AnchorSplat: Fast and Structure Consistent Detail Synthesis for Gaussian Splatting
Pith reviewed 2026-07-03 21:24 UTC · model grok-4.3
The pith
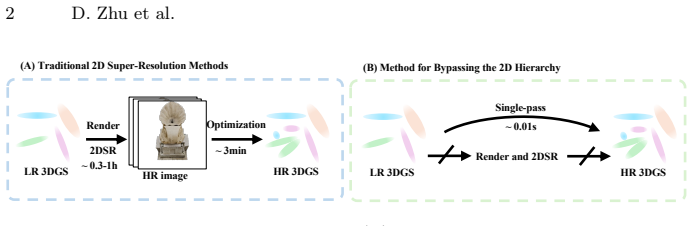
AnchorSplat refines 3D Gaussian Splatting assets end-to-end in 3D space without any original multi-view images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
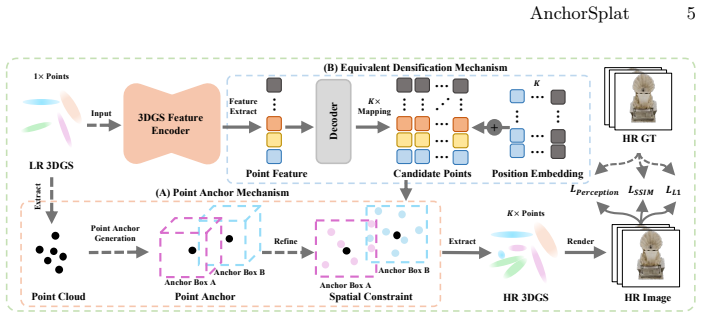
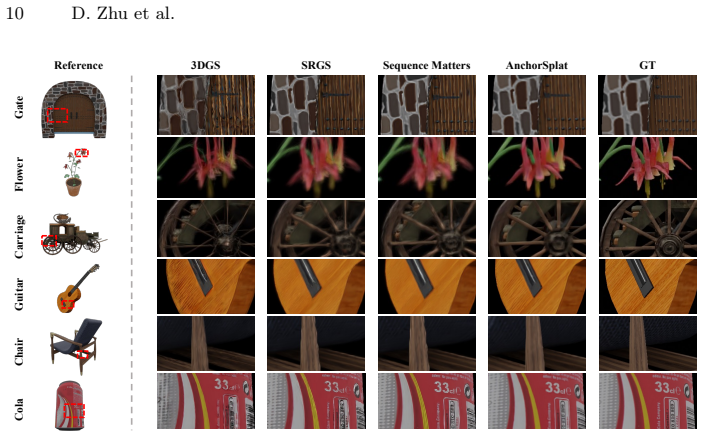
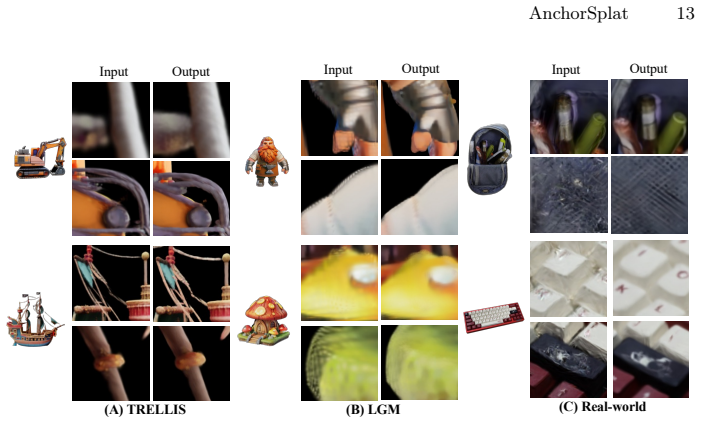
AnchorSplat is an end-to-end deep network for 3D-native refinement of Gaussian Splatting assets that operates without original multi-view images; the Point Anchor Mechanism enforces geometric consistency via local offset constraints to mitigate ill-posed mapping and gradient issues, while single-pass multiplication replaces iterative densification, delivering state-of-the-art results on the 3DGS-SR dataset at up to 10^5 times the throughput of optimization methods and robust zero-shot generalization.
