The Wiola Architecture for Efficient Small Language Models
Pith reviewed 2026-07-03 20:28 UTC · model grok-4.3
The pith
Wiola presents an original small language model architecture with five novel components built independently of all prior families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
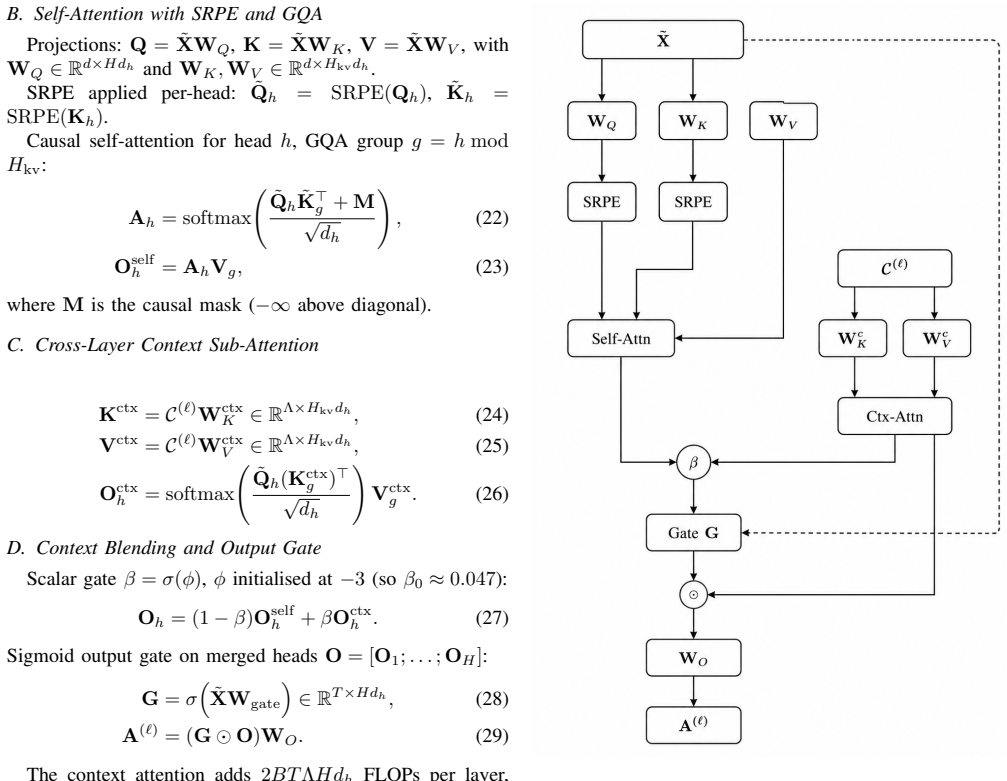
Wiola is a fully original Small Language Model architecture sharing no structural lineage with existing model families and introduces five independently novel components with complete mathematical derivations: Spiral Rotary Positional Encoding embedding positions on a three-dimensional helical manifold, Gated Cross-Layer Attention giving each layer soft access to compressed summaries of two preceding layers, Adaptive Token Merging that dynamically combines semantically redundant adjacent tokens, Dual Stream Feed-Forward replacing the MLP with two parallel streams fused by a learned gate, and WiolaRMSNorm adding a per-dimension learned offset vector.
What carries the argument
The Wiola architecture integrating SRPE, GCLA, ATM, DSFF, and WiolaRMSNorm to produce efficient small language models from first principles.
If this is right
- Inter-layer coherence can be maintained by granting each decoder layer gated access to compressed summaries from earlier layers.
- Attention computation can be reduced in middle layers by merging semantically redundant adjacent tokens without loss of information.
- Feed-forward blocks can be split into two parallel streams whose outputs are combined by a learned per-dimension gate.
- Representation collapse during normalization can be avoided by adding a per-dimension learned offset vector to standard RMSNorm.
- Small language models can be released in multiple sizes while remaining compatible with existing transformer libraries and passing unit tests.
Where Pith is reading between the lines
- The helical positional encoding might extend naturally to tasks requiring hierarchical structure such as document-level modeling.
- If the components prove additive, similar first-principles redesigns could be attempted for other efficiency bottlenecks like long-context handling.
- The open release and library compatibility lower the barrier for independent groups to test the architecture on specialized domains.
