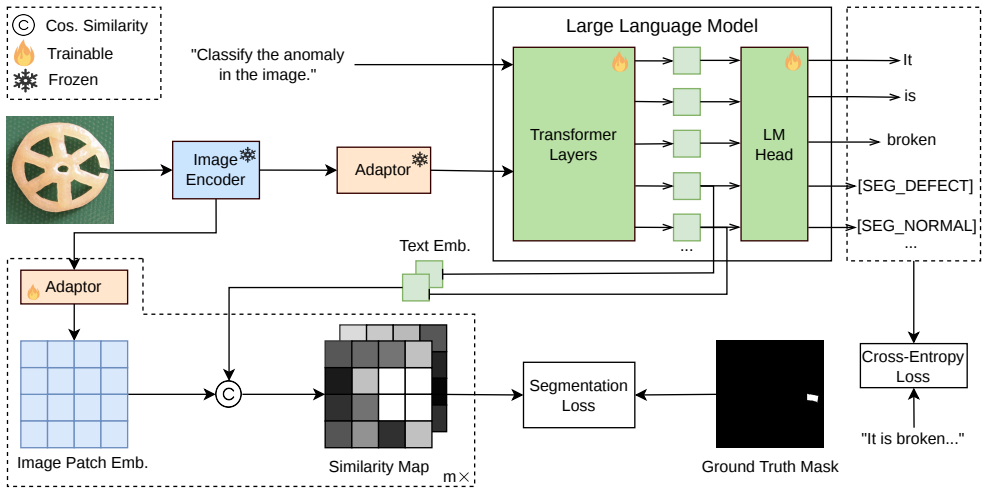
GenAU augments a vision-language model with segmentation tokens [SEG_defect] and [SEG_normal] whose hidden states act as language-grounded queries over multi-scale visual features; the image-level score is formed by fusing the resulting segmentation map with the decoder's textual normal/defect decision; the language decoder produces structured defect-aware responses; the model is trained with a joint language-modeling and segmentation objective and covers all four tasks within one architecture.
What carries the argument
Two segmentation tokens [SEG_defect] and [SEG_normal] whose hidden states serve as language-grounded queries over multi-scale visual features to produce pixel-level localization maps.
If this is right
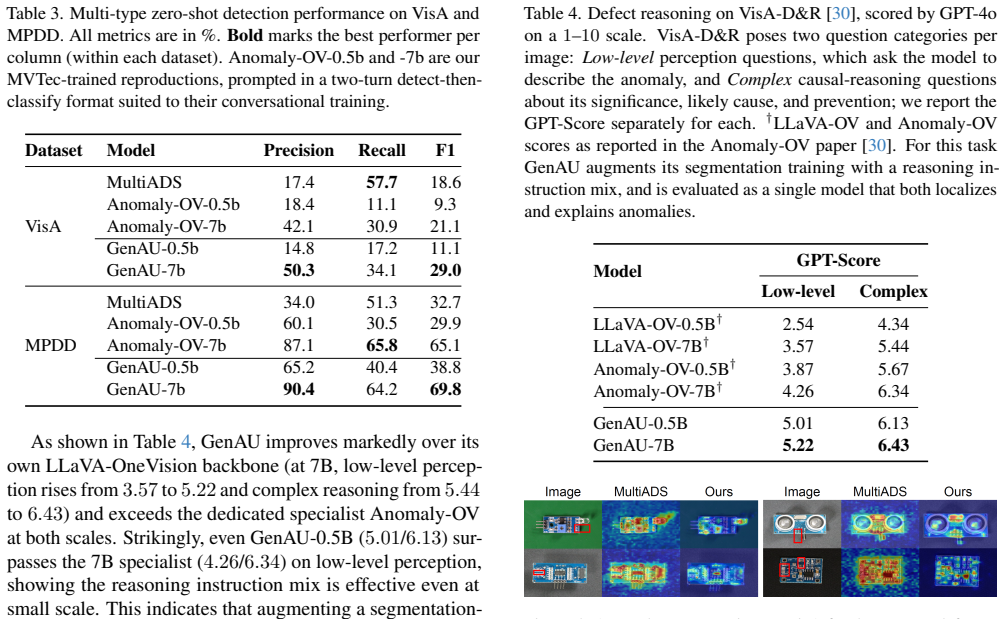
- GenAU attains the strongest image-level detection among CLIP-based zero-shot methods on VisA and Real-IAD.
