Multi-Objective Exploration and Preference Optimization via Mutual Information
Pith reviewed 2026-07-03 21:15 UTC · model grok-4.3
The pith
Maximizing joint conditional mutual information among responses, feedback, and preference vectors makes LLM outputs distinguishable and aligned across conflicting objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MI-EPO unifies exploration and alignment by maximizing the joint conditional mutual information among generated responses, preference feedback, and preference vectors; the added probabilistic routing mechanism decomposes the two goals so that responses become distinguishable and correctly aligned with each conditioning vector.
What carries the argument
Joint conditional mutual information maximization among responses, feedback, and vectors, combined with a probabilistic routing mechanism that decomposes alignment from preference-aware exploration.
If this is right
- Responses generated under different preference vectors become distinguishable rather than overlapping in reward space.
- Outputs gain controllability, allowing direct steering by preference vectors.
- Trade-offs across multiple objectives remain stable during training and inference.
- Alignment improves on both safe-alignment and helpful-assistant tasks compared with prior conditional direct preference optimization.
Where Pith is reading between the lines
- The same mutual-information objective could be tested on conditional generation tasks outside preference alignment, such as style or domain control.
- If the routing mechanism proves robust, separate exploration bonuses may become unnecessary in other preference-learning pipelines.
- Extending the framework to more than two or three objectives would test whether the information gain scales without additional regularization.
Load-bearing premise
Maximizing the joint conditional mutual information among generated responses, preference feedback, and preference vectors, together with a probabilistic routing mechanism, will cause responses to become distinguishable and correctly aligned without introducing new instabilities or requiring additional constraints on the reward distributions.
What would settle it
An experiment in which reward distributions for responses conditioned on different preference vectors remain heavily overlapped or alignment scores fail to rise after MI-EPO training would falsify the central claim.
Figures
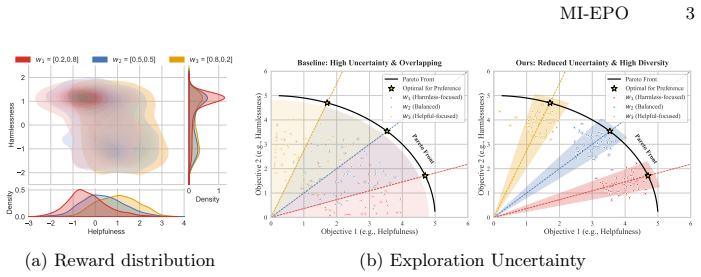
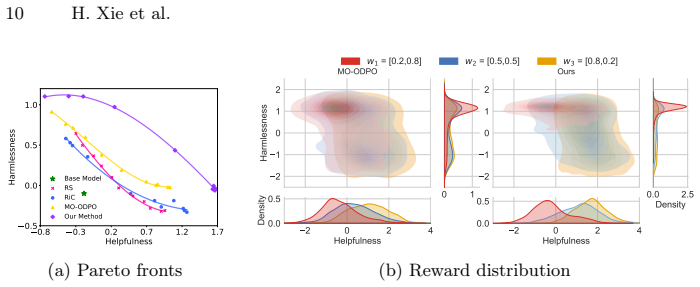
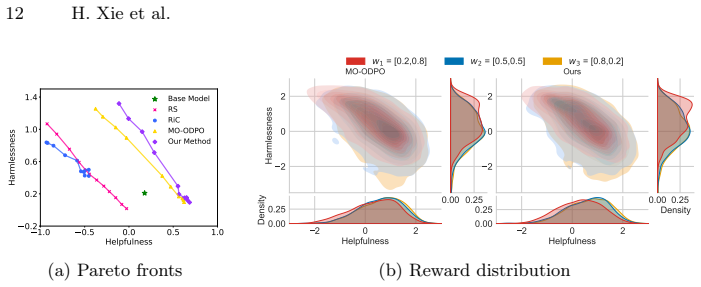
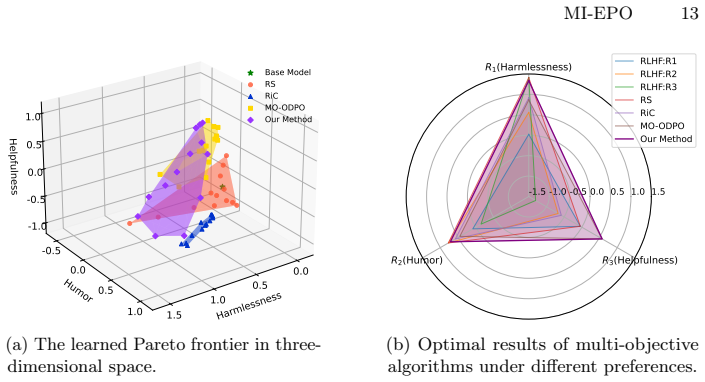
read the original abstract
Aligning large language models with diverse and heterogeneous human values requires multi-objective alignment methods to effectively trade off conflicting preference dimensions. Current methods achieve this trade-off by training policies conditioned on preference vectors and leveraging online direct preference optimization. However, exploration uncertainty can cause the reward distributions of responses generated under different preference vectors to overlap, and the generated responses may fail to effectively align with the corresponding preference vectors. In this paper, we propose Multi-Objective Exploration and Preference Optimization via Mutual Information (MI-EPO), an information-theoretic framework. It unifies multi-objective exploration and alignment by maximizing the joint conditional mutual information among generated responses, preference feedback, and preference vectors. By incorporating a probabilistic routing mechanism, MI-EPO naturally decomposes objective alignment and preference-aware exploration, encouraging the model to generate responses that are distinguishable and aligned with different preference