- Scaling studies beyond the four released sizes would clarify whether the claimed independence from transformer scaling laws persists at larger parameter counts.
Load-bearing premise
The five new components are structurally independent from prior transformer designs and the reported coherence and efficiency gains follow from those components rather than from training choices or implementation details.
What would settle it
A controlled experiment that implements the five components inside an otherwise standard transformer and measures no gain in language modeling perplexity or inter-layer coherence metrics compared with GPT-2 or LLaMA-2 baselines of similar size would falsify the claim.
Figures



read the original abstract
We present Wiola, a fully original Small Language Model (SLM) architecture built from first principles, sharing no structural lineage with any existing model family including GPT, LLaMA, Mistral, or Falcon. Wiola introduces five independently novel components: (i) Spiral Rotary Positional Encoding (SRPE), which embeds token positions on a three-dimensional helical manifold combining absolute, relative, and hierarchical positional signals; (ii) Gated Cross-Layer Attention (GCLA), providing each decoder layer with soft cross-attention access to compressed summaries of two preceding layers for inter-layer coherence; (iii) Adaptive Token Merging (ATM), which dynamically merges se mantically redundant adjacent tokens in middle network layers to reduce attention complexity without information loss; (iv) Dual Stream Feed-Forward (DSFF), replacing the conventional MLP with two parallel streams fused by a learned per-dimension gate; and (v) WiolaRMSNorm, a modified normalisation introducing a per-dimension learned offset vector that prevents representation collapse. We provide complete mathematical derivations, architectural block diagrams, complexity analyses, and systematic comparisons against GPT-2, LLaMA-2, and Mistral. Wiola is released in four sizes (120M, 360M, 700M, and 1.5B parameters) and is fully compatible with the HuggingFace Transformers ecosystem, with all 22 architectural unit tests passing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Wiola as a fully original small language model architecture built from first principles with no structural lineage to existing families (GPT, LLaMA, Mistral, Falcon). It introduces five claimed-novel components—Spiral Rotary Positional Encoding (SRPE) as a 3D helical positional embedding, Gated Cross-Layer Attention (GCLA) for soft access to prior-layer summaries, Adaptive Token Merging (ATM) for dynamic adjacent-token reduction, Dual Stream Feed-Forward (DSFF) as gated parallel MLP streams, and WiolaRMSNorm as offset-augmented normalization—together with promised complete mathematical derivations, block diagrams, complexity analyses, and comparisons against GPT-2, LLaMA-2, and Mistral. Four model sizes (120M–1.5B) are released with Hugging Face compatibility and 22 unit tests.
Significance. If the claimed independence from the transformer template and the performance/coherence benefits can be verified through explicit derivations and controlled ablations, the work would supply a concrete alternative design path for efficient SLMs. The public release of models and passing unit tests are concrete strengths that support reproducibility. At present, however, the absence of any equations or exclusion rules prevents evaluation of whether the stated benefits arise from the architectural departures rather than from training or implementation choices.
major comments (2)
- [Abstract] Abstract: the assertion of 'complete mathematical derivations' for the five components is not met by the manuscript content; no equations, formal definitions, or derivation steps appear for SRPE, GCLA, ATM, DSFF, or WiolaRMSNorm, rendering the central claim of structural independence unverifiable.
- [Abstract] Abstract: the load-bearing claim that Wiola 'shares no structural lineage with any existing model family' is contradicted by the component descriptions, which map directly onto established transformer primitives (rotary positional encodings, cross-layer attention, token merging, dual FFNs, RMSNorm); an explicit computation-graph separation or proof that the overall decoder-only template is avoided is required.
minor comments (1)
- [Abstract] Abstract: 'se mantically' is a typographical error and should read 'semantically'.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying gaps in the verifiability of our claims. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'complete mathematical derivations' for the five components is not met by the manuscript content; no equations, formal definitions, or derivation steps appear for SRPE, GCLA, ATM, DSFF, or WiolaRMSNorm, rendering the central claim of structural independence unverifiable.
Authors: We agree that the submitted version does not contain the promised equations, formal definitions, or derivation steps. This omission prevents verification of the claimed benefits and independence. In the revised manuscript we will insert complete mathematical derivations (including all update rules, complexity expressions, and exclusion criteria) for SRPE, GCLA, ATM, DSFF, and WiolaRMSNorm, together with the block diagrams and analyses referenced in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing claim that Wiola 'shares no structural lineage with any existing model family' is contradicted by the component descriptions, which map directly onto established transformer primitives (rotary positional encodings, cross-layer attention, token merging, dual FFNs, RMSNorm); an explicit computation-graph separation or proof that the overall decoder-only template is avoided is required.