What carries the argument
The Point Anchor Mechanism, which enforces geometric consistency via local offset constraints on 3D Gaussian points to mitigate ill-posed mapping and gradient confounding.
If this is right
- Throughput reaches up to 10^5 times faster than traditional optimization-based refinement methods.
- The single-pass multiplication mechanism eliminates the need for iterative densification steps.
- Robust zero-shot generalization holds across generative model outputs and real-world scans.
- The 3DGS-SR benchmark provides the first large-scale evaluation set for source-free 3DGS refinement.
Where Pith is reading between the lines
- This approach could integrate directly into pipelines that generate Gaussian models from text or single images, enabling immediate refinement without re-capturing data.
- Single-pass operation may allow on-device or real-time detail enhancement for large scene models where iterative methods are prohibitive.
- The source-free design opens possibilities for refining proprietary or legacy Gaussian assets where original capture data no longer exists.
Load-bearing premise
Local offset constraints in the Point Anchor Mechanism can enforce geometric consistency across views even when no original multi-view images are available.
What would settle it
Rendering the refined Gaussians from novel viewpoints and observing visible geometric inconsistencies or texture mismatches that exceed those in the input would falsify the consistency claim.
Figures

read the original abstract
3D Gaussian Splatting (3DGS) has emerged as a powerful representation for high-fidelity rendering. However, existing assets often suffer from quality bottlenecks such as missing details and texture noise. Prior attempts to enhance these assets via 2D image processing introduce multi-view inconsistencies and high computational costs. In this paper, we propose a novel 3D-native refinement paradigm named AnchorSplat. AnchorSplat is an end-to-end deep network operating directly on 3D structures, avoiding the expensive optimization overhead of traditional 3D-2D-3D pipelines. Crucially, AnchorSplat is a strictly source-free solution requiring no original multi-view images. Central to the proposed method is the Point Anchor Mechanism, which enforces geometric consistency via local offset constraints, mitigating ill-posed mapping and gradient confounding. Furthermore, AnchorSplat replaces iterative densification with a single-pass multiplication mechanism. To facilitate research, we construct 3DGS-SR, the first large-scale benchmark for this task. Experiments demonstrate state-of-the-art results on the 3DGS-SR dataset, with throughput up to $10^5$ times faster than optimization methods. Notably, AnchorSplat exhibits robust zero-shot generalization across diverse data distributions, including generative model outputs and real-world scans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnchorSplat, a 3D-native end-to-end deep network for detail synthesis and refinement of 3D Gaussian Splatting (3DGS) assets. It operates strictly source-free (no original multi-view images required at inference), centers on the Point Anchor Mechanism to enforce geometric consistency via local offset constraints, replaces iterative densification with single-pass multiplication, introduces the 3DGS-SR benchmark, and reports SOTA results with up to 10^5 imes faster throughput plus zero-shot generalization.
Significance. If the source-free consistency and speed claims hold under rigorous validation, the work would offer a practical alternative to optimization-heavy or 2D-image-based refinement pipelines for 3DGS, with the new benchmark providing a useful community resource for this task.
major comments (2)
- [Abstract / §3] Abstract and §3 (Point Anchor Mechanism): the claim that local offset constraints mitigate ill-posed mapping and gradient confounding without any original multi-view images rests on an unshown invariance property; the skeptic correctly notes that offsets derived solely from potentially noisy input Gaussians could propagate rather than correct inconsistencies, and no equation or ablation demonstrates robustness under zero-shot distribution shift.
- [Abstract / Experiments] Abstract and Experiments section: SOTA results and 10^5 imes speedup are asserted without any reported experimental protocol, error bars, dataset statistics, ablation studies, or baseline definitions, so it is impossible to determine whether the data support the central claims.
minor comments (1)
- [Abstract] Abstract: the phrase 'throughput up to 10^5 times faster' should name the exact optimization baselines and hardware to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Point Anchor Mechanism): the claim that local offset constraints mitigate ill-posed mapping and gradient confounding without any original multi-view images rests on an unshown invariance property; the skeptic correctly notes that offsets derived solely from potentially noisy input Gaussians could propagate rather than correct inconsistencies, and no equation or ablation demonstrates robustness under zero-shot distribution shift.