conditions. Experiments on safe alignment and helpful assistant tasks show that MI-EPO significantly improves the alignment between generated responses and preference vectors, makes the outputs more controllable, and achieves stable trade-offs across multiple objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MI-EPO, an information-theoretic method for multi-objective LLM alignment that unifies exploration and preference optimization by maximizing the joint conditional mutual information I(response; feedback, vector) together with a probabilistic routing mechanism. It argues that this addresses overlapping reward distributions under different preference vectors (unlike conditioned DPO), yielding distinguishable, controllable responses and stable trade-offs. Experiments on safe alignment and helpful assistant tasks are claimed to demonstrate improved alignment, controllability, and objective trade-offs.
Significance. If the central claim holds, the work would supply a principled information-theoretic route to multi-objective alignment that avoids reward overlap without additional constraints on the reward model. The unification of exploration and alignment via mutual information, plus the routing decomposition, would be a notable contribution if accompanied by the missing derivation and convergence analysis.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that joint conditional MI maximization plus probabilistic routing 'naturally decomposes' alignment from exploration and produces distinguishable aligned responses rests on an unproven effect; no derivation, explicit objective function, or condition on the reward distributions is supplied to show why MI maximization separates rather than reinforces overlap or introduces instabilities.
- [Experiments] Experiments section: the abstract asserts that 'MI-EPO significantly improves' alignment and achieves 'stable trade-offs,' yet the visible text supplies no quantitative results, baselines, or metrics, so the experimental support for the load-bearing claim cannot be evaluated.
minor comments (1)
- [§3] Notation for the joint conditional mutual information and the routing mechanism should be defined explicitly with an equation early in the method section.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below, providing clarifications where the manuscript already contains the relevant material and committing to revisions for improved rigor and visibility.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that joint conditional MI maximization plus probabilistic routing 'naturally decomposes' alignment from exploration and produces distinguishable aligned responses rests on an unproven effect; no derivation, explicit objective function, or condition on the reward distributions is supplied to show why MI maximization separates rather than reinforces overlap or introduces instabilities.
Authors: The manuscript in §3 presents the MI-EPO objective as the maximization of the joint conditional mutual information I(response; feedback, vector) and introduces the probabilistic routing decomposition to separate alignment and exploration terms. However, we agree that an explicit step-by-step derivation, the full objective function, and the conditions on reward distributions that guarantee separation (rather than overlap reinforcement) are not sufficiently detailed. We will add this derivation, including the routing decomposition and a brief stability argument, in the revised §3. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts that 'MI-EPO significantly improves' alignment and achieves 'stable trade-offs,' yet the visible text supplies no quantitative results, baselines, or metrics, so the experimental support for the load-bearing claim cannot be evaluated.