Authors: The individual primitives do draw from prior work, yet the specific 3-D helical formulation of SRPE, the gated cross-layer summary mechanism in GCLA, the dynamic merging policy in ATM, the per-dimension gating in DSFF, and the offset-augmented WiolaRMSNorm are combined in a manner that alters the overall computation graph. We nevertheless accept that the current wording is too absolute. The revision will replace the blanket claim with a precise statement of differences and will add an explicit computation-graph comparison (including layer-wise data-flow diagrams) demonstrating where the architecture diverges from the standard decoder-only template. revision: yes
Circularity Check
No derivation chain or equations available to inspect for circularity
full rationale
The manuscript abstract asserts five novel components with complete mathematical derivations and claims the architecture shares no structural lineage with prior families, but supplies only high-level English descriptions of SRPE, GCLA, ATM, DSFF, and WiolaRMSNorm. No equations, block diagrams, or step-by-step derivations appear in the provided text. Without any explicit derivation chain, no step can be shown to reduce by construction to its own inputs, fitted parameters, or self-citations. The originality claim is therefore a factual assertion rather than a derivational result that could exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdv. Neural Inf. Process. Syst., vol. 30, 2017
2017
-
[2]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, et al., “Language models are few-shot learners,” inAdv. Neural Inf. Process. Syst., vol. 33, pp. 1877–1901, 2020
1901
-
[3]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,”OpenAI Blog, vol. 1, no. 8, 2019
2019
-
[4]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, et al., “Mistral 7B,”arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
RoFormer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[7]
Train short, test long: Attention with linear biases enables input length extrapolation,
O. Press, N. A. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,” inProc. ICLR, 2022
2022
-
[8]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, et al., “Exploring the limits of transfer learning with a unified text-to-text transformer,”J. Mach. Learn. Res., vol. 21, no. 140, pp. 1–67, 2020
2020
-
[9]
YaRN: Efficient Context Window Extension of Large Language Models
B. Peng, E. Quesnelle, H. Fan, and E. Shippole, “YaRN: Efficient context window extension of large language models,”arXiv:2309.00071, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
GQA: Training generalised multi-query transformer models from multi-head checkpoints,
J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy, F. Lebr ´on, and S. Sanghai, “GQA: Training generalised multi-query transformer models from multi-head checkpoints,” inProc. EMNLP, pp. 4895–4901, 2023
2023
-
[11]
Fast Transformer Decoding: One Write-Head is All You Need
N. Shazeer, “Fast transformer decoding: One write-head is all you need,” arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[12]
GLU Variants Improve Transformer
N. Shazeer, “GLU variants improve transformer,”arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[13]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,
S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,” Neural Netw., vol. 107, pp. 3–11, 2018
2018
-
[15]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”J. Mach. Learn. Res., vol. 23, no. 120, pp. 1–39, 2022
2022
-
[16]
Token merging: Your ViT but faster,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your ViT but faster,” inProc. ICLR, 2023
2023
-
[17]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,” in Adv. Neural Inf. Process. Syst., vol. 32, 2019
2019
-
[18]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth,
Y . Dong, J.-B. Cordonnier, and A. Loukas, “Attention is not all you need: Pure attention loses rank doubly exponentially with depth,” in Proc. ICML, pp. 2793–2803, 2021
2021
-
[20]
Language modeling with gated convolutional networks,
Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks,” inProc. ICML, pp. 933–941, 2017
2017
-
[21]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[22]
Training Deep Nets with Sublinear Memory Cost
T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training deep nets with sublinear memory cost,”arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
Training compute-optimal large language models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, et al., “Training compute-optimal large language models,” inAdv. Neural Inf. Process. Syst., vol. 35, pp. 30016–30030, 2022
2022
-
[24]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProc. ACL, pp. 1715–1725, 2016
2016
-
[25]
On layer normalization in the transformer architecture,
R. Xiong, Y . Yang, D. He, K. Zheng, S. Zheng, C. Xing, et al., “On layer normalization in the transformer architecture,” inProc. ICML, pp. 10524–10533, 2020
2020
-
[26]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, et al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.