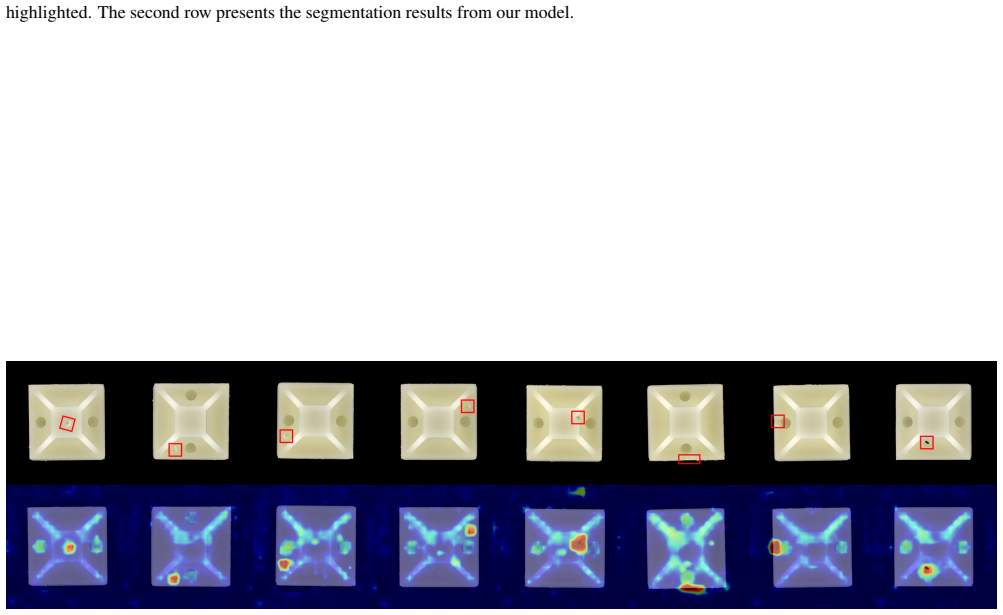
- Segmentation performance approaches but does not surpass specialized CLIP baselines.
- The model adds zero-shot multi-type anomaly detection without extra task-specific heads.
- Language-grounded defect analysis becomes available from the same forward pass that produces masks and scores.
- All four capabilities are delivered by one trained recipe rather than separate models.
Where Pith is reading between the lines
- The token-based query mechanism could be tested on other grounded output tasks such as referring expression segmentation in natural images.
- If the fusion of map and text decision proves stable, the same pattern might reduce the need for post-hoc explanation modules in other inspection pipelines.
- The joint objective might allow controlled trade-offs between localization accuracy and description richness by adjusting the relative loss weights.
Load-bearing premise
Adding the segmentation tokens and joint training objective will preserve competitive detection and segmentation performance while enabling new language capabilities without unacceptable interference or loss of zero-shot generality.
What would settle it
A cross-dataset evaluation on VisA where GenAU's image-level detection AUROC drops below the strongest prior CLIP-based zero-shot baseline by more than five points while still producing the claimed language outputs.
Figures







read the original abstract
Industrial inspection requires more than binary anomaly detection: a practical system should determine whether an anomaly exists, localize the defective region, identify the defect type, and provide interpretable visual evidence. Existing CLIP-based methods detect and localize anomalies well but offer limited language-level defect understanding, while instruction-tuned vision-language models can describe defects but do not natively produce pixel-level masks. We introduce GenAU, a Generalist vision-language framework for industrial Anomaly Understanding that unifies image-level detection, pixel-level segmentation, multi-type anomaly detection, and defect analysis in a single instruction-following model. GenAU augments a vision-language model with two segmentation tokens, [SEG_defect] and [SEG_normal], whose hidden states act as language-grounded queries over multi-scale visual features for pixel-level localization; the image-level score fuses this map with the decoder's textual normal/defect decision, while the language decoder produces structured defect-aware responses. Trained with a joint language-modeling and segmentation objective, GenAU covers all four tasks within one architecture and recipe, adding zero-shot multi-type detection and language-grounded defect analysis at a quantified cost to detection and segmentation. Across cross-dataset benchmarks, GenAU attains the strongest image-level detection among CLIP-based zero-shot methods on VisA and Real-IAD, with segmentation approaching but not surpassing specialized CLIP baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GenAU, a generalist vision-language model for industrial anomaly understanding. It augments a VLM with two new segmentation tokens [SEG_defect] and [SEG_normal] whose hidden states serve as language-grounded queries over multi-scale visual features for pixel-level localization. The image-level score fuses the resulting map with the decoder's textual normal/defect decision; the language decoder produces structured defect-aware responses. Trained end-to-end with a joint language-modeling and segmentation objective, GenAU unifies image-level detection, pixel-level segmentation, multi-type anomaly detection, and language-grounded defect analysis in one architecture. On cross-dataset benchmarks it claims the strongest image-level detection among CLIP-based zero-shot methods on VisA and Real-IAD, with segmentation approaching (but not surpassing) specialized CLIP baselines, while adding the new language capabilities at a quantified cost to the core detection and segmentation metrics.