Authors: The full manuscript contains an Experiments section reporting quantitative results on safe alignment and helpful assistant tasks, including comparisons to conditioned DPO baselines and metrics for alignment, controllability, and objective trade-offs. If these results were not visible in the reviewed version, we will revise the section to include a summary table of key metrics and explicit numerical improvements to make the support for the claims immediately evaluable. revision: yes
Circularity Check
No circularity detected; derivation relies on external information-theoretic principles
full rationale
The provided abstract and description introduce MI-EPO as maximizing joint conditional mutual information I(response; feedback, vector) plus a probabilistic routing mechanism, but contain no equations, fitted parameters renamed as predictions, or self-citations that reduce any claim to its own inputs by construction. No self-definitional loops, uniqueness theorems from the same authors, or ansatzes smuggled via prior work are visible. The framework is presented as building on standard mutual information concepts without the central result being forced by internal fitting or self-reference, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Maximizing the joint conditional mutual information among generated responses, preference feedback, and preference vectors produces distinguishable and correctly aligned outputs under different preference conditions.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[2]
Li, Moxin and Zhang, Yuantao and Wang, Wenjie and Shi, Wentao and Liu, Zhuo and Feng, Fuli and Chua, Tat-Seng. Self-Improvement Towards P areto Optimality: Mitigating Preference Conflicts in Multi-Objective Alignment. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.574
-
[3]
IEEE transactions on cybernetics , volume=
Deep reinforcement learning for multiobjective optimization , author=. IEEE transactions on cybernetics , volume=. 2020 , publisher=
2020
-
[4]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning , year=
Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging , author=. Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning , year=
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Conditional language policy: A general framework for steerable multi-objective finetuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Robust Multi-Objective Preference Alignment with Online DPO , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[8]
CoRR , year=
Direct Language Model Alignment from Online AI Feedback , author=. CoRR , year=
-
[9]
CoRR , year=
RLHF Workflow: From Reward Modeling to Online RLHF , author=. CoRR , year=
-
[10]
Proceedings of the 41st International Conference on Machine Learning , pages=
Self-rewarding language models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[11]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[12]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[13]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[14]
Conference on Neural Information Processing Systems , year=
Decoding-time language model alignment with multiple objectives , author=. Conference on Neural Information Processing Systems , year=
-
[15]
Conference on Neural Information Processing Systems , year=
Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards , author=. Conference on Neural Information Processing Systems , year=
-
[16]
Panacea: Pareto Alignment via Preference Adaptation for
Zhong, Yifan and Ma, Chengdong and Zhang, Xiaoyuan and Yang, Ziran and Zhang, Qingfu and Qi, Siyuan and Yang, Yaodong , booktitle=. Panacea: Pareto Alignment via Preference Adaptation for
-
[17]
Findings of Annual Meeting of the Association for Computational Linguistics , year=
Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization , author=. Findings of Annual Meeting of the Association for Computational Linguistics , year=
-
[18]
Conference on Neural Information Processing Systems , year=
Metaaligner: Towards generalizable multi-objective alignment of language models , author=. Conference on Neural Information Processing Systems , year=
-
[19]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle=
-
[20]
Findings of Annual Meeting of the Association for Computational Linguistics , year=
Disentangling length from quality in direct preference optimization , author=. Findings of Annual Meeting of the Association for Computational Linguistics , year=
-
[21]
Arithmetic Control of
Haoxiang Wang and Yong Lin and Wei Xiong and Rui Yang and Shizhe Diao and Shuang Qiu and Han Zhao and Tong Zhang , booktitle=. Arithmetic Control of
-
[22]