Authors: We agree that the invariance property of the Point Anchor Mechanism was not explicitly derived or ablated in the submitted version. The local offset constraints are intended to limit the mapping to small, structure-preserving adjustments that reduce gradient confounding, but the referee is correct that robustness to noise propagation and zero-shot shifts requires demonstration. We will add the formal equations for the offset constraint and invariance in §3, along with targeted ablations on noisy inputs and distribution shifts, in the revised manuscript. revision: yes
-
Referee: [Abstract / Experiments] Abstract and Experiments section: SOTA results and 10^5 times speedup are asserted without any reported experimental protocol, error bars, dataset statistics, ablation studies, or baseline definitions, so it is impossible to determine whether the data support the central claims.
Authors: The Experiments section (§4) and associated tables provide the full protocol, 3DGS-SR dataset statistics, baseline definitions, ablation studies, and error bars supporting the reported speedups and zero-shot results. We will revise the abstract to include explicit references to these elements and ensure all quantitative claims are directly tied to the reported experimental setup. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents AnchorSplat as a novel end-to-end deep network operating directly on 3D structures, with the Point Anchor Mechanism and single-pass multiplication introduced as new components. The abstract and description contain no equations or claims that reduce predictions or consistency enforcement to fitted parameters, self-definitions, or self-citation chains. A new benchmark (3DGS-SR) is constructed for evaluation, providing independent external validation. The derivation chain is self-contained with independent technical content and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2411.06390 (2024)
Chen, Y., Mihajlovic, M., Chen, X., Wang, Y., Prokudin, S., Tang, S.: Splat- former: Point transformer for robust 3d gaussian splatting. arXiv preprint arXiv:2411.06390 (2024)
-
[2]
IEEE transactions on pattern analysis and machine intelligence (2015)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convo- lutional networks. IEEE transactions on pattern analysis and machine intelligence (2015)
2015
-
[3]
IEEE Transactions on Biometrics, Behavior, and Identity Science (2025)
Duan, J., Liu, S., Hao, Y., Huang, H., He, R.: Dual frequency-guided spatiotempo- ral feature learning for face forgery detection. IEEE Transactions on Biometrics, Behavior, and Identity Science (2025)
2025
-
[4]
Sen- sors (2025)
Dumic, E., da Silva Cruz, L.A.: Three-dimensional point cloud applications, datasets, and compression methodologies for remote sensing: A meta-survey. Sen- sors (2025)
2025
-
[5]
Advances in neural information processing systems (2024)
Fan, Z., Zhang, J., Cong, W., Wang, P., Li, R., Wen, K., Zhou, S., Kadambi, A., Wang, Z., Xu, D., et al.: Large spatial model: End-to-end unposed images to semantic 3d. Advances in neural information processing systems (2024)
2024
-
[6]
arXiv preprint arXiv:2404.10318 (2024)
Feng, X., He, Y., Wang, Y., Yang, Y., Li, W., Chen, Y., Kuang, Z., Fan, J., Jun, Y., et al.: Srgs: Super-resolution 3d gaussian splatting. arXiv preprint arXiv:2404.10318 (2024)
-
[7]
In: Proceedings of the 32nd ACM International Conference on Multimedia (2024)
Han, X., Tang, Y., Wang, Z., Li, X.: Mamba3d: Enhancing local features for 3d point cloud analysis via state space model. In: Proceedings of the 32nd ACM International Conference on Multimedia (2024)
2024
-
[8]
IEEE Transactions on Visualization and Computer Graphics (2024)
Han, Y., Yu, T., Yu, X., Xu, D., Zheng, B., Dai, Z., Yang, C., Wang, Y., Dai, Q.: Super-nerf: View-consistent detail generation for nerf super-resolution. IEEE Transactions on Visualization and Computer Graphics (2024)
2024
-
[9]
In: ACM SIGGRAPH 2024 conference papers (2024)
Huang, B., Yu, Z., Chen, A., Geiger, A., Gao, S.: 2d gaussian splatting for geo- metrically accurate radiance fields. In: ACM SIGGRAPH 2024 conference papers (2024)