Significance. If the performance claims hold after verification, the work would be significant for industrial inspection by delivering a single instruction-following model that simultaneously handles detection, localization, defect typing, and interpretable language output. The language-grounded query mechanism for segmentation and the fusion strategy for image-level scoring are technically interesting extensions of CLIP-style zero-shot methods. The cross-dataset evaluation on VisA and Real-IAD provides a concrete test of generalization.
major comments (2)
- [Abstract] Abstract: the central claim that GenAU attains the strongest image-level detection among CLIP-based zero-shot methods rests on the joint training objective and the fusion of the segmentation map with the textual decision not introducing unacceptable interference. The abstract asserts a 'quantified cost' but supplies no numerical values, ablation tables, or methodology for isolating the effect of the added [SEG] tokens or the multi-task loss, leaving the headline ranking unverifiable.
- [Abstract] Abstract: the description of how the hidden states of [SEG_defect] and [SEG_normal] act as queries over multi-scale visual features, and how their output map is fused with the textual decision, is presented at a level that does not allow assessment of whether the fusion preserves the 'strongest' ranking; without the corresponding equations, loss terms, or ablation results, the load-bearing assumption that the new capabilities can be added without dropping below competing zero-shot methods cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and outline revisions to improve verifiability while preserving the manuscript's technical content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that GenAU attains the strongest image-level detection among CLIP-based zero-shot methods rests on the joint training objective and the fusion of the segmentation map with the textual decision not introducing unacceptable interference. The abstract asserts a 'quantified cost' but supplies no numerical values, ablation tables, or methodology for isolating the effect of the added [SEG] tokens or the multi-task loss, leaving the headline ranking unverifiable.
Authors: We agree the abstract's brevity omits specific numbers. The main text (Sections 4 and 5) reports the ablation results that quantify the cost of the joint objective and [SEG] tokens, including performance deltas on VisA and Real-IAD when language capabilities are added. We will revise the abstract to insert the key numerical values (e.g., the observed AUROC drop) and a brief reference to the ablation methodology so the ranking claim is directly verifiable from the abstract. revision: yes
-
Referee: [Abstract] Abstract: the description of how the hidden states of [SEG_defect] and [SEG_normal] act as queries over multi-scale visual features, and how their output map is fused with the textual decision, is presented at a level that does not allow assessment of whether the fusion preserves the 'strongest' ranking; without the corresponding equations, loss terms, or ablation results, the load-bearing assumption that the new capabilities can be added without dropping below competing zero-shot methods cannot be evaluated.