Proceedings of the 41st International Conference on Machine Learning , pages=
Iterative preference learning from human feedback: bridging theory and practice for RLHF under KL-constraint , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[23]
Comptes Rendus Mathematique , volume=
Multiple-gradient descent algorithm (MGDA) for multiobjective optimization , author=. Comptes Rendus Mathematique , volume=. 2012 , publisher=
2012
-
[24]
Conference on Empirical Methods in Natural Language Processing , year=
Controllable preference optimization: Toward controllable multi-objective alignment , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[25]
A Survey on Evolutionary Constrained Multiobjective Optimization , year=
Liang, Jing and Ban, Xuanxuan and Yu, Kunjie and Qu, Boyang and Qiao, Kangjia and Yue, Caitong and Chen, Ke and Tan, Kay Chen , journal=. A Survey on Evolutionary Constrained Multiobjective Optimization , year=
-
[26]
International Conference on Machine Learning , year=
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment , author=. International Conference on Machine Learning , year=
-
[27]
2024 , note=
Hanze Dong and Wei Xiong and Bo Pang and Haoxiang Wang and Han Zhao and Yingbo Zhou and Nan Jiang and Doyen Sahoo and Caiming Xiong and Tong Zhang , journal=. 2024 , note=
2024
-
[28]
Advances in Neural Information Processing Systems , volume=
Iterative reasoning preference optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Xu, Yuancheng and Sehwag, Udari Madhushani and Koppel, Alec and Zhu, Sicheng and An, Bang and Huang, Furong and Ganesh, Sumitra , booktitle=
-
[30]
arXiv preprint arXiv:2310.11564 , year=
Personalized soups: Personalized large language model alignment via post-hoc parameter merging , author=. arXiv preprint arXiv:2310.11564 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Fine-grained human feedback gives better rewards for language model training , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Forty-second International Conference on Machine Learning , year=
Pareto Merging: Multi-Objective Optimization for Preference-Aware Model Merging , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
Baijiong Lin and Weisen Jiang and Yuancheng Xu and Hao Chen and Ying-Cong Chen , booktitle=
-
[34]
arXiv preprint arXiv:2310.17022 , year=
Controlled decoding from language models , author=. arXiv preprint arXiv:2310.17022 , year=
-
[35]
Handbook of the fundamentals of financial decision making: Part I , pages=
Prospect theory: An analysis of decision under risk , author=. Handbook of the fundamentals of financial decision making: Part I , pages=. 2013 , publisher=
2013
-
[36]
arXiv preprint arXiv:2405.06639 , year=
Value Augmented Sampling for Language Model Alignment and Personalization , author=. arXiv preprint arXiv:2405.06639 , year=
-
[37]
Conference on Neural Information Processing Systems , year=
Fine-grained human feedback gives better rewards for language model training , author=. Conference on Neural Information Processing Systems , year=
-
[38]
Chen, Ruizhe and Zhang, Xiaotian and Luo, Meng and Chai, Wenhao and Liu, Zuozhu , booktitle=
-
[39]
LoRA: Low-Rank Adaptation of Large Language Models , author=
-
[40]
Autonomous Agents and Multi-Agent Systems , volume=
Actor-critic multi-objective reinforcement learning for non-linear utility functions , author=. Autonomous Agents and Multi-Agent Systems , volume=. 2023 , publisher=
2023
-
[41]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[42]
International Conference on Machine Learning , pages=
DoRA: Weight-Decomposed Low-Rank Adaptation , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[43]
Proceedings of the AAAI conference on artificial intelligence , year=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , year=
-
[44]
Conference on Neural Information Processing Systems , year=
Transfer Q Star: Principled Decoding for LLM Alignment , author=. Conference on Neural Information Processing Systems , year=
-
[45]
Maxim Khanov and Jirayu Burapacheep and Yixuan Li , booktitle=
-
[46]
arXiv preprint arXiv:2402.06147 , year=
DeAL: Decoding-time Alignment for Large Language Models , author=. arXiv preprint arXiv:2402.06147 , year=
-
[47]
Conference on Neural Information Processing Systems , year=
Training language models to follow instructions with human feedback , author=. Conference on Neural Information Processing Systems , year=
-
[48]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
International Conference on Learning Representations , year=
Controlled Text Generation via Language Model Arithmetic , author=. International Conference on Learning Representations , year=
-