2024
-
[10]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2025)
Huang, Y., Miyazaki, T., Liu, X., Omachi, S.: Infrared image super-resolution: A systematic review and future trends. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2025)
2025
-
[11]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. (2023) 16 D. Zhu et al
2023
-
[12]
In: Proceedings of the IEEE conference on computer vision and pattern recognition (2016)
Kim, J., Lee, J.K., Lee, K.M.: Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2016)
2016
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
Ko, H.k., Park, D., Park, Y., Lee, B., Han, J., Park, E.: Sequence matters: Harness- ing video models in 3d super-resolution. In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
2025
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Lee, J.L., Li, C., Lee, G.H.: Disr-nerf: Diffusion-guided view-consistent super- resolution nerf. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[15]
In: Proceedings of the 31st ACM International Conference on Multimedia (2023)
Li, G., Xing, W., Zhao, L., Lan, Z., Sun, J., Zhang, Z., Zhang, Q., Lin, H., Lin, Z.: Self-reference image super-resolution via pre-trained diffusion large model and window adjustable transformer. In: Proceedings of the 31st ACM International Conference on Multimedia (2023)
2023
-
[16]
Advances in neural information processing systems (2024)
Liang, D., Zhou, X., Xu, W., Zhu, X., Zou, Z., Ye, X., Tan, X., Bai, X.: Point- mamba: A simple state space model for point cloud analysis. Advances in neural information processing systems (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision (2021)
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision (2021)
2021
-
[18]
arXiv preprint arXiv:2405.08609 (2024)
Lin, J.: Dynamic nerf: A review. arXiv preprint arXiv:2405.08609 (2024)
-
[19]
In: Proceedings of the 33rd ACM International Conference on Multimedia (2025)
Liu, Y., Pan, J., Li, Y., Dong, Q., Zhu, C., Guo, Y., Wang, F.: Ultravsr: Achiev- ing ultra-realistic video super-resolution with efficient one-step diffusion space. In: Proceedings of the 33rd ACM International Conference on Multimedia (2025)
2025
-
[20]
Current World Models Lack a Persistent State Core
Lu, J., Zhu, D., Shi, H., Cai, L., Tang, G., Chen, Y., Cao, J., Tang, D., Zhang, Y., Dai, Y., et al.: Current world models lack a persistent state core. arXiv preprint arXiv:2606.20545 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Commu- nications of the ACM (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM (2021)
2021
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition (2017)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2017)
2017
-
[23]
Advances in neural information processing systems (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space. Advances in neural information processing systems (2017)
2017
-
[24]
IEEE transactions on pattern analysis and ma- chine intelligence (2022)
Saharia, C., Ho, J., Chan, W., Salimans, T., Fleet, D.J., Norouzi, M.: Image super- resolution via iterative refinement. IEEE transactions on pattern analysis and ma- chine intelligence (2022)
2022
-
[25]
In: European Conference on Computer Vision
Shen, Y., Ceylan, D., Guerrero, P., Xu, Z., Mitra, N.J., Wang, S., Frühstück, A.: Supergaussian: Repurposing video models for 3d super resolution. In: European Conference on Computer Vision. Springer (2024)
2024
-
[26]
Information Fusion (2025)
Sohail, S.S., Himeur, Y., Kheddar, H., Amira, A., Fadli, F., Atalla, S., Copiaco, A., Mansoor, W.: Advancing 3d point cloud understanding through deep transfer learning: A comprehensive survey. Information Fusion (2025)
2025
-
[27]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference (2025)
Wan, Y., Shao, M., Cheng, Y., Zuo, W.: S2gaussian: Sparse-view super-resolution 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference (2025)
2025
-
[28]
In: Proceedings of the 30th ACM International Conference on Multimedia (2022) AnchorSplat 17