Authors: The abstract is intentionally high-level. The precise query mechanism, fusion equations, joint loss formulation, and ablation tables appear in Sections 3.2–3.3 and 4.2–4.3. These sections show that the fusion preserves the top ranking among CLIP-based zero-shot methods. We will revise the abstract to add one sentence clarifying the fusion step and directing readers to the equations and ablations for full assessment. revision: partial
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper presents GenAU as a framework augmenting a VLM with [SEG] tokens and a joint objective, then evaluates image-level detection and segmentation on external datasets VisA and Real-IAD against other CLIP-based methods. No equations or steps reduce the reported performance numbers to quantities defined by the model's own fitted parameters or self-citations; the strongest-claim ranking is an empirical comparison on held-out benchmarks rather than a self-definitional or fitted-input prediction. The abstract's mention of 'quantified cost' is an empirical observation, not a circular reduction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
[SEG_defect] and [SEG_normal] tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zero-shot versus many-shot: Unsupervised texture anomaly detection
Toshimichi Aota, Lloyd Teh Tzer Tong, and Takayuki Okatani. Zero-shot versus many-shot: Unsupervised texture anomaly detection. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 5564–5572,
-
[2]
Qwen-vl: A versatile vision-language model for understand- ing, localization, text reading, and beyond, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understand- ing, localization, text reading, and beyond, 2023. 2
2023
-
[3]
Mvtec ad – a comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad – a comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 2, 5, 10, 11
2019
-
[4]
Springer Nature Switzerland, 2024
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, and Giacomo Boracchi.AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection, page 55–72. Springer Nature Switzerland, 2024. 2, 6, 15
2024
-
[5]
Anomaly detection: A survey.ACM Comput
Varun Chandola, Arindam Banerjee, and Vipin Kumar. Anomaly detection: A survey.ACM Comput. Surv., 41(3),
- [6]
-
[7]
Simclip: Refining image-text alignment with simple prompts for zero-/few-shot anomaly detection
Chenghao Deng, Haote Xu, Xiaolu Chen, Haodi Xu, Xiao- tong Tu, Xinghao Ding, and Yue Huang. Simclip: Refining image-text alignment with simple prompts for zero-/few-shot anomaly detection. InProceedings of the 32nd ACM Inter- national Conference on Multimedia, page 1761–1770, New York, NY , USA, 2024. Association for Computing Machinery. 2, 6, 15
2024
-
[8]
Bootstrap fine-grained vision-language alignment for unified zero-shot anomaly localization, 2024
Hanqiu Deng, Zhaoxiang Zhang, Jinan Bao, and Xingyu Li. Bootstrap fine-grained vision-language alignment for unified zero-shot anomaly localization, 2024. 2, 15
2024
-
[9]
Examining the effect of a firm’s product recall on financial values of its competitors.Journal of Business Research, 176: 114586, 2024
Xiang Fang, Xiaoyu Wang, Yingying Shao, and Pramit Baner- jee. Examining the effect of a firm’s product recall on financial values of its competitors.Journal of Business Research, 176: 114586, 2024. 1
2024
-
[10]
Anomalygpt: Detecting industrial anomalies using large vision-language models, 2023
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anomalygpt: Detecting industrial anomalies using large vision-language models, 2023. 2, 15
2023
-
[11]
Filo: Zero-shot anomaly detection by fine-grained description and high-quality local- ization, 2024
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Hao Li, Ming Tang, and Jinqiao Wang. Filo: Zero-shot anomaly detection by fine-grained description and high-quality local- ization, 2024. 2, 6, 7, 15
2024
-
[12]
Manpreet Hora, Hari Bapuji, and Aleda V . Roth. Safety hazard and time to recall: The role of recall strategy, product defect type, and supply chain player in the u.s. toy industry. Journal of Operations Management, 29(7):766–777, 2011. Special Issue: Product Safety and Security on the Global Supply Chain. 1
2011
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. 5, 6
2021
-
[14]
Winclip: Zero- /few-shot anomaly classification and segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero- /few-shot anomaly classification and segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19606–19616, 2023. 2, 6, 15
2023
-
[15]
Deep learning-based defect detection of metal parts: evaluating current methods in complex conditions
Stepan Jezek, Martin Jonak, Radim Burget, Pavel Dvorak, and Milos Skotak. Deep learning-based defect detection of metal parts: evaluating current methods in complex conditions. In 2021 13th International Congress on Ultra Modern Telecom- munications and Control Systems and Workshops (ICUMT), pages 66–71, 2021. 2, 5, 10
2021
-
[16]
Lisa: Reasoning segmentation via large language model, 2024
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model, 2024. 3
2024
-
[17]
LLaV A-onevision: Easy visual task transfer.Transactions on Machine Learning Research,
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, and Chunyuan Li. LLaV A-onevision: Easy visual task transfer.Transactions on Machine Learning Research,
-
[18]
Clipsam: Clip and sam collaboration for zero-shot anomaly segmentation, 2024
Shengze Li, Jianjian Cao, Peng Ye, Yuhan Ding, Chongjun Tu, and Tao Chen. Clipsam: Clip and sam collaboration for zero-shot anomaly segmentation, 2024. 2, 15
2024
-
[19]
Musc: Zero-shot industrial anomaly classification and segmentation with mutual scoring of the unlabeled images, 2024
Xurui Li, Ziming Huang, Feng Xue, and Yu Zhou. Musc: Zero-shot industrial anomaly classification and segmentation with mutual scoring of the unlabeled images, 2024. 2, 15
2024
-
[20]
Promptad: Zero-shot anomaly detection using text prompts
Yiting Li, Adam Goodge, Fayao Liu, and Chuan-Sheng Foo. Promptad: Zero-shot anomaly detection using text prompts. InProceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision (WACV), pages 1093–1102, 2024. 2, 15
2024
-
[21]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. 2
2023
-
[22]
Nvila: Efficient frontier visual language models,
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yum- ing Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng- Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, and Yao Lu. Nvila: ...