[50]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Self-improvement towards pareto optimality: Mitigating preference conflicts in multi-objective alignment , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[51]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[52]
Cambridge UP , year=
Convex optimization , author=. Cambridge UP , year=
-
[53]
Zhang, Xiaoyuan and Zhao, Liang and Yu, Yingying and Lin, Xi and Chen, Yifan and Zhao, Han and Zhang, Qingfu , booktitle=
-
[54]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
arXiv preprint arXiv:2307.12966 , year=
Aligning large language models with human: A survey , author=. arXiv preprint arXiv:2307.12966 , year=
-
[56]
arXiv preprint arXiv:2406.16306 , year=
Cascade reward sampling for efficient decoding-time alignment , author=. arXiv preprint arXiv:2406.16306 , year=
-
[57]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Mixture-of-Subspaces in Low-Rank Adaptation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[58]
International Conference on Parallel Problem Solving from Nature , year =
Multiobjective optimization using evolutionary algorithms—a comparative case study , author =. International Conference on Parallel Problem Solving from Nature , year =
-
[59]
1999 , publisher =
Nonlinear multiobjective optimization , author =. 1999 , publisher =
1999
-
[60]
Ji, Jiaming and Hong, Donghai and Zhang, Borong and Chen, Boyuan and Dai, Josef and Zheng, Boren and Qiu, Tianyi and Li, Boxun and Yang, Yaodong , journal=
-
[61]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Stanford alpaca: An instruction-following
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B , year=. Stanford alpaca: An instruction-following
-
[63]
TinyLlama: An Open-Source Small Language Model
Tinyllama: An open-source small language model , author=. arXiv preprint arXiv:2401.02385 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Transactions on Machine Learning Research , year=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. Transactions on Machine Learning Research , year=
-
[65]
arXiv preprint arXiv:2501.10945 , year=
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond , author=. arXiv preprint arXiv:2501.10945 , year=
-
[66]
Transactions on Machine Learning Research , year=
Reasonable Effectiveness of Random Weighting: A Litmus Test for Multi-Task Learning , author=. Transactions on Machine Learning Research , year=
-
[67]
GitHub repository , howpublished =
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec , title =. GitHub repository , howpublished =. 2020 , publisher =
2020
-
[68]
Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan , howpublished =
-
[69]
Efficient
Chen, Weiyu and Kwok, James , booktitle =. Efficient
-
[70]
arXiv preprint arXiv:2308.12029 , year =
Dual-Balancing for Multi-Task Learning , author =. arXiv preprint arXiv:2308.12029 , year =
-
[71]
Conference on Neural Information Processing Systems , year =
Multi-objective meta learning , author =. Conference on Neural Information Processing Systems , year =
-
[72]
International Conference on Machine Learning , year =
Smooth Tchebycheff Scalarization for Multi-Objective Optimization , author =. International Conference on Machine Learning , year =
-
[73]
International Conference on Learning Representations , year =
Few for Many: Tchebycheff Set Scalarization for Many-Objective Optimization , author =. International Conference on Learning Representations , year =
-
[74]
International Conference on Machine Learning , year =
Pareto Manifold Learning: Tackling multiple tasks via ensembles of single-task models , author =. International Conference on Machine Learning , year =
-
[75]
International Conference on Learning Representations , year=
Pareto low-rank adapters: Efficient multi-task learning with preferences , author=. International Conference on Learning Representations , year=
-
[76]
European Conference on Artificial Intelligence , year =
A First-Order Multi-Gradient Algorithm for Multi-Objective Bi-Level Optimization , author =. European Conference on Artificial Intelligence , year =
-
[77]
Chen, Lisha and Saif, AFM and Shen, Yanning and Chen, Tianyi , booktitle =
-
[78]
Gliding over the
Xiaoyuan Zhang and Genghui Li and Xi Lin and Yichi Zhang and Yifan Chen and Qingfu Zhang , booktitle=. Gliding over the
-
[79]
Conference on Neural Information Processing Systems , year =
Pareto set learning for expensive multi-objective optimization , author =. Conference on Neural Information Processing Systems , year =
-
[80]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Separating Shared and Domain-Specific LoRAs for Multi-Domain Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.