Wang, C., Wu, X., Guo, Y.C., Zhang, S.H., Tai, Y.W., Hu, S.M.: Nerf-sr: High quality neural radiance fields using supersampling. In: Proceedings of the 30th ACM International Conference on Multimedia (2022) AnchorSplat 17
2022
-
[29]
Advances in Neural Information Processing Systems37, 118883–118906 (2024)
Wang, H., Cao, J., Liu, J., Zhou, X., Huang, H., He, R.: Hallo3d: Multi-modal hal- lucination detection and mitigation for consistent 3d content generation. Advances in Neural Information Processing Systems37, 118883–118906 (2024)
2024
-
[30]
Advances in Neural Information Processing Systems (2024)
Wang, X., Li, M., Liu, W., Zhang, H., Hu, S., Zhang, Y., Zhou, Z., Jin, H.: Un- learnable 3d point clouds: Class-wise transformation is all you need. Advances in Neural Information Processing Systems (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., Zhao, H.: Point transformer v3: Simpler faster stronger. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
2024
-
[33]
Advances in Neural Information Processing Systems (2022)
Wu, X., Lao, Y., Jiang, L., Liu, X., Zhao, H.: Point transformer v2: Grouped vector attention and partition-based pooling. Advances in Neural Information Processing Systems (2022)
2022
-
[34]
In: European Conference on Computer Vision
Wu, Z., Wan, Z., Zhang, J., Liao, J., Xu, D.: Rafe: Generative radiance fields restoration. In: European Conference on Computer Vision. Springer (2024)
2024
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Xiao, Z., Wang, X.: Event-based video super-resolution via state space models. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
2025
-
[36]
Resplat: Learning recurrent gaussian splats.arXiv preprint arXiv:2510.08575, 2025
Xu, H., Barath, D., Geiger, A., Pollefeys, M.: Resplat: Learning recurrent gaussian splats. arXiv preprint arXiv:2510.08575 (2025)
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Xu, Y., Park, T., Zhang, R., Zhou, Y., Shechtman, E., Liu, F., Huang, J.B., Liu, D.: Videogigagan: Towards detail-rich video super-resolution. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
2025
- [38]
-
[39]
arXiv preprint arXiv:2406.10111 (2024)
Yu, X., Zhu, H., He, T., Chen, Z.: Gaussiansr: 3d gaussian super-resolution with 2d diffusion priors. arXiv preprint arXiv:2406.10111 (2024)
-
[40]
arXiv preprint arXiv:2508.16467 (2025)
Zeng, H., Bai, Y., Fu, Y.: Arbitrary-scale 3d gaussian super-resolution. arXiv preprint arXiv:2508.16467 (2025)
-
[41]
arXiv preprint arXiv:2508.03057 (2025)
Zhang, T., Liang, Z., Wang, B.: A survey of medical point cloud shape learning: Registration, reconstruction and variation. arXiv preprint arXiv:2508.03057 (2025)
-
[42]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (2025)
Zhang, W., Zhou, J., Geng, H., Zhang, W., Liu, Y.S.: Gap: Gaussianize any point clouds with text guidance. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (2025)
2025
-
[43]
In: Proceed- ings of the IEEE/CVF international conference on computer vision (2021)
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V.: Point transformer. In: Proceed- ings of the IEEE/CVF international conference on computer vision (2021)
2021
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Zheng, M., Sun, L., Dong, J., Pan, J.: Efficient video super-resolution for real- time rendering with decoupled g-buffer guidance. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
2025
-
[45]
Advances in Neural Information Processing Systems (2024)
Zhou, J., Zhang, W., Liu, Y.S.: Diffgs: Functional gaussian splatting diffusion. Advances in Neural Information Processing Systems (2024)
2024
-
[46]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Zhu, D., Cao, J., Shao, J., Zhang, Z., Duan, J., He, R.: Mtsd: Simple yet effective self-distillation for generalizable deepfake detection. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[47]
Pattern recognition (2024)
Zhu, Q., Fan, L., Weng, N.: Advancements in point cloud data augmentation for deep learning: A survey. Pattern recognition (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.