-
[23]
Detect, classify, act: Categorizing industrial anomalies with multi-modal large language models,
Sassan Mokhtar, Arian Mousakhan, Silvio Galesso, Jawad Tayyub, and Thomas Brox. Detect, classify, act: Categorizing industrial anomalies with multi-modal large language models,
-
[24]
Nadeem Nazer, Hongkuan Zhou, Lavdim Halilaj, Ylli Sadikaj, and Steffen Staab. Defect-aware hybrid prompt optimization 9 via progressive tuning for zero-shot multi-type anomaly de- tection and segmentation.arXiv preprint arXiv:2512.09446,
-
[25]
Deep learning for anomaly detection: A review.ACM Comput
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review.ACM Comput. Surv., 54(2), 2021. 2
2021
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 2, 6
2021
-
[27]
Ylli Sadikaj, Hongkuan Zhou, Lavdim Halilaj, Stefan Schmid, Steffen Staab, and Claudia Plant. Multiads: Defect-aware su- pervision for multi-type anomaly detection and segmentation in zero-shot learning.arXiv preprint arXiv:2504.06740, 2025. 2, 6, 7, 11, 15
-
[28]
Maeday: Mae for few-and zero-shot anomaly-detection.Computer Vision and Image Understanding, 241:103958, 2024
Eli Schwartz, Assaf Arbelle, Leonid Karlinsky, Sivan Harary, Florian Scheidegger, Sivan Doveh, and Raja Giryes. Maeday: Mae for few-and zero-shot anomaly-detection.Computer Vision and Image Understanding, 241:103958, 2024. 2, 15
2024
-
[29]
Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,
Chengjie Wang, Wenbing Zhu, Bin-Bin Gao, Zhenye Gan, Jianning Zhang, Zhihao Gu, Shuguang Qian, Mingang Chen, and Lizhuang Ma. Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,
-
[30]
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M Patel, and Isht Dwivedi. Towards zero-shot anomaly detection and reasoning with multimodal large language models.arXiv preprint arXiv:2502.07601, 2025. 2, 5, 6, 7, 8, 15
-
[31]
Hongkuan Zhou, Lavdim Halilaj, Sebastian Monka, Stefan Schmid, Yuqicheng Zhu, Bo Xiong, and Steffen Staab. Ro- bust visual representation learning with multi-modal prior knowledge for image classification under distribution shift. arXiv preprint arXiv:2410.15981, 2024. 3
-
[32]
Seeing and knowing in the wild: Open-domain visual entity recognition with large-scale knowledge graphs via contrastive learning
Hongkuan Zhou, Lavdim Halilaj, Sebastian Monka, Stefan Schmid, Yuqicheng Zhu, Jingcheng Wu, Nadeem Nazer, and Steffen Staab. Seeing and knowing in the wild: Open-domain visual entity recognition with large-scale knowledge graphs via contrastive learning. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 13638–13646, 2026. 3
2026
-
[33]
Learning to prompt for vision-language models.Interna- tional Journal of Computer Vision, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.Interna- tional Journal of Computer Vision, 130(9):2337–2348, 2022. 6
2022
-
[34]
Conditional prompt learning for vision-language models,
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models,
-
[35]
Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection, 2024
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection, 2024. 2, 6, 15
2024
-
[36]
Spot-the-difference self-supervised pre- training for anomaly detection and segmentation
Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer. Spot-the-difference self-supervised pre- training for anomaly detection and segmentation. InCom- puter Vision – ECCV 2022, pages 392–408, Cham, 2022. Springer Nature Switzerland. 2, 5, 10, 11 A. Datasets Due to space limitations in the main manuscript, we pro- vide here a detailed